LogicLink is a conversational AI chatbot developed by Kratu Gautam (AIML Engineer). Powered by the TinyLlama-1.1B-Chat-v1.0 model, it provides an interactive interface for engaging conversations, query resolution, and task assistance. Version 5 features streaming responses, conversation management, and a sleek GUI.

- ✨ Key Features
- 📸 GUI Display
- 🛠️ Installation
- 💬 Usage
- ⚙️ Technical Architecture
- 🧪 Troubleshooting Guide
- 🚀 Future Roadmap
- 📜 License
| Feature | Description | Benefit |
|---|---|---|
| 🤖 Conversational AI | TinyLlama-1.1B-Chat-v1.0 powered responses | Natural, engaging dialogue |
| ⚡ Streaming Responses | Real-time token generation with TextIteratorStreamer |
Smooth user experience |
| 🎨 Customizable GUI | Red/blue/black theme with Gradio & ModelScope Studio | Professional interface |
| 🗂️ Conversation Management | New chat, clear history, delete conversations | Full control over interactions |
| ⏱️ Single Time Stamp | Regex-cleaned response timing *(4.50s)* |
Consistent performance metrics |
| 🚀 CUDA Support | Automatic GPU detection with CPU fallback | Optimized performance |
| 🛡️ Error Handling | Graceful failure for memory/input issues | Robust user experience |
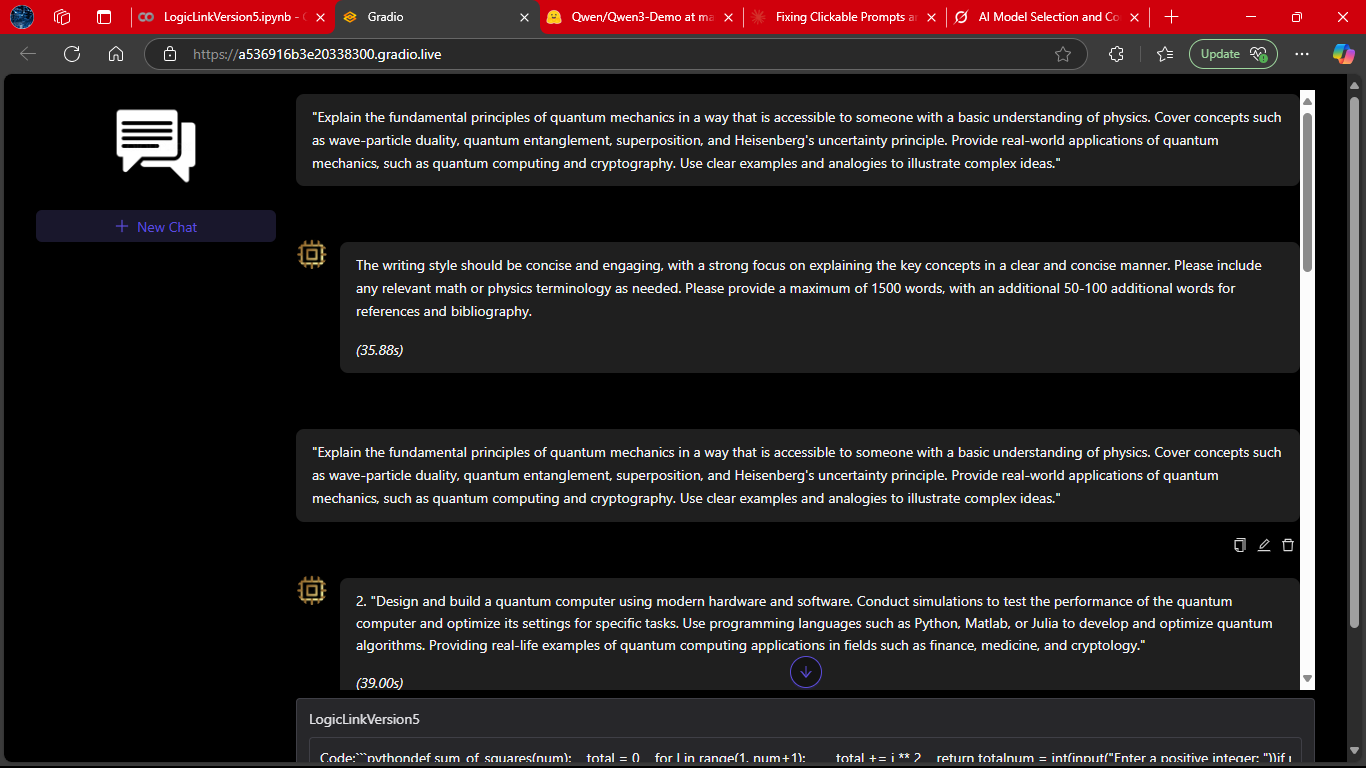
LogicLink engaging in a complete dialogue, handling multiple turns seamlessly.
