Một cụm lưu trữ từ ceph có thể bao gồm nhiều CEPH Node với độ mở rộng không giới hạn, cùng với đó là khả dụng cao và hiệu năng. CEPH deamon cung cấp khả năng tận dùng và quản lý các phần cứng trên máy chủ không chuyên dụng, cung cấp các khả năng như sử phần các phần cứng lưu trữ chuyên dụng - Truy nhập, truy xuất dữ liệu - Nén dữ liệu - Đảm bảo tính bền vững của dữ liệu bằng cách sử dụng cơ chế nhân bản hoặc sử dụng erasure coding , tương tự với chơ chế RAID 5 - Kiểm soát và báo cáo trạng thái của cụm, được gọi là heartbeating - Quản lý dữ liệu thông minh, cơ chế san bằng dữ liệu động , dược gọi là backfilling - Đảm bảo tính toàn vẹn dữ liệu và khả năng khôi phục sau lỗi
Đối với CEPH Client có thể truy xuất dữ liệu, CEPH Storage CLuster được xem như một "hồ chứa" để lưu trữ dữ liệu . Tuy nhiên với librados và storage cluster thực hiện nhiều tác vụ để các CEPH Client có thể truy xuất dữ liệu . CEPH Client và CEPH OSD sử dụng thuật toán CRUSH ( cơ chế kiểm soát nhân bản dữ liệu trên hệ thống mở rộng cao ).
-
CEPH Storage cluster lưu trữ các dối tượng dữ liệu lên một logical partion được gọi là Pool. CEPH Admin có thể khởi tạo các Pool này dựa vào từng loại data, có thể là block dewvice, object hoặc đơn giản để phân chia quyền các nhóm người dùng.
-
Với CEPH Client, làm việc với storage cluster sẽ được hiểu đơn giản. Khi một Client gửi yêu cầu truy xuất dữ liệu, nó luôn luôn kết nối đến một Storage Pool trong CEPH Storage Cluster. Client sẽ chỉ định Pool, Username và Secretkey, và pool sẽ được xuất hiện dưới dạng logical partion với khả năng quản lý các object.
-
Tuy nhiên trong thực tế, Pool không phải là một logical partion để lưu trữ các object, Pool chỉ là một đơn vị đảm nhiệm quản lý các dữ liệu được phân phối và lưu trữ lên Cluster, tuy nhiên quá trình hoạt động của Pool hoàn toàn tỏng suốt với các CLient, Pool sẽ là điểm cuối cho các Client làm việc .
- Pool type : Với các phiên bản đời đầu, CEPH chĩ đơn giản có thể duy trì số nhân bản của một object, truy nhiên hiện tại CEPH đã có thể quản lý và phân phối dược nhiều nhân bản của object và sử dụng cơ chế erasure coding. Pool type sẽ định nghĩa cách dữ liệu được đảm bảo tính bền dữ khi khởi tạo Pool. Sau khi khởi tạo Pool sẽ không thể thay đổi được Pool Type.
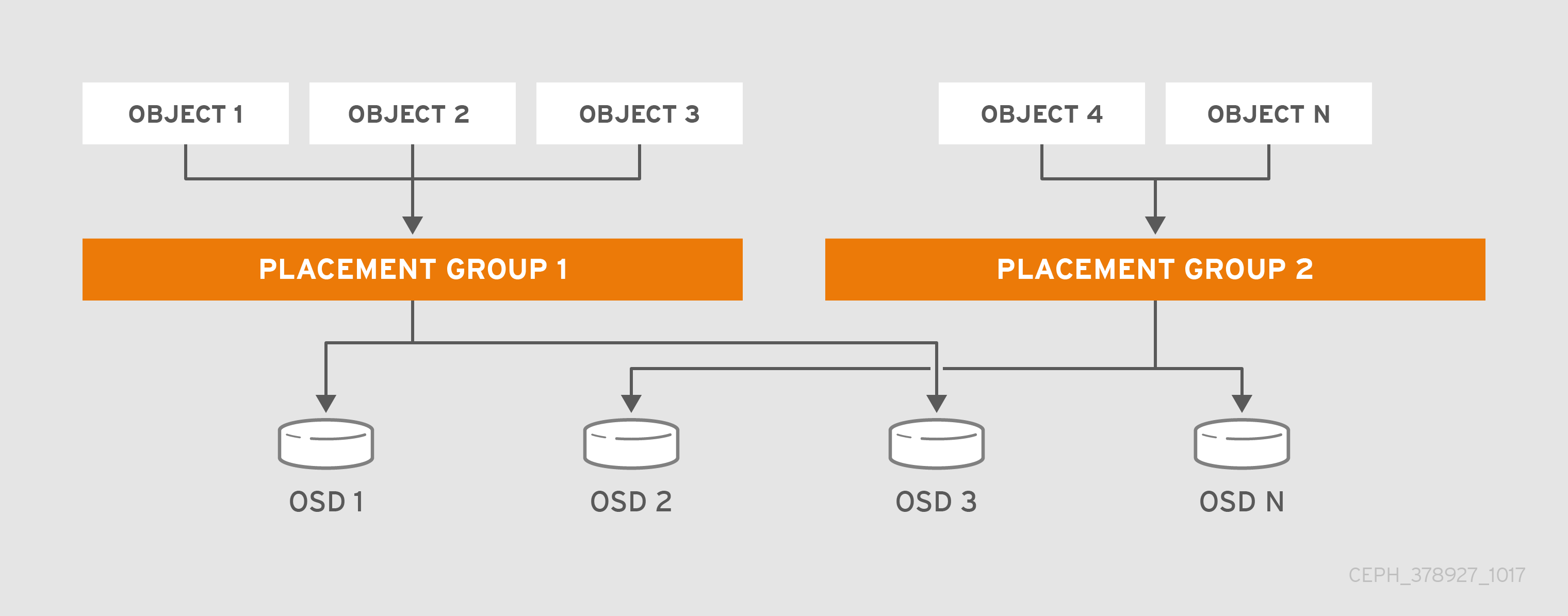
- Placment group : Với một cluster lớn, Một Pool có thể lưu trữ hàng triệu object. CEPH phải xử lý nhiều loại công việc bao gồm việc bền vững dữ liệu thông qua việc nhân bản và erasure code và toàn vẹn dữ liệu , cũng như cần bằng dữ liệu và khôi phục dữ liệu. Do khối lượng dữ liệu nhiều việc quản lý dữ liệu trên từng đối lượng thể khó trong việc kiểm soát và xẩy ra hiện tượng nghẽn cổ chai, cũng như khả năng mở rộng và hiệu năng. CEPH giải quyết hiện tượng nghẽn cổ chai này bằng cách ánh xạ một Pool vào nhiều nhóm Placement group. Thuật toán CRUSH sử dụng placement group để tính toán cách dữ liệu dữ liệu được lưu trữ và tính toán các OSD cho các Placment Group. CRUSH sẽ map mỗi object vào các placment group, và CRUSH sẽ lưu các placment group vào OSD.
