T5 fine-tuning for summarization decoder_input_ids and labels #15
Comments
|
|
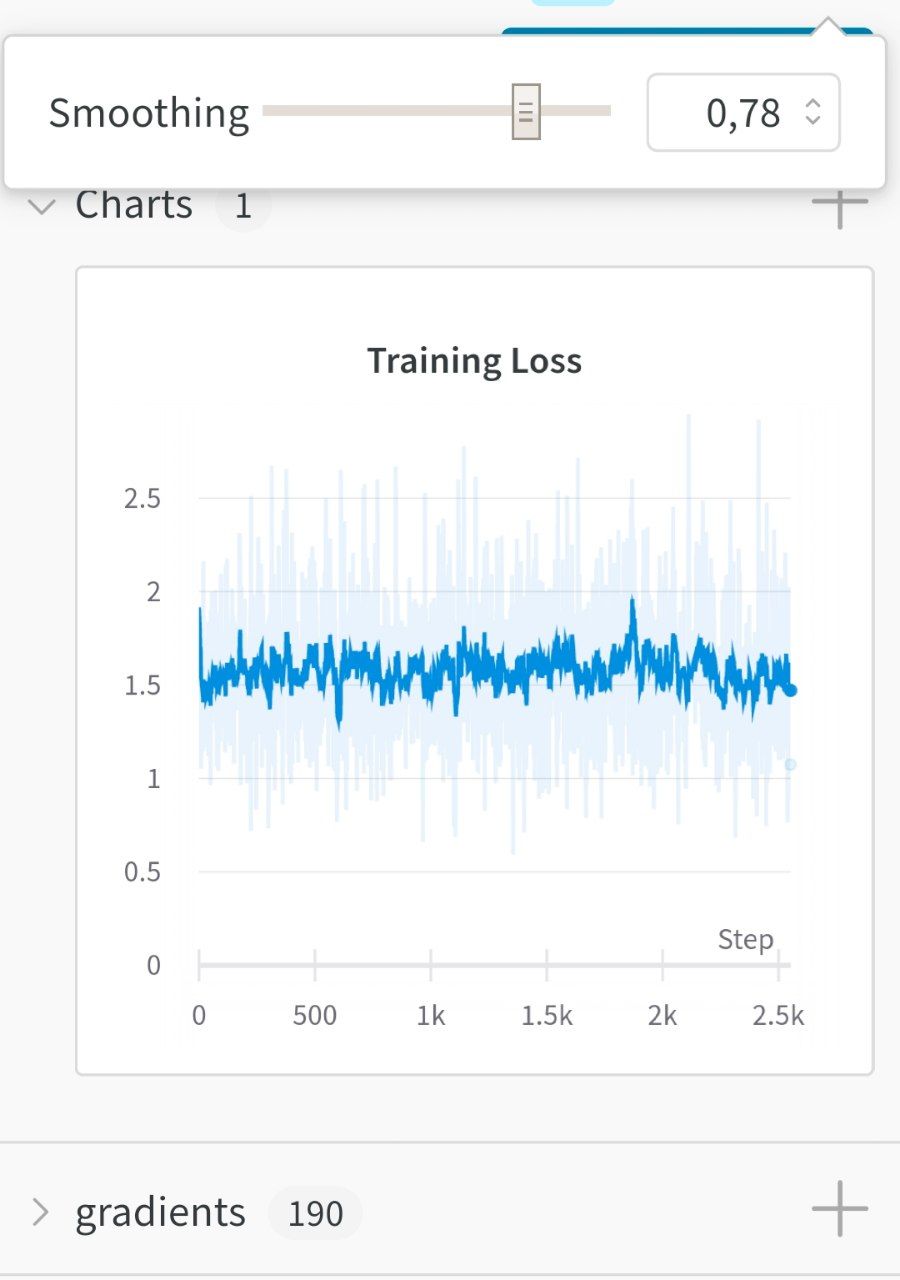
|
Hi @Gorodecki |
|
@Gorodecki , @marcoabrate : so far I have found this one useful: |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
hello @abhimishra91
i was trying to implement the fine tuning of T5 as explained in your notebook.
in addition to have implemented the same structure as you, i have made some experiments with the HuggingFace Trainer class. the
decoder_input_idsandlabelsparameters are not very clear to me. when you train the model, you do thiswhere
y_idsis thedecoder_input_ids. i don't understand why we need these preprocessing. i kindly ask you why are you skipping the last token of thetarget_ids, and why are you replacing the pads with -100 in thelabels?when i use the HuggingFace Trainer i need to tweak the
__getitem__function of the DataLoader like thisotherwise the loss function does not decrease over time.
thank you for your help!
The text was updated successfully, but these errors were encountered: