- 感谢 Wormhole 的官方帮助!官方微信群很友好,这让我很意外,只能感谢了!
- 本人大数据和 Ansible 刚看,只会皮毛的皮毛。但是也因为这样的契机促使了我写这篇文章。
- 因为刚入门,需要了解细节,所以没用 Ambari 这类工具,已经熟悉的可以考虑使用。
- 希望对你们有帮助。
- 需要对 Linux 环境,流计算的一些基础概念有基础了解,比如:Source、Sink、YARN、Zookeeper、Kafka、Ansible 等
- 如果有欠缺,可以查看本系列文章:点击我
- 统计 滑动窗口 下的流过的数据量(count)
- 业务数据格式:
{
"id": 1,
"name": "test",
"phone": "18074546423",
"city": "Beijing",
"time": "2017-12-22 10:00:00"
}
- 4 台 8C32G 服务器 CentOS 7.5,内存推荐 16G 或以上。
- 为了方便,所有服务器都已经关闭防火墙,并且在云服务上设置安全组对外开通所有端口
- 全程 root 用户
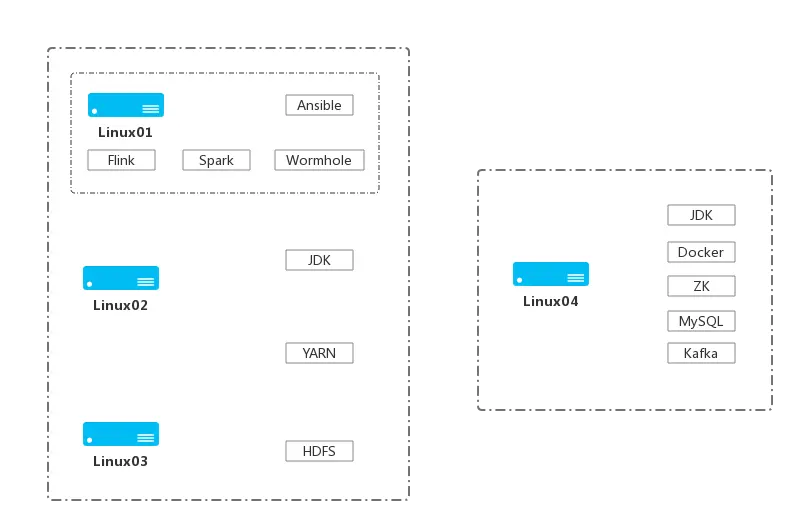
- 整体部署结构图:
- 给对应服务器设置 hostname,方便后面使用:
hostnamectl --static set-hostname linux01
hostnamectl --static set-hostname linux02
hostnamectl --static set-hostname linux03
hostnamectl --static set-hostname linux04
- 给所有服务器设置 hosts:
vim /etc/hosts
172.16.0.55 linux01
172.16.0.92 linux02
172.16.0.133 linux03
172.16.0.159 linux04
- 在 linux01 生成密钥对,设置 SSH 免密登录
生产密钥对
ssh-keygen -t rsa
公钥内容写入 authorized_keys
cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
测试:
ssh localhost
将公钥复制到其他机子
ssh-copy-id -i ~/.ssh/id_rsa.pub -p 22 root@linux02(根据提示输入 linux02 密码)
ssh-copy-id -i ~/.ssh/id_rsa.pub -p 22 root@linux03(根据提示输入 linux03 密码)
ssh-copy-id -i ~/.ssh/id_rsa.pub -p 22 root@linux04(根据提示输入 linux04 密码)
在 linux01 上测试
ssh linux01
ssh linux02
ssh linux03
ssh linux04
- 安装基础软件:
yum install -y zip unzip lrzsz git epel-release wget htop deltarpm
- 安装 Ansible:
yum install -y ansible
- 配置 Inventory 编辑配置文件:
vim /etc/ansible/hosts
- 在文件尾部补上如下内容
[hadoop-host]
linux01
linux02
linux03
[kafka-host]
linux04
- 测试 Ansible:
ansible all -a 'ps',必须保证能得到如下结果:
linux01 | CHANGED | rc=0 >>
PID TTY TIME CMD
11088 pts/7 00:00:00 sh
11101 pts/7 00:00:00 python
11102 pts/7 00:00:00 ps
linux02 | CHANGED | rc=0 >>
PID TTY TIME CMD
10590 pts/1 00:00:00 sh
10603 pts/1 00:00:00 python
10604 pts/1 00:00:00 ps
linux03 | CHANGED | rc=0 >>
PID TTY TIME CMD
10586 pts/1 00:00:00 sh
10599 pts/1 00:00:00 python
10600 pts/1 00:00:00 ps
linux04 | CHANGED | rc=0 >>
PID TTY TIME CMD
10574 pts/1 00:00:00 sh
10587 pts/1 00:00:00 python
10588 pts/1 00:00:00 ps
- 创建脚本文件:
vim /opt/install-basic-playbook.yml
- hosts: all
remote_user: root
tasks:
- name: Disable SELinux at next reboot
selinux:
state: disabled
- name: disable firewalld
command: "{{ item }}"
with_items:
- systemctl stop firewalld
- systemctl disable firewalld
- name: install-basic
command: "{{ item }}"
with_items:
- yum install -y zip unzip lrzsz git epel-release wget htop deltarpm
- name: install-vim
shell: "{{ item }}"
with_items:
- yum install -y vim
- curl https://raw.githubusercontent.com/wklken/vim-for-server/master/vimrc > ~/.vimrc
- name: install-docker
shell: "{{ item }}"
with_items:
- yum install -y yum-utils device-mapper-persistent-data lvm2
- yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
- yum makecache fast
- yum install -y docker-ce
- systemctl start docker.service
- docker run hello-world
- name: install-docker-compose
shell: "{{ item }}"
with_items:
- curl -L https://github.com/docker/compose/releases/download/1.18.0/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose
- chmod +x /usr/local/bin/docker-compose
- docker-compose --version
- systemctl restart docker.service
- systemctl enable docker.service
- 执行命令:
ansible-playbook /opt/install-basic-playbook.yml
- 百度云打包下载(提取码:8tm3):https://pan.baidu.com/s/1hJa-wdxGSjG_z1SS8Qt2cg
- 版本:
- jdk-8u191-linux-x64.tar.gz
- zookeeper-3.4.13(Docker)
- kafka_2.11-0.10.2.2.tgz
- hadoop-2.6.5.tar.gz
- flink-1.5.1-bin-hadoop26-scala_2.11.tgz
- spark-2.2.0-bin-hadoop2.6.tgz
- mysql-3.7(Docker)
- wormhole-0.6.0-beta.tar.gz
- 端口
- 将 linux01 下的 JDK 压缩包复制到所有机子的 /opt 目录下:
scp -r /opt/jdk-8u191-linux-x64.tar.gz root@linux02:/opt
scp -r /opt/jdk-8u191-linux-x64.tar.gz root@linux03:/opt
scp -r /opt/jdk-8u191-linux-x64.tar.gz root@linux04:/opt
- 在 linux01 创建脚本文件:
vim /opt/jdk8-playbook.yml
- hosts: all
remote_user: root
tasks:
- name: copy jdk
copy: src=/opt/jdk-8u191-linux-x64.tar.gz dest=/usr/local
- name: tar jdk
shell: cd /usr/local && tar zxf jdk-8u191-linux-x64.tar.gz
- name: set JAVA_HOME
blockinfile:
path: /etc/profile
marker: "#{mark} JDK ENV"
block: |
JAVA_HOME=/usr/local/jdk1.8.0_191
JRE_HOME=$JAVA_HOME/jre
PATH=$PATH:$JAVA_HOME/bin
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export JAVA_HOME
export JRE_HOME
export PATH
export CLASSPATH
- name: source profile
shell: source /etc/profile
- 执行命令:
ansible-playbook /opt/jdk8-playbook.yml
- 经过试验,发现还是要自己再手动:
source /etc/profile,原因未知。
- Hadoop 集群(HDFS,YARN)(linux01、linux02、linux03):
2.6.5
- Hadoop 环境可以用脚本文件,剩余部分内容请参考上文手工操作:
vim /opt/hadoop-playbook.yml
- hosts: hadoop-host
remote_user: root
tasks:
- name: Creates directory
file:
path: /data/hadoop/hdfs/name
state: directory
- name: Creates directory
file:
path: /data/hadoop/hdfs/data
state: directory
- name: Creates directory
file:
path: /data/hadoop/hdfs/tmp
state: directory
- name: set HADOOP_HOME
blockinfile:
path: /etc/profile
marker: "#{mark} HADOOP ENV"
block: |
HADOOP_HOME=/usr/local/hadoop
HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_CONF_DIR
export YARN_CONF_DIR
export HADOOP_HOME
export PATH
- name: source profile
shell: source /etc/profile
- 执行命令:
ansible-playbook /opt/hadoop-playbook.yml
- 剩余内容较多,具体参考:点击我
- 解压压缩包:
tar zxvf hadoop-2.6.5.tar.gz
- 这里最好把目录重命名下:
mv /usr/local/hadoop-2.6.5 /usr/local/hadoop
- 剩下内容从:修改 linux01 配置,开始阅读
- 须安装在 linux01
- Flink 单点(linux01):
1.5.1
- 拷贝:
cd /usr/local/ && cp /opt/flink-1.5.1-bin-hadoop26-scala_2.11.tgz .
