面向对象程序设计(Object Oriented Programming)
对象基于类创建,类相当于一个模板,对象就是根据模板创建出来的实体(就像做月饼,我们要做一个月饼首先需要一个模具,模具就是我们的类,而做出来的月饼,就是类的实现,也叫做对象),类是抽象的数据类型,并不能代表某一个具体的事物,类是对象的一个模板。类具有自己的属性,包括成员变量、成员方法等,我们可以调用类的成员方法来让类进行一些操作。
Scanner sc = new Scanner(System.in);
String str = sc.nextLine();
System.out.println("你输入了:"+str);
sc.close();所有的对象,都需要通过new关键字创建,基本数据类型不是对象!Java不是纯面对对象语言!
不是基本类型的变量,都是引用类型,引用类型变量代表一个对象,而基本数据类型变量,保存的是基本数据类型的值,我们可以通过引用来对对象进行操作。(最好不要理解为引用指向对象的地址,初学者不要谈内存,学到JVM时再来讨论)
对象占用的内存由JVM统一管理,不需要手动释放内存,当一个对象不再使用时(比如失去引用或是离开了作用域)会被JVM自动清理,内存管理更方便!
为了快速掌握,我们自己创建一个自己的类,创建的类文件名称应该和类名一致。
在类中,可以包含许多的成员变量,也叫成员属性,成员字段(field)通过.来访问我们类中的成员变量,我们可以通过类创建的对象来访问和修改这些变量。成员变量是属于对象的!
public class Test {
int age;
String name;
}
public static void main(String[] args) {
Test test = new Test();
test.name = "奥利给";
System.out.println(test.name);
}成员变量默认带有初始值,也可以自己定义初始值。
我们之前的学习中接触过方法(Method)吗?主方法!
public static void main(String[] args) {
//Body
}方法是语句的集合,是为了完成某件事情而存在的。完成某件事情,可以有结果,也可以做了就做了,不返回结果。比如计算两个数字的和,我们需要得到计算后的结果,所以说方法需要有返回值;又比如,我们只想吧数字打印在控制台,只需要打印就行,不用给我结果,所以说方法不需要有返回值。
在类中,我们可以定义自己的方法,格式如下:
[返回值类型] 方法名称([参数]){
//方法体
return 结果;
}- 返回值类型:可以是引用类型和基本类型,还可以是void,表示没有返回值
- 方法名称:和标识符的规则一致,和变量一样,规范小写字母开头!
- 参数:例如方法需要计算两个数的和,那么我们就要把两个数到底是什么告诉方法,那么它们就可以作为参数传入方法
- 方法体:方法具体要干的事情
- 结果:方法执行的结果通过return返回(如果返回类型为void,可以省略return)
非void方法中,return关键字不一定需要放在最后,但是一定要保证方法在任何情况下都具有返回值!
int test(int a){
if(a > 0){
//缺少retrun语句!
}else{
return 0;
}
}return也能用来提前结束整个方法,无论此时程序执行到何处,无论return位于哪里,都会立即结束个方法!
void main(String[] args) {
for (int i = 0; i < 10; i++) {
if(i == 1) return; //在循环内返回了!和break区别?
}
System.out.println("淦"); //还会到这里吗?
}传入方法的参数,如果是基本类型,会在调用方法的时候,对参数的值进行复制,方法中的参数变量,不是我们传入的变量本身!
public static void main(String[] args) {
int a = 10, b = 20;
new Test().swap(a, b);
System.out.println("a="+a+", b="+b);
}
public class Test{
void swap(int a, int b){ //传递的仅仅是值而已!
int temp = a;
a = b;
b = temp;
}
}传入方法的参数,如果是引用类型,那么传入的依然是该对象的引用!(类似于C语言的指针)
public class B{
String name;
}
public class A{
void test(B b){ //传递的是对象的引用,而不是值
System.out.println(b.name);
}
}
public static void main(String[] args) {
int a = 10, b = 20;
B b = new B();
b.name = "lbw";
new A().test(b);
System.out.println("a="+a+", b="+b);
}方法之间可以相互调用
void a(){
//xxxx
}
void b(){
a();
}当方法在自己内部调用自己时,称为递归调用(递归很危险,慎重!)
int a(){
return a();
}成员方法和成员变量一样,是属于对象的,只能通过对象去调用!
- 学生应该具有以下属性:名字、年龄
- 学生应该具有以下行为:学习、运动、说话
一个类中可以包含多个同名的方法,但是需要的形式参数不一样。(补充:形式参数就是定义方法需要的参数,实际参数就传入的参数)方法的返回类型,可以相同,也可以不同,但是仅返回类型不同,是不允许的!
public class Test {
int a(){ //原本的方法
return 1;
}
int a(int i){ //ok,形参不同
return i;
}
void a(byte i){ //ok,返回类型和形参都不同
}
void a(){ //错误,仅返回值类型名称不同不能重载
}
}现在我们就可以使用不同的参数,但是支持调用同样的方法,执行一样的逻辑:
public class Test {
int sum(int a, int b){ //只有int支持,不灵活!
return a+b;
}
double sum(double a, double b){ //重写一个double类型的,就支持小数计算了
return a+b;
}
}现在我们有很多种重写的方法,那么传入实参后,到底进了哪个方法呢?
public class Test {
void a(int i){
System.out.println("调用了int");
}
void a(short i){
System.out.println("调用了short");
}
void a(long i){
System.out.println("调用了long");
}
void a(char i){
System.out.println("调用了char");
}
void a(double i){
System.out.println("调用了double");
}
void a(float i){
System.out.println("调用了float");
}
public static void main(String[] args) {
Test test = new Test();
test.a(1); //直接输入整数
test.a(1.0); //直接输入小数
short s = 2;
test.a(s); //会对号入座吗?
test.a(1.0F);
}
}构造方法(构造器)没有返回值,也可以理解为,返回的是当前对象的引用!每一个类都默认自带一个无参构造方法。
//反编译结果
package com.test;
public class Test {
public Test() { //即使你什么都不编写,也自带一个无参构造方法,只是默认是隐藏的
}
}反编译其实就是把我们编译好的class文件变回Java源代码。
Test test = new Test(); //实际上存在Test()这个的方法,new关键字就是用来创建并得到引用的
// new + 你想要使用的构造方法这种方法没有写明返回值,但是每个类都必须具有这个方法!只有调用类的构造方法,才能创建类的对象!
类要在一开始准备的所有东西,都会在构造方法里面执行,完成构造方法的内容后,才能创建出对象!
一般最常用的就是给成员属性赋初始值:
public class Student {
String name;
Student(){
name = "伞兵一号";
}
}我们可以手动指定有参构造,当遇到名称冲突时,需要用到this关键字
public class Student {
String name;
Student(String name){ //形参和类成员变量冲突了,Java会优先使用形式参数定义的变量!
this.name = name; //通过this指代当前的对象属性,this就代表当前对象
}
}
//idea 右键快速生成!注意,this只能用于指代当前对象的内容,因此,只有属于对象拥有的部分才可以使用this,也就是说,只能在类的成员方法中使用this,不能在静态方法中使用this关键字。
在我们定义了新的有参构造之后,默认的无参构造会被覆盖!
//反编译后依然只有我们定义的有参构造!如果同时需要有参和无参构造,那么就需要用到方法的重载!手动再去定义一个无参构造。
public class Student {
String name;
Student(){
}
Student(String name){
this.name = name;
}
}成员变量的初始化始终在构造方法执行之前
public class Student {
String a = "sadasa";
Student(){
System.out.println(a);
}
public static void main(String[] args) {
Student s = new Student();
}
}静态变量和静态方法是类具有的属性(后面还会提到静态类、静态代码块),也可以理解为是所有对象共享的内容。我们通过使用static关键字来声明一个变量或一个方法为静态的,一旦被声明为静态,那么通过这个类创建的所有对象,操作的都是同一个目标,也就是说,对象再多,也只有这一个静态的变量或方法。那么,一个对象改变了静态变量的值,那么其他的对象读取的就是被改变的值。
public class Student {
static int a;
}
public static void main(String[] args) {
Student s1 = new Student();
s1.a = 10;
Student s2 = new Student();
System.out.println(s2.a);
}不推荐使用对象来调用,被标记为静态的内容,可以直接通过类名.xxx的形式访问
public static void main(String[] args) {
Student.a = 10;
System.out.println(Student.a);
}类并不是在一开始就全部加载好,而是在需要时才会去加载(提升速度)以下情况会加载类:
- 访问类的静态变量,或者为静态变量赋值
- new 创建类的实例(隐式加载)
- 调用类的静态方法
- 子类初始化时
- 其他的情况会在讲到反射时介绍
所有被标记为静态的内容,会在类刚加载的时候就分配,而不是在对象创建的时候分配,所以说静态内容一定会在第一个对象初始化之前完成加载。
public class Student {
static int a = test(); //直接调用静态方法,只能调用静态方法
Student(){
System.out.println("构造类对象");
}
static int test(){ //静态方法刚加载时就有了
System.out.println("初始化变量a");
return 1;
}
}思考:下面这种情况下,程序能正常运行吗?如果能,会输出什么内容?
public class Student {
static int a = test();
static int test(){
return a;
}
public static void main(String[] args) {
System.out.println(Student.a);
}
}定义和赋值是两个阶段,在定义时会使用默认值(上面讲的,类的成员变量会有默认值)定义出来之后,如果发现有赋值语句,再进行赋值,而这时,调用了静态方法,所以说会先去加载静态方法,静态方法调用时拿到a,而a这时仅仅是刚定义,所以说还是初始值,最后得到0
代码块在对象创建时执行,也是属于类的内容,但是它在构造方法执行之前执行(和成员变量初始值一样),且每创建一个对象时,只执行一次!(相当于构造之前的准备工作)
public class Student {
{
System.out.println("我是代码块");
}
Student(){
System.out.println("我是构造方法");
}
}静态代码块和上面的静态方法和静态变量一样,在类刚加载时就会调用;
public class Student {
static int a;
static {
a = 10;
}
public static void main(String[] args) {
System.out.println(Student.a);
}
}字符串类是一个比较特殊的类,他是Java中唯一重载运算符的类!(Java不支持运算符重载,String是特例)
String的对象直接支持使用+或+=运算符来进行拼接,并形成新的String对象!(String的字符串是不可变的!)
String a = "dasdsa", b = "dasdasdsa";
String l = a+b;
System.out.println(l);大量进行字符串的拼接似乎不太好,编译器是很聪明的,String的拼接有可能会被编译器优化为StringBuilder来减少对象创建(对象频繁创建时很费时间同时占内存的!)
String result="String"+"and"; //会被优化成一句!String str1="String";
String str2="and";
String result=str1+str2;
//变量随时可变,在编译时无法确定result的值,那么只能在运行时再去确定String str1="String";
String str2="and";
String result=(new StringBuilder(String.valueOf(str1))).append(str2).toString();
//使用StringBuilder,会采用类似于第一种实现,显然会更快!StringBuilder也是一个类,但是它能够存储可变长度的字符串!
StringBuilder builder = new StringBuilder();
builder
.append("a")
.append("bc")
.append("d"); //链式调用
String str = builder.toString();
System.out.println(str);包其实就是用来区分类位置的东西,也可以用来将我们的类进行分类,类似于C++中的namespace!
package com.test;
public class Test{
}包其实是文件夹,比如com.test就是一个com文件夹中包含一个test文件夹,再包含我们Test类。
一般包按照个人或是公司域名的规则倒过来写 顶级域名.一级域名.二级域名 com.java.xxxx
如果需要使用其他包里面的类,那么我们需要import(类似于C/C++中的include)
import com.test.Student;也可以导入包下的全部(一般导入会由编译器自带帮我们补全,但是一定要记得我们需要导包!)
import com.test.*Java默认为我们导入了以下的包,不需要去声明
import java.lang.*静态导入可以直接导入某个类的静态方法或者是静态变量,导入后,相当于这个方法或是类在定义在当前类中,可以直接调用该方法。
import static com.test.ui.Student.test;
public class Main {
public static void main(String[] args) {
test();
}
}静态导入不会进行类的初始化!
Java支持对类属性访问的保护,也就是说,不希望外部类访问类中的属性或是方法,只允许内部调用,这种情况下我们就需要用到权限控制符。

权限控制符可以声明在方法、成员变量、类前面,一旦声明private,只能类内部访问!
public class Student {
private int a = 10; //具有私有访问权限,只能类内部访问
}
public static void main(String[] args) {
Student s = new Student();
System.out.println(s.a); //还可以访问吗?
}和文件名称相同的类,只能是public,并且一个java文件中只能有一个public class!
// Student.java
public class Student {
}
class Test{ //不能添加权限修饰符!只能是default
}假设出现一种情况,我想记录100个数字,定义100个变量还可行吗?

我们可以使用到数组,数组是相同类型数据的有序集合。数组可以代表任何相同类型的一组内容(包括引用类型和基本类型)其中存放的每一个数据称为数组的一个元素,数组的下标是从0开始,也就是第一个元素的索引是0!
int[] arr = new int[10]; //需要new关键字来创建!
String[] arr2 = new String[10];数组本身也是类(编程不可见,C++写的),不是基本数据类型!
int[] arr = new int[10];
System.out.println(arr.length); //数组有成员变量!
System.out.println(arr.toString()); //数组有成员方法!一维数组中,元素是依次排列的(线性),每个数组元素可以通过下标来访问!声明格式如下:
类型[] 变量名称 = new 类型[数组大小];
类型 变量名称n = new 类型[数组大小]; //支持C语言样式,但不推荐!
类型[] 变量名称 = new 类型[]{...}; //静态初始化(直接指定值和大小)
类型[] 变量名称 = {...}; //同上,但是只能在定义时赋值
创建出来的数组每个元素都有默认值(规则和类的成员变量一样,C语言创建的数组需要手动设置默认值),我们可以通过下标去访问:
int[] arr = new int[10];
arr[0] = 626;
System.out.println(arr[0]);
System.out.println(arr[1]);我们可以通过数组变量名称.length来获取当前数组长度:
int[] arr = new int[]{1, 2, 3};
System.out.println(arr.length); //打印length成员变量的值数组在创建时,就固定长度,不可更改!访问超出数组长度的内容,会出现错误!
String[] arr = new String[10];
System.out.println(arr[10]); //出现异常!
//Exception in thread "main" java.lang.ArrayIndexOutOfBoundsException: 11
// at com.test.Application.main(Application.java:7)思考:能不能直接修改length的值来实现动态扩容呢?
int[] arr = new int[]{1, 2, 3};
arr.length = 10;数组做实参,因为数组也是类,所以形参得到的是数组的引用而不是复制的数组,操作的依然是数组对象本身
public static void main(String[] args) {
int[] arr = new int[]{1, 2, 3};
test(arr);
System.out.println(arr[0]);
}
private static void test(int[] arr){
arr[0] = 2934;
}如果我们想要快速打印数组中的每一个元素,又怎么办呢?
我们很容易就联想到for循环
int[] arr = new int[]{1, 2, 3};
for (int i = 0; i < arr.length; i++) {
System.out.println(arr[i]);
}传统for循环虽然可控性高,但是不够省事,要写一大堆东西,有没有一种省事的写法呢?
int[] arr = new int[]{1, 2, 3};
for (int i : arr) {
System.out.println(i);
}foreach属于增强型的for循环,它使得代码更简洁,同时我们能直接拿到数组中的每一个数字。
二维数组其实就是存放数组的数组,每一个元素都存放一个数组的引用,也就相当于变成了一个平面。

//三行两列
int[][] arr = { {1, 2},
{3, 4},
{5, 6}};
System.out.println(arr[2][1]);二维数组的遍历同一维数组一样,只不过需要嵌套循环!
int[][] arr = new int[][]{ {1, 2},
{3, 4},
{5, 6}};
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 2; j++) {
System.out.println(arr[i][j]);
}
}不止二维数组,还存在三维数组,也就是存放数组的数组的数组,原理同二维数组一样,逐级访问即可。
可变长参数其实就是数组的一种应用,我们可以指定方法的形参为一个可变长参数,要求实参可以根据情况动态填入0个或多个,而不是固定的数量
public static void main(String[] args) {
test("AAA", "BBB", "CCC"); //可变长,最后都会被自动封装成一个数组
}
private static void test(String... test){
System.out.println(test[0]); //其实参数就是一个数组
}由于是数组,所以说只能使用一种类型的可变长参数,并且可变长参数只能放在最后一位!
现在我们有一个数组,但是数组里面的数据是乱序排列的,如何使它变得有序?
int[] arr = {8, 5, 0, 1, 4, 9, 2, 3, 6, 7};排序是编程的一个重要技能,掌握排序算法,你的技术才能更上一层楼,很多的项目都需要用到排序!三大排序算法:
- 冒泡排序
冒泡排序就是冒泡,其实就是不断使得我们无序数组中的最大数向前移动,经历n轮循环逐渐将每一个数推向最前。
- 插入排序
插入排序其实就跟我们打牌是一样的,我们在摸牌的时候,牌堆是乱序的,但是我们一张一张摸到手中进行排序,使得它变成了有序的!

