-
Notifications
You must be signed in to change notification settings - Fork 7
Indices
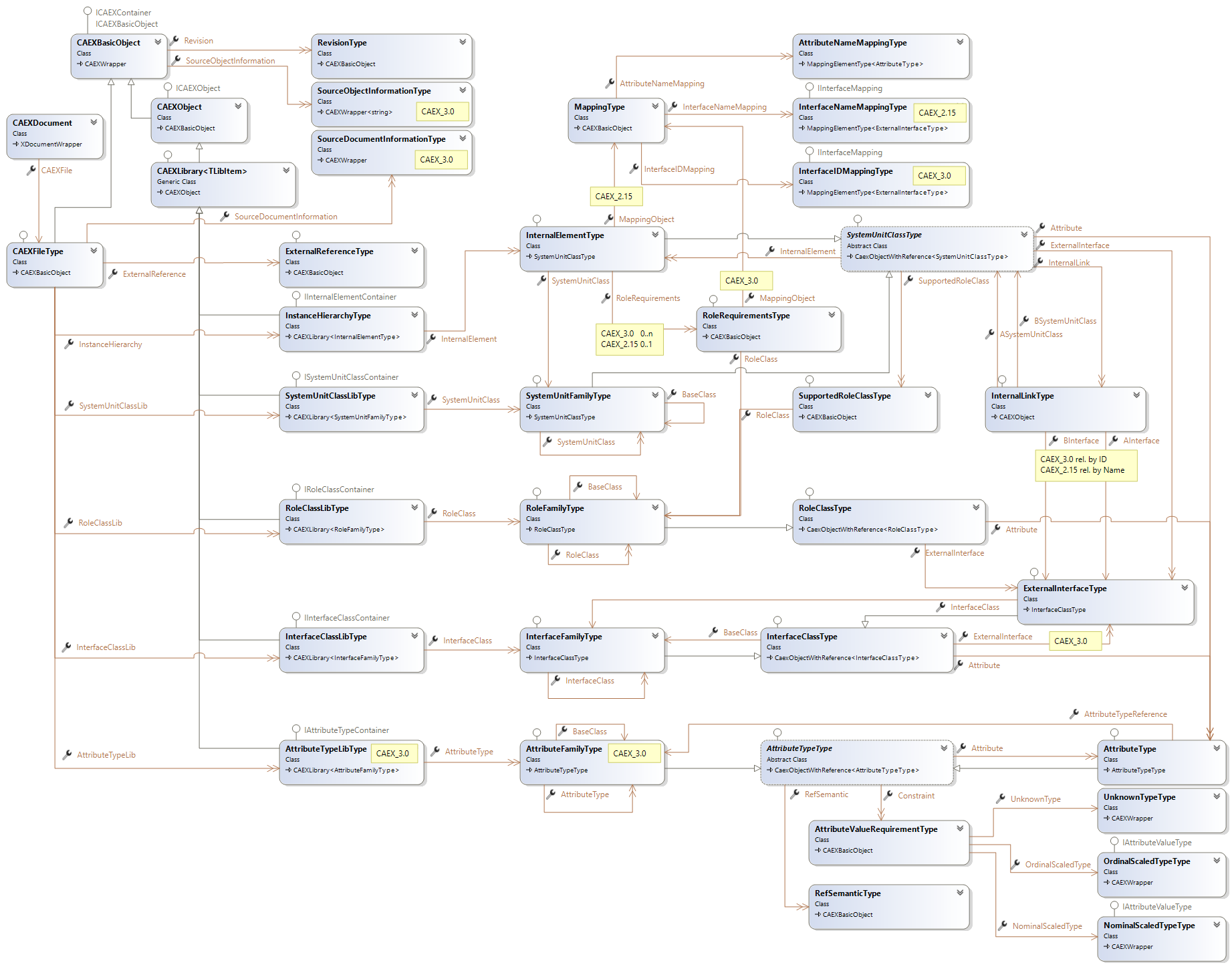
The AutomationML engine provides the user with convenient methods to query relations between AutomationML objects in an AutomationML document. Object references are defined in AutomationML by the ID of the referenced CAEXObject and by the CAEXPath of the referenced object, where instances are identified by the ID-Attribute value and classes as well as class-attributes by the CAEXPath. For accessing objects by means of the object ID or by means of the object path the engine provides the methods FindByID and FindByPath.