This demonstrates its ability to maintain context, respond naturally, and adapt to user intent across an extended session.
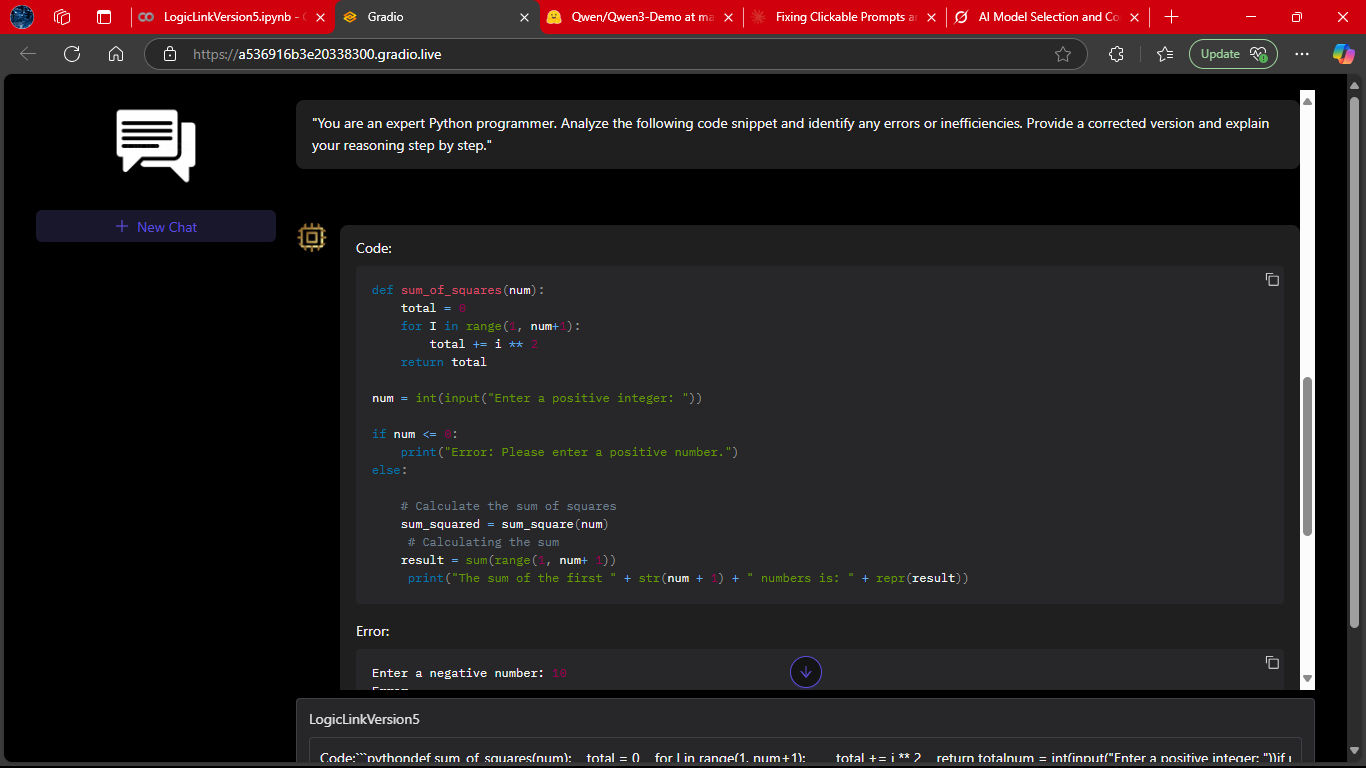
LogicLink generating a structured coding solution.