- 选择排序
选择排序其实就是每次都选择当前数组中最大的数排到最前面!
封装、继承和多态是面向对象编程的三大特性。
封装的目的是为了保证变量的安全性,使用者不必在意具体实现细节,而只是通过外部接口即可访问类的成员,如果不进行封装,类中的实例变量可以直接查看和修改,可能给整个代码带来不好的影响,因此在编写类时一般将成员变量私有化,外部类需要同getter和setter方法来查看和设置变量。
设想:学生小明已经创建成功,正常情况下能随便改他的名字和年龄吗?
public class Student {
private String name;
private int age;
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public int getAge() {
return age;
}
public String getName() {
return name;
}
}也就是说,外部现在只能通过调用我定义的方法来获取成员属性,而我们可以在这个方法中进行一些额外的操作,比如小明可以修改名字,但是名字中不能包含"小"这个字。
public void setName(String name) {
if(name.contains("小")) return;
this.name = name;
}单独给外部开放设置名称的方法,因为我还需要做一些额外的处理,所以说不能给外部直接操作成员变量的权限!
封装思想其实就是把实现细节给隐藏了,外部只需知道这个方法是什么作用,而无需关心实现。
封装就是通过访问权限控制来实现的。
继承属于非常重要的内容,在定义不同类的时候存在一些相同属性,为了方便使用可以将这些共同属性抽象成一个父类,在定义其他子类时可以继承自该父类,减少代码的重复定义,子类可以使用父类中非私有的成员。
现在学生分为两种,艺术生和体育生,他们都是学生的分支,但是他们都有自己的方法:
public class SportsStudent extends Student{ //通过extends关键字来继承父类
public SportsStudent(String name, int age) {
super(name, age); //必须先通过super关键字(指代父类),实现父类的构造方法!
}
public void exercise(){
System.out.println("我超勇的!");
}
}
public class ArtStudent extends Student{
public ArtStudent(String name, int age) {
super(name, age);
}
public void art(){
System.out.println("随手画个毕加索!");
}
}子类具有父类的全部属性,protected可见但外部无法使用(包括private属性,不可见,无法使用),同时子类还能有自己的方法。继承只能继承一个父类,不支持多继承!
每一个子类必须定义一个实现父类构造方法的构造方法,也就是需要在构造方法开始使用super(),如果父类使用的是默认构造方法,那么子类不用手动指明。
所有类都默认继承自Object类,除非手动指定类型,但是依然改变不了最顶层的父类是Object类。所有类都包含Object类中的方法,比如:
public static void main(String[] args) {
Object obj = new Object;
System.out.println(obj.hashCode()); //求对象的hashcode,默认是对象的内存地址
System.out.println(obj.equals(obj)); //比较对象是否相同,默认比较的是对象的内存地址,也就是等同于 ==
System.out.println(obj.toString()); //将对象转换为字符串,默认生成对象的类名称+hashcode
}关于Object类的其他方法,我们会在Java多线程中再来提及。
多态是同一个行为具有多个不同表现形式或形态的能力。也就是同样的方法,由于实现类不同,执行的结果也不同!
我们之前学习了方法的重载,方法的重写和重载是不一样的,重载是原有的方法逻辑不变的情况下,支持更多参数的实现,而重写是直接覆盖原有方法!
//父类中的study
public void study(){
System.out.println("学习");
}
//子类中的study
@Override //声明这个方法是重写的,但是可以不要,我们现阶段不接触
public void study(){
System.out.println("给你看点好康的");
}再次定义同样的方法后,父类的方法就被覆盖!子类还可以给父类方法提升访问权限!
public static void main(String[] args) {
SportsStudent student = new SportsStudent("lbw", 20);
student.study(); //输出子类定义的内容
}思考:静态方法能被重写吗?
当我们在重写方法时,不仅想使用我们自己的逻辑,同时还希望执行父类的逻辑(也就是调用父类的方法)怎么办呢?
public void study(){
super.study();
System.out.println("给你看点好康的");
}同理,如果想访问父类的成员变量,也可以使用super关键字来访问,注意,子类可以具有和父类相同的成员变量!而在方法中访问的默认是 形参列表中 > 当前类的成员变量 > 父类成员变量
public void setTest(int test){
test = 1;
this.test = 1;
super.test = 1;
}我们曾经学习过基本数据类型的类型转换,支持一种数据类型转换为另一种数据类型,而我们的类也是支持类型转换的(仅限于存在亲缘关系的类之间进行转换)比如子类可以直接向上转型:
Student student = new SportsStudent("lbw", 20); //父类变量引用子类实例
student.study(); //得到依然是具体实现的结果,而不是当前类型的结果我们也可以把已经明确是由哪个类实现的父类引用,强制转换为对应的类型:
Student student = new SportsStudent("lbw", 20); //是由SportsStudent进行实现的
//... do something...
SportsStudent ps = (SportsStudent)student; //让它变成一个具体的子类
ps.sport(); //调用具体实现类的方法这样的类型转换称为向下转型。
那么我们如果只是得到一个父类引用,但是不知道它到底是哪一个子类的实现怎么办?我们可以使用instanceof关键字来实现,它能够进行类型判断!
private static void test(Student student){
if (student instanceof SportsStudent){
SportsStudent sportsStudent = (SportsStudent) student;
sportsStudent.sport();
}else if (student instanceof ArtStudent){
ArtStudent artStudent = (ArtStudent) student;
artStudent.art();
}
}通过进行类型判断,我们就可以明确类的具体实现到底是哪个类!
思考:student instanceof Student的结果是什么?
我们目前只知道final关键字能够使得一个变量的值不可更改,那么如果在类前面声明final,会发生什么?
public final class Student { //类被声明为终态,那么它还能被继承吗
}类一旦被声明为终态,将无法再被继承,不允许子类的存在!而方法被声明为final呢?
public final void study(){ //还能重写吗
System.out.println("学习");
}如果类的成员属性被声明为final,那么必须在构造方法中或是在定义时赋初始值!
private final String name; //引用类型不允许再指向其他对象
private final int age; //基本类型值不允许发生改变
public Student(String name, int age) {
this.name = name;
this.age = age;
}学习完封装继承和多态之后,我们推荐在不会再发生改变的成员属性上添加final关键字,JVM会对添加了final关键字的属性进行优化!
类本身就是一种抽象,而抽象类,把类还要抽象,也就是说,抽象类可以只保留特征,而不保留具体呈现形态,比如方法可以定义好,但是我可以不去实现它,而是交由子类来进行实现!
public abstract class Student { //抽象类
public abstract void test(); //抽象方法
}通过使用abstract关键字来表明一个类是一个抽象类,抽象类可以使用abstract关键字来表明一个方法为抽象方法,也可以定义普通方法,抽象方法不需要编写具体实现(无方法体)但是必须由子类实现(除非子类也是一个抽象类)!
抽象类由于不是具体的类定义,因此无法直接通过new关键字来创建对象!
Student s = new Student(){ //只能直接创建带实现的匿名内部类!
public void test(){
}
}因此,抽象类一般只用作继承使用!抽象类使得继承关系之间更加明确:
public void study(){ //现在只能由子类编写,父类没有定义,更加明确了多态的定义!同一个方法多种实现!
System.out.println("给你看点好康的");
}接口甚至比抽象类还抽象,他只代表某个确切的功能!也就是只包含方法的定义,甚至都不是一个类!接口包含了一些列方法的具体定义,类可以实现这个接口,表示类支持接口代表的功能(类似于一个插件,只能作为一个附属功能加在主体上,同时具体实现还需要由主体来实现)
public interface Eat {
void eat();
}通过使用interface关键字来表明是一个接口(注意,这里class关键字被替换为了interface)接口只能包含public权限的抽象方法!(Java8以后可以有默认实现)我们可以通过声明default关键字来给抽象方法一个默认实现:
public interface Eat {
default void eat(){
//do something...
}
}接口中定义的变量,默认为public static final
public interface Eat {
int a = 1;
void eat();
}一个类可以实现很多个接口,但是不能理解为多继承!(实际上实现接口是附加功能,和继承的概念有一定出入,顶多说是多继承的一种替代方案)一个类可以附加很多个功能!
public class SportsStudent extends Student implements Eat, ...{
@Override
public void eat() {
}
}类通过implements关键字来声明实现的接口!每个接口之间用逗号隔开!
实现接口的类也能通过instanceof关键字判断,也支持向上和向下转型!
类中可以存在一个类!各种各样的长相怪异的代码就是从这里开始出现的!
我们的类中可以在嵌套一个类:
public class Test {
class Inner{ //类中定义的一个内部类
}
}成员内部类和成员变量和成员方法一样,都是属于对象的,也就是说,必须存在外部对象,才能创建内部类的对象!
public static void main(String[] args) {
Test test = new Test();
Test.Inner inner = test.new Inner(); //写法有那么一丝怪异,但是没毛病!
}静态内部类其实就和类中的静态变量和静态方法一样,是属于类拥有的,我们可以直接通过类名.去访问:
public class Test {
static class Inner{
}
}
public static void main(String[] args) {
Test.Inner inner = new Test.Inner(); //不用再创建外部类对象了!
}对,你没猜错,就是和局部变量一样哒~
public class Test {
public void test(){
class Inner{
}
Inner inner = new Inner();
}
}反正我是没用过!内部类 -> 累不累 -> 反正我累了!
匿名内部类才是我们的重点,也是实现lambda表达式的原理!匿名内部类其实就是在new的时候,直接对接口或是抽象类的实现:
public static void main(String[] args) {
Eat eat = new Eat() {
@Override
public void eat() {
//DO something...
}
};
}我们不用单独去创建一个类来实现,而是可以直接在new的时候写对应的实现!但是,这样写,无法实现复用,只能在这里使用!
读作λ表达式,它其实就是我们接口匿名实现的简化,比如说:
public static void main(String[] args) {
Eat eat = new Eat() {
@Override
public void eat() {
//DO something...
}
};
}
public static void main(String[] args) {
Eat eat = () -> {}; //等价于上述内容
}lambda表达式(匿名内部类)只能访问外部的final类型或是隐式final类型的局部变量!
为了方便,JDK默认就为我们提供了专门写函数式的接口,这里只介绍Consumer
假设现在我们想给小明添加一个状态(跑步、学习、睡觉),外部可以实时获取小明的状态:
public class Student {
private final String name;
private final int age;
private String status;
//...
public void setStatus(String status) {
this.status = status;
}
public String getStatus() {
return status;
}
}但是这样会出现一个问题,如果我们仅仅是存储字符串,似乎外部可以不按照我们规则,传入一些其他的字符串。这显然是不够严谨的!
有没有一种办法,能够更好地去实现这样的状态标记呢?我们希望开发者拿到使用的就是我们定义好的状态,我们可以使用枚举类!
public enum Status {
RUNNING, STUDY, SLEEP //直接写每个状态的名字即可,分号可以不打,但是推荐打上
}使用枚举类也非常方便,我们只需要直接访问即可
public class Student {
private final String name;
private final int age;
private Status status;
//...
public void setStatus(Status status) { //不再是String,而是我们指定的枚举类型
this.status = status;
}
public Status getStatus() {
return status;
}
}
public static void main(String[] args) {
Student student = new Student("小明", 18);
student.setStatus(Status.RUNNING);
System.out.println(student.getStatus());
}枚举类型使用起来就非常方便了,其实枚举类型的本质就是一个普通的类,但是它继承自Enum类,我们定义的每一个状态其实就是一个public static final的Status类型成员变量!
// Compiled from "Status.java"
public final class com.test.Status extends java.lang.Enum<com.test.Status> {
public static final com.test.Status RUNNING;
public static final com.test.Status STUDY;
public static final com.test.Status SLEEP;
public static com.test.Status[] values();
public static com.test.Status valueOf(java.lang.String);
static {};
}既然枚举类型是普通的类,那么我们也可以给枚举类型添加独有的成员方法
public enum Status {
RUNNING("睡觉"), STUDY("学习"), SLEEP("睡觉"); //无参构造方法被覆盖,创建枚举需要添加参数(本质就是调用的构造方法!)
private final String name; //枚举的成员变量
Status(String name){ //覆盖原有构造方法(默认private,只能内部使用!)
this.name = name;
}
public String getName() { //获取封装的成员变量
return name;
}
}
public static void main(String[] args) {
Student student = new Student("小明", 18);
student.setStatus(Status.RUNNING);
System.out.println(student.getStatus().getName());
}枚举类还自带一些继承下来的实用方法
Status.valueOf("") //将名称相同的字符串转换为枚举
Status.values() //快速获取所有的枚举Java并不是纯面向对象的语言,虽然Java语言是一个面向对象的语言,但是Java中的基本数据类型却不是面向对象的。在学习泛型和集合之前,基本类型的包装类是一定要讲解的内容!
我们的基本类型,如果想通过对象的形式去使用他们,Java提供的基本类型包装类,使得Java能够更好的体现面向对象的思想,同时也使得基本类型能够支持对象操作!

