

Scala.Rx is a change propagation library for Scala. Scala.Rx gives you Reactive variables (Rxs), which are smart variables who auto-update themselves when the values they depend on change. The underlying implementation is push-based FRP based on the ideas in Deprecating the Observer Pattern.
A simple example which demonstrates the behavior is:
import rx._
val a = Var(1); val b = Var(2)
val c = Rx{ a() + b() }
println(c.now) // 3
a() = 4
println(c.now) // 6The idea being that 99% of the time, when you re-calculate a variable, you re-calculate it the same way you initially calculated it. Furthermore, you only re-calculate it when one of the values it depends on changes. Scala.Rx does this for you automatically, and handles all the tedious update logic for you so you can focus on other, more interesting things!
Apart from basic change-propagation, Scala.Rx provides a host of other functionality, such as a set of combinators for easily constructing the dataflow graph, compile time checks for a high degree of correctness, and seamless interop with existing Scala code. This means it can be easily embedded in an existing Scala application.
Scala.Rx is available on Maven Central. In order to get started, simply add the following to your build.sbt:
libraryDependencies += "com.lihaoyi" %% "scalarx" % "0.4.1"After that, opening up the sbt console and pasting the above example into the console should work! You can proceed through the examples in the Basic Usage page to get a feel for what Scala.Rx can do.
In addition to running on the JVM, Scala.Rx also compiles to Scala-Js! This artifact is currently on Maven Central and an be used via the following SBT snippet:
libraryDependencies += "com.lihaoyi" %%% "scalarx" % "0.4.1"There are some minor differences between running Scala.Rx on the JVM and in Javascript particularly around asynchronous operations, the parallelism model and memory model. In general, though, all the examples given in the documentation below will work perfectly when cross-compiled to javascript and run in the browser!
Scala.rx 0.4.1 is only compatible with ScalaJS 0.6.5+.
The primary operations only need a import rx._ before being used, with addtional operations also needing a import rx.ops._. Some of the examples below also use various imports from scala.concurrent or scalatest aswell.
import rx._
val a = Var(1); val b = Var(2)
val c = Rx{ a() + b() }
println(c.now) // 3
a() = 4
println(c.now) // 6The above example is an executable program. In general, import rx._ is enough to get you started with Scala.Rx, and it will be assumed in all further examples. These examples are all taken from the unit tests.
The basic entities you have to care about are Var, Rx and Obs:
- Var: a smart variable which you can get using
a()and set usinga() = .... Whenever its value changes, it pings any downstream entity which needs to be recalculated. - Rx: a reactive definition which automatically captures any Vars or other Rxs which get called in its body, flagging them as dependencies and re-calculating whenever one of them changes. Like a Var, you can use the
a()syntax to retrieve its value, and it also pings downstream entities when the value changes. - Obs: an observer on one or more Var s or Rx s, performing some side-effect when the observed node changes value and sends it a ping.
Using these components, you can easily construct a dataflow graph, and have the various values within the dataflow graph be kept up to date when the inputs to the graph change:
val a = Var(1) // 1
val b = Var(2) // 2
val c = Rx{ a() + b() } // 3
val d = Rx{ c() * 5 } // 15
val e = Rx{ c() + 4 } // 7
val f = Rx{ d() + e() + 4 } // 26
println(f.now) // 26
a() = 3
println(f.now) // 38The dataflow graph for this program looks like this:

Where the Vars are represented by squares, the Rxs by circles and the dependencies by arrows. Each Rx is labelled with its name, its body and its value.
Modifying the value of a causes the changes the propagate through the dataflow graph

As can be seen above, changing the value of a causes the change to propagate all the way through c d e to f. You can use a Var and Rx anywhere you an use a normal variable.
The changes propagate through the dataflow graph in waves. Each update to a Var touches off a propagation, which pushes the changes from that Var to any Rx which is (directly or indirectly) dependent on its value. In the process, it is possible for a Rx to be re-calculated more than once.
As mentioned, Obs s can be created from Rx s or Var s and be used to perform side effects when they change:
val a = Var(1)
var count = 0
val o = a.trigger {
count = a.now + 1
}
println(count) // 2
a() = 4
println(count) // 5This creates a dataflow graph that looks like:

When a is modified, the observer o will perform the side effect:

The body of Rxs should be side effect free, as they may be run more than once per propagation. You should use Obs s to perform your side effects, as they are guaranteed to run only once per propagation after the values for all Rxs have stabilized.