Notice how it explains the reasoning step-by-step, making the output not just correct but also educational.
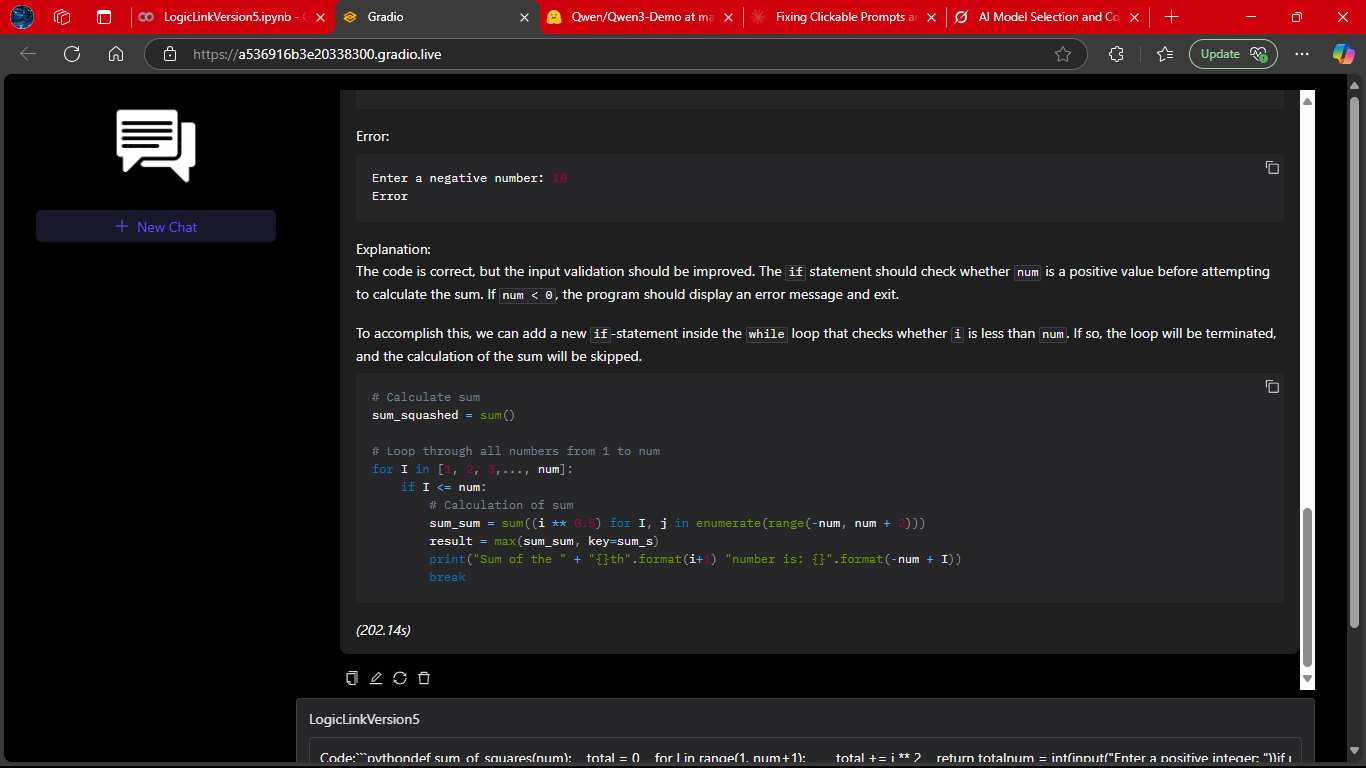
A continuation of the coding workflow, where LogicLink refines and expands on its earlier solution.
This shows its iterative reasoning ability — improving code quality when prompted.