Examples of relations in which the object ID is used are:
- Instance to Instance relations
-
MirrortoMasterrelations -
InternalLinkrelations
-
Examples of relations in which the CAEX path is used are:
-
Instance to Class relations
-
InternalElementtoSystemUnitClass -
ExternalInterfacetoInterfaceClass - Attribute to
AttributeType - Role reference to
RoleClass
-
-
Class to Class relations
- Derived class to Base class
The identification of objects by means of the ID and the CAEXPath is very common, especially in AutomationML-based import interfaces. In order to avoid significant runtime restrictions with large files the AutomationML engine offers the LookupService. This service generates indices for an AutomationML document, one index on the CAEXObject ID and another index based on the CAEXPath.
The core of the AutomationML engine - represented by the package Aml.Engine does not define any services itself - with the exception of the standard QueryService - but can use services if they are registered via the ServiceLocator class. The package Aml.Engine.Services provides various services, such as the mentioned LookupService. The object identification-methods FindByID and FindByPath are defined as CAEXDocument Extension methods and are also members of the IQuery query interface implemented by both, the standard QueryService and the LookupService.
If the LookupService is not registered, the default QueryService is used for all queries. Please note that only one service implementing IQuery can be registered at a time. The registration of the Standard QueryService is done by the engine itself and does not have to be triggered by the user. The registration of the LookupService would unregister the standard QueryService. Unregister of the LookupSerice will automatically reactivate the standard QueryService. The currently registered query service is always assigned to the static property ServiceLocator.QueryService.
The standard QueryService is an application of LINQ to XML. LINQ to XML provides an in-memory XML programming interface that uses the .NET Language-Integrated Query (LINQ) framework. The FindById and FindByPath methods provided by this service do not use an index and search the entire document with each call, which could results in significant runtimes for large documents. When the LookupService is used, these queries run much faster.
The use of the LookupService can be activated by a single method call.
// Activation of the LookupService; Deactivation of the standard QueryService
var service = LookupService.Register();
// Deactivation of the LookupService; Reactivation of the standard QueryService
LookupService.UnRegister();The index tables, used by the LookupService, are created during the first query. Alternatively, table generation for a document can also be triggered by a method call of the LookupService.
service.AddDocument(myDocument);The ServiceLocator reacts to changes in the AutomationML document and always keeps the indices up-to-date. This requires an administrative overhead. In applications that have read-only access to an AutomationML document, this additional overhead would actually be unnecessary.
To support index based queries in read-only application since engine version 3.1.3 the standard QueryService offers the use of immutable read-only indices for fast searches. To load the index, based on the CAEXObjects ID-Attribute, the following code snippet can be used.
// check, if the activated query service supports index based access
if (ServiceLocator.QueryService is not ILookUpTable queryService)
{
// not supported; do nothing
return;
}
// check if the ID based index is already loaded
if (!queryService.IDTableIsLoaded(myDocument))
{
// load the table
queryService.LoadIDTable(myDocument);
}The following compact code snippet loads or reloads the ID table regardless of whether it has already been loaded.
(ServiceLocator.QueryService as ILookUpTable)?.LoadIDTable(document);The Interface ILookUpTable defines the new added methods from version 3.1.3 assigned to the standard QueryService supporting an index based access.
To load the index, based on the CAEXPath of CAEXObjects, the new method LoadPathTable is provided.
Instead of loading the indices via the QueryService, since version 3.1.3 there is the option to generate the indices already when loading the document. For this purpose, the new optional parameter createIndices has been added to all load methods - such as the LoadFromFile - of the CAEXDocument class.