Scala.Rx provides a convenient .foreach() combinator, which provides an alternate way of creating an Obs from an Rx:
val a = Var(1)
var count = 0
val o = a.foreach{ x =>
count = x + 1
}
println(count) // 2
a() = 4
println(count) // 5This example does the same thing as the code above.
Note that the body of the Obs is run once initially when it is declared. This matches the way each Rx is calculated once when it is initially declared. but it is conceivable that you want an Obs which fires for the first time only when the Rx it is listening to changes. You can do this by using the alternate triggerLater syntax:
val a = Var(1)
var count = 0
val o = a.triggerLater {
count = count + 1
}
println(count) // 0
a() = 2
println(count) // 1An Obs acts to encapsulate the callback that it runs. They can be passed around, stored in variables, etc.. When the Obs gets garbage collected, the callback will stop triggering. Thus, an Obs should be stored in the object it affects: if the callback only affects that object, it doesn't matter when the Obs itself gets garbage collected, as it will only happen after that object holding it becomes unreachable, in which case its effects cannot be observed anyway. An Obs can also be actively shut off, if a stronger guarantee is needed:
val a = Var(1)
val b = Rx{ 2 * a() }
var target = 0
val o = b.trigger {
target = b.now
}
println(target) // 2
a() = 2
println(target) // 4
o.kill()
a() = 3
println(target) // 4After manually calling .kill(), the Obs no longer triggers. Apart from .kill()ing Obss, you can also kill Rxs, which prevents further updates.
In general, Scala.Rx revolves around constructing dataflow graphs which automatically keep things in sync, which you can easily interact with from external, imperative code. This involves using:
- Vars as inputs to the dataflow graph from the imperative world
- Rxs as the intermediate nodes in the dataflow graphs
- Obss as the output from the dataflow graph back into the imperative world
Rxs are not limited to Ints. Strings, Seq[Int]s, Seq[String]s, anything can go inside an Rx:
val a = Var(Seq(1, 2, 3))
val b = Var(3)
val c = Rx{ b() +: a() }
val d = Rx{ c().map("omg" * _) }
val e = Var("wtf")
val f = Rx{ (d() :+ e()).mkString }
println(f.now) // "omgomgomgomgomgomgomgomgomgwtf"
a() = Nil
println(f.now) // "omgomgomgwtf"
e() = "wtfbbq"
println(f.now) // "omgomgomgwtfbbq"As shown, you can use Scala.Rx's reactive variables to model problems of arbitrary complexity, not just trivial ones which involve primitive numbers.
Since the body of an Rx can be any arbitrary Scala code, it can throw exceptions. Propagating the exception up the call stack would not make much sense, as the code evaluating the Rx is probably not in control of the reason it failed. Instead, any exceptions are caught by the Rx itself and stored internally as a Try.
This can be seen in the following unit test:
val a = Var(1)
val b = Rx{ 1 / a() }
println(b.now) // 1
println(b.toTry) // Success(1)
a() = 0
intercept[ArithmeticException]{
b()
}
assert(b.toTry.isInstanceOf[Failure])Initially, the value of a is 1 and so the value of b also is 1. You can also extract the internal Try using b.toTry, which at first is Success(1).
However, when the value of a becomes 0, the body of b throws an ArithmeticException. This is caught by b and re-thrown if you try to extract the value from b using b(). You can extract the entire Try using toTry and pattern match on it to handle both the Success case as well as the Failure case.
When you have many Rxs chained together, exceptions propagate forward following the dependency graph, as you would expect. The following code:
val a = Var(1)
val b = Var(2)
val c = Rx{ a() / b() }
val d = Rx{ a() * 5 }
val e = Rx{ 5 / b() }
val f = Rx{ a() + b() + 2 }
val g = Rx{ f() + c() }
inside(c.toTry){case Success(0) => () }
inside(d.toTry){case Success(5) => () }
inside(e.toTry){case Success(2) => () }
inside(f.toTry){case Success(5) => () }
inside(g.toTry){case Success(5) => () }
b() = 0
inside(c.toTry){case Failure(_) => () }
inside(d.toTry){case Success(5) => () }
inside(e.toTry){case Failure(_) => () }
inside(f.toTry){case Success(3) => () }
inside(g.toTry){case Failure(_) => () }Creates a dependency graph that looks like the follows:

In this example, initially all the values for a, b, c, d, e, f and g are well defined. However, when b is set to 0:
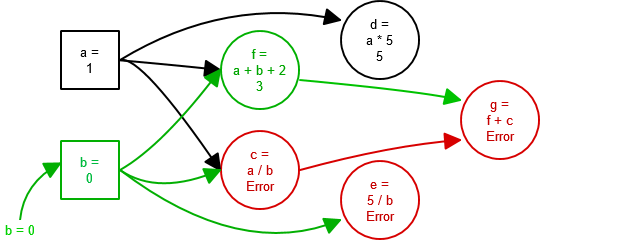
c and e both result in exceptions, and the exception from c propagates to g. Attempting to extract the value from g using g.now, for example, will re-throw the ArithmeticException. Again, using toTry works too.
