|
1 | 1 | (introduction)= |
2 | 2 | # Introduction |
3 | 3 |
|
4 | | -```{warning} |
5 | | -**This model is under active development. If you would like to chat about using the model please don't hesitate to reach out to [email protected] and [email protected] for support** |
6 | | -``` |
| 4 | +PyPSA-USA is an open-source tool that enables you to model and simulate the United States energy system with flexibility. |
7 | 5 |
|
8 | | -PyPSA-USA is an open-source energy system dataset of the United States energy system with continental US coverage. |
| 6 | +PyPSA-USA offers a versatile toolkit that allows you to customize the **data** for your energy system model with ease. Through a simple configuration file, you can control the spatial, temporal, and operational resolution of your model. Access a range of cleaned and prepared historical and forecasted data to build a model tailored to your needs. |
9 | 7 |
|
10 | | -PyPSA-USA provides you with a toolkit to customize the **data** of energy system model with ease. Through configuration file you can control the spatial, temporal, and operational resolution of your energy system model with access to cleaned and prepared historical and forecasted data. This means, you can build a model of **ERCOT, WECC, or the Eastern interconnection**, where the transmission network is clustered to **N# of user defined nodes**, which can respect the boundaries of **balancing areas, states, or REeDs GIS Shapes**, using **historical EIA-930 demand data years 2018-2023** OR **NREL EFS forcasted demand [2030, 2040, 2050]**, with **historical daily/monthly fuel prices from ISOs/EIA [choice of year]**, AND imported capital cost projections from the **NREL Annual Technology Baseline**. |
| 8 | +Whether you’re focusing on **ERCOT, WECC, or the Eastern Interconnection**, PyPSA-USA gives you the flexibility to: |
| 9 | +- Choose between multiple transmission networks. |
| 10 | +- Cluster the nodal network a user-defined number of nodes, respecting county lines, balancing areas, states, NERC region boundaries. |
| 11 | +- Utilize **historical EIA-930 demand data** (2018-2023) or **NREL EFS forecasted demand** (2030, 2040, 2050). |
| 12 | +- Incorporate **historical daily/monthly fuel prices** from ISOs/EIA for your chosen year. |
| 13 | +- Import cost projections from the **NREL Annual Technology Baseline** and **Annual Energy Outlook**. |
11 | 14 |
|
12 | | -You can create data model- and export to use in your own homebrewed optimization model via csv tables, or xarray netCDF model. |
| 15 | +You can create and export data models for use in your own optimization models via CSV tables or xarray netCDF formats. |
13 | 16 |
|
14 | | -Beyond creating a data model, PyPSA-USA also provides an interface for running capacity expansion planning and operational simulation models with DC power flow with the Python for Power System Analysis package. You can run expansion planning exercises which integrate regional and national policy constraints like RPS standards, emissions standards, PRMs, and more. |