- byte -> Byte
- boolean -> Boolean
- short -> Short
- char -> Character
- int -> Integer
- long -> Long
- float -> Float
- double -> Double
包装类实际上就行将我们的基本数据类型,封装成一个类(运用了封装的思想)
private final int value; //Integer内部其实本质还是存了一个基本类型的数据,但是我们不能直接操作
public Integer(int value) {
this.value = value;
}现在我们操作的就是Integer对象而不是一个int基本类型了!
public static void main(String[] args) {
Integer i = 1; //包装类型可以直接接收对应类型的数据,并变为一个对象!
System.out.println(i + i); //包装类型可以直接被当做一个基本类型进行操作!
}那么为什么包装类型能直接使用一个具体值来赋值呢?其实依靠的是自动装箱和拆箱机制
Integer i = 1; //其实这里只是简写了而已
Integer i = Integer.valueOf(1); //编译后真正的样子调用valueOf来生成一个Integer对象!
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high) //注意,Java为了优化,有一个缓存机制,如果是在-128~127之间的数,会直接使用已经缓存好的对象,而不是再去创建新的!(面试常考)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i); //返回一个新创建好的对象
}而如果使用包装类来进行运算,或是赋值给一个基本类型变量,会进行自动拆箱:
public static void main(String[] args) {
Integer i = Integer.valueOf(1);
int a = i; //简写
int a = i.intValue(); //编译后实际的代码
long c = i.longValue(); //其他类型也有!
}既然现在是包装类型了,那么我们还能使用==来判断两个数是否相等吗?
public static void main(String[] args) {
Integer i1 = 28914;
Integer i2 = 28914;
System.out.println(i1 == i2); //实际上判断是两个对象是否为同一个对象(内存地址是否相同)
System.out.println(i1.equals(i2)); //这个才是真正的值判断!
}注意IntegerCache带来的影响!
思考:下面这种情况结果会是什么?
public static void main(String[] args) {
Integer i1 = 28914;
Integer i2 = 28914;
System.out.println(i1+1 == i2+1);
}在集合类的学习中,我们还会继续用到我们的包装类型!
虽然我们学习了编程,但是我们不能一股脑的所有问题都照着编程的思维去解决,编程只是解决问题的一种手段,灵活的运用我们所学的知识,才是解决问题的最好办法!比如,求1到100所有数的和:
public static void main(String[] args) {
int sum = 0;
for (int i = 1; i <= 100; i++) { //for循环暴力求解,简单,但是效率似乎低了一些
sum += i;
}
System.out.println(sum);
}
public static void main(String[] args) {
System.out.println((1 + 100) * 50); //高斯求和公式,利用数学,瞬间计算结果!
}说到最后,其实数学和逻辑思维才是解决问题的最终办法!
- 设计一个Person抽象类,包含吃饭运动学习三种行为,分为工人、学生、老师三种职业。
- 设计设计一个接口
考试,只有老师和学生会考试。 - 设计一个方法,模拟让人类进入考场,要求只有会考试的人才能进入,并且考试。
现在有一个有序数组(从小到大,数组长度 0 < n < 1000000)如何快速寻找我们想要的数在哪个位置,如果存在请返回下标,不存在返回-1即可。
int[] arr = new int[]{1, 4, 5, 6, 7, 10, 12, 14, 20, 22, 26}; //测试用例
private static int test(int[] arr, int target){
//请在这里实现搜索算法
}(开始之前先介绍一下递归!)快速排序其实是一种排序执行效率很高的排序算法,它利用分治法来对待排序序列进行分治排序,它的思想主要是通过一趟排序将待排记录分隔成独立的两部分,其中的一部分比关键字小,后面一部分比关键字大,然后再对这前后的两部分分别采用这种方式进行排序,通过递归的运算最终达到整个序列有序。
快速排序就像它的名字一样,快速!在极端情况下,会退化成冒泡排序!
给定 n 件物品,每一个物品的重量为 w[n],每个物品的价值为 v[n]。现挑选物品放入背包中,假定背包能承受的最大重量为 capacity,求装入物品的最大价值是多少?
int[] w = {2, 3, 4, 5};
int[] v = {3, 4, 5, 6};
int capacity = 8;在理想的情况下,我们的程序会按照我们的思路去运行,按理说是不会出现问题的,但是,代码实际编写后并不一定是完美的,可能会有我们没有考虑到的情况,如果这些情况能够正常得到一个错误的结果还好,但是如果直接导致程序运行出现问题了呢?
public static void main(String[] args) {
test(1, 0); //当b为0的时候,还能正常运行吗?
}
private static int test(int a, int b){
return a/b; //没有任何的判断而是直接做计算
}
Exception in thread "main" java.lang.ArithmeticException: / by zero
at com.test.Application.test(Application.java:9)
at com.test.Application.main(Application.java:5)当程序运行出现我们没有考虑到的情况时,就有可能出现异常或是错误!
我们在之前其实已经接触过一些异常了,比如数组越界异常,空指针异常,算术异常等,他们其实都是异常类型,我们的每一个异常也是一个类,他们都继承自Exception类!异常类型本质依然类的对象,但是异常类型支持在程序运行出现问题时抛出(也就是上面出现的红色报错)也可以提前声明,告知使用者需要处理可能会出现的异常!
异常的第一种类型是运行时异常,如上述的列子,在编译阶段无法感知代码是否会出现问题,只有在运行的时候才知道会不会出错(正常情况下是不会出错的),这样的异常称为运行时异常。所有的运行时异常都继承自RuntimeException。
异常的另一种类型是编译时异常,编译时异常是明确会出现的异常,在编译阶段就需要进行处理的异常(捕获异常)如果不进行处理,将无法通过编译!默认继承自Exception类的异常都是编译时异常。
File file = new File("my.txt");
file.createNewFile(); //要调用此方法,首先需要处理异常错误比异常更严重,异常就是不同寻常,但不一定会导致致命的问题,而错误是致命问题,一般出现错误可能JVM就无法继续正常运行了,比如OutOfMemoryError就是内存溢出错误(内存占用已经超出限制,无法继续申请内存了)
int[] arr = new int[Integer.MAX_VALUE]; //能创建如此之大的数组吗?运行后得到以下内容:
Exception in thread "main" java.lang.OutOfMemoryError: Requested array size exceeds VM limit
at com.test.Main.main(Main.java:14)错误都继承自Error类,一般情况下,程序中只能处理异常,错误是很难进行处理的,Error和Execption都继承自Throwable类。当程序中出现错误或异常时又没有进行处理时,程序(当前线程)将终止运行:
int[] arr = new int[Integer.MAX_VALUE];
System.out.println("lbwnb"); //还能正常打印吗?当程序没有按照我们想要的样子运行而出现异常时(默认会交给JVM来处理,JVM发现任何异常都会立即终止程序运行,并在控制台打印栈追踪信息),我们希望能够自己处理出现的问题,让程序继续运行下去,就需要对异常进行捕获,比如:
int[] arr = new int[5];
arr[5] = 1; //我们需要处理这种情况,保证后面的代码正常运行!
System.out.println("lbwnb");我们可以使用try和catch语句块来处理:
int[] arr = new int[5];
try{ //在try块中运行代码
arr[5] = 1; //当代码出现异常时,异常会被捕获,并在catch块中得到异常类型的对象
}catch (ArrayIndexOutOfBoundsException e){ //捕获的异常类型
System.out.println("程序运行出现异常!"); //出现异常时执行
}
//后面的代码会正常运行
System.out.println("lbwnb");当异常被捕获后,就由我们自己进行处理(不再交给JVM处理),因此就不会导致程序终止运行。
我们可以通过使用e.printStackTrace()来打印栈追踪信息,定位我们的异常出现位置:
java.lang.ArrayIndexOutOfBoundsException: 5
at com.test.Main.main(Main.java:7) //Main类的第7行出现问题
程序运行出现异常!
lbwnb运行时异常在编译时可以不用捕获,但是编译时异常必须进行处理:
File file = new File("my.txt");
try {
file.createNewFile();
} catch (IOException e) { //捕获声明的异常类型
e.printStackTrace();
}可以捕获到类型不止是Exception的子类,只要是继承自Throwalbe的类,都能被捕获,也就是说,Error也能被捕获,但是不建议这样做,因为错误一般是虚拟机相关的问题,出现Error应该从问题的根源去解决。
当别人调用我们的方法时,如果传入了错误的参数导致程序无法正常运行,这时我们就需要手动抛出一个异常来终止程序继续运行下去,同时告知上一级方法执行出现了问题:
public static void main(String[] args) {
try {
test(1, 0);
} catch (Exception e) { //捕获方法中会出现的异常
e.printStackTrace();
}
}
private static int test(int a, int b) throws Exception { //声明抛出的异常类型
if(b == 0) throw new Exception("0不能做除数!"); //创建异常对象并抛出异常
return a/b; //抛出异常会终止代码运行
}通过throw关键字抛出异常(抛出异常后,后面的代码不再执行)当程序运行到这一行时,就会终止执行,并出现一个异常。
如果方法中抛出了非运行时异常,但是不希望在此方法内处理,而是交给调用者来处理异常,就需要在方法定义后面显式声明抛出的异常类型!如果抛出的是运行时异常,则不需要在方法后面声明异常类型,调用时也无需捕获,但是出现异常时同样会导致程序终止(出现运行时异常同时未被捕获会默认交给JVM处理,也就是直接中止程序并在控制台打印栈追踪信息)
如果想要调用声明编译时异常的方法,但是依然不想去处理,可以同样的在方法上声明throws来继续交给上一级处理。
public static void main(String[] args) throws Exception { //出现异常就再往上抛,而不是在此方法内处理
test(1, 0);
}
private static int test(int a, int b) throws Exception { //声明抛出的异常类型
if(b == 0) throw new Exception("0不能做除数!"); //创建异常对象并抛出异常
return a/b;
}当main方法都声明抛出异常时,出现异常就由JVM进行处理,也就是默认的处理方式(直接中止程序并在控制台打印栈追踪信息)
异常只能被捕获一次,当异常捕获出现嵌套时,只会在最内层被捕获:
public static void main(String[] args) throws Exception {
try{
test(1, 0);
}catch (Exception e){
System.out.println("外层");
}
}
private static int test(int a, int b){
try{
if(b == 0) throw new Exception("0不能做除数!");
}catch (Exception e){
System.out.println("内层");
return 0;
}
return a/b;
}JDK为我们已经提前定义了一些异常了,但是可能对我们来说不够,那么就需要自定义异常:
public class MyException extends Exception { //直接继承即可
}
public static void main(String[] args) throws MyException {
throw new MyException(); //直接使用
}也可以使用父类的带描述的构造方法:
public class MyException extends Exception {
public MyException(String message){
super(message);
}
}
public static void main(String[] args) throws MyException {
throw new MyException("出现了自定义的错误");
}捕获异常指定的类型,会捕获其所有子异常类型:
try {
throw new MyException("出现了自定义的错误");
} catch (Exception e) { //捕获父异常类型
System.out.println("捕获到异常");
}当代码可能出现多种类型的异常时,我们希望能够分不同情况处理不同类型的异常,就可以使用多重异常捕获:
try {
//....
} catch (NullPointerException e) {
} catch (IndexOutOfBoundsException e){
} catch (RuntimeException e){
}注意,类似于if-else if的结构,父异常类型只能放在最后!
try {
//....
} catch (RuntimeException e){ //父类型在前,会将子类的也捕获
} catch (NullPointerException e) { //永远都不会被捕获
} catch (IndexOutOfBoundsException e){ //永远都不会被捕获
}如果希望把这些异常放在一起进行处理:
try {
//....
} catch (NullPointerException | IndexOutOfBoundsException e) { //用|隔开每种类型即可
}当我们希望,程序运行时,无论是否出现异常,都会在最后执行的任务,可以交给finally语句块来处理:
try {
//....
}catch (Exception e){
}finally {
System.out.println("lbwnb"); //无论是否出现异常,都会在最后执行
}try语句块至少要配合catch或finally中的一个:
try {
int a = 10;
a /= 0;
}finally { //不捕获异常,程序会终止,但在最后依然会执行下面的内容
System.out.println("lbwnb");
}思考:try、catch和finally执行顺序:
private static int test(int a){
try{
return a;
}catch (Exception e){
return 0;
}finally {
a = a + 1;
}
}为了统计学生成绩,要求设计一个Score对象,包括课程名称、课程号、课程成绩,但是成绩分为两种,一种是以优秀、良好、合格 来作为结果,还有一种就是 60.0、75.5、92.5 这样的数字分数,那么现在该如何去设计这样的一个Score类呢?现在的问题就是,成绩可能是String类型,也可能是Integer类型,如何才能很好的去存可能出现的两种类型呢?
public class Score {
String name;
String id;
Object score; //因为Object是所有类型的父类,因此既可以存放Integer也能存放String
public Score(String name, String id, Object score) {
this.name = name;
this.id = id;
this.score = score;
}
}以上的方法虽然很好地解决了多种类型存储问题,但是Object类型在编译阶段并不具有良好的类型判断能力,很容易出现以下的情况:
public static void main(String[] args) {
Score score = new Score("数据结构与算法基础", "EP074512", "优秀"); //是String类型的
//....
Integer number = (Integer) score.score; //获取成绩需要进行强制类型转换,虽然并不是一开始的类型,但是编译不会报错
}
//运行时出现异常!
Exception in thread "main" java.lang.ClassCastException: java.lang.String cannot be cast to java.lang.Integer
at com.test.Main.main(Main.java:14)使用Object类型作为引用,取值只能进行强制类型转换,显然无法在编译期确定类型是否安全,项目中代码量非常之大,进行类型比较又会导致额外的开销和增加代码量,如果不经比较就很容易出现类型转换异常,代码的健壮性有所欠缺!(此方法虽然可行,但并不是最好的方法)
为了解决以上问题,JDK1.5新增了泛型,它能够在编译阶段就检查类型安全,大大提升开发效率。
public class Score<T> { //将Score转变为泛型类<T>
String name;
String id;
T score; //T为泛型,根据用户提供的类型自动变成对应类型
public Score(String name, String id, T score) { //提供的score类型即为T代表的类型
this.name = name;
this.id = id;
this.score = score;
}
}public static void main(String[] args) {
//直接确定Score的类型是字符串类型的成绩
Score<String> score = new Score<String>("数据结构与算法基础", "EP074512", "优秀");
Integer i = score.score; //编译不通过,因为成员变量score类型被定为String!
}泛型将数据类型的确定控制在了编译阶段,在编写代码的时候就能明确泛型的类型!如果类型不符合,将无法通过编译!
泛型本质上也是一个语法糖(并不是JVM所支持的语法,编译后会转成编译器支持的语法,比如之前的foreach就是),在编译后会被擦除,变回上面的Object类型调用,但是类型转换由编译器帮我们完成,而不是我们自己进行转换(安全)
//反编译后的代码
public static void main(String[] args) {
Score score = new Score("数据结构与算法基础", "EP074512", "优秀");
String i = (String)score.score; //其实依然会变为强制类型转换,但是这是由编译器帮我们完成的
}像这样在编译后泛型的内容消失转变为Object的情况称为类型擦除(重要,需要完全理解),所以泛型只是为了方便我们在编译阶段确定类型的一种语法而已,并不是JVM所支持的。
综上,泛型其实就是一种类型参数,用于指定类型。
上一节我们已经提到泛型类的定义,实际上就是普通的类多了一个类型参数,也就是在使用时需要指定具体的泛型类型。泛型的名称一般取单个大写字母,比如T代表Type,也就是类型的英文单词首字母,当然也可以添加数字和其他的字符。
public class Score<T> { //将Score转变为泛型类<T>
String name;
String id;
T score; //T为泛型,根据用户提供的类型自动变成对应类型
public Score(String name, String id, T score) { //提供的score类型即为T代表的类型
this.name = name;
this.id = id;
this.score = score;
}
}在一个普通类型中定义泛型,泛型T称为参数化类型,在定义泛型类的引用时,需要明确指出类型:
Score<String> score = new Score<String>("数据结构与算法基础", "EP074512", "优秀");此时类中的泛型T已经被替换为String了,在我们获取此对象的泛型属性时,编译器会直接告诉我们类型:
Integer i = score.score; //编译不通过,因为成员变量score明确为String类型注意,泛型只能用于对象属性,也就是非静态的成员变量才能使用:
static T score; //错误,不能在静态成员上定义由此可见,泛型是只有在创建对象后编译器才能明确泛型类型,而静态类型是类所具有的属性,不足以使得编译器完成类型推断。
泛型无法使用基本类型,如果需要基本类型,只能使用基本类型的包装类进行替换!
Score<double> score = new Score<double>("数据结构与算法基础", "EP074512", 90.5); //编译不通过那么为什么泛型无法使用基本类型呢?回想上一节提到的类型擦除,其实就很好理解了。由于JVM没有泛型概念,因此泛型最后还是会被编译器编译为Object,并采用强制类型转换的形式进行类型匹配,而我们的基本数据类型和引用类型之间无法进行类型转换,所以只能使用基本类型的包装类来处理。
泛型方法的使用也很简单,我们只需要把它当做一个未知的类型来使用即可:
public T getScore() { //若方法的返回值类型为泛型,那么编译器会自动进行推断
return score;
}
public void setScore(T score) { //若方法的形式参数为泛型,那么实参只能是定义时的类型
this.score = score;
}Score<String> score = new Score<String>("数据结构与算法基础", "EP074512", "优秀");
score.setScore(10); //编译不通过,因为只接受String类型同样地,静态方法无法直接使用类定义的泛型(注意是无法直接使用,静态方法可以使用泛型)
那么如果我想在静态方法中使用泛型呢?首先我们要明确之前为什么无法使用泛型,因为之前我们的泛型定义是在类上的,只有明确具体的类型才能开始使用,也就是创建对象时完成类型确定,但是静态方法不需要依附于对象,那么只能在使用时再来确定了,所以静态方法可以使用泛型,但是需要单独定义:
public static <E> void test(E e){ //在方法定义前声明泛型
System.out.println(e);
}同理,成员方法也能自行定义泛型,在实际使用时再进行类型确定:
public <E> void test(E e){
System.out.println(e);
}其实,无论是泛型类还是泛型方法,再使用时一定要能够进行类型推断,明确类型才行。
注意一定要区分类定义的泛型和方法前定义的泛型!
可以看到我们在定义一个泛型类的引用时,需要在后面指出此类型:
Score<Integer> score; //声明泛型为Integer类型如果不希望指定类型,或是希望此引用类型可以引用任意泛型的Score类对象,可以使用?通配符,来表示自动匹配任意的可用类型:
Score<?> score; //score可以引用任意的Score类型对象了!那么使用通配符之后,得到的泛型成员变量会是什么类型呢?
Object o = score.getScore(); //只能变为Object因为使用了通配符,编译器就无法进行类型推断,所以只能使用原始类型。
在学习了泛型的界限后,我们还会继续了解通配符的使用。
现在有一个新的需求,现在没有String类型的成绩了,但是成绩依然可能是整数,也可能是小数,这时我们不希望用户将泛型指定为除数字类型外的其他类型,我们就需要使用到泛型的上界定义:
public class Score<T extends Number> { //设定泛型上界,必须是Number的子类
private final String name;
private final String id;
private T score;
public Score(String name, String id, T score) {
this.name = name;
this.id = id;
this.score = score;
}
public T getScore() {
return score;
}
}通过extends关键字进行上界限定,只有指定类型或指定类型的子类才能作为类型参数。
同样的,泛型通配符也支持泛型的界限:
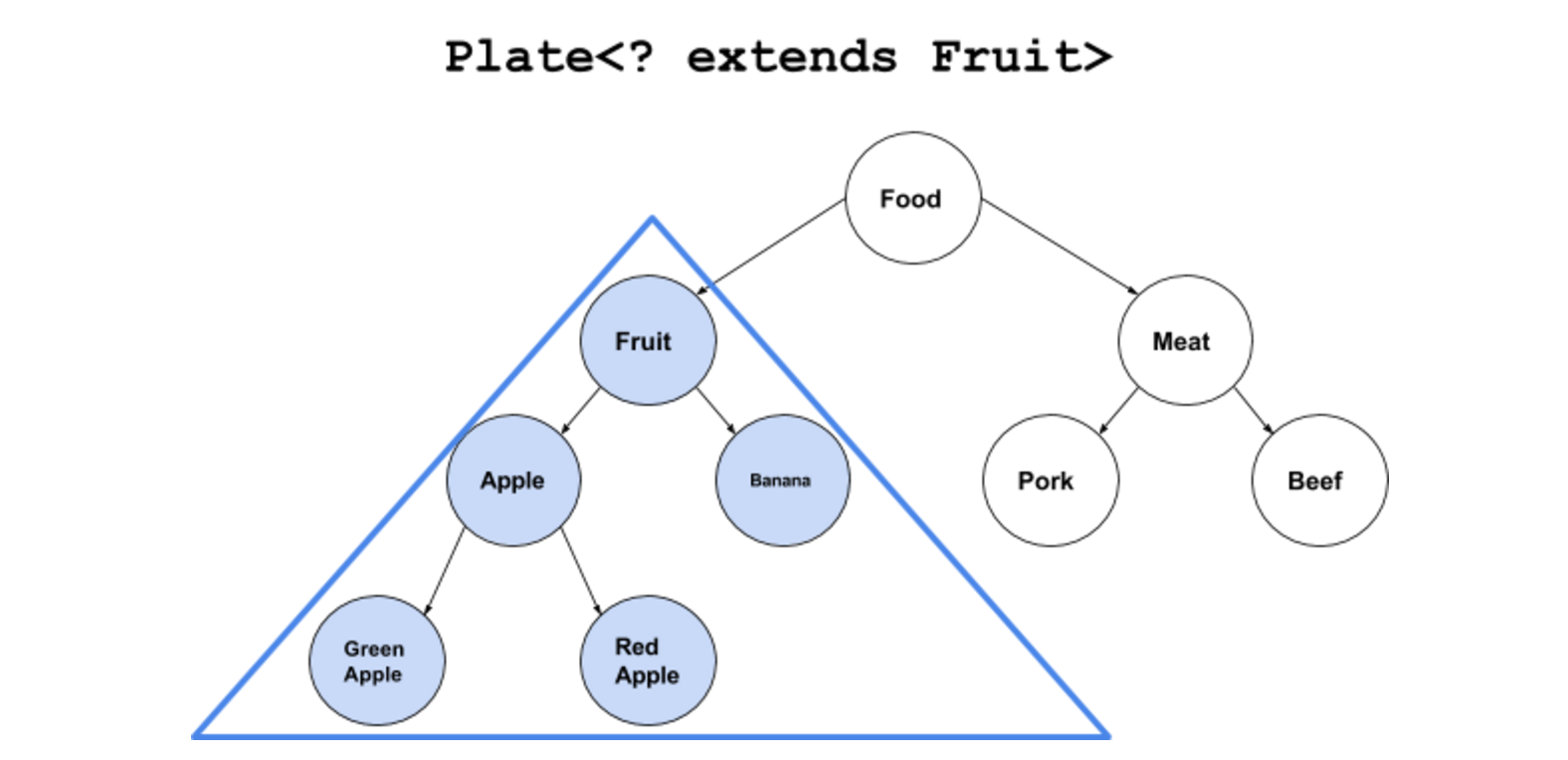
Score<? extends Number> score; //限定为匹配Number及其子类的类型同理,既然泛型有上限,那么也有下限:
Score<? super Integer> score; //限定为匹配Integer及其父类通过super关键字进行下界限定,只有指定类型或指定类型的父类才能作为类型参数。
图解如下:

那么限定了上界后,我们再来使用这个对象的泛型成员,会变成什么类型呢?
Score<? extends Number> score = new Score<>("数据结构与算法基础", "EP074512", 10);
Number o = score.getScore(); //得到的结果为上界类型也就是说,一旦我们指定了上界后,编译器就将范围从原始类型Object提升到我们指定的上界Number,但是依然无法明确具体类型。思考:那如果定义下限呢?
那么既然我们可以给泛型类限定上界,现在我们来看编译后结果呢:
//使用javap -l 进行反编译
public class com.test.Score<T extends java.lang.Number> {
public com.test.Score(java.lang.String, java.lang.String, T);
LineNumberTable:
line 8: 0
line 9: 4
line 10: 9
line 11: 14
line 12: 19
LocalVariableTable:
Start Length Slot Name Signature
0 20 0 this Lcom/test/Score;
0 20 1 name Ljava/lang/String;
0 20 2 id Ljava/lang/String;
0 20 3 score Ljava/lang/Number; //可以看到score的类型直接被编译为Number类
public T getScore();
LineNumberTable:
line 15: 0
LocalVariableTable:
Start Length Slot Name Signature
0 5 0 this Lcom/test/Score;
}
因此,一旦确立上限后,编译器会自动将类型提升到上限类型。
我们发现,每次创建泛型对象都需要在前后都标明类型,但是实际上后面的类型声明是可以去掉的,因为我们在传入参数时或定义泛型类的引用时,就已经明确了类型,因此JDK1.7提供了钻石运算符来简化代码:
Score<Integer> score = new Score<Integer>("数据结构与算法基础", "EP074512", 10); //1.7之前
Score<Integer> score = new Score<>("数据结构与算法基础", "EP074512", 10); //1.7之后泛型不仅仅可以可以定义在类上,同时也能定义在接口上:
public interface ScoreInterface<T> {
T getScore();
void setScore(T t);
}当实现此接口时,我们可以选择在实现类明确泛型类型或是继续使用此泛型,让具体创建的对象来确定类型。
public class Score<T> implements ScoreInterface<T>{ //将Score转变为泛型类<T>
private final String name;
private final String id;
private T score;
public Score(String name, String id, T score) {
this.name = name;
this.id = id;
this.score = score;
}
public T getScore() {
return score;
}
@Override
public void setScore(T score) {
this.score = score;
}
}public class StringScore implements ScoreInterface<String>{ //在实现时明确类型
@Override
public String getScore() {
return null;
}
@Override
public void setScore(String s) {
}
}抽象类同理,这里就不多做演示了。
思考一个问题,既然继承后明确了泛型类型,那么为什么@Override不会出现错误呢,重写的条件是需要和父类的返回值类型、形式参数一致,而泛型默认的原始类型是Object类型,子类明确后变为Number类型,这显然不满足重写的条件,但是为什么依然能编译通过呢?
class A<T>{
private T t;
public T get(){
return t;
}
public void set(T t){
this.t=t;
}
}
class B extends A<Number>{
private Number n;
@Override
public Number get(){ //这并不满足重写的要求,因为只能重写父类同样返回值和参数的方法,但是这样却能够通过编译!
return t;
}
@Override
public void set(Number t){
this.t=t;
}
}通过反编译进行观察,实际上是编译器帮助我们生成了两个桥接方法用于支持重写:
@Override
public Object get(){
return this.get();//调用返回Number的那个方法
}
@Override
public void set(Object t ){
this.set((Number)t ); //调用参数是Number的那个方法
}警告!本章最难的部分!
学习集合类之前,我们还有最关键的内容需要学习,同第一章一样,自底向上才是最佳的学习方向,比起直接带大家认识集合类,不如先了解一下数据结构,只有了解了数据结构基础,才能更好地学习集合类,同时,数据结构也是你以后深入学习JDK源码的必备条件!(学习不要快餐式!)当然,我们主要是讲解Java,数据结构作为铺垫作用,所以我们只会讲解关键的部分,其他部分可以下去自行了解。
在计算机科学中,数据结构是一种数据组织、管理和存储的格式,它可以帮助我们实现对数据高效的访问和修改。更准确地说,数据结构是数据值的集合,可以体现数据值之间的关系,以及可以对数据进行应用的函数或操作。
通俗地说,我们需要去学习在计算机中如何去更好地管理我们的数据,才能让我们对我们的数据控制更加灵活!
线性表是最基本的一种数据结构,它是表示一组相同类型数据的有限序列,你可以把它与数组进行参考,但是它并不是数组,线性表是一种表结构,它能够支持数据的插入、删除、更新、查询等,同时数组可以随意存放在数组中任意位置,而线性表只能依次有序排列,不能出现空隙,因此,我们需要进一步的设计。
######## 顺序表
将数据依次存储在连续的整块物理空间中,这种存储结构称为顺序存储结构,而以这种方式实现的线性表,我们称为顺序表。
同样的,表中的每一个个体都被称为元素,元素左边的元素(上一个元素),称为前驱,同理,右边的元素(后一个元素)称为后驱。

我们设计线性表的目标就是为了去更好地管理我们的数据,也就是说,我们可以基于数组,来进行封装,实现增删改查!既然要存储一组数据,那么很容易联想到我们之前学过的数组,数组就能够容纳一组同类型的数据。
目标:以数组为底层,编写以下抽象类的具体实现
/**
* 线性表抽象类
* @param <E> 存储的元素(Element)类型
*/
public abstract class AbstractList<E> {
/**
* 获取表的长度
* @return 顺序表的长度
*/
public abstract int size();
/**
* 添加一个元素
* @param e 元素
* @param index 要添加的位置(索引)
*/
public abstract void add(E e, int index);
/**
* 移除指定位置的元素
* @param index 位置
* @return 移除的元素
*/
public abstract E remove(int index);
/**
* 获取指定位置的元素
* @param index 位置
* @return 元素
*/
public abstract E get(int index);
}######## 链表
数据分散的存储在物理空间中,通过一根线保存着它们之间的逻辑关系,这种存储结构称为链式存储结构
实际上,就是每一个结点存放一个元素和一个指向下一个结点的引用(C语言里面是指针,Java中就是对象的引用,代表下一个结点对象)

利用这种思想,我们再来尝试实现上面的抽象类,从实际的代码中感受!
比较:顺序表和链表的优异?
顺序表优缺点:
-
访问速度快,随机访问性能高
-
插入和删除的效率低下,极端情况下需要变更整个表
-
不易扩充,需要复制并重新创建数组
链表优缺点:
-
插入和删除效率高,只需要改变连接点的指向即可
-
动态扩充容量,无需担心容量问题
-
访问元素需要依次寻找,随机访问元素效率低下
链表只能指向后面,能不能指向前面呢?双向链表!
栈和队列实际上就是对线性表加以约束的一种数据结构,如果前面的线性表的掌握已经ok,那么栈和队列就非常轻松了!
######## 栈
栈遵循先入后出原则,只能在线性表的一端添加和删除元素。我们可以把栈看做一个杯子,杯子只有一个口进出,最低处的元素只能等到上面的元素离开杯子后,才能离开。

向栈中插入一个元素时,称为入栈(压栈),移除栈顶元素称为出栈,我们需要尝试实现以下抽象类型:
/**
* 抽象类型栈,待实现
* @param <E> 元素类型
*/
public abstract class AbstractStack<E> {
/**
* 出栈操作
* @return 栈顶元素
*/
public abstract E pop();
/**
* 入栈操作
* @param e 元素
*/
public abstract void push(E e);
}其实,我们的JVM在处理方法调用时,也是一个栈操作:

所以说,如果玩不好递归,就会像这样:
public class Main {
public static void main(String[] args) {
go();
}
private static void go(){
go();
}
}
Exception in thread "main" java.lang.StackOverflowError
at com.test.Main.go(Main.java:13)
at com.test.Main.go(Main.java:13)
at com.test.Main.go(Main.java:13)
at com.test.Main.go(Main.java:13)
at com.test.Main.go(Main.java:13)
at com.test.Main.go(Main.java:13)
at com.test.Main.go(Main.java:13)
at com.test.Main.go(Main.java:13)
...栈的深度是有限制的,如果达到限制,将会出现StackOverflowError错误(注意是错误!说明是JVM出现了问题)
######## 队列
队列同样也是受限制的线性表,不过队列就像我们排队一样,只能从队尾开始排,从队首出。

所以我们要实现以下内容:
/**
*
* @param <E>
*/
public abstract class AbstractQueue<E> {
/**
* 进队操作
* @param e 元素
*/
public abstract void offer(E e);
/**
* 出队操作
* @return 元素
*/
public abstract E poll();
}
本版块主要学习的是二叉树,树也是一种数据结构,但是它使用起来更加的复杂。
######## 树
我们前面已经学习过链表了,我们知道链表是单个结点之间相连,也就是一种一对一的关系,而树则是一个结点连接多个结点,也就是一对多的关系。

一个结点可以有N个子结点,就像上图一样,看起来就像是一棵树。而位于最顶端的结点(没有父结点)我们称为根结点,而结点拥有的子节点数量称为度,每向下一级称为一个层次,树中出现的最大层次称为树的深度(高度)。
######## 二叉树
二叉树是一种特殊的树,每个结点最多有两颗子树,所以二叉树中不存在度大于2的结点,位于两边的子结点称为左右子树(注意,左右子树是明确区分的,是左就是左,是右就是右)

数学性质:
-
在二叉树的第i层上最多有2^(i-1) 个节点。
-
二叉树中如果深度为k,那么最多有2^k-1个节点。
设计一个二叉树结点类:
public class TreeNode<E> {
public E e; //当前结点数据
public TreeNode<E> left; //左子树
public TreeNode<E> right; //右子树
}######## 二叉树的遍历
顺序表的遍历其实就是依次有序去访问表中每一个元素,而像二叉树这样的复杂结构,我们有四种遍历方式,他们是:前序遍历、中序遍历、后序遍历以及层序遍历,本版块我们主要讨论前三种遍历方式:
-
前序遍历:从二叉树的根结点出发,到达结点时就直接输出结点数据,按照先向左在向右的方向访问。ABCDEF
-
中序遍历:从二叉树的根结点出发,优先输出左子树的节点的数据,再输出当前节点本身,最后才是右子树。CBDAEF
-
后序遍历:从二叉树的根结点出发,优先遍历其左子树,再遍历右子树,最后在输出当前节点本身。CDBFEA
######## 满二叉树和完全二叉树
满二叉树和完全二叉树其实就是特殊情况下的二叉树,满二叉树左右的所有叶子节点都在同一层,也就是说,完全把每一个层级都给加满了结点。完全二叉树与满二叉树不同的地方在于,它的最下层叶子节点可以不满,但是最下层的叶子节点必须靠左排布。

其实满二叉树和完全二叉树就是有一定规律的二叉树,很容易理解。
我们之前提到的这些数据结构,很好地帮我们管理了数据,但是,如果需要查找某一个元素是否存在于数据结构中,如何才能更加高效的去完成呢?
######## 哈希表
通过前面的学习,我们发现,顺序表虽然查询效率高,但是插入删除有严重表更新的问题,而链表虽然弥补了更新问题,但是查询效率实在是太低了,能否有一种折中方案?哈希表!
不知大家在之前的学习中是否发现,我们的Object类中,定义了一个叫做hashcode()的方法?而这个方法呢,就是为了更好地支持哈希表的实现。hashcode()默认得到的是对象的内存地址,也就是说,每个对象的hashCode都不一样。
哈希表,其实本质上就是一个存放链表的数组,那么它是如何去存储数据的呢?我们先来看看长啥样:

数组中每一个元素都是一个头结点,用于保存数据,那我们怎么确定数据应该放在哪一个位置呢?通过hash算法,我们能够瞬间得到元素应该放置的位置。
//假设hash表长度为16,hash算法为:
private int hash(int hashcode){
return hashcode % 16;
}设想这样一个问题,如果计算出来的hash值和之前已经存在的元素相同了呢?这种情况我们称为hash碰撞,这也是为什么要将每一个表元素设置为一个链表的头结点的原因,一旦发现重复,我们可以往后继续添加节点。
当然,以上的hash表结构只是一种设计方案,在面对大额数据时,是不够用的,在JDK1.8中,集合类使用的是数组+二叉树的形式解决的(这里的二叉树是经过加强的二叉树,不是前面讲得简单二叉树,我们下一节就会开始讲)
######## 二叉排序树
我们前面学习的二叉树效率是不够的,我们需要的是一种效率更高的二叉树,因此,基于二叉树的改进,提出了二叉查找树,可以看到结构像下面这样:

不难发现,每个节点的左子树,一定小于当前节点的值,每个节点的右子树,一定大于当前节点的值,这样的二叉树称为二叉排序树。利用二分搜索的思想,我们就可以快速查找某个节点!
######## 平衡二叉树
在了解了二叉查找树之后,我们发现,如果根节点为10,现在加入到结点的值从9开始,依次减小到1,那么这个表就会很奇怪,就像下面这样:

显然,当所有的结点都排列到一边,这种情况下,查找效率会直接退化为最原始的二叉树!因此我们需要维持二叉树的平衡,才能维持原有的查找效率。
现在我们对二叉排序树加以约束,要求每个结点的左右两个子树的高度差的绝对值不超过1,这样的二叉树称为平衡二叉树,同时要求每个结点的左右子树都是平衡二叉树,这样,就不会因为一边的疯狂增加导致失衡。我们来看看以下几种情况:

左左失衡

右右失衡

左右失衡

右左失衡
通过以上四种情况的处理,最终得到维护平衡二叉树的算法。
######## 红黑树
红黑树也是二叉排序树的一种改进,同平衡二叉树一样,红黑树也是一种维护平衡的二叉排序树,但是没有平衡二叉树那样严格(平衡二叉树每次插入新结点时,可能会出现大量的旋转,而红黑树保证不超过三次),红黑树降低了对于旋转的要求,因此效率有一定的提升同时实现起来也更加简单。但是红黑树的效率却高于平衡二叉树,红黑树也是JDK1.8中使用的数据结构!

红黑树的特性:
(1)每个节点或者是黑色,或者是红色。
(2)根节点是黑色。
(3)每个叶子节点的两边也需要表示(虽然没有,但是null也需要表示出来)是黑色。
(4)如果一个节点是红色的,则它的子节点必须是黑色的。
(5)从一个节点到该节点的子孙节点的所有路径上包含相同数目的黑节点。
我们来看看一个节点,是如何插入到红黑树中的:
基本的 插入规则和平衡二叉树一样,但是在插入后:
-
将新插入的节点标记为红色
-
如果 X 是根结点(root),则标记为黑色
-
如果 X 的 parent 不是黑色,同时 X 也不是 root:
-
3.1 如果 X 的 uncle (叔叔) 是红色
-
- 3.1.1 将 parent 和 uncle 标记为黑色
-
3.1.2 将 grand parent (祖父) 标记为红色
-
3.1.3 让 X 节点的颜色与 X 祖父的颜色相同,然后重复步骤 2、3
-
3.2 如果 X 的 uncle (叔叔) 是黑色,我们要分四种情况处理
-
- 3.2.1 左左 (P 是 G 的左孩子,并且 X 是 P 的左孩子)
-
3.2.2 左右 (P 是 G 的左孩子,并且 X 是 P 的右孩子)
-
3.2.3 右右 (P 是 G 的右孩子,并且 X 是 P 的右孩子)
-
3.2.4 右左 (P 是 G 的右孩子,并且 X 是 P 的左孩子)
-
其实这种情况下处理就和我们的平衡二叉树一样了
集合表示一组对象,称为其元素。一些集合允许重复的元素,而另一些则不允许。一些集合是有序的,而其他则是无序的。
集合类其实就是为了更好地组织、管理和操作我们的数据而存在的,包括列表、集合、队列、映射等数据结构。从这一块开始,我们会从源码角度给大家讲解(数据结构很重要!),不仅仅是教会大家如何去使用。
集合类最顶层不是抽象类而是接口,因为接口代表的是某个功能,而抽象类是已经快要成形的类型,不同的集合类的底层实现是不相同的,同时一个集合类可能会同时具有两种及以上功能(既能做队列也能做列表),所以采用接口会更加合适,接口只需定义支持的功能即可。

相同之处:
- 它们都是容器,都能够容纳一组元素。
不同之处:
-
数组的大小是固定的,集合的大小是可变的。
-
数组可以存放基本数据类型,但集合只能存放对象。
-
数组存放的类型只能是一种,但集合可以有不同种类的元素。
本接口中定义了全部的集合基本操作,我们可以在源码中看看。
我们再来看看List和Set以及Queue接口。
首先介绍ArrayList,它的底层是用数组实现的,内部维护的是一个可改变大小的数组,也就是我们之前所说的线性表!跟我们之前自己写的ArrayList相比,它更加的规范,同时继承自List接口。
先看看ArrayList的源码!
######## 基本操作
List<String> list = new ArrayList<>(); //默认长度的列表
List<String> listInit = new ArrayList<>(100); //初始长度为100的列表向列表中添加元素:
List<String> list = new ArrayList<>();
list.add("lbwnb");
list.add("yyds");
list.contains("yyds"); //是否包含某个元素
System.out.println(list);移除元素:
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("lbwnb");
list.add("yyds");
list.remove(0); //按下标移除元素
list.remove("yyds"); //移除指定元素
System.out.println(list);
}也支持批量操作:
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.addAll(new ArrayList<>()); //在尾部批量添加元素
list.removeAll(new ArrayList<>()); //批量移除元素(只有给定集合中存在的元素才会被移除)
list.retainAll(new ArrayList<>()); //只保留某些元素
System.out.println(list);
}我们再来看LinkedList,其实本质就是一个链表!我们来看看源码。
其实与我们之前编写的LinkedList不同之处在于,它内部使用的是一个双向链表:
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}当然,我们发现它还实现了Queue接口,所以LinkedList也能被当做一个队列或是栈来使用。
public static void main(String[] args) {
LinkedList<String> list = new LinkedList<>();
list.offer("A"); //入队
System.out.println(list.poll()); //出队
list.push("A");
list.push("B"); //进栈
list.push("C");
System.out.println(list.pop());
System.out.println(list.pop()); //出栈
System.out.println(list.pop());
}######## 利用代码块来快速添加内容
前面我们学习了匿名内部类,我们就可以利用代码块,来快速生成一个自带元素的List
List<String> list = new LinkedList<String>(){{ //初始化时添加
this.add("A");
this.add("B");
}};如果是需要快速生成一个只读的List,后面我们会讲解Arrays工具类。
######## 集合的排序
List<Integer> list = new LinkedList<Integer>(){ //Java9才支持匿名内部类使用钻石运算符
{
this.add(10);
this.add(2);
this.add(5);
this.add(8);
}
};
list.sort((a, b) -> { //排序已经由JDK实现,现在只需要填入自定义规则,完成Comparator接口实现
return a - b; //返回值小于0,表示a应该在b前面,返回值大于0,表示b应该在a后面,等于0则不进行交换
});
System.out.println(list);######## 集合的遍历
所有的集合类,都支持foreach循环!
public static void main(String[] args) {
List<Integer> list = new LinkedList<Integer>(){ //Java9才支持匿名内部类使用钻石运算符
{
this.add(10);
this.add(2);
this.add(5);
this.add(8);
}
};
for (Integer integer : list) {
System.out.println(integer);
}
}当然,也可以使用JDK1.8新增的forEach方法,它接受一个Consumer接口实现:
list.forEach(i -> {
System.out.println(i);
});从JDK1.8开始,lambda表达式开始逐渐成为主流,我们需要去适应函数式编程的这种语法,包括批量替换,也是用到了函数式接口来完成的。
list.replaceAll((i) -> {
if(i == 2) return 3; //将所有的2替换为3
else return i; //不是2就不变
});
System.out.println(list);######## Iterable和Iterator接口
我们之前学习数据结构时,已经得知,不同的线性表实现,在获取元素时的效率也不同,因此我们需要一种更好地方式来统一不同数据结构的遍历。
由于ArrayList对于随机访问的速度更快,而LinkedList对于顺序访问的速度更快,因此在上述的传统for循环遍历操作中,ArrayList的效率更胜一筹,因此我们要使得LinkedList遍历效率提升,就需要采用顺序访问的方式进行遍历,如果没有迭代器帮助我们统一标准,那么我们在应对多种集合类型的时候,就需要对应编写不同的遍历算法,很显然这样会降低我们的开发效率,而迭代器的出现就帮助我们解决了这个问题。
我们先来看看迭代器里面方法:
public interface Iterator<E> {
//...
}每个集合类都有自己的迭代器,通过iterator()方法来获取:
Iterator<Integer> iterator = list.iterator(); //生成一个新的迭代器
while (iterator.hasNext()){ //判断是否还有下一个元素
Integer i = iterator.next(); //获取下一个元素(获取一个少一个)
System.out.println(i);
}迭代器生成后,默认指向第一个元素,每次调用next()方法,都会将指针后移,当指针移动到最后一个元素之后,调用hasNext()将会返回false,迭代器是一次性的,用完即止,如果需要再次使用,需要调用iterator()方法。
ListIterator<Integer> iterator = list.listIterator(); //List还有一个更好地迭代器实现ListIteratorListIterator是List中独有的迭代器,在原有迭代器基础上新增了一些额外的操作。
我们之前已经看过Set接口的定义了,我们发现接口中定义的方法都是Collection中直接继承的,因此,Set支持的功能其实也就和Collection中定义的差不多,只不过使用方法上稍有不同。
Set集合特点:
-
不允许出现重复元素
-
不支持随机访问(不允许通过下标访问)
首先认识一下HashSet,它的底层就是采用哈希表实现的(我们在这里先不去探讨实现原理,因为底层实质上维护的是一个HashMap,我们学习了Map之后再来讨论)
public static void main(String[] args) {
HashSet<Integer> set = new HashSet<>();
set.add(120); //支持插入元素,但是不支持指定位置插入
set.add(13);
set.add(11);
for (Integer integer : set) {
System.out.println(integer);
}
}运行上面代码发现,最后Set集合中存在的元素顺序,并不是我们的插入顺序,这是因为HashSet底层是采用哈希表来实现的,实际的存放顺序是由Hash算法决定的。
那么我们希望数据按照我们插入的顺序进行保存该怎么办呢?我们可以使用LinkedHashSet:
public static void main(String[] args) {
LinkedHashSet<Integer> set = new LinkedHashSet<>(); //会自动保存我们的插入顺序
set.add(120);
set.add(13);
set.add(11);
for (Integer integer : set) {
System.out.println(integer);
}
}LinkedHashSet底层维护的不再是一个HashMap,而是LinkedHashMap,它能够在插入数据时利用链表自动维护顺序,因此这样就能够保证我们插入顺序和最后的迭代顺序一致了。
还有一种Set叫做TreeSet,它会在元素插入时进行排序:
public static void main(String[] args) {
TreeSet<Integer> set = new TreeSet<>();
set.add(1);
set.add(3);
set.add(2);
System.out.println(set);
}可以看到最后得到的结果并不是我们插入顺序,而是按照数字的大小进行排列。当然,我们也可以自定义排序规则:
public static void main(String[] args) {
TreeSet<Integer> set = new TreeSet<>((a, b) -> b - a); //在创建对象时指定规则即可
set.add(1);
set.add(3);
set.add(2);
System.out.println(set);
}现在的结果就是我们自定义的排序规则了。
虽然Set集合只是粗略的进行了讲解,但是学习Map之后,我们还会回来看我们Set的底层实现,所以说最重要的还是Map。本节只需要记住Set的性质、使用即可。
######## 什么是映射
我们在高中阶段其实已经学习过映射了,映射指两个元素的之间相互“对应”的关系,也就是说,我们的元素之间是两两对应的,是以键值对的形式存在。