Rxs can contain other Rxs, arbitrarily deeply. This example shows the Rxs nested two levels deep:
val a = Var(1)
val b = Rx{
(Rx{ a() }, Rx{ math.random })
}
val r = b.now._2.now
a() = 2
println(b.now._2.now) // rIn this example, we can see that although we modified a, this only affects the left-inner Rx, neither the right-inner Rx (which takes on a different, random value each time it gets re-calculated) or the outer Rx (which would cause the whole thing to re-calculate) are affected. A slightly less contrived example may be:
var fakeTime = 123
trait WebPage{
def fTime = fakeTime
val time = Var(fTime)
def update(): Unit = time() = fTime
val html: Rx[String]
}
class HomePage(implicit ctx: Ctx.Owner) extends WebPage {
val html = Rx{"Home Page! time: " + time()}
}
class AboutPage(implicit ctx: Ctx.Owner) extends WebPage {
val html = Rx{"About Me, time: " + time()}
}
val url = Var("www.mysite.com/home")
val page = Rx{
url() match{
case "www.mysite.com/home" => new HomePage()
case "www.mysite.com/about" => new AboutPage()
}
}
println(page.now.html.now) // "Home Page! time: 123"
fakeTime = 234
page.now.update()
println(page.now.html.now) // "Home Page! time: 234"
fakeTime = 345
url() = "www.mysite.com/about"
println(page.now.html.now) // "About Me, time: 345"
fakeTime = 456
page.now.update()
println(page.now.html.now) // "About Me, time: 456"In this case, we define a web page which has a html value (a Rx[String]). However, depending on the url, it could be either a HomePage or an AboutPage, and so our page object is a Rx[WebPage].
Having a Rx[WebPage], where the WebPage has an Rx[String] inside, seems natural and obvious, and Scala.Rx lets you do it simply and naturally. This kind of objects-within-objects situation arises very naturally when modelling a problem in an object-oriented way. The ability of Scala.Rx to gracefully handle the corresponding Rxs within Rxs allows it to gracefully fit into this paradigm, something I found lacking in most of the Related Work I surveyed.
Most of the examples here are taken from the unit tests, which provide more examples on guidance on how to use this library.
In the last example above, we had to introduce the concept of Ownership where Ctx.Owner is used. In fact, if we leave out (implicit ctx: Ctx.Owner), we would get the following compile time error:
error: This Rx might leak! Either explicitly mark it unsafe (Rx.unsafe) or ensure an implicit RxCtx is in scope!
val html = Rx{"Home Page! time: " + time()}To understand ownership it is important to understand the problem it fixes: leaks. As an example, consider this slight modification to the first example:
var count = 0
val a = Var(1); val b = Var(2)
def mkRx(i: Int) = Rx.unsafe { count += 1; i + b() }
val c = Rx{
val newRx = mkRx(a())
newRx()
}
println(c.now, count) //(3,1)In this version, the function mkRx was added, but otherwise the computed value of c remains unchanged. And modfying a appears to behave as expected:
a() = 4
println(c.now, count) //(6,2)But if we modify b we might start to notice something not quite right:
b() = 3
println(c.now, count) //(7,5) -- 5??
(0 to 100).foreach { i => a() = i }
println(c.now, count) //(103,106)
b() = 4
println(c.now, count) //(104,211) -- 211!!!In this example, even though b is only updated a few times, the count value starts to soar as a is modified. This is mkRx leaking! That is, every time c is recomputed, it builds a whole new Rx that sticks around and keeps on evaluating, even after it is no longer reachable as a data dependency and forgotten. So after running that (0 to 100).foreach statment, there are over 100 Rxs that all fire every time b is changed. This clearly is not desirable.