The effects on the runtime regarding the FindById method can be clearly seen in the following benchmark result. The test was performed with a small AutomationML document with only 100 indexed objects, a second time with 1000 indexed objects, and another time with 10,000 indexed objects. The same 100 randomly determined objects were identified in each test. It can be clearly seen how the runtime increases without using an index (the baseline) depending on the size of the document. To see the performance impact the default version without an index is marked as the baseline method (with a ratio of 1.0).
BenchmarkDotNet=v0.13.5, OS=Windows 10 (10.0.19045.2846/22H2/2022Update)
Intel Core i7-6700HQ CPU 2.60GHz (Skylake), 1 CPU, 8 logical and 4 physical cores
.NET SDK=7.0.300-preview.23179.2
[Host] : .NET 6.0.16 (6.0.1623.17311), X64 RyuJIT AVX2
.NET 6.0 : .NET 6.0.16 (6.0.1623.17311), X64 RyuJIT AVX2
Job=.NET 6.0 Runtime=.NET 6.0
| Method | Objects | Mean | Min | Max | Ratio |
|---|---|---|---|---|---|
'FindByID using raw LinqToXml query' |
100 | 987.55 μs | 973.53 μs | 1,008.00 μs | 1.00 |
'FindByID using ID-Table in QueryService' |
100 | 55.39 μs | 54.56 μs | 56.09 μs | 0.06 |
'FindByID using LookupService' |
100 | 77.32 μs | 76.26 μs | 78.46 μs | 0.08 |
'FindByID using raw LinqToXml query' |
1000 | 8,973.29 μs | 8,775.14 μs | 9,110.12 μs | 1.000 |
'FindByID using ID-Table in QueryService' |
1000 | 56.25 μs | 55.37 μs | 56.99 μs | 0.006 |
'FindByID using LookupService' |
1000 | 79.62 μs | 77.26 μs | 84.85 μs | 0.009 |
'FindByID using raw LinqToXml query' |
10000 | 159,234.48 μs | 156,343.67 μs | 163,849.02 μs | 1.000 |
'FindByID using ID-Table in QueryService' |
10000 | 59.40 μs | 54.92 μs | 69.46 μs | 0.000 |
'FindByID using LookupService' |
10000 | 80.26 μs | 77.25 μs | 88.45 μs | 0.001 |
The effects on the runtime regarding the FindByPath method are summarized in the following benchmark result. The test configuration is the same as before. The path references are taken from the InternalElement to SystemUnitClass relation and from the SystemUnitClass to RoleClass relation. It can be again seen how the runtime increases without using an index (the baseline). In this case, the runtime depends less on the size of the document than on the nesting depth of the class trees. To see the performance impact, the default version without an index is marked as the baseline method (with a ratio of 1). The runtime loss of the standard method without the use of an index is in this case much smaller than with the object identification by the object ID.
| Method | Objects | Mean | Min | Max | Ratio |
|---|---|---|---|---|---|
'FindByPath using raw LinqToXml query' |
100 | 673.8 μs | 642.9 μs | 727.8 μs | 1.00 |
'FindByPath using Path-Table in QueryService' |
100 | 302.4 μs | 285.3 μs | 329.4 μs | 0.45 |
'FindByPath using LookupService' |
100 | 379.3 μs | 368.3 μs | 403.6 μs | 0.55 |
'FindByPath using raw LinqToXml query' |
1000 | 673.9 μs | 642.9 μs | 722.8 μs | 1.00 |
'FindByPath using Path-Table in QueryService' |
1000 | 309.4 μs | 285.9 μs | 334.7 μs | 0.46 |
'FindByPath using LookupService' |
1000 | 399.0 μs | 382.7 μs | 415.8 μs | 0.59 |
'FindByPath using raw LinqToXml query' |
10000 | 699.8 μs | 675.6 μs | 725.4 μs | 1.00 |
'FindByPath using Path-Table in QueryService' |
10000 | 302.9 μs | 287.3 μs | 328.0 μs | 0.44 |
'FindByPath using LookupService' |
10000 | 429.4 μs | 400.2 μs | 445.4 μs | 0.61 |
The use of indices to speed up the identification of referenced objects in relations is generally recommended, especially when many instance to instance relations (Mirror-Master relations and Internal Links) based on the object ID-Attribute value are used. For choosing the right application mode it is important whether the loaded AutomationML document is opened only for reading or also for writing. For read-only documents, it is recommended to select the creation of index tables as an option directly when loading the document. These indexes are static tables in the standard QueryService and are not updated when the AutomationML document is changed.
