Home
skweak a versatile, Python-based software toolkit enabling NLP developers to apply weak supervision to a wide range of tasks, and in particular sequence labelling and text classification. Instead of labelling data points by hand, we define labelling functions to automatically annotate text documents from the target domain. The results of those labelling functions are then aggregated into one single annotation layer using a generative model.
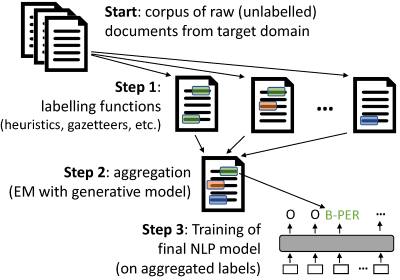
As shown above, weak supervision with skweak is divided in several steps:
-
Start: We must first prepare the(unlabelled) corpus onto which the labelling functions will be applied.
skweakis build on top of SpaCy, and operates with SpacyDocobjects, so you first need to convert your documents toDocobjects withspacy. - Step 1: We then define a range of labelling functions that will take those documents and annotate spans with labels. Those labelling functions can take a variety of forms, from handcrafted heuristics to machine learning models, gazetteers, etc.
-
Step 2: Once the labelling functions have been applied to your corpus, we aggregate their results in order to obtain a single, probabilistic annotation (instead of the multiple, possibly conflicting annotations from the labelling functions). This is done in
skweakusing a generative model that automatically estimates the relative accuracy and possible confuctions of each labelling function. - Step 3: Finally, based on those aggregated labels, we train our final model. Step 2 gives us a labelled corpus that (probabilistically) aggregates the outputs of all labelling functions, and you can use this labelled data to estimate any kind of machine learning model.
Labelling functions are at the core of skweak.
The generic class for all labelling functions is SpanAnnotator. An flexible way to create a labelling function is to create a child class of SpanAggregator, and implement the method find_spans(doc), like this:
class MoneyDetector(base.SpanAggregator):
def __init__(self):
super(MoneyDetector, self).__init__("money_detector")
def find_spans(self, doc):
for i, tok in enumerate(doc[1:]):
if tok.text[0].isdigit() and tok.nbor(-1).is_currency:
yield (i-1,i+1, "MONEY")
money_detector = MoneyDetector()If the function to apply is relatively simple and stateless, one can also use FunctionAnnotator to accomplish the same thing:
def money_detector_fun(doc):
for i, tok in enumerate(doc[1:]):
if tok.text[0].isdigit() and tok.nbor(-1).is_currency:
yield (i-1,i+1, "MONEY")
money_detector = heuristics.FunctionAnnotator("money_detector", money_detector_fun)In both cases, you can also specify a number of "incompatible labelling functions" (see to_exclude parameters) that should take precedence over the current function if their spans overlap with one another. For instance, if we were to add a function to detect entities of type CARDINAL, we may want to specify that we wish to skip numbers that were already labelled by money_detector, since the entity is then most likely a MONEY.
If you wish to apply skweak to text classification tasks (such as sentiment analysis), you create labelling functions in the exact same way: by creating spans associated with labels. The only difference is that the span corresponds to the full text you wish to classify (a sentence, a full document, etc.).