- 解压:
tar zxf flink-*.tgz
- 修改目录名:
mv /usr/local/flink-1.5.1 /usr/local/flink
- 修改配置文件:
vim /usr/local/flink/conf/flink-conf.yaml
- 在文件最前加上:
env.java.home: /usr/local/jdk1.8.0_191
- 启动:
cd /usr/local/flink && ./bin/start-cluster.sh
- 停止:
cd /usr/local/flink && ./bin/stop-cluster.sh
- 查看日志:
tail -300f log/flink-*-standalonesession-*.log
- 浏览器访问 WEB 管理:
http://linux01:8081/
- yarn 启动
- 先停止下本地模式
- 测试控制台启动:
cd /usr/local/flink && ./bin/yarn-session.sh -n 2 -jm 2024 -tm 2024
- 有可能会报:
The Flink Yarn cluster has failed,可能是资源不够,需要调优内存相关参数
- Zookeeper 单点(linux04):
3.4.13
- 单个实例:
docker run -d --restart always --name one-zookeeper -p 2181:2181 -v /etc/localtime:/etc/localtime zookeeper:3.4.13
- Kafka 单点(linux04):
0.10.2.2
- 上传压缩包到 /opt 目录下
- 拷贝压缩包:
cd /usr/local && cp /opt/kafka_2.11-0.10.2.2.tgz .
- 解压:
tar zxvf kafka_2.11-0.10.2.2.tgz
- 删除压缩包并重命名目录:
rm -rf kafka_2.11-0.10.2.2.tgz && mv /usr/local/kafka_2.11-0.10.2.2 /usr/local/kafka
- 修改 kafka-server 的配置文件:
vim /usr/local/kafka/config/server.properties
034 行:listeners=PLAINTEXT://0.0.0.0:9092
039 行:advertised.listeners=PLAINTEXT://linux04:9092
119 行:zookeeper.connect=linux04:2181
补充 :auto.create.topics.enable=true
- 启动 kafka 服务(必须制定配置文件):
cd /usr/local/kafka && bin/kafka-server-start.sh config/server.properties
- 后台方式运行 kafka 服务:
cd /usr/local/kafka && bin/kafka-server-start.sh -daemon config/server.properties
- 停止 kafka 服务:
cd /usr/local/kafka && bin/kafka-server-stop.sh
- 再开一个终端测试:
- 创建 topic 命令:
cd /usr/local/kafka && bin/kafka-topics.sh --create --zookeeper linux04:2181 --replication-factor 1 --partitions 1 --topic my-topic-test
- 查看 topic 命令:
cd /usr/local/kafka && bin/kafka-topics.sh --list --zookeeper linux04:2181
- 删除 topic:
cd /usr/local/kafka && bin/kafka-topics.sh --delete --topic my-topic-test --zookeeper linux04:2181
- 给 topic 发送消息命令:
cd /usr/local/kafka && bin/kafka-console-producer.sh --broker-list linux04:9092 --topic my-topic-test,然后在出现交互输入框的时候输入你要发送的内容
- 再开一个终端,进入 kafka 容器,接受消息:
cd /usr/local/kafka && bin/kafka-console-consumer.sh --bootstrap-server linux04:9092 --topic my-topic-test --from-beginning
- 此时发送的终端输入一个内容回车,接受消息的终端就可以收到。
- MySQL 单点(linux04):
5.7
- 创建本地数据存储 + 配置文件目录:
mkdir -p /data/docker/mysql/datadir /data/docker/mysql/conf /data/docker/mysql/log
- 在宿主机上创建一个配置文件:
vim /data/docker/mysql/conf/mysql-1.cnf,内容如下:
[mysql]
default-character-set = utf8
[mysqld]
pid-file = /var/run/mysqld/mysqld.pid
socket = /var/run/mysqld/mysqld.sock
datadir = /var/lib/mysql
symbolic-links=0
log-error=/var/log/mysql/error.log
default-storage-engine = InnoDB
collation-server = utf8_unicode_ci
init_connect = 'SET NAMES utf8'
character-set-server = utf8
lower_case_table_names = 1
max_allowed_packet = 50M
- 赋权(避免挂载的时候,一些程序需要容器中的用户的特定权限使用):
chmod -R 777 /data/docker/mysql/datadir /data/docker/mysql/log
- 赋权:
chown -R 0:0 /data/docker/mysql/conf
docker run -p 3306:3306 --name one-mysql -v /data/docker/mysql/datadir:/var/lib/mysql -v /data/docker/mysql/log:/var/log/mysql -v /data/docker/mysql/conf:/etc/mysql/conf.d -e MYSQL_ROOT_PASSWORD=aaabbb123456 -d mysql:5.7- 连上容器:
docker exec -it one-mysql /bin/bash
- 连上 MySQL:
mysql -u root -p
- 创建表:
CREATE DATABASE wormhole DEFAULT CHARACTER SET utf8 COLLATE utf8_unicode_ci;
- 确保用 sqlyog 能直接在外网连上,方便后面调试
- 须安装在 linux01
- Spark 单点(linux01):
2.2.0
- 上传压缩包到 /opt 目录下
- 拷贝压缩包:
cd /usr/local && cp /opt/spark-2.2.0-bin-hadoop2.6.tgz .
- 解压:
tar zxvf spark-2.2.0-bin-hadoop2.6.tgz
- 重命名:
mv /usr/local/spark-2.2.0-bin-hadoop2.6 /usr/local/spark
- 增加环境变量:
vim /etc/profile
SPARK_HOME=/usr/local/spark
PATH=$PATH:${SPARK_HOME}/bin:${SPARK_HOME}/sbin
export SPARK_HOME
export PATH
source /etc/profile
- 修改配置:
cp $SPARK_HOME/conf/spark-env.sh.template $SPARK_HOME/conf/spark-env.sh
- 修改配置:
vim $SPARK_HOME/conf/spark-env.sh
- 假设我的 hadoop 路径是:/usr/local/hadoop,则最尾巴增加:
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
- Elasticsearch(支持版本 5.x)(非必须,若无则无法查看 wormhole 处理数据的吞吐和延时)
- Grafana (支持版本 4.x)(非必须,若无则无法查看 wormhole 处理数据的吞吐和延时的图形化展示)
- 须安装在 linux01
- wormhole 单点(linux01):
0.6.0-beta,2018-12-06 版本
- 先在 linux04 机子的 kafka 创建 topic:
cd /usr/local/kafka && bin/kafka-topics.sh --list --zookeeper linux04:2181
cd /usr/local/kafka && bin/kafka-topics.sh --create --zookeeper linux04:2181 --replication-factor 1 --partitions 1 --topic source
cd /usr/local/kafka && bin/kafka-topics.sh --create --zookeeper linux04:2181 --replication-factor 1 --partitions 1 --topic wormhole_feedback
cd /usr/local/kafka && bin/kafka-topics.sh --create --zookeeper linux04:2181 --replication-factor 1 --partitions 1 --topic wormhole_heartbeat
- 上传压缩包到 /opt 目录下
- 拷贝压缩包:
cd /usr/local && cp /opt/wormhole-0.6.0-beta.tar.gz .