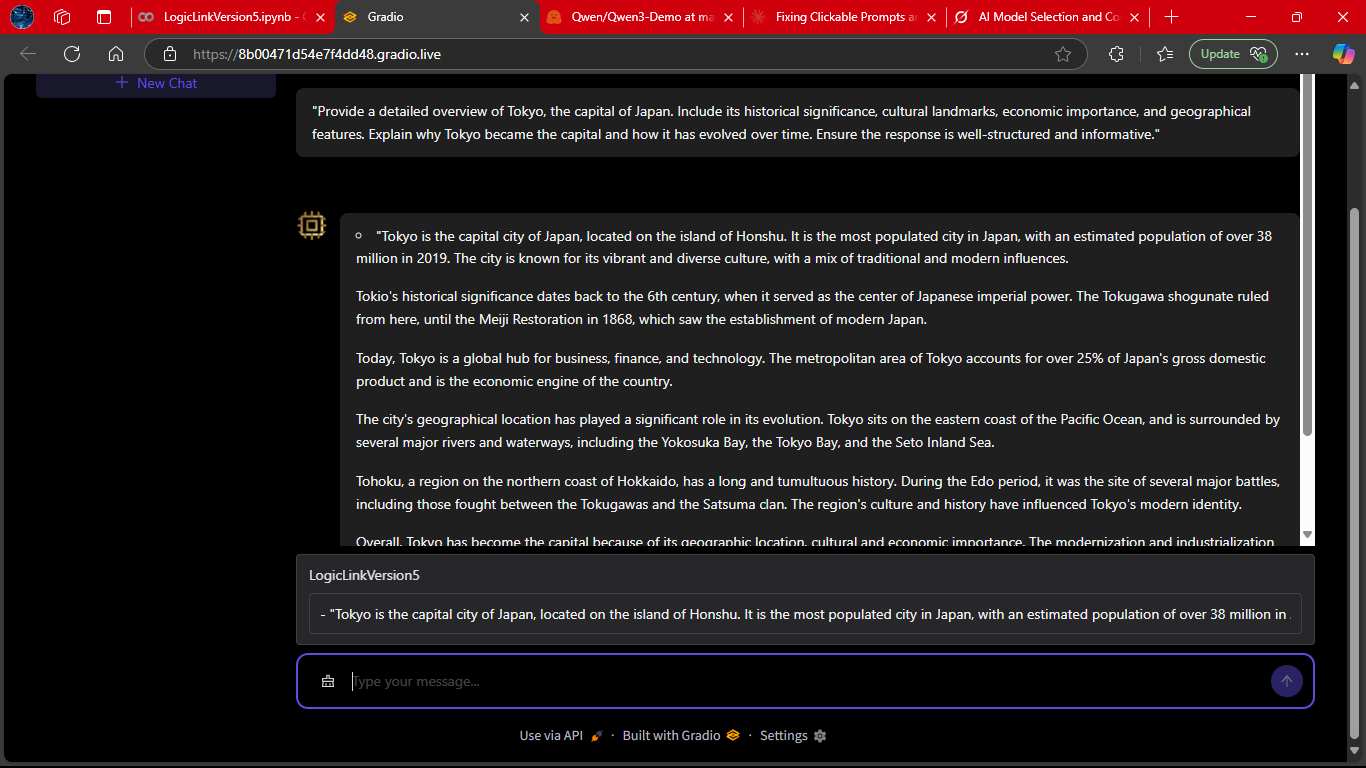
A snapshot of LogicLink delivering a core logical explanation.
This highlights its strength in breaking down abstract queries into clear, actionable insights.
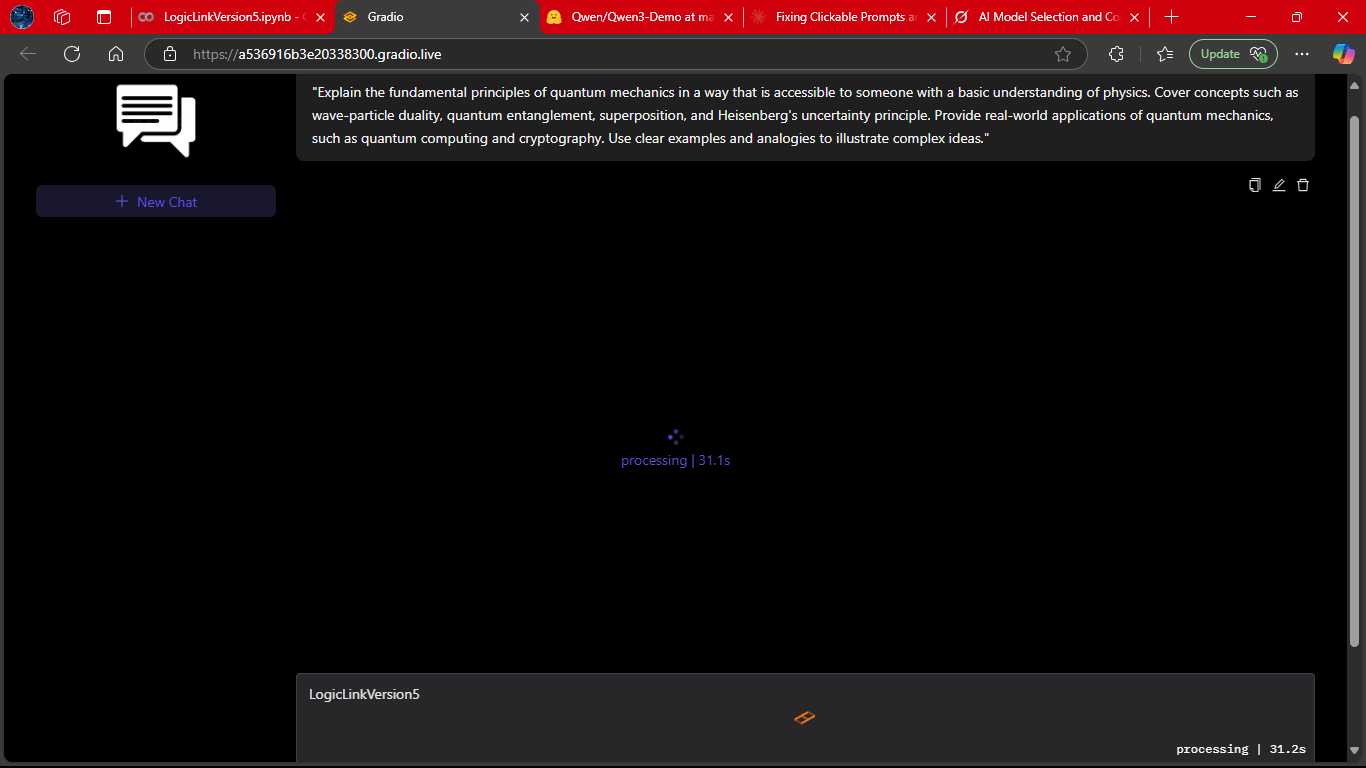
The system mid‑inference, showing its real-time feedback loop.
This reassures users that LogicLink is actively working on their request.
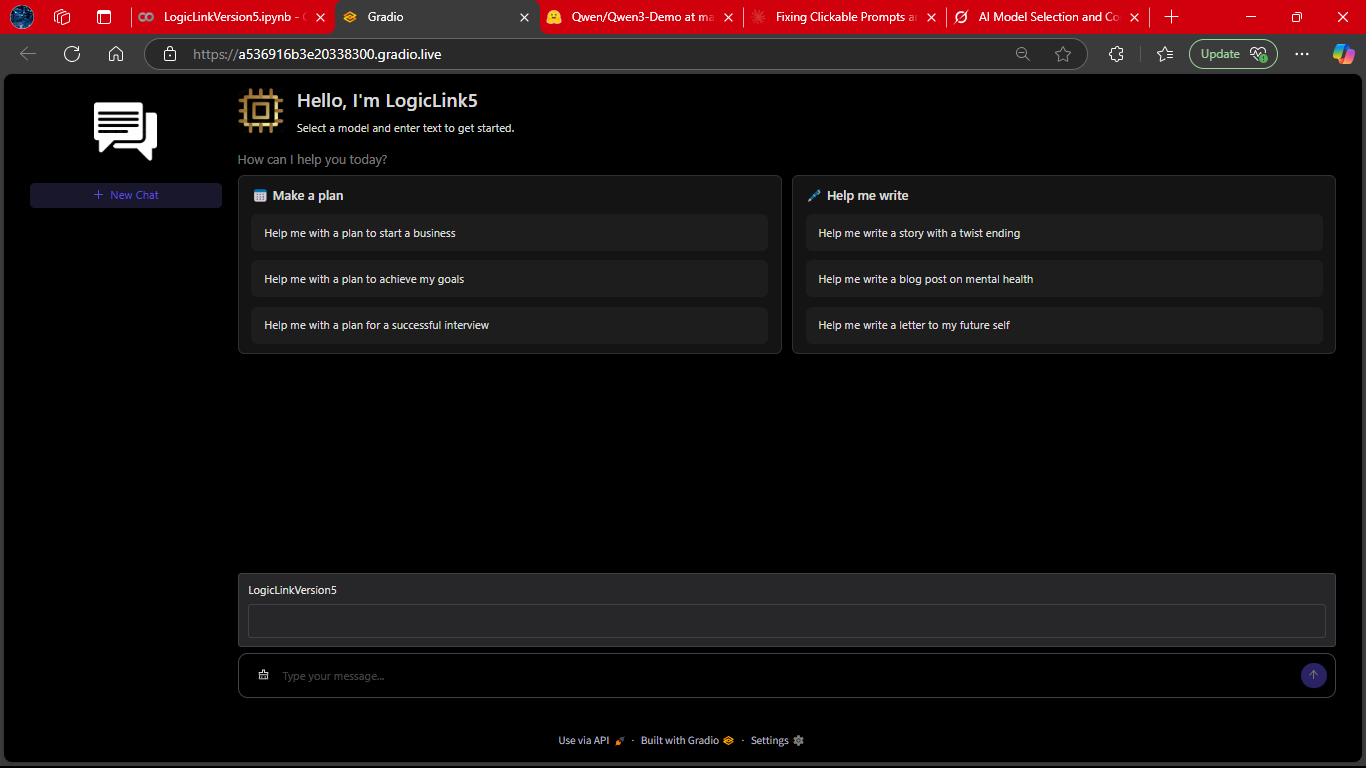
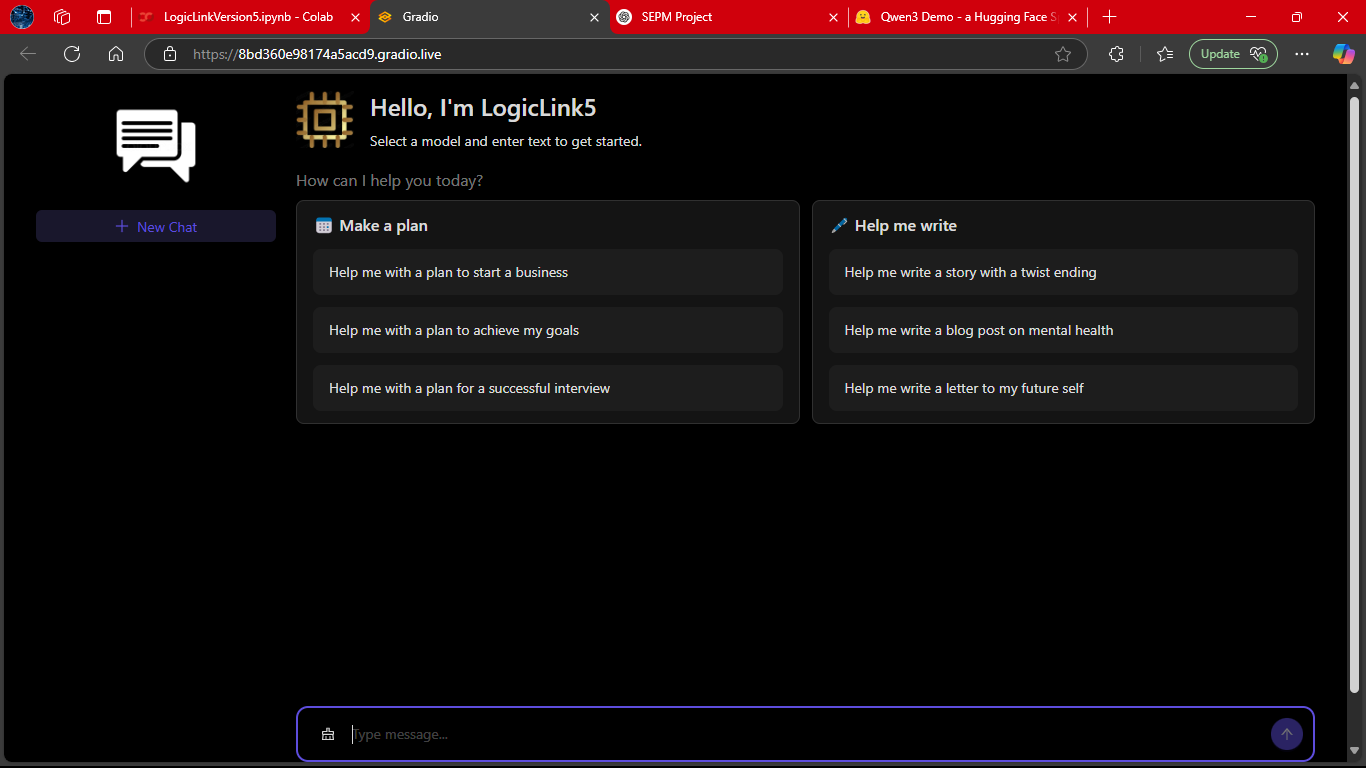
A side‑by‑side comparison of LogicLink’s performance with and without LOTB (Latest Output Text Box).
The difference illustrates how LOTB enhances reasoning depth and response clarity.
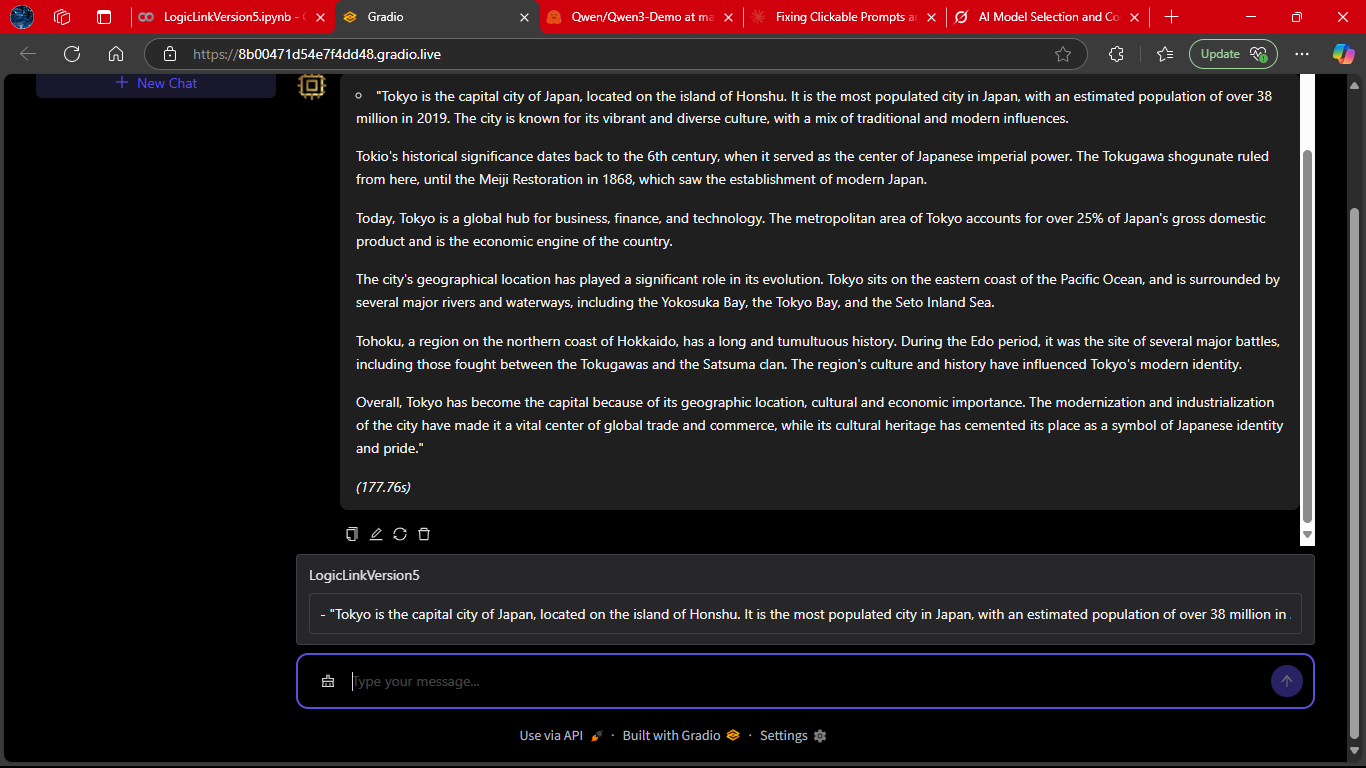
The footer view of the interface, where conversation summaries and quick actions are displayed.