- CRUSH Ruleset : CRUSH được sử dụng trong một chức năng quan trọng khác : CRUSH có thể xác định được failure domain và performance doamin . CRUSH có thể xác định các OSD bởi các class type và tổ chức các OSD này theo cơ chế phân cấp : nodfe, rack, row. CRUSH cho phép các CEPH OSD lưu trữ các bản copy của object thông qua các failure domain. Ví dụ một object có thể được copy thông qua các room , rack, node . Ngoài ra, CRUSH cho phép các client viết data trên các storage device cụ thể như SSD, HDD . Người quản trị có thể chỉ định Ruleset khi khởi tạo các Pool và không thể thay đổi Ruleset của một pool sau này.
- Durability : với một cluster có thể mở rộng đến hàng exabyte, việc phần cứng bị lỗi là không thể tránh khỏi. Khi một data object được sử dụng để khởi tạo một storage lớn như block device , việc mất một data object sẽ ảnh hướng đến tính toàn vẹn cảu các cả block, dẫn đến block không thể sử dụng. CEPH cunng cấp khả năng bền vững dữ liệu thứ nhất nhân bản dữ liệu bằng cách sử dụng CRUSH failure domain để sử dụng cơ chế phân tán dữ liệu sang các failure domain khác, thứ 2 là sử dụng erasure coded .
- Để xác thực người dùng và chống lại tấn công man-in-the-middle, CEPH sử dụng hệ thống xác thực cephx, dùng để xác thực người dùng và các daeamon.
- CEPHx sử dụng cơ chế share key để xác thực , có nghĩa cách client và montior đểu có chung một bản copy secret key của các client. Cơ chế này cho phép cả 2 đều chó một bản copy của key và không phải tiết lộ nó, bên cạnh đó cung cấp khả năng xác thực 2 chiều.
-
Lưu trữ hàng triệu object trên một cluster và quản lý riêng lẻ chúng kiến việc tốn tài nguyên và rất khó kiếm soát. Vì vậy CPEH sử dụng Placement groupo để việc quản lý các object này trở nên dễ đàng hơn.
-
Một PG dược xem là một subnet trong một Pool , và chứa hàng loạt Object. CEPH phân mảnh các Pool thành nhiều các PG và sau đó thuật toán CRUSH sẽ sử dụng cluster map để phân phối các PG trên các OSD.
-
Khi một người quản trị khởi tạo một POOL, CRUSH sẽ chỉ định số PG cho pool này. Ví dụ với 100 PG trên một OSD trên pool có nghĩa một PG sẽ chứa 1% dữ liệu của Pool.
-
Số PG sẽ có hiệu quả khi trong trừng hợp CEPH cần chuyển PG từ một OSD này sang OSD khác. Nếu số PG quá ít, số lượng data cần chuyển đồng thời sẽ cao gây ảnh hướng đến cluster network, nếu ố PG quá nhiều sẽ sử dụng lượng tài nguyên CPU và RAM quá nhiều ảnh hướng đến hiệu năng của cụm.
-
CEPH chống lại việc mất mát dữ liệu bằng việc luuw trữ các bản nhân hoặc sử dụng erasure code chunk của một object. Trong trường hợp sử dụng dụng cơ chế nhân bản hay erasure code chunks của một object trên một PG, CEPH nhân bản các PG trên một set các OSD dược gọi là "Acting Set", người quản trị có thể chỉ định được só PG trên OSD và số bản replica hoặc erasure code.