However, by adding an explicit owner (and removing unsafe), we can fix the leak:
var count = 0
val a = Var(1); val b = Var(2)
def mkRx(i: Int)(implicit ctx: Ctx.Owner) = Rx { count += 1; i + b() }
val c = Rx{
val newRx = mkRx(a())
newRx()
}
println(c.now,count) // (3,1)
a() = 4
println(c.now,count) // (6,2)
b() = 3
println(c.now,count) // (7,4)
(0 to 100).foreach { i => a() = i }
println(c.now,count) //(103,105)
b() = 4
println(c.now,count) //(104,107)Ownership fixes leaks by keeping allowing a parent Rx to track its "owned" nested Rx. That is whenever an Rx recaculates, it first kills all of its owned dependencies, ensuring they do not leak. In this example, c is the owner of all the Rxs which are created in mkRx and kills them automatically every time c recalculates.
Given either a Rx or a Var using () (aka apply) unwraps the current value and adds itself as a dependency to whatever Rx that is currently evaluating. Alternatively, .now can be used to simply unwrap the value and skips over becoming a data dependency:
val a = Var(1); val b = Var(2)
val c = Rx{ a.now + b.now } //not a very useful `Rx`
println(c.now) // 3
a() = 4
println(c.now) // 3
b() = 5
println(c.now) // 3 To understand the need for a Data context and how Data contexts differ from Owner contexts, consider the following example:
def foo()(implicit ctx: Ctx.Owner) = {
val a = rx.Var(1)
a()
a
}
val x = rx.Rx{val y = foo(); y() = y() + 1; println("done!") }With the concept of ownership, if a() is allowed to create a data dependency on its owner, it would enter infinite recursion and blow up the stack! Instead, the above code gives this compile time error:
<console>:17: error: No implicit Ctx.Data is available here!
a()We can "fix" the error by explicitly allowing the data dependencies (and see that the stack blows up):
def foo()(implicit ctx: Ctx.Owner, data: Ctx.Data) = {
val a = rx.Var(1)
a()
a
}
val x = rx.Rx{val y = foo(); y() = y() + 1; println("done!") }
...
at rx.Rx$Dynamic$Internal$$anonfun$calc$2.apply(Core.scala:180)
at scala.util.Try$.apply(Try.scala:192)
at rx.Rx$Dynamic$Internal$.calc(Core.scala:180)
at rx.Rx$Dynamic$Internal$.update(Core.scala:184)
at rx.Rx$.doRecalc(Core.scala:130)
at rx.Var.update(Core.scala:280)
at $anonfun$1.apply(<console>:15)
at $anonfun$1.apply(<console>:15)
at rx.Rx$Dynamic$Internal$$anonfun$calc$2.apply(Core.scala:180)
at scala.util.Try$.apply(Try.scala:192)
...The Data context is the mechanism that an Rx uses to decide when to recaculate. Ownership fixes the problem of leaking. Mixing the two can lead to infinite recursion: when something is both owned and a data dependency of the same parent Rx.
Luckily though it is almost always the case that only one or the other context is needed. when dealing with dynamic graphs, it is almost always the case that only the ownership context is needed, ie functions most often have the form:
def f(...)(implicit ctx: Ctx.Owner) = Rx { ... }The Data context is needed less often and is useful in, as an example, the case where it is desirable to DRY up some repeated Rx code. Such a funtion would have this form:
def f(...)(implicit data: Ctx.Data) = ...This would allow some shared data dependency to be pulled out of the body of each Rx and into the shared function.
By splitting up the orthogonal concepts of ownership and data dependencies the problem of infinite recursion as outlined above is greatly limited. Explicit data dependencies also make it more clear when the use of a Var or Rx is meant to be a data dependency, and not just a simple read of the current value (ie .now). Without this distiction, it is easier to introduce "accidental" data dependencies that are unexpected and unintended.
Apart from the basic building blocks of Var/Rx/Obs, Scala.Rx also provides a set of combinators which allow your to easily transform your Rxs; this allows the programmer to avoid constantly re-writing logic for the common ways of constructing the dataflow graph. The five basic combinators: map(), flatMap, filter(), reduce() and fold() are all modelled after the scala collections library, and provide an easy way of transforming the values coming out of an Rx.
val a = Var(10)
val b = Rx{ a() + 2 }
val c = a.map(_*2)
val d = b.map(_+3)
println(c.now) // 20
println(d.now) // 15
a() = 1
println(c.now) // 2
println(d.now) // 6map does what you would expect, creating a new Rx with the value of the old Rx transformed by some function. For example, a.map(_*2) is essentially equivalent to Rx{ a() * 2 }, but somewhat more convenient to write.
val a = Var(10)
val b = Var(1)
val c = a.flatMap(a => Rx { a*b() })
println(c.now) // 10
b() = 2
println(c.now) // 20flatMap is analogous to flatMap from the collections library in that it allows for merging nested Rx s of type Rx[Rx[_]] into a single Rx[_].