var readOnlyDocument = CAEXDocument.LoadFromFile (filePath, createIndices:true);If the document content is changed after opening, the option must not be selected when loading the document, otherwise the object identification could give wrong results when the document is modified. In this case the LookupService must be registered. In this case, the indexes are automatically updated by the LookupService after each modification of the document.
LookupService.Register();
var writeDocument = CAEXDocument.LoadFromFile (filePath);
// continue with modifications, indices are updatedChoosing the createIndices option in a CAEXDocument-load method when the LookupService is registered does not have any effect.
To use the read-only indices for a modified document is not recommended. The following code could produce incorrect model relations, since the engine itself uses the object identification methods in many editing methods and for this the indices must also be up to date during the modifications.
// load a document and create the indices
var writeDocument = CAEXDocument.LoadFromFile (filePath, createIndices:true);
// ....
// do a bulk of modifications
// modifcations could produce incorrect relations
// ....
// reload the tables after a modification
(ServiceLocator.QueryService as ILookUpTable)?.LoadIDTable(writeDocument);
(ServiceLocator.QueryService as ILookUpTable)?.LoadPathTable(writeDocument);However, it is possible to make modifications without using indexes at all and to create the index only for a final validation of the document.
// load a document without indices
var writeDocument = CAEXDocument.LoadFromFile (filePath);
// ....
// do a bulk of modifications, queries are executed with linq to xml but could be time consuming
// ....
// load the tables after a modification to speed up the validation
(ServiceLocator.QueryService as ILookUpTable)?.LoadIDTable(writeDocument);
(ServiceLocator.QueryService as ILookUpTable)?.LoadPathTable(writeDocument);
// do some validationIf you use the ValidatorService for the validation of the document and the document has been loaded without indices, indices are automatically loaded for the validation and unloaded again after the validation by the ValidatorService. Please note that the indices are only unloaded, when the linq result query is finally materialized.
// load a document without indices
var writeDocument = CAEXDocument.LoadFromFile (filePath);
// ....
// do a bulk of modifications
// ....
// validate the document (Indices are loaded by the ValidatorService)
var service = ValidatorService.Register();
var errors = service.ValidateAll(writeDocument).ToList();
// Indices are unloaded by the ValidatorService when the validation result has been materializedMixed operation of LookupService during modifications and QueryService with indices after modification is also possible in principle, but cannot be justified.
LookupService.Register();
// load a document without indices
var writeDocument = CAEXDocument.LoadFromFile (filePath);
// ....
// do a bulk of modifications
// ....
// Unregister the LookupService, the default QueryServic, supporting indices will be activated
LookupService.UnRegister();
// load the tables after a modification
(ServiceLocator.QueryService as ILookUpTable)?.LoadIDTable(writeDocument);
(ServiceLocator.QueryService as ILookUpTable)?.LoadPathTable(writeDocument);
// do some validationThe use of the engine without using indices without large runtime losses is quite possible in certain situations, for example, when only a few instance relations based on the values of object ID-Attributes are used.
Home | Installation | API | Solutions
Getting Started
- Install
- First Steps with CAEX
- Working with CAEX Libraries
- Working with CAEX Relations
- Managing Inheritance
- Attribut Values
- Document Versions
Extended Examples
API Reference Guide
{kind=link}