######## Map接口
Map就是为了实现这种数据结构而存在的,我们通过保存键值对的形式来存储映射关系。
我们先来看看Map接口中定义了哪些操作。
######## HashMap和LinkedHashMap
HashMap的实现过程,相比List,就非常地复杂了,它并不是简简单单的表结构,而是利用哈希表存放映射关系,我们来看看HashMap是如何实现的,首先回顾我们之前学习的哈希表,它长这样:

哈希表的本质其实就是一个用于存放后续节点的头结点的数组,数组里面的每一个元素都是一个头结点(也可以说就是一个链表),当要新插入一个数据时,会先计算该数据的哈希值,找到数组下标,然后创建一个新的节点,添加到对应的链表后面。
而HashMap就是采用的这种方式,我们可以看到源码中同样定义了这样的一个结构:
/**
* The table, initialized on first use, and resized as
* necessary. When allocated, length is always a power of two.
* (We also tolerate length zero in some operations to allow
* bootstrapping mechanics that are currently not needed.)
*/
transient Node<K,V>[] table;这个表会在第一次使用时初始化,同时在必要时进行扩容,并且它的大小永远是2的倍数!
/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16我们可以看到默认的大小为2的4次方,每次都需要是2的倍数,也就是说,下一次增长之后,大小会变成2的5次方。
我们现在需要思考一个问题,当我们表中的数据不断增加之后,链表会变得越来越长,这样会严重导致查询速度变慢,首先想到办法就是,我们可以对数组的长度进行扩容,来存放更多的链表,那么什么情况下会进行扩容呢?
/**
* The load factor for the hash table.
*
* @serial
*/
final float loadFactor;我们还发现HashMap源码中有这样一个变量,也就是负载因子,那么它是干嘛的呢?
负载因子其实就是用来衡量当前情况是否需要进行扩容的标准。我们可以看到默认的负载因子是0.75
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;那么负载因子是怎么控制扩容的呢?0.75的意思是,在插入新的结点后,如果当前数组的占用率达到75%则进行扩容。在扩容时,会将所有的数据,重新计算哈希值,得到一个新的下标,组成新的哈希表。
但是这样依然有一个问题,链表过长的情况还是有可能发生,所以,为了从根源上解决这个问题,在JDK1.8时,引入了红黑树这个数据结构。
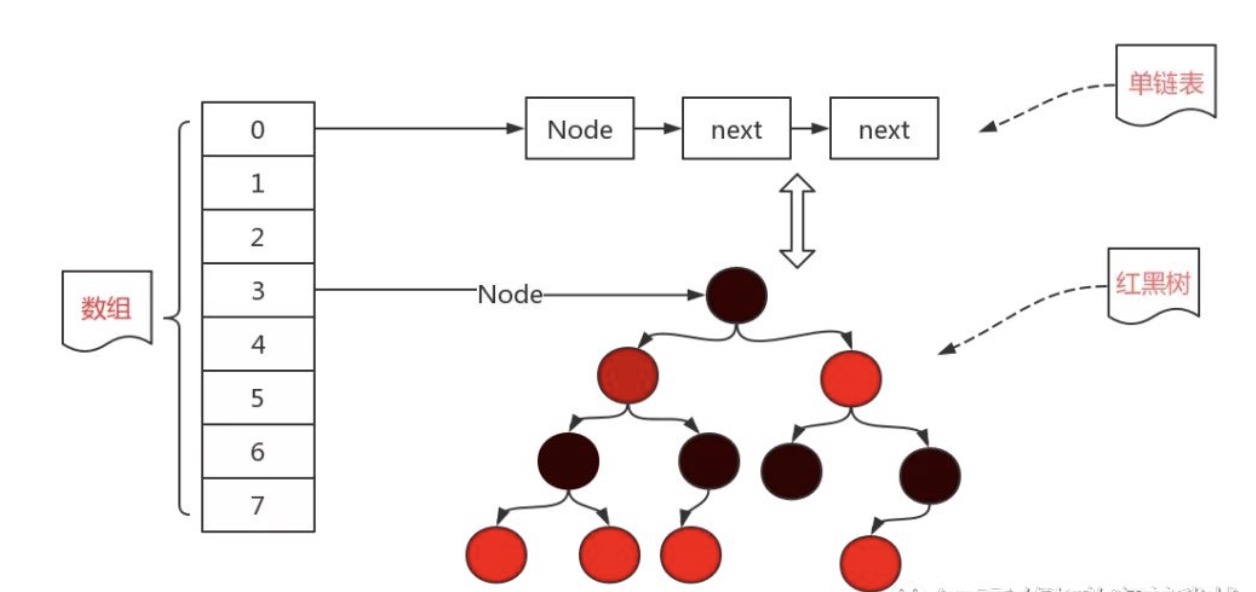
当链表的长度达到8时,会自动将链表转换为红黑树,这样能使得原有的查询效率大幅度降低!当使用红黑树之后,我们就可以利用二分搜索的思想,快速地去寻找我们想要的结果,而不是像链表一样挨个去看。
/**
* Entry for Tree bins. Extends LinkedHashMap.Entry (which in turn
* extends Node) so can be used as extension of either regular or
* linked node.
*/
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {除了Node以外,HashMap还有TreeNode,很明显这就是为了实现红黑树而设计的内部类。不过我们发现,TreeNode并不是直接继承Node,而是使用了LinkedHashMap中的Entry实现,它保存了前后节点的顺序(也就是我们的插入顺序)。
/**
* HashMap.Node subclass for normal LinkedHashMap entries.
*/
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}LinkedHashMap是直接继承自HashMap,具有HashMap的全部性质,同时得益于每一个节点都是一个双向链表,保存了插入顺序,这样我们在遍历LinkedHashMap时,顺序就同我们的插入顺序一致。当然,也可以使用访问顺序,也就是说对于刚访问过的元素,会被排到最后一位。
public static void main(String[] args) {
LinkedHashMap<Integer, String> map = new LinkedHashMap<>(16, 0.75f, true); //以访问顺序
map.put(1, "A");
map.put(2, "B");
map.put(3, "C");
map.get(2);
System.out.println(map);
}观察结果,我们发现,刚访问的结果被排到了最后一位。
######## TreeMap
TreeMap其实就是自动维护顺序的一种Map,就和我们前面提到的TreeSet一样:
/**
* The comparator used to maintain order in this tree map, or
* null if it uses the natural ordering of its keys.
*
* @serial
*/
private final Comparator<? super K> comparator;
private transient Entry<K,V> root;
/**
* Node in the Tree. Doubles as a means to pass key-value pairs back to
* user (see Map.Entry).
*/
static final class Entry<K,V> implements Map.Entry<K,V> {我们发现它的内部直接维护了一个红黑树,就像它的名字一样,就是一个Tree,因为它默认就是有序的,所以说直接采用红黑树会更好。我们在创建时,直接给予一个比较规则即可。
######## Map的使用
我们首先来看看Map的一些基本操作:
public static void main(String[] args) {
Map<Integer, String> map = new HashMap<>();
map.put(1, "A");
map.put(2, "B");
map.put(3, "C");
System.out.println(map.get(1)); //获取Key为1的值
System.out.println(map.getOrDefault(0, "K")); //不存在就返回K
map.remove(1); //移除这个Key的键值对
}由于Map并未实现迭代器接口,因此不支持foreach,但是JDK1.8为我们提供了forEach方法使用:
public static void main(String[] args) {
Map<Integer, String> map = new HashMap<>();
map.put(1, "A");
map.put(2, "B");
map.put(3, "C");
map.forEach((k, v) -> System.out.println(k+"->"+v));
for (Map.Entry<Integer, String> entry : map.entrySet()) { //也可以获取所有的Entry来foreach
int key = entry.getKey();
String value = entry.getValue();
System.out.println(key+" -> "+value);
}
}我们也可以单独获取所有的值或者是键:
public static void main(String[] args) {
Map<Integer, String> map = new HashMap<>();
map.put(1, "A");
map.put(2, "B");
map.put(3, "C");
System.out.println(map.keySet()); //直接获取所有的key
System.out.println(map.values()); //直接获取所有的值
}######## 再谈Set原理
通过观察HashSet的源码发现,HashSet几乎都在操作内部维护的一个HashMap,也就是说,HashSet只是一个表壳,而内部维护的HashMap才是灵魂!
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();我们发现,在添加元素时,其实添加的是一个键为我们插入的元素,而值就是PRESENT常量:
/**
* Adds the specified element to this set if it is not already present.
* More formally, adds the specified element <tt>e</tt> to this set if
* this set contains no element <tt>e2</tt> such that
* <tt>(e==null ? e2==null : e.equals(e2))</tt>.
* If this set already contains the element, the call leaves the set
* unchanged and returns <tt>false</tt>.
*
* @param e element to be added to this set
* @return <tt>true</tt> if this set did not already contain the specified
* element
*/
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}观察其他的方法,也几乎都是在用HashMap做事,所以说,HashSet利用了HashMap内部的数据结构,轻松地就实现了Set定义的全部功能!
再来看TreeSet,实际上用的就是我们的TreeMap:
/**
* The backing map.
*/
private transient NavigableMap<E,Object> m;同理,这里就不多做阐述了。
######## JDK1.8新增方法使用
最后,我们再来看看JDK1.8中集合类新增的一些操作(之前没有提及的)首先来看看compute方法:
public static void main(String[] args) {
Map<Integer, String> map = new HashMap<>();
map.put(1, "A");
map.put(2, "B");
map.compute(1, (k, v) -> { //compute会将指定Key的值进行重新计算,若Key不存在,v会返回null
return v+"M"; //这里返回原来的value+M
});
map.computeIfPresent(1, (k, v) -> { //当Key存在时存在则计算并赋予新的值
return v+"M"; //这里返回原来的value+M
});
System.out.println(map);
}也可以使用computeIfAbsent,当不存在Key时,计算并将键值对放入Map
public static void main(String[] args) {
Map<Integer, String> map = new HashMap<>();
map.put(1, "A");
map.put(2, "B");
map.computeIfAbsent(0, (k) -> { //若不存在则计算并插入新的值
return "M"; //这里返回M
});
System.out.println(map);
}merge方法用于处理数据:
public static void main(String[] args) {
List<Student> students = Arrays.asList(
new Student("yoni", "English", 80),
new Student("yoni", "Chiness", 98),
new Student("yoni", "Math", 95),
new Student("taohai.wang", "English", 50),
new Student("taohai.wang", "Chiness", 72),
new Student("taohai.wang", "Math", 41),
new Student("Seely", "English", 88),
new Student("Seely", "Chiness", 89),
new Student("Seely", "Math", 92)
);
Map<String, Integer> scoreMap = new HashMap<>();
students.forEach(student -> scoreMap.merge(student.getName(), student.getScore(), Integer::sum));
scoreMap.forEach((k, v) -> System.out.println("key:" + k + "总分" + "value:" + v));
}
static class Student {
private final String name;
private final String type;
private final int score;
public Student(String name, String type, int score) {
this.name = name;
this.type = type;
this.score = score;
}
public String getName() {
return name;
}
public int getScore() {
return score;
}
public String getType() {
return type;
}
}既然集合类型中的元素类型是泛型,那么能否嵌套存储呢?
public static void main(String[] args) {
Map<String, List<Integer>> map = new HashMap<>(); //每一个映射都是 字符串<->列表
map.put("卡布奇诺今犹在", new LinkedList<>());
map.put("不见当年倒茶人", new LinkedList<>());
System.out.println(map.keySet());
System.out.println(map.values());
}通过Key获取到对应的值后,就是一个列表:
map.get("卡布奇诺今犹在").add(10);
System.out.println(map.get("卡布奇诺今犹在").get(0));让套娃继续下去:
public static void main(String[] args) {
Map<Integer, Map<Integer, Map<Integer, String>>> map = new HashMap<>();
}你也可以使用List来套娃别的:
public static void main(String[] args) {
List<Map<String, Set<String>>> list = new LinkedList<>();
}Java 8 API添加了一个新的抽象称为流Stream,可以让你以一种声明的方式处理数据。Stream 使用一种类似用 SQL 语句从数据库查询数据的直观方式来提供一种对 Java 集合运算和表达的高阶抽象。Stream API可以极大提高Java程序员的生产力,让程序员写出高效率、干净、简洁的代码。这种风格将要处理的元素集合看作一种流, 流在管道中传输, 并且可以在管道的节点上进行处理, 比如筛选, 排序,聚合等。元素流在管道中经过中间操作(intermediate operation)的处理,最后由最终操作(terminal operation)得到前面处理的结果。