- 解压:
cd /usr/local && tar -xvf wormhole-0.6.0-beta.tar.gz
- 修改配置文件:
vim /usr/local/wormhole-0.6.0-beta/conf/application.conf
akka.http.server.request-timeout = 120s
wormholeServer {
cluster.id = "" #optional global uuid
host = "linux01"
port = 8989
ui.default.language = "Chinese"
token.timeout = 1
token.secret.key = "iytr174395lclkb?lgj~8u;[=L:ljg"
admin.username = "admin" #default admin user name
admin.password = "admin" #default admin user password
}
mysql = {
driver = "slick.driver.MySQLDriver$"
db = {
driver = "com.mysql.jdbc.Driver"
user = "root"
password = "aaabbb123456"
url = "jdbc:mysql://linux04:3306/wormhole?useUnicode=true&characterEncoding=UTF-8&useSSL=false"
numThreads = 4
minConnections = 4
maxConnections = 10
connectionTimeout = 3000
}
}
#ldap = {
# enabled = false
# user = ""
# pwd = ""
# url = ""
# dc = ""
# read.timeout = 3000
# read.timeout = 5000
# connect = {
# timeout = 5000
# pool = true
# }
#}
spark = {
wormholeServer.user = "root" #WormholeServer linux user
wormholeServer.ssh.port = 22 #ssh port, please set WormholeServer linux user can password-less login itself remote
spark.home = "/usr/local/spark"
yarn.queue.name = "default" #WormholeServer submit spark streaming/job queue
wormhole.hdfs.root.path = "hdfs://linux01/wormhole" #WormholeServer hdfslog data default hdfs root path
yarn.rm1.http.url = "linux01:8088" #Yarn ActiveResourceManager address
yarn.rm2.http.url = "linux01:8088" #Yarn StandbyResourceManager address
}
flink = {
home = "/usr/local/flink"
yarn.queue.name = "default"
feedback.state.count=100
checkpoint.enable=false
checkpoint.interval=60000
stateBackend="hdfs://linux01/flink-checkpoints"
feedback.interval=30
}
zookeeper = {
connection.url = "linux04:2181" #WormholeServer stream and flow interaction channel
wormhole.root.path = "/wormhole" #zookeeper
}
kafka = {
brokers.url = "linux04:9092"
zookeeper.url = "linux04:2181"
topic.refactor = 1
using.cluster.suffix = false #if true, _${cluster.id} will be concatenated to consumer.feedback.topic
consumer = {
feedback.topic = "wormhole_feedback"
poll-interval = 20ms
poll-timeout = 1s
stop-timeout = 30s
close-timeout = 20s
commit-timeout = 70s
wakeup-timeout = 60s
max-wakeups = 10
session.timeout.ms = 60000
heartbeat.interval.ms = 50000
max.poll.records = 1000
request.timeout.ms = 80000
max.partition.fetch.bytes = 10485760
}
}
#kerberos = {
# keyTab="" #the keyTab will be used on yarn
# spark.principal="" #the principal of spark
# spark.keyTab="" #the keyTab of spark
# server.config="" #the path of krb5.conf
# jaas.startShell.config="" #the path of jaas config file which should be used by start.sh
# jaas.yarn.config="" #the path of jaas config file which will be uploaded to yarn
# server.enabled=false #enable wormhole connect to Kerberized cluster
#}
# choose monitor method among ES、MYSQL
monitor ={
database.type="MYSQL"
}
#Wormhole feedback data store, if doesn't want to config, you will not see wormhole processing delay and throughput
#if not set, please comment it
#elasticSearch.http = {
# url = "http://localhost:9200"
# user = ""
# password = ""
#}
#display wormhole processing delay and throughput data, get admin user token from grafana
#garfana should set to be anonymous login, so you can access the dashboard through wormhole directly