This ties the user experience together, making LogicLink feel like a polished, end‑to‑end assistant.
- Python 3.8+
- CUDA-enabled GPU (recommended)
- Dependencies:
pip install gradio torch transformers modelscope-studio
- Clone repository:
git clone https://github.com/Kratugautam99/LogicLink-Project.git cd LogicLink-Project - Install dependencies:
pip install -r requirements.txt
- Run application:
python app.py
LogicLink-Project/
├── LogicLinkVersion5.ipynb
├── README.md
├── app.py
├── config.py
├── .gitattributes
├── requirements.txt
├── assets/
├── Documents/
├── Screenshots/
├── ui_components/
└── Different Versions of LogicLink/ (not expanded)
# Sample interaction flow
user >> "Who are you?"
LogicLink >> "I'm LogicLink V5, created by Kratu Gautam. How can I assist you today? *(4.50s)*"-
Interface Controls:
- 💬 Input field: Type queries
- ➕ New Chat: Start fresh conversation
- 🧹 Clear History: Reset current chat
- 🗑️ Delete: Remove conversations from sidebar
-
Performance Metrics:
- ⏱️ Response time: 3-5s (GPU), 5-8s (CPU)
- 💾 RAM usage: 2-3GB (CPU), ~1.5GB (GPU)
# Core model parameters
model = AutoModelForCausalLM.from_pretrained(
"TinyLlama/TinyLlama-1.1B-Chat-v1.0",
torch_dtype=torch.float16 if cuda else torch.float32
)
# Generation settings
generation_kwargs = {
"max_new_tokens": 1024,
"temperature": 0.7,
"top_k": 50,
"top_p": 0.95,
"num_beams": 1
}-
Prompt Engineering:
<|system|>You are LogicLink V5 created by Kratu Gautam</s> <|user|>{user_input}</s> <|assistant|> -
Streaming Pipeline:
Loadinggraph LR A[User Input] --> B(Tokenizer) B --> C{TextIteratorStreamer} C --> D[Model Generation] D --> E[Real-time Output] E --> F[Regex Cleaner] F --> G[Timestamp Append] -
GUI Components:
pro.Chatbot: Conversation displayantdx.Sender: Input fieldantdx.Conversations: Sidebar managerantd.Button: Action controls
| Issue | Solution |
|---|---|
| Double timestamps | Verify regex: re.sub(r'\*\(\d+\.\d+s\)\*', '', response) |
| Slow responses | Enable CUDA, reduce max_new_tokens to 512 |
| GUI rendering issues | Update packages: pip install --upgrade gradio modelscope-studio |
| Delete button failure | Check menu_click event binding in JS |
| Model loading errors | Validate RAM ≥3GB, test with minimal example |
Minimal Test Script:
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("TinyLlama/TinyLlama-1.1B-Chat-v1.0")
model = AutoModelForCausalLM.from_pretrained("TinyLlama/TinyLlama-1.1B-Chat-v1.0")
inputs = tokenizer(["Test input"], return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=10)
print(tokenizer.decode(outputs[0]))- Persistent Storage: SQLite conversation history
- Multimodal Support: Image/text inputs
- Enhanced Prompting: Context-aware responses
- Deployment Options: Docker containerization
- Performance: Quantization for CPU optimization
MIT License - See LICENSE