它看起来就像一个工厂的流水线一样!我们就可以把一个Stream当做流水线处理:
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("A");
list.add("B");
list.add("C");
//移除为B的元素
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()){
if(iterator.next().equals("B")) iterator.remove();
}
//Stream操作
list = list //链式调用
.stream() //获取流
.filter(e -> !e.equals("B")) //只允许所有不是B的元素通过流水线
.collect(Collectors.toList()); //将流水线中的元素重新收集起来,变回List
System.out.println(list);
}可能从上述例子中还不能感受到流处理带来的便捷,我们通过下面这个例子来感受一下:
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(3);
list = list
.stream()
.distinct() //去重(使用equals判断)
.sorted((a, b) -> b - a) //进行倒序排列
.map(e -> e+1) //每个元素都要执行+1操作
.limit(2) //只放行前两个元素
.collect(Collectors.toList());
System.out.println(list);
}当遇到大量的复杂操作时,我们就可以使用Stream来快速编写代码,这样不仅代码量大幅度减少,而且逻辑也更加清晰明了(如果你学习过SQL的话,你会发现它更像一个Sql语句)
注意:不能认为每一步是直接依次执行的!
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(3);
list = list
.stream()
.distinct() //断点
.sorted((a, b) -> b - a)
.map(e -> {
System.out.println(">>> "+e); //断点
return e+1;
})
.limit(2) //断点
.collect(Collectors.toList());
//实际上,stream会先记录每一步操作,而不是直接开始执行内容,当整个链式调用完成后,才会依次进行! n接下来,我们用一堆随机数来进行更多流操作的演示:
public static void main(String[] args) {
Random random = new Random(); //Random是一个随机数工具类
random
.ints(-100, 100) //生成-100~100之间的,随机int型数字(本质上是一个IntStream)
.limit(10) //只获取前10个数字(这是一个无限制的流,如果不加以限制,将会无限进行下去!)
.filter(i -> i < 0) //只保留小于0的数字
.sorted() //默认从小到大排序
.forEach(System.out::println); //依次打印
}我们可以生成一个统计实例来帮助我们快速进行统计:
public static void main(String[] args) {
Random random = new Random(); //Random是一个随机数工具类
IntSummaryStatistics statistics = random
.ints(0, 100)
.limit(100)
.summaryStatistics(); //获取语法统计实例
System.out.println(statistics.getMax()); //快速获取最大值
System.out.println(statistics.getCount()); //获取数量
System.out.println(statistics.getAverage()); //获取平均值
}普通的List只需要一个方法就可以直接转换到方便好用的IntStream了:
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(1);
list.add(2);
list.add(3);
list.add(4);
list.stream()
.mapToInt(i -> i) //将每一个元素映射为Integer类型(这里因为本来就是Integer)
.summaryStatistics();
}我们还可以通过flat来对整个流进行进一步细分:
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("A,B");
list.add("C,D");
list.add("E,F"); //我们想让每一个元素通过,进行分割,变成独立的6个元素
list = list
.stream() //生成流
.flatMap(e -> Arrays.stream(e.split(","))) //分割字符串并生成新的流
.collect(Collectors.toList()); //汇成新的List
System.out.println(list); //得到结果
}我们也可以只通过Stream来完成所有数字的和,使用reduce方法:
8public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
int sum = list
.stream()
.reduce((a, b) -> a + b) //计算规则为:a是上一次计算的值,b是当前要计算的参数,这里是求和
.get(); //我们发现得到的是一个Optional类实例,不是我们返回的类型,通过get方法返回得到的值
System.out.println(sum);
}通过上面的例子,我们发现,Stream不喜欢直接给我们返回一个结果,而是通过Optinal的方式,那么什么是Optional呢?
Optional类是Java8为了解决null值判断问题,使用Optional类可以避免显式的null值判断(null的防御性检查),避免null导致的NPE(NullPointerException)。总而言之,就是对控制的一个判断,为了避免空指针异常。
public static void main(String[] args) {
String str = null;
if(str != null){ //当str不为空时添加元素到List中
list.add(str);
}
}有了Optional之后,我们就可以这样写:
public static void main(String[] args) {
String str = null;
Optional<String> optional = Optional.ofNullable(str); //转换为Optional
optional.ifPresent(System.out::println); //当存在时再执行方法
}就类似于Kotlin中的:
var str : String? = null
str?.upperCase()我们可以选择直接get或是当值为null时,获取备选值:
public static void main(String[] args) {
String str = null;
Optional optional = Optional.ofNullable(str); //转换为Optional(可空)
System.out.println(optional.orElse("lbwnb"));
// System.out.println(optional.get()); 这样会直接报错
}同样的,Optional也支持过滤操作和映射操作,不过是对于单对象而言:
public static void main(String[] args) {
String str = "A";
Optional optional = Optional.ofNullable(str); //转换为Optional(可空)
System.out.println(optional.filter(s -> s.equals("B")).get()); //被过滤了,此时元素为null,获取时报错
}public static void main(String[] args) {
List<String> list = new ArrayList<>();
String str = "A";
Optional optional = Optional.ofNullable(str); //转换为Optional(可空)
System.out.println(optional.map(s -> s + "A").get()); //在尾部追加一个A
}其他操作自学了解。
Arrays是一个用于操作数组的工具类,它给我们提供了大量的工具方法:
/**
* This class contains various methods for manipulating arrays (such as
* sorting and searching). This class also contains a static factory
* that allows arrays to be viewed as lists. <- 注意,这句话很关键
*
* @author Josh Bloch
* @author Neal Gafter
* @author John Rose
* @since 1.2
*/
public class Arrays {由于操作数组并不像集合那样方便,因此JDK提供了Arrays类来增强对数组操作,比如:
public static void main(String[] args) {
int[] array = {1, 5, 2, 4, 7, 3, 6};
Arrays.sort(array); //直接进行排序(底层原理:进行判断,元素少使用插入排序,大量元素使用双轴快速/归并排序)
System.out.println(array); //由于int[]是一个对象类型,而数组默认是没有重写toString()方法,因此无法打印到想要的结果
System.out.println(Arrays.toString(array)); //我们可以使用Arrays.toString()来像集合一样直接打印每一个元素出来
}public static void main(String[] args) {
int[] array = {1, 5, 2, 4, 7, 3, 6};
Arrays.sort(array);
System.out.println("排序后的结果:"+Arrays.toString(array));
System.out.println("目标元素3位置为:"+Arrays.binarySearch(array, 3)); //二分搜素,必须是已经排序好的数组!
}public static void main(String[] args) {
int[] array = {1, 5, 2, 4, 7, 3, 6};
Arrays
.stream(array) //将数组转换为流进行操作
.sorted()
.forEach(System.out::println);
}public static void main(String[] args) {
int[] array = {1, 5, 2, 4, 7, 3, 6};
int[] array2 = Arrays.copyOf(array, array.length); //复制一个一模一样的数组
System.out.println(Arrays.toString(array2));
System.out.println(Arrays.equals(array, array2)); //比较两个数组是否值相同
Arrays.fill(array, 0); //将数组的所有值全部填充为指定值
System.out.println(Arrays.toString(array));
Arrays.setAll(array2, i -> array2[i] + 2); //依次计算每一个元素(注意i是下标位置)
System.out.println(Arrays.toString(array2)); //这里计算让每个元素值+2
}思考:当二维数组使用Arrays.equals()进行比较以及Arrays.toString()进行打印时,还会得到我们想要的结果吗?
public static void main(String[] args) {
Integer[][] array = {{1, 5}, {2, 4}, {7, 3}, {6}};
Integer[][] array2 = {{1, 5}, {2, 4}, {7, 3}, {6}};
System.out.println(Arrays.toString(array)); //这样还会得到我们想要的结果吗?
System.out.println(Arrays.equals(array2, array)); //这样还会得到true吗?
System.out.println(Arrays.deepToString(array)); //使用deepToString就能到打印多维数组
System.out.println(Arrays.deepEquals(array2, array)); //使用deepEquals就能比较多维数组
}那么,一开始提到的当做List进行操作呢?我们可以使用Arrays.asList()来将数组转换为一个 固定长度的List
public static void main(String[] args) {
Integer[] array = {1, 5, 2, 4, 7, 3, 6};
List<Integer> list = Arrays.asList(array); //不支持基本类型数组,必须是对象类型数组
Arrays.asList("A", "B", "C"); //也可以逐个添加,因为是可变参数
list.add(1); //此List实现是长度固定的,是Arrays内部单独实现的一个类型,因此不支持添加操作
list.remove(0); //同理,也不支持移除
list.set(0, 8); //直接设置指定下标的值就可以
list.sort(Comparator.reverseOrder()); //也可以执行排序操作
System.out.println(list); //也可以像List那样直接打印
}文字游戏:allows arrays to be viewed as lists,实际上只是当做List使用,本质还是数组,因此数组的属性依然存在!因此如果要将数组快速转换为实际的List,可以像这样:
public static void main(String[] args) {
Integer[] array = {1, 5, 2, 4, 7, 3, 6};
List<Integer> list = new ArrayList<>(Arrays.asList(array));
}通过自行创建一个真正的ArrayList并在构造时将Arrays的List值传递。
既然数组操作都这么方便了,集合操作能不能也安排点高级的玩法呢?那必须的,JDK为我们准备的Collocations类就是专用于集合的工具类:
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
Collections.max(list);
Collections.min(list);
}当然,Collections提供的内容相比Arrays会更多,希望大家下去自行了解,这里就不多做介绍了。
1 <- 3 <- 5 <- 7 <- 9 转换为 1 <- 3 <- 5 <- 7 <- 9
现在有一个单链表,尝试将其所有节点倒序排列
public class Main {
public static void main(String[] args) {
Node head = new Node(1);
head.next = new Node(3);
head.next.next = new Node(5);
head.next.next.next = new Node(7);
head.next.next.next.next = new Node(9);
head = reverse(head);
while (head != null){
System.out.println(head.value+" ");
head = head.next;
}
}
public static class Node {
public int value;
public Node next;
public Node(int data) {
this.value = data;
}
}
public static Node reverse(Node head) {
//在这里实现
}
}现在知道二叉树的前序: GDAFEMHZ,以及中序: ADEFGHMZ,请根据已知信息还原这颗二叉树。
实现一个计算器,要求输入一个计算公式(含加减乘除运算符,没有负数但是有小数),得到结果,比如输入:1+4*3/1.321,得到结果为:2.2
现在给定一个主字符串和一个子字符串,请判断主字符串是否包含子字符串,例如主字符串:ABCABCDHI,子字符串:ABCD,因此主字符串包含此子字符串;主字符串:ABCABCUISA,子字符串:ABCD,则不包含。
注意:这块会涉及到操作系统和计算机组成原理相关内容。
I/O简而言之,就是输入输出,那么为什么会有I/O呢?其实I/O无时无刻都在我们的身边,比如读取硬盘上的文件,网络文件传输,鼠标键盘输入,也可以是接受单片机发回的数据,而能够支持这些操作的设备就是I/O设备。
我们可以大致看一下整个计算机的总线结构:

常见的I/O设备一般是鼠标、键盘这类通过USB进行传输的外设或者是通过Sata接口或是M.2连接的硬盘。一般情况下,这些设备是由CPU发出指令通过南桥芯片间接进行控制,而不是由CPU直接操作。
而我们在程序中,想要读取这些外部连接的I/O设备中的内容,就需要将数据传输到内存中。而需要实现这样的操作,单单凭借一个小的程序是无法做到的,而操作系统(如:Windows/Linux/MacOS)就是专门用于控制和管理计算机硬件和软件资源的软件,我们需要读取一个IO设备的内容时,可以向操作系统发出请求,由操作系统帮助我们来和底层的硬件交互以完成我们的读取/写入请求。从读取硬盘文件的角度来说,不同的操作系统有着不同的文件系统(也就是文件在硬盘中的存储排列方式,如Windows就是NTFS、MacOS就是APFS),硬盘只能存储一个个0和1这样的二进制数据,至于0和1如何排列,各自又代表什么意思,就是由操作系统的文件系统来决定的。从网络通信角度来说,网络信号通过网卡等设备翻译为二进制信号,再交给系统进行读取,最后再由操作系统来给到程序。
JDK提供了一套用于IO操作的框架,根据流的传输方向和读取单位,分为字节流InputStream和OutputStream以及字符流Reader和Writer,当然,这里的Stream并不是前面集合框架认识的Stream,这里的流指的是数据流,通过流,我们就可以一直从流中读取数据,直到读取到尽头,或是不断向其中写入数据,直到我们写入完成。而这类IO就是我们所说的BIO,
字节流一次读取一个字节,也就是一个byte的大小,而字符流顾名思义,就是一次读取一个字符,也就是一个char的大小(在读取纯文本文件的时候更加适合),有关这两种流,会在后面详细介绍,这个章节我们需要学习16个关键的流。
要学习和使用IO,首先就要从最易于理解的读取文件开始说起。
首先介绍一下FileInputStream,通过它来获取文件的输入流。
public static void main(String[] args) {
try {
FileInputStream inputStream = new FileInputStream("路径");
//路径支持相对路径和绝对路径
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}相对路径是在当前运行的路径下寻找文件,而绝对路径,是从根目录开始寻找。路径分割符支持使用/或是\\,但是不能写为\因为它是转义字符!
在使用完成一个流之后,必须关闭这个流来完成对资源的释放,否则资源会被一直占用!
public static void main(String[] args) {
FileInputStream inputStream = null; //定义可以先放在try外部
try {
inputStream = new FileInputStream("路径");
} catch (FileNotFoundException e) {
e.printStackTrace();
} finally {
try { //建议在finally中进行,因为这个是任何情况都必须要执行的!
if(inputStream != null) inputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}虽然这样的写法才是最保险的,但是显得过于繁琐了,尤其是finally中再次嵌套了一个try-catch块,因此在JDK1.7新增了try-with-resource语法,用于简化这样的写法(本质上还是和这样的操作一致,只是换了个写法)
public static void main(String[] args) {
//注意,这种语法只支持实现了AutoCloseable接口的类!
try(FileInputStream inputStream = new FileInputStream("路径")) { //直接在try()中定义要在完成之后释放的资源
} catch (IOException e) { //这里变成IOException是因为调用close()可能会出现,而FileNotFoundException是继承自IOException的
e.printStackTrace();
}
//无需再编写finally语句块,因为在最后自动帮我们调用了close()
}之后为了方便,我们都使用此语法进行教学。
public static void main(String[] args) {
//test.txt:a
try(FileInputStream inputStream = new FileInputStream("test.txt")) {
//使用read()方法进行字符读取
System.out.println((char) inputStream.read()); //读取一个字节的数据(英文字母只占1字节,中文占2字节)
System.out.println(inputStream.read()); //唯一一个字节的内容已经读完了,再次读取返回-1表示没有内容了
}catch (IOException e){
e.printStackTrace();
}
}使用read可以直接读取一个字节的数据,注意,流的内容是有限的,读取一个少一个!我们如果想一次性全部读取的话,可以直接使用一个while循环来完成:
public static void main(String[] args) {
//test.txt:abcd
try(FileInputStream inputStream = new FileInputStream("test.txt")) {
int tmp;
while ((tmp = inputStream.read()) != -1){ //通过while循环来一次性读完内容
System.out.println((char)tmp);
}
}catch (IOException e){
e.printStackTrace();
}
}使用方法能查看当前可读的剩余字节数量(注意:并不一定真实的数据量就是这么多,尤其是在网络I/O操作时,这个方法只能进行一个预估也可以说是暂时能一次性读取的数量)
try(FileInputStream inputStream = new FileInputStream("test.txt")) {
System.out.println(inputStream.available()); //查看剩余数量
}catch (IOException e){
e.printStackTrace();
}当然,一个一个读取效率太低了,那能否一次性全部读取呢?我们可以预置一个合适容量的byte[]数组来存放。
public static void main(String[] args) {
//test.txt:abcd
try(FileInputStream inputStream = new FileInputStream("test.txt")) {
byte[] bytes = new byte[inputStream.available()]; //我们可以提前准备好合适容量的byte数组来存放
System.out.println(inputStream.read(bytes)); //一次性读取全部内容(返回值是读取的字节数)
System.out.println(new String(bytes)); //通过String(byte[])构造方法得到字符串
}catch (IOException e){
e.printStackTrace();
}
}也可以控制要读取数量:
System.out.println(inputStream.read(bytes, 1, 2)); //第二个参数是从给定数组的哪个位置开始放入内容,第三个参数是读取流中的字节数注意:一次性读取同单个读取一样,当没有任何数据可读时,依然会返回-1
通过skip()方法可以跳过指定数量的字节:
public static void main(String[] args) {
//test.txt:abcd
try(FileInputStream inputStream = new FileInputStream("test.txt")) {
System.out.println(inputStream.skip(1));
System.out.println((char) inputStream.read()); //跳过了一个字节
}catch (IOException e){
e.printStackTrace();
}
}注意:FileInputStream是不支持reset()的,虽然有这个方法,但是这里先不提及。
既然有输入流,那么文件输出流也是必不可少的:
public static void main(String[] args) {
//输出流也需要在最后调用close()方法,并且同样支持try-with-resource
try(FileOutputStream outputStream = new FileOutputStream("output.txt")) {
//注意:若此文件不存在,会直接创建这个文件!
}catch (IOException e){
e.printStackTrace();
}
}输出流没有read()操作而是write()操作,使用方法同输入流一样,只不过现在的方向变为我们向文件里写入内容:
public static void main(String[] args) {
try(FileOutputStream outputStream = new FileOutputStream("output.txt")) {
outputStream.write('c'); //同read一样,可以直接写入内容
outputStream.write("lbwnb".getBytes()); //也可以直接写入byte[]
outputStream.write("lbwnb".getBytes(), 0, 1); //同上输入流
outputStream.flush(); //建议在最后执行一次刷新操作(强制写入)来保证数据正确写入到硬盘文件中
}catch (IOException e){
e.printStackTrace();
}
}那么如果是我只想在文件尾部进行追加写入数据呢?我们可以调用另一个构造方法来实现:
public static void main(String[] args) {
try(FileOutputStream outputStream = new FileOutputStream("output.txt", true)) {
outputStream.write("lb".getBytes()); //现在只会进行追加写入,而不是直接替换原文件内容
outputStream.flush();
}catch (IOException e){
e.printStackTrace();
}
}利用输入流和输出流,就可以轻松实现文件的拷贝了:
public static void main(String[] args) {
try(FileOutputStream outputStream = new FileOutputStream("output.txt");
FileInputStream inputStream = new FileInputStream("test.txt")) { //可以写入多个
byte[] bytes = new byte[10]; //使用长度为10的byte[]做传输媒介
int tmp; //存储本地读取字节数
while ((tmp = inputStream.read(bytes)) != -1){ //直到读取完成为止
outputStream.write(bytes, 0, tmp); //写入对应长度的数据到输出流
}
}catch (IOException e){
e.printStackTrace();
}
}字符流不同于字节,字符流是以一个具体的字符进行读取,因此它只适合读纯文本的文件,如果是其他类型的文件不适用:
public static void main(String[] args) {
try(FileReader reader = new FileReader("test.txt")){
reader.skip(1); //现在跳过的是一个字符
System.out.println((char) reader.read()); //现在是按字符进行读取,而不是字节,因此可以直接读取到中文字符
}catch (IOException e){
e.printStackTrace();
}
}同理,字符流只支持char[]类型作为存储:
public static void main(String[] args) {
try(FileReader reader = new FileReader("test.txt")){
char[] str = new char[10];
reader.read(str);
System.out.println(str); //直接读取到char[]中
}catch (IOException e){
e.printStackTrace();
}
}既然有了Reader肯定也有Writer:
public static void main(String[] args) {
try(FileWriter writer = new FileWriter("output.txt")){
writer.getEncoding(); //支持获取编码(不同的文本文件可能会有不同的编码类型)
writer.write('牛');
writer.append('牛'); //其实功能和write一样
writer.flush(); //刷新
}catch (IOException e){
e.printStackTrace();
}
}我们发现不仅有write()方法,还有一个append()方法,但是实际上他们效果是一样的,看源码:
/**
* Appends the specified character to this writer.
*
* <p> An invocation of this method of the form <tt>out.append(c)</tt>
* behaves in exactly the same way as the invocation
*
* <pre>
* out.write(c) </pre>
*
* @param c
* The 16-bit character to append
*
* @return This writer
*
* @throws IOException
* If an I/O error occurs
*
* @since 1.5
*/
public Writer append(char c) throws IOException {
write(c);
return this;
}append支持像StringBuilder那样的链式调用,返回的是Writer对象本身。
练习:尝试一下用Reader和Writer来拷贝纯文本文件
File类专门用于表示一个文件或文件夹,只不过它只是代表这个文件,但并不是这个文件本身。通过File对象,可以更好地管理和操作硬盘上的文件。
public static void main(String[] args) {
File file = new File("test.txt"); //直接创建文件对象,可以是相对路径,也可以是绝对路径
System.out.println(file.exists()); //此文件是否存在
System.out.println(file.length()); //获取文件的大小
System.out.println(file.isDirectory()); //是否为一个文件夹
System.out.println(file.canRead()); //是否可读
System.out.println(file.canWrite()); //是否可写
System.out.println(file.canExecute()); //是否可执行
}通过File对象,我们就能快速得到文件的所有信息,如果是文件夹,还可以获取文件夹内部的文件列表等内容:
File file = new File("/");
System.out.println(Arrays.toString(file.list())); //快速获取文件夹下的文件名称列表
for (File f : file.listFiles()){ //所有子文件的File对象
System.out.println(f.getAbsolutePath()); //获取文件的绝对路径
}如果我们希望读取某个文件的内容,可以直接将File作为参数传入字节流或是字符流:
File file = new File("test.txt");
try (FileInputStream inputStream = new FileInputStream(file)){ //直接做参数
System.out.println(inputStream.available());
}catch (IOException e){
e.printStackTrace();
}练习:尝试拷贝文件夹下的所有文件到另一个文件夹
虽然普通的文件流读取文件数据非常便捷,但是每次都需要从外部I/O设备去获取数据,由于外部I/O设备的速度一般都达不到内存的读取速度,很有可能造成程序反应迟钝,因此性能还不够高,而缓冲流正如其名称一样,它能够提供一个缓冲,提前将部分内容存入内存(缓冲区)在下次读取时,如果缓冲区中存在此数据,则无需再去请求外部设备。同理,当向外部设备写入数据时,也是由缓冲区处理,而不是直接向外部设备写入。