| 17 | +PyPSA-USA also provides an interface for running capacity expansion planning and operational simulation models with the Python for Power System Analysis (pypsa) package. You can run expansion planning exercises which integrate regional and national policy constraints like RPS standards, emissions standards, PRMs, and more. |
15 | 18 |
|
16 | | -PyPSA-USA builds on and leverages the work of [PyPSA-EUR](https://pypsa-eur.readthedocs.io/en/latest/index.html) developed by TU Berlin. PyPSA-USA is actively developed by the [INES Research Group](https://ines.stanford.edu) at Stanford University and the [ΔE+ Research Group](https://www.sfu.ca/see/research/delta-e.html) at Simon Fraser University. |
| 19 | +PyPSA-USA builds on and leverages the work of [PyPSA-EUR](https://pypsa-eur.readthedocs.io/en/latest/index.html) developed by TU Berlin. It is actively developed by the [INES Research Group](https://ines.stanford.edu) at Stanford University and the [ΔE+ Research Group](https://www.sfu.ca/see/research/delta-e.html) at Simon Fraser University. We welcome contributions and collaborations from the community- please don't hesitate to reach out! |
17 | 20 |
|
18 | 21 | (workflow)= |
19 | 22 | ## Workflow |
20 | 23 |
|
| 24 | +The diagram below illustrates the workflow of PyPSA-USA, highlighting how the data flows through the model scripts. |
| 25 | + |
21 | 26 | 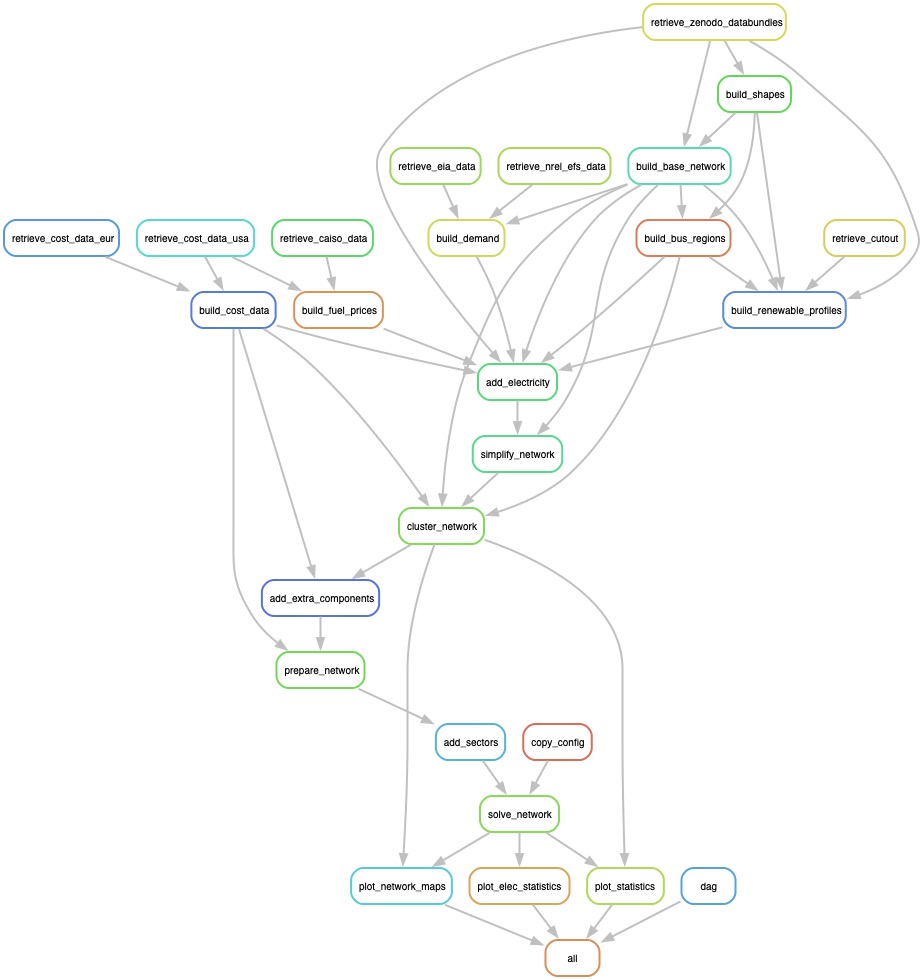 |
22 | 27 |
|
23 | 28 | (folder-structure)= |
24 | 29 | ## Folder Structure |
25 | 30 |
|
26 | | -The project is organized based on the folder structure below. The workflow folder contains all data and scripts neccesary to run the pypsa-usa model. After the first time you run the snakemake file, your directory will be built and populated with the associated data. Because most of the files are too large to store on github, we pull data from various sources into the `data` folder. The `repo_data` folder contains smaller files suitable for github. The resources folder contains intermediate files built by snakemake rules through the workflow. You'll see sub-folders created for each interconnection you run the model with. |
27 | | - |
28 | | -The envs folder contains the conda env yaml files neccesary to build your mamba/conda environment. The scripts folder contains the individual python scripts that are referenced in the Snakefile rules. |
| 31 | +PyPSA-USA is organized to facilitate easy navigation and efficient execution. Below is the folder structure of the project. Each folder serves a specific purpose, from environment setup to data processing and storage. After running the Snakemake file for the first time, your directory will be built and populated with the necessary data files. |
29 | 32 |
|
30 | 33 | ```bash |
31 | 34 | ├── .gitignore |
@@ -59,3 +62,8 @@ The envs folder contains the conda env yaml files neccesary to build your mamba/ |
59 | 62 | | │ └── example_data.csv |
60 | 63 | | └── Snakefile |
61 | 64 | ``` |
| 65 | + |
| 66 | + |
| 67 | +```{warning} |
| 68 | +**This model is under active development. If you need assistance or would like to discuss using the model, please reach out to [email protected] and [email protected].** |
| 69 | +``` |
0 commit comments