#if not set, please comment it
#grafana = {
# url = "http://localhost:3000"
# admin.token = "jihefouglokoj"
#}
#delete feedback history data on time
maintenance = {
mysql.feedback.remain.maxDays = 7
elasticSearch.feedback.remain.maxDays = 7
}
#Dbus integration, support serveral DBus services, if not set, please comment it
#dbus = {
# api = [
# {
# login = {
# url = "http://localhost:8080/keeper/login"
# email = ""
# password = ""
# }
# synchronization.namespace.url = "http://localhost:8080/keeper/tables/riderSearch"
# }
# ]
#}
- Instance 用于绑定各个组件的所在服务连接
- 一般我们都会选择 Kafka 作为 source,后面的基础也是基于 Kafka 作为 Source 的场景
- 假设填写实例名:
source_kafka
- URL:
linux04:9092
- 各个组件的具体数据库、Topic 等信息
- 假设填写 Topic Name:
source
- Partition:1
- wormhole 抽象出来的概念
- 用于数据分类
- 假设填写 Tables:
ums_extension id
- 配置 schema,记得配置上 ums_ts
{
"id": 1,
"name": "test",
"phone": "18074546423",
"city": "Beijing",
"time": "2017-12-22 10:00:00"
}
- 假设填写实例名:
sink_mysql
- URL:
linux04:3306
- 假设填写 Database Name:
sink
- config 参数:
useUnicode=true&characterEncoding=UTF-8&useSSL=false&rewriteBatchedStatements=true
- Stream 是在 Project 内容页下才能创建
- 一个 Stream 可以有多个 Flow
- 并且是 Project 下面的用户才能创建,admin 用户没有权限
- 要删除 Project 必须先进入 Project 内容页删除所有 Stream 之后 admin 才能删除 Project
- 新建 Stream
- Stream type 类型选择:
Flink
- 假设填写 Name:
wormhole_stream_test
- 假设 Flow name 为:
wormhole_flow_test
- Flow 是在 Project 内容页下才能创建
- 并且是 Project 下面的用户才能创建,admin 用户没有权限
- Flow 会关联 source 和 sink
- 要删除 Project 必须先进入 Project 内容页删除所有 Stream 之后 admin 才能删除 Project
- 基于 Stream 新建 Flow
- Pipeline
- Transformation
- Confirmation
- 注意:Stream 处于 running 状态时,才可以启动 Flow
- 在 linux04 机子上
cd /usr/local/kafka/bin && ./kafka-console-producer.sh --broker-list linux04:9092 --topic source --property "parse.key=true" --property "key.separator=@@@"- 发送 UMS 流消息协议规范格式:
data_increment_data.kafka.source_kafka.source.ums_extension.*.*.*@@@{"id": 1, "name": "test1", "phone":"18074546423", "city": "Beijing", "time": "2017-12-22 10:01:00"}
data_increment_data.kafka.source_kafka.source.ums_extension.*.*.*@@@{"id": 2, "name": "test2", "phone":"18074546423", "city": "Beijing", "time": "2017-12-22 10:02:00"}
data_increment_data.kafka.source_kafka.source.ums_extension.*.*.*@@@{"id": 3, "name": "test3", "phone":"18074546423", "city": "Beijing", "time": "2017-12-22 10:03:00"}
data_increment_data.kafka.source_kafka.source.ums_extension.*.*.*@@@{"id": 4, "name": "test4", "phone":"18074546423", "city": "Beijing", "time": "2017-12-22 10:04:00"}
data_increment_data.kafka.source_kafka.source.ums_extension.*.*.*@@@{"id": 5, "name": "test5", "phone":"18074546423", "city": "Beijing", "time": "2017-12-22 10:05:00"}
data_increment_data.kafka.source_kafka.source.ums_extension.*.*.*@@@{"id": 6, "name": "test6", "phone":"18074546423", "city": "Beijing", "time": "2017-12-22 10:06:00"}
data_increment_data.kafka.source_kafka.source.ums_extension.*.*.*@@@{"id": 7, "name": "test7", "phone":"18074546423", "city": "Beijing", "time": "2017-12-22 10:07:00"}
data_increment_data.kafka.source_kafka.source.ums_extension.*.*.*@@@{"id": 8, "name": "test8", "phone":"18074546423", "city": "Beijing", "time": "2017-12-22 10:08:00"}
data_increment_data.kafka.source_kafka.source.ums_extension.*.*.*@@@{"id": 9, "name": "test9", "phone":"18074546423", "city": "Beijing", "time": "2017-12-22 10:09:00"}