要创建一个缓冲字节流,只需要将原本的流作为构造参数传入BufferedInputStream即可:
public static void main(String[] args) {
try (BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream("test.txt"))){ //传入FileInputStream
System.out.println((char) bufferedInputStream.read()); //操作和原来的流是一样的
}catch (IOException e){
e.printStackTrace();
}
}实际上进行I/O操作的并不是BufferedInputStream,而是我们传入的FileInputStream,而BufferedInputStream虽然有着同样的方法,但是进行了一些额外的处理然后再调用FileInputStream的同名方法,这样的写法称为装饰者模式
public void close() throws IOException {
byte[] buffer;
while ( (buffer = buf) != null) {
if (bufUpdater.compareAndSet(this, buffer, null)) { //CAS无锁算法,并发会用到,暂时不管
InputStream input = in;
in = null;
if (input != null)
input.close();
return;
}
// Else retry in case a new buf was CASed in fill()
}
}实际上这种模式是父类FilterInputStream提供的规范,后面我们还会讲到更多FilterInputStream的子类。
我们可以发现在BufferedInputStream中还存在一个专门用于缓存的数组:
/**
* The internal buffer array where the data is stored. When necessary,
* it may be replaced by another array of
* a different size.
*/
protected volatile byte buf[];I/O操作一般不能重复读取内容(比如键盘发送的信号,主机接收了就没了),而缓冲流提供了缓冲机制,一部分内容可以被暂时保存,BufferedInputStream支持reset()和mark()操作,首先我们来看看mark()方法的介绍:
/**
* Marks the current position in this input stream. A subsequent
* call to the <code>reset</code> method repositions this stream at
* the last marked position so that subsequent reads re-read the same bytes.
* <p>
* The <code>readlimit</code> argument tells this input stream to
* allow that many bytes to be read before the mark position gets
* invalidated.
* <p>
* This method simply performs <code>in.mark(readlimit)</code>.
*
* @param readlimit the maximum limit of bytes that can be read before
* the mark position becomes invalid.
* @see java.io.FilterInputStream#in
* @see java.io.FilterInputStream#reset()
*/
public synchronized void mark(int readlimit) {
in.mark(readlimit);
}当调用mark()之后,输入流会以某种方式保留之后读取的readlimit数量的内容,当读取的内容数量超过readlimit则之后的内容不会被保留,当调用reset()之后,会使得当前的读取位置回到mark()调用时的位置。
public static void main(String[] args) {
try (BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream("test.txt"))){
bufferedInputStream.mark(1); //只保留之后的1个字符
System.out.println((char) bufferedInputStream.read());
System.out.println((char) bufferedInputStream.read());
bufferedInputStream.reset(); //回到mark时的位置
System.out.println((char) bufferedInputStream.read());
System.out.println((char) bufferedInputStream.read());
}catch (IOException e) {
e.printStackTrace();
}
}我们发现虽然后面的部分没有保存,但是依然能够正常读取,其实mark()后保存的读取内容是取readlimit和BufferedInputStream类的缓冲区大小两者中的最大值,而并非完全由readlimit确定。因此我们限制一下缓冲区大小,再来观察一下结果:
public static void main(String[] args) {
try (BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream("test.txt"), 1)){ //将缓冲区大小设置为1
bufferedInputStream.mark(1); //只保留之后的1个字符
System.out.println((char) bufferedInputStream.read());
System.out.println((char) bufferedInputStream.read()); //已经超过了readlimit,继续读取会导致mark失效
bufferedInputStream.reset(); //mark已经失效,无法reset()
System.out.println((char) bufferedInputStream.read());
System.out.println((char) bufferedInputStream.read());
}catch (IOException e) {
e.printStackTrace();
}
}了解完了BufferedInputStream之后,我们再来看看BufferedOutputStream,其实和BufferedInputStream原理差不多,只是反向操作:
public static void main(String[] args) {
try (BufferedOutputStream outputStream = new BufferedOutputStream(new FileOutputStream("output.txt"))){
outputStream.write("lbwnb".getBytes());
outputStream.flush();
}catch (IOException e) {
e.printStackTrace();
}
}操作和FileOutputStream一致,这里就不多做介绍了。
缓存字符流和缓冲字节流一样,也有一个专门的缓冲区,BufferedReader构造时需要传入一个Reader对象:
public static void main(String[] args) {
try (BufferedReader reader = new BufferedReader(new FileReader("test.txt"))){
System.out.println((char) reader.read());
}catch (IOException e) {
e.printStackTrace();
}
}使用和reader也是一样的,内部也包含一个缓存数组:
private char cb[];相比Reader更方便的是,它支持按行读取:
public static void main(String[] args) {
try (BufferedReader reader = new BufferedReader(new FileReader("test.txt"))){
System.out.println(reader.readLine()); //按行读取
}catch (IOException e) {
e.printStackTrace();
}
}读取后直接得到一个字符串,当然,它还能把每一行内容依次转换为集合类提到的Stream流:
public static void main(String[] args) {
try (BufferedReader reader = new BufferedReader(new FileReader("test.txt"))){
reader
.lines()
.limit(2)
.distinct()
.sorted()
.forEach(System.out::println);
}catch (IOException e) {
e.printStackTrace();
}
}它同样也支持mark()和reset()操作:
public static void main(String[] args) {
try (BufferedReader reader = new BufferedReader(new FileReader("test.txt"))){
reader.mark(1);
System.out.println((char) reader.read());
reader.reset();
System.out.println((char) reader.read());
}catch (IOException e) {
e.printStackTrace();
}
}BufferedReader处理纯文本文件时就更加方便了,BufferedWriter在处理时也同样方便:
public static void main(String[] args) {
try (BufferedWriter reader = new BufferedWriter(new FileWriter("output.txt"))){
reader.newLine(); //使用newLine进行换行
reader.write("汉堡做滴彳亍不彳亍"); //可以直接写入一个字符串
reader.flush(); //清空缓冲区
}catch (IOException e) {
e.printStackTrace();
}
}有时会遇到这样一个很麻烦的问题:我这里读取的是一个字符串或是一个个字符,但是我只能往一个OutputStream里输出,但是OutputStream又只支持byte类型,如果要往里面写入内容,进行数据转换就会很麻烦,那么能否有更加简便的方式来做这样的事情呢?
public static void main(String[] args) {
try(OutputStreamWriter writer = new OutputStreamWriter(new FileOutputStream("test.txt"))){ //虽然给定的是FileOutputStream,但是现在支持以Writer的方式进行写入
writer.write("lbwnb"); //以操作Writer的样子写入OutputStream
}catch (IOException e){
e.printStackTrace();
}
}同样的,我们现在只拿到了一个InputStream,但是我们希望能够按字符的方式读取,我们就可以使用InputStreamReader来帮助我们实现:
public static void main(String[] args) {
try(InputStreamReader reader = new InputStreamReader(new FileInputStream("test.txt"))){ //虽然给定的是FileInputStream,但是现在支持以Reader的方式进行读取
System.out.println((char) reader.read());
}catch (IOException e){
e.printStackTrace();
}
}InputStreamReader和OutputStreamWriter本质也是Reader和Writer,因此可以直接放入BufferedReader来实现更加方便的操作。
打印流其实我们从一开始就在使用了,比如System.out就是一个PrintStream,PrintStream也继承自FilterOutputStream类因此依然是装饰我们传入的输出流,但是它存在自动刷新机制,例如当向PrintStream流中写入一个字节数组后自动调用flush()方法。PrintStream也永远不会抛出异常,而是使用内部检查机制checkError()方法进行错误检查。最方便的是,它能够格式化任意的类型,将它们以字符串的形式写入到输出流。
public final static PrintStream out = null;可以看到System.out也是PrintStream,不过默认是向控制台打印,我们也可以让它向文件中打印:
public static void main(String[] args) {
try(PrintStream stream = new PrintStream(new FileOutputStream("test.txt"))){
stream.println("lbwnb"); //其实System.out就是一个PrintStream
}catch (IOException e){
e.printStackTrace();
}
}我们平时使用的println方法就是PrintStream中的方法,它会直接打印基本数据类型或是调用对象的toString()方法得到一个字符串,并将字符串转换为字符,放入缓冲区再经过转换流输出到给定的输出流上。

因此实际上内部还包含这两个内容:
/**
* Track both the text- and character-output streams, so that their buffers
* can be flushed without flushing the entire stream.
*/
private BufferedWriter textOut;
private OutputStreamWriter charOut;与此相同的还有一个PrintWriter,不过他们的功能基本一致,PrintWriter的构造方法可以接受一个Writer作为参数,这里就不再做过多阐述了。
数据流DataInputStream也是FilterInputStream的子类,同样采用装饰者模式,最大的不同是它支持基本数据类型的直接读取:
public static void main(String[] args) {
try (DataInputStream dataInputStream = new DataInputStream(new FileInputStream("test.txt"))){
System.out.println(dataInputStream.readBoolean()); //直接将数据读取为任意基本数据类型
}catch (IOException e) {
e.printStackTrace();
}
}用于写入基本数据类型:
public static void main(String[] args) {
try (DataOutputStream dataOutputStream = new DataOutputStream(new FileOutputStream("output.txt"))){
dataOutputStream.writeBoolean(false);
}catch (IOException e) {
e.printStackTrace();
}
}注意,写入的是二进制数据,并不是写入的字符串,使用DataInputStream可以读取,一般他们是配合一起使用的。
既然基本数据类型能够读取和写入基本数据类型,那么能否将对象也支持呢?ObjectOutputStream不仅支持基本数据类型,通过对对象的序列化操作,以某种格式保存对象,来支持对象类型的IO,注意:它不是继承自FilterInputStream的。
public static void main(String[] args) {
try (ObjectOutputStream outputStream = new ObjectOutputStream(new FileOutputStream("output.txt"));
ObjectInputStream inputStream = new ObjectInputStream(new FileInputStream("output.txt"))){
People people = new People("lbw");
outputStream.writeObject(people);
outputStream.flush();
people = (People) inputStream.readObject();
System.out.println(people.name);
}catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
}
}
static class People implements Serializable{ //必须实现Serializable接口才能被序列化
String name;
public People(String name){
this.name = name;
}
}在我们后续的操作中,有可能会使得这个类的一些结构发生变化,而原来保存的数据只适用于之前版本的这个类,因此我们需要一种方法来区分类的不同版本:
static class People implements Serializable{
private static final long serialVersionUID = 123456; //在序列化时,会被自动添加这个属性,它代表当前类的版本,我们也可以手动指定版本。
String name;
c
public People(String name){
this.name = name;
}
}当发生版本不匹配时,会无法反序列化为对象:
java.io.InvalidClassException: com.test.Main$People; local class incompatible: stream classdesc serialVersionUID = 123456, local class serialVersionUID = 1234567
at java.io.ObjectStreamClass.initNonProxy(ObjectStreamClass.java:699)
at java.io.ObjectInputStream.readNonProxyDesc(ObjectInputStream.java:2003)
at java.io.ObjectInputStream.readClassDesc(ObjectInputStream.java:1850)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2160)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1667)
at java.io.ObjectInputStream.readObject(ObjectInputStream.java:503)
at java.io.ObjectInputStream.readObject(ObjectInputStream.java:461)
at com.test.Main.main(Main.java:27)如果我们不希望某些属性参与到序列化中进行保存,我们可以添加transient关键字:
public static void main(String[] args) {
try (ObjectOutputStream outputStream = new ObjectOutputStream(new FileOutputStream("output.txt"));
ObjectInputStream inputStream = new ObjectInputStream(new FileInputStream("output.txt"))){
People people = new People("lbw");
outputStream.writeObject(people);
outputStream.flush();
people = (People) inputStream.readObject();
System.out.println(people.name); //虽然能得到对象,但是name属性并没有保存,因此为null
}catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
}
}
static class People implements Serializable{
private static final long serialVersionUID = 1234567;
transient String name;
public People(String name){
this.name = name;
}
}其实我们可以看到,在一些JDK内部的源码中,也存在大量的transient关键字,使得某些属性不参与序列化,取消这些不必要保存的属性,可以节省数据空间占用以及减少序列化时间。
**注意:**本章节涉及到JVM相关底层原理,难度会有一些大。
反射就是把Java类中的各个成分映射成一个个的Java对象。即在运行状态中,对于任意一个类,都能够知道这个类所有的属性和方法,对于任意一个对象,都能调用它的任意一个方法和属性。这种动态获取信息及动态调用对象方法的功能叫Java的反射机制。
简而言之,我们可以通过反射机制,获取到类的一些属性,包括类里面有哪些字段,有哪些方法,继承自哪个类,甚至还能获取到泛型!它的权限非常高,慎重使用!
在学习Java的反射机制之前,我们需要先了解一下类的加载机制,一个类是如何被加载和使用的:

在Java程序启动时,JVM会将一部分类(class文件)先加载(并不是所有的类都会在一开始加载),通过ClassLoader将类加载,在加载过程中,会将类的信息提取出来(存放在元空间中,JDK1.8之前存放在永久代),同时也会生成一个Class对象存放在内存(堆内存),注意此Class对象只会存在一个,与加载的类唯一对应!
**思考:**既然说和与加载的类唯一对应,那如果我们手动创建一个与JDK包名一样,同时类名也保持一致,那么JVM会加载这个类吗?
package java.lang;
public class String { //JDK提供的String类也是
public static void main(String[] args) {
System.out.println("我姓🐴,我叫🐴nb");
}
}我们发现,会出现以下报错:
错误: 在类 java.lang.String 中找不到 main 方法, 请将 main 方法定义为:
public static void main(String[] args)但是我们明明在自己写的String类中定义了main方法啊,为什么会找不到此方法呢?实际上这是ClassLoader的双亲委派机制在保护Java程序的正常运行:
实际上我们的类最开始是由BootstarpClassLoader进行加载,BootstarpClassLoader用于加载JDK提供的类,而我们自己编写的类实际上是AppClassLoader,只有BootstarpClassLoader都没有加载的类,才会让AppClassLoader来加载,因此我们自己编写的同名包同名类不会被加载,而实际要去启动的是真正的String类,也就自然找不到main方法了!
public class Main {
public static void main(String[] args) {
System.out.println(Main.class.getClassLoader()); //查看当前类的类加载器
System.out.println(Main.class.getClassLoader().getParent()); //父加载器
System.out.println(Main.class.getClassLoader().getParent().getParent()); //爷爷加载器
System.out.println(String.class.getClassLoader()); //String类的加载器
}
}由于BootstarpClassLoader是C++编写的,我们在Java中是获取不到的。
通过前面,我们了解了类的加载,同时会提取一个类的信息生成Class对象存放在内存中,而反射机制其实就是利用这些存放的类信息,来获取类的信息和操作类。那么如何获取到每个类对应的Class对象呢,我们可以通过以下方式:
public static void main(String[] args) throws ClassNotFoundException {
Class<String> clazz = String.class; //使用class关键字,通过类名获取
Class<?> clazz2 = Class.forName("java.lang.String"); //使用Class类静态方法forName(),通过包名.类名获取,注意返回值是Class<?>
Class<?> clazz3 = new String("cpdd").getClass(); //通过实例对象获取
}注意Class类也是一个泛型类,只有第一种方法,能够直接获取到对应类型的Class对象,而以下两种方法使用了?通配符作为返回值,但是实际上都和第一个返回的是同一个对象:
Class<String> clazz = String.class; //使用class关键字,通过类名获取
Class<?> clazz2 = Class.forName("java.lang.String"); //使用Class类静态方法forName(),通过包名.类名获取,注意返回值是Class<?>
Class<?> clazz3 = new String("cpdd").getClass();
System.out.println(clazz == clazz2);
System.out.println(clazz == clazz3);通过比较,验证了我们一开始的结论,在JVM中每个类始终只存在一个Class对象,无论通过什么方法获取,都是一样的。现在我们再来看看这个问题:
public static void main(String[] args) {
Class<?> clazz = int.class; //基本数据类型有Class对象吗?
System.out.println(clazz);
}迷了,不是每个类才有Class对象吗,基本数据类型又不是类,这也行吗?实际上,基本数据类型也有对应的Class对象(反射操作可能需要用到),而且我们不仅可以通过class关键字获取,其实本质上是定义在对应的包装类中的:
/**
* The {@code Class} instance representing the primitive type
* {@code int}.
*
* @since JDK1.1
*/
@SuppressWarnings("unchecked")
public static final Class<Integer> TYPE = (Class<Integer>) Class.getPrimitiveClass("int");
/*
* Return the Virtual Machine's Class object for the named
* primitive type
*/
static native Class<?> getPrimitiveClass(String name); //C++实现,并非Java定义每个包装类中(包括Void),都有一个获取原始类型Class方法,注意,getPrimitiveClass获取的是原始类型,并不是包装类型,只是可以使用包装类来表示。
public static void main(String[] args) {
Class<?> clazz = int.class;
System.out.println(Integer.TYPE == int.class);
}通过对比,我们发现实际上包装类型都有一个TYPE,其实也就是基本类型的Class,那么包装类的Class和基本类的Class一样吗?
public static void main(String[] args) {
System.out.println(Integer.TYPE == Integer.class);
}我们发现,包装类型的Class对象并不是基本类型Class对象。数组类型也是一种类型,只是编程不可见,因此我们可以直接获取数组的Class对象:
public static void main(String[] args) {
Class<String[]> clazz = String[].class;
System.out.println(clazz.getName()); //获取类名称(得到的是包名+类名的完整名称)
System.out.println(clazz.getSimpleName());
System.out.println(clazz.getTypeName());
System.out.println(clazz.getClassLoader()); //获取它的类加载器
System.out.println(clazz.cast(new Integer("10"))); //强制类型转换
}正常情况下,我们使用instanceof进行类型比较:
public static void main(String[] args) {
String str = "";
System.out.println(str instanceof String);
}它可以判断一个对象是否为此接口或是类的实现或是子类,而现在我们有了更多的方式去判断类型:
public static void main(String[] args) {
String str = "";
System.out.println(str.getClass() == String.class); //直接判断是否为这个类型
}如果需要判断是否为子类或是接口/抽象类的实现,我们可以使用asSubClass()方法:
public static void main(String[] args) {
Integer i = 10;
i.getClass().asSubclass(Number.class); //当Integer不是Number的子类时,会产生异常
}通过getSuperclass()方法,我们可以获取到父类的Class对象:
public static void main(String[] args) {
Integer i = 10;
System.out.println(i.getClass().getSuperclass());
}也可以通过getGenericSuperclass()获取父类的原始类型的Type:
public static void main(String[] args) {
Integer i = 10;
Type type = i.getClass().getGenericSuperclass();
System.out.println(type);
System.out.println(type instanceof Class);
}我们发现Type实际上是Class类的父接口,但是获取到的Type的实现并不一定是Class。
同理,我们也可以像上面这样获取父接口:
public static void main(String[] args) {
Integer i = 10;
for (Class<?> anInterface : i.getClass().getInterfaces()) {
System.out.println(anInterface.getName());
}
for (Type genericInterface : i.getClass().getGenericInterfaces()) {
System.out.println(genericInterface.getTypeName());
}
}既然我们拿到了类的定义,那么是否可以通过Class对象来创建对象、调用方法、修改变量呢?当然是可以的,那我们首先来探讨一下如何创建一个类的对象:
public static void main(String[] args) throws InstantiationException, IllegalAccessException {
Class<Student> clazz = Student.class;
Student student = clazz.newInstance();
student.test();
}
static class Student{
public void test(){
System.out.println("萨日朗");
}
}通过使用newInstance()方法来创建对应类型的实例,返回泛型T,注意它会抛出InstantiationException和IllegalAccessException异常,那么什么情况下会出现异常呢?
public static void main(String[] args) throws InstantiationException, IllegalAccessException {
Class<Student> clazz = Student.class;
Student student = clazz.newInstance();
student.test();
}
static class Student{
public Student(String text){
}
public void test(){
System.out.println("萨日朗");
}
}当类默认的构造方法被带参构造覆盖时,会出现InstantiationException异常,因为newInstance()只适用于默认无参构造。
public static void main(String[] args) throws InstantiationException, IllegalAccessException {
Class<Student> clazz = Student.class;
Student student = clazz.newInstance();
student.test();
}
static class Student{
private Student(){}
public void test(){
System.out.println("萨日朗");
}
}当默认无参构造的权限不是public时,会出现IllegalAccessException异常,表示我们无权去调用默认构造方法。在JDK9之后,不再推荐使用newInstance()方法了,而是使用我们接下来要介绍到的,通过获取构造器,来实例化对象:
public static void main(String[] args) throws NoSuchMethodException, InvocationTargetException, InstantiationException, IllegalAccessException {
Class<Student> clazz = Student.class;
Student student = clazz.getConstructor(String.class).newInstance("what's up");
student.test();
}
static class Student{
public Student(String str){}
public void test(){
System.out.println("萨日朗");
}
}通过获取类的构造方法(构造器)来创建对象实例,会更加合理,我们可以使用getConstructor()方法来获取类的构造方法,同时我们需要向其中填入参数,也就是构造方法需要的类型,当然我们这里只演示了。那么,当访问权限不是public的时候呢?
public static void main(String[] args) throws NoSuchMethodException, InvocationTargetException, InstantiationException, IllegalAccessException {
Class<Student> clazz = Student.class;
Student student = clazz.getConstructor(String.class).newInstance("what's up");
student.test();
}
static class Student{
private Student(String str){}
public void test(){
System.out.println("萨日朗");
}
}我们发现,当访问权限不足时,会无法找到此构造方法,那么如何找到非public的构造方法呢?
Class<Student> clazz = Student.class;
Constructor<Student> constructor = clazz.getDeclaredConstructor(String.class);
constructor.setAccessible(true); //修改访问权限
Student student = constructor.newInstance("what's up");
student.test();使用getDeclaredConstructor()方法可以找到类中的非public构造方法,但是在使用之前,我们需要先修改访问权限,在修改访问权限之后,就可以使用非public方法了(这意味着,反射可以无视权限修饰符访问类的内容)
我们可以通过反射来调用类的方法(本质上还是类的实例进行调用)只是利用反射机制实现了方法的调用,我们在包下创建一个新的类:
package com.test;
public class Student {
public void test(String str){
System.out.println("萨日朗"+str);
}
}这次我们通过forName(String)来找到这个类并创建一个新的对象:
public static void main(String[] args) throws ReflectiveOperationException {
Class<?> clazz = Class.forName("com.test.Student");
Object instance = clazz.newInstance(); //创建出学生对象
Method method = clazz.getMethod("test", String.class); //通过方法名和形参类型获取类中的方法
method.invoke(instance, "what's up"); //通过Method对象的invoke方法来调用方法
}通过调用getMethod()方法,我们可以获取到类中所有声明为public的方法,得到一个Method对象,我们可以通过Method对象的invoke()方法(返回值就是方法的返回值,因为这里是void,返回值为null)来调用已经获取到的方法,注意传参。
我们发现,利用反射之后,在一个对象从构造到方法调用,没有任何一处需要引用到对象的实际类型,我们也没有导入Student类,整个过程都是反射在代替进行操作,使得整个过程被模糊了,过多的使用反射,会极大地降低后期维护性。
同构造方法一样,当出现非public方法时,我们可以通过反射来无视权限修饰符,获取非public方法并调用,现在我们将test()方法的权限修饰符改为private:
public static void main(String[] args) throws ReflectiveOperationException {
Class<?> clazz = Class.forName("com.test.Student");
Object instance = clazz.newInstance(); //创建出学生对象
Method method = clazz.getDeclaredMethod("test", String.class); //通过方法名和形参类型获取类中的方法
method.setAccessible(true);
method.invoke(instance, "what's up"); //通过Method对象的invoke方法来调用方法
}Method和Constructor都和Class一样,他们存储了方法的信息,包括方法的形式参数列表,返回值,方法的名称等内容,我们可以直接通过Method对象来获取这些信息:
public static void main(String[] args) throws ReflectiveOperationException {
Class<?> clazz = Class.forName("com.test.Student");
Method method = clazz.getDeclaredMethod("test", String.class); //通过方法名和形参类型获取类中的方法
System.out.println(method.getName()); //获取方法名称
System.out.println(method.getReturnType()); //获取返回值类型
}当方法的参数为可变参数时,我们该如何获取方法呢?实际上,我们在之前就已经提到过,可变参数实际上就是一个数组,因此我们可以直接使用数组的class对象表示:
Method method = clazz.getDeclaredMethod("test", String[].class);反射非常强大,尤其是我们提到的越权访问,但是请一定谨慎使用,别人将某个方法设置为private一定有他的理由,如果实在是需要使用别人定义为private的方法,就必须确保这样做是安全的,在没有了解别人代码的整个过程就强行越权访问,可能会出现无法预知的错误。
我们还可以通过反射访问一个类中定义的成员字段也可以修改一个类的对象中的成员字段值,通过getField()方法来获取一个类定义的指定字段:
public static void main(String[] args) throws ReflectiveOperationException {
Class<?> clazz = Class.forName("com.test.Student");
Object instance = clazz.newInstance();
Field field = clazz.getField("i"); //获取类的成员字段i
field.set(instance, 100); //将类实例instance的成员字段i设置为100
Method method = clazz.getMethod("test");
method.invoke(instance);
}在得到Field之后,我们就可以直接通过set()方法为某个对象,设定此属性的值,比如上面,我们就为instance对象设定值为100,当访问private字段时,同样可以按照上面的操作进行越权访问:
public static void main(String[] args) throws ReflectiveOperationException {
Class<?> clazz = Class.forName("com.test.Student");
Object instance = clazz.newInstance();
Field field = clazz.getDeclaredField("i"); //获取类的成员字段i
field.setAccessible(true);
field.set(instance, 100); //将类实例instance的成员字段i设置为100
Method method = clazz.getMethod("test");
method.invoke(instance);
}现在我们已经知道,反射几乎可以把一个类的老底都给扒出来,任何属性,任何内容,都可以被反射修改,无论权限修饰符是什么,那么,如果我的字段被标记为final呢?现在在字段i前面添加final关键字,我们再来看看效果:
private final int i = 10;这时,当字段为final时,就修改失败了!当然,通过反射可以直接将final修饰符直接去除,去除后,就可以随意修改内容了,我们来尝试修改Integer的value值:
public static void main(String[] args) throws ReflectiveOperationException {
Integer i = 10;
Field field = Integer.class.getDeclaredField("value");
Field modifiersField = Field.class.getDeclaredField("modifiers"); //这里要获取Field类的modifiers字段进行修改
modifiersField.setAccessible(true);
modifiersField.setInt(field,field.getModifiers()&~Modifier.FINAL); //去除final标记
field.setAccessible(true);
field.set(i, 100); //强行设置值
System.out.println(i);
}我们可以发现,反射非常暴力,就连被定义为final字段的值都能强行修改,几乎能够无视一切阻拦。我们来试试看修改一些其他的类型:
public static void main(String[] args) throws ReflectiveOperationException {
List<String> i = new ArrayList<>();
Field field = ArrayList.class.getDeclaredField("size");
field.setAccessible(true);
field.set(i, 10);
i.add("测试"); //只添加一个元素
System.out.println(i.size()); //大小直接变成11
i.remove(10); //瞎移除都不带报错的,淦
}实际上,整个ArrayList体系由于我们的反射操作,导致被破坏,因此它已经无法正常工作了!
再次强调,在进行反射操作时,必须注意是否安全,虽然拥有了创世主的能力,但是我们不能滥用,我们只能把它当做一个不得已才去使用的工具!
我们可以自己手动将class文件加载到JVM中吗?先写好我们定义的类:
package com.test;
public class Test {
public String text;
public void test(String str){
System.out.println(text+" > 我是测试方法!"+str);
}
}通过javac命令,手动编译一个.class文件:
nagocoler@NagodeMacBook-Pro HelloWorld % javac src/main/java/com/test/Test.java编译后,得到一个class文件,我们把它放到根目录下,然后编写一个我们自己的ClassLoader,因为普通的ClassLoader无法加载二进制文件,因此我们编写一个自己的来让它支持:
//定义一个自己的ClassLoader
static class MyClassLoader extends ClassLoader{
public Class<?> defineClass(String name, byte[] b){
return defineClass(name, b, 0, b.length); //调用protected方法,支持载入外部class文件
}
}
public static void main(String[] args) throws IOException {
MyClassLoader classLoader = new MyClassLoader();
FileInputStream stream = new FileInputStream("Test.class");
byte[] bytes = new byte[stream.available()];
stream.read(bytes);
Class<?> clazz = classLoader.defineClass("com.test.Test", bytes); //类名必须和我们定义的保持一致
System.out.println(clazz.getName()); //成功加载外部class文件
}现在,我们就将此class文件读取并解析为Class了,现在我们就可以对此类进行操作了(注意,我们无法在代码中直接使用此类型,因为它是我们直接加载的),我们来试试看创建一个此类的对象并调用其方法:
try {
Object obj = clazz.newInstance();
Method method = clazz.getMethod("test", String.class); //获取我们定义的test(String str)方法
method.invoke(obj, "哥们这瓜多少钱一斤?");
}catch (Exception e){
e.printStackTrace();
}我们来试试看修改成员字段之后,再来调用此方法:
try {
Object obj = clazz.newInstance();
Field field = clazz.getField("text"); //获取成员变量 String text;
field.set(obj, "华强");
Method method = clazz.getMethod("test", String.class); //获取我们定义的test(String str)方法
method.invoke(obj, "哥们这瓜多少钱一斤?");
}catch (Exception e){
e.printStackTrace();
}通过这种方式,我们就可以实现外部加载甚至是网络加载一个类,只需要把类文件传递即可,这样就无需再将代码写在本地,而是动态进行传递,不仅可以一定程度上防止源代码被反编译(只是一定程度上,想破解你代码有的是方法),而且在更多情况下,我们还可以对byte[]进行加密,保证在传输过程中的安全性。
其实我们在之前就接触到注解了,比如@Override表示重写父类方法(当然不加效果也是一样的,此注解在编译时会被自动丢弃)注解本质上也是一个类,只不过它的用法比较特殊。
注解可以被标注在任意地方,包括方法上、类名上、参数上、成员属性上、注解定义上等,就像注释一样,它相当于我们对某样东西的一个标记。而与注释不同的是,注解可以通过反射在运行时获取,注解也可以选择是否保留到运行时。
JDK预设了以下注解,作用于代码:
- @Override - 检查(仅仅是检查,不保留到运行时)该方法是否是重写方法。如果发现其父类,或者是引用的接口中并没有该方法时,会报编译错误。
- @Deprecated - 标记过时方法。如果使用该方法,会报编译警告。
- @SuppressWarnings - 指示编译器去忽略注解中声明的警告(仅仅编译器阶段,不保留到运行时)
- @FunctionalInterface - Java 8 开始支持,标识一个匿名函数或函数式接口。
- @SafeVarargs - Java 7 开始支持,忽略任何使用参数为泛型变量的方法或构造函数调用产生的警告。
元注解是作用于注解上的注解,用于我们编写自定义的注解:
- @Retention - 标识这个注解怎么保存,是只在代码中,还是编入class文件中,或者是在运行时可以通过反射访问。
- @Documented - 标记这些注解是否包含在用户文档中。
- @Target - 标记这个注解应该是哪种 Java 成员。
- @Inherited - 标记这个注解是继承于哪个注解类(默认 注解并没有继承于任何子类)
- @Repeatable - Java 8 开始支持,标识某注解可以在同一个声明上使用多次。
看了这么多预设的注解,你们肯定眼花缭乱了,那我们来看看@Override是如何定义的:
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.SOURCE)
public @interface Override {
}该注解由@Target限定为只能作用于方法上,ElementType是一个枚举类型,用于表示此枚举的作用域,一个注解可以有很多个作用域。@Retention表示此注解的保留策略,包括三种策略,在上述中有写到,而这里定义为只在代码中。一般情况下,自定义的注解需要定义1个@Retention和1-n个@Target。
既然了解了元注解的使用和注解的定义方式,我们就来尝试定义一个自己的注解:
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface Test {
}这里我们定义一个Test注解,并将其保留到运行时,同时此注解可以作用于方法或是类上:
@Test
public class Main {
@Test
public static void main(String[] args) {
}
}这样,一个最简单的注解就被我们创建了。
我们还可以在注解中定义一些属性,注解的属性也叫做成员变量,注解只有成员变量,没有方法。注解的成员变量在注解的定义中以“无形参的方法”形式来声明,其方法名定义了该成员变量的名字,其返回值定义了该成员变量的类型:
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface Test {
String value();
}默认只有一个属性时,我们可以将其名字设定为value,否则,我们需要在使用时手动指定注解的属性名称,使用value则无需填入:
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface Test {
String test();
}public class Main {
@Test(test = "")
public static void main(String[] args) {
}
}我们也可以使用default关键字来为这些属性指定默认值:
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface Test {
String value() default "都看到这里了,给个三连吧!";
}当属性存在默认值时,使用注解的时候可以不用传入属性值。当属性为数组时呢?
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface Test {
String[] value();
}当属性为数组,我们在使用注解传参时,如果数组里面只有一个内容,我们可以直接传入一个值,而不是创建一个数组:
@Test("关注点了吗")
public static void main(String[] args) {
}public class Main {
@Test({"value1", "value2"}) //多个值时就使用花括号括起来
public static void main(String[] args) {
}
}既然我们的注解可以保留到运行时,那么我们来看看,如何获取我们编写的注解,我们需要用到反射机制:
public static void main(String[] args) {
Class<Student> clazz = Student.class;
for (Annotation annotation : clazz.getAnnotations()) {
System.out.println(annotation.annotationType()); //获取类型
System.out.println(annotation instanceof Test); //直接判断是否为Test
Test test = (Test) annotation;
System.out.println(test.value()); //获取我们在注解中写入的内容
}
}通过反射机制,我们可以快速获取到我们标记的注解,同时还能获取到注解中填入的值,那么我们来看看,方法上的标记是不是也可以通过这种方式获取注解:
public static void main(String[] args) throws NoSuchMethodException {
Class<Student> clazz = Student.class;
for (Annotation annotation : clazz.getMethod("test").getAnnotations()) {
System.out.println(annotation.annotationType()); //获取类型
System.out.println(annotation instanceof Test); //直接判断是否为Test
Test test = (Test) annotation;
System.out.println(test.value()); //获取我们在注解中写入的内容
}
}无论是方法、类、还是字段,都可以使用getAnnotations()方法(还有几个同名的)来快速获取我们标记的注解。
所以说呢,这玩意学来有啥用?丝毫get不到这玩意的用处。其实不是,现阶段你们还体会不到注解带来的快乐,在接触到Spring和SpringBoot等大型框架后,就能感受到注解带来的魅力了。