This in conjunction with the map combinator allow for scala's for comprehension syntax to work with Rx s and Var s:
val a = Var(10)
val b = for {
aa <- a
bb <- Rx { a() + 5}
cc <- Var(1).map(_*2)
} yield {
aa + bb + cc
}val a = Var(10)
val b = a.filter(_ > 5)
a() = 1
println(b.now) // 10
a() = 6
println(b.now) // 6
a() = 2
println(b.now) // 6
a() = 19
println(b.now) // 19filter ignores changes to the value of the Rx that fail the predicate.
Note that none of the filter methods is able to filter out the first, initial value of a Rx, as there is no "older" value to fall back to. Hence this:
val a = Var(2)
val b = a.filter(_ > 5)
println(b.now)will print out "2".
val a = Var(1)
val b = a.reduce(_ * _)
a() = 2
println(b.now) // 2
a() = 3
println(b.now) // 6
a() = 4
println(b.now) // 24The reduce operator combines subsequent values of an Rx together, starting from the initial value. Every change to the original Rx is combined with the previously-stored value and becomes the new value of the reduced Rx.
val a = Var(1)
val b = a.fold(List.empty[Int])((acc,elem) => elem :: acc)
a() = 2
println(b.now) // List(2,1)
a() = 3
println(b.now) // List(3,2,1)
a() = 4
println(b.now) // List(4,3,2,1)Fold enables accumulation in a similar way to reduce, but can accumulate to some other type than that of the source Rx.
Each of these five combinators has a counterpart in the .all namespace which operates on Try[T]s rather than Ts, in the case where you need the added flexibility to handle Failures in some special way.
These are combinators which do more than simply transforming a value from one to another. These have asynchronous effects, and can spontaneously modify the dataflow graph and begin propagation cycles without any external trigger. Although this may sound somewhat unsettling, the functionality provided by these combinators is often necessary, and manually writing the logic around something like Debouncing, for example, is far more error prone than simply using the combinators provided.
Note that none of these combinators are doing anything that cannot be done via a combination of Obss and Vars; they simply encapsulate the common patterns, saving you manually writing them over and over, and reducing the potential for bugs.
import scala.concurrent.Promise
import scala.concurrent.ExecutionContext.Implicits.global
import rx.async._
val p = Promise[Int]()
val a = p.future.toRx(10)
println(a.now) //10
p.success(5)
println(a.now) //5The toRx combinator only applies to Future[_]s. It takes an initial value, which will be the value of the Rx until the Future completes, at which point the the value will become the value of the Future.
This async can create Futures as many times as necessary. This example shows it creating two distinct Futures:
import scala.concurrent.Promise
import scala.concurrent.ExecutionContext.Implicits.global
import rx.async._
var p = Promise[Int]()
val a = Var(1)
val b: Rx[Int] = Rx {
val f = p.future.toRx(10)
f() + a()
}
println(b.now) //11
p.success(5)
println(b.now) //6
p = Promise[Int]()
a() = 2
println(b.now) //12
p.success(7)
println(b.now) //9The value of b() updates as you would expect as the series of Futures complete (in this case, manually using Promises).
This is handy if your dependency graph contains some asynchronous elements. For example, you could have a Rx which depends on another Rx, but requires an asynchronous web request to calculate its final value. With async, the results from the asynchronous web request will be pushed back into the dataflow graph automatically when the Future completes, starting off another propagation run and conveniently updating the rest of the graph which depends on the new result.
import rx.async._
import rx.async.Platform._
import scala.concurrent.duration._
val t = Timer(100 millis)
var count = 0
val o = t.trigger {
count = count + 1
}
println(count) // 3
println(count) // 8
println(count) // 13A Timer is a Rx that generates events on a regular basis. In the example above, using println in the console show that the value t() has increased over time.
The scheduled task is cancelled automatically when the Timer object becomes unreachable, so it can be garbage collected. This means you do not have to worry about managing the life-cycle of the Timer. On the other hand, this means the programmer should ensure that the reference to the Timer is held by the same object as that holding any Rx listening to it. This will ensure that the exact moment at which the Timer is garbage collected will not matter, since by then the object holding it (and any Rx it could possibly affect) are both unreachable.
import rx.async._
import rx.async.Platform._
import scala.concurrent.duration._
val a = Var(10)
val b = a.delay(250 millis)
a() = 5
println(b.now) // 10
eventually{
println(b.now) // 5
}
a() = 4
println(b.now) // 5
eventually{
println(b.now) // 4
}The delay(t) combinator creates a delayed version of an Rx whose value lags the original by a duration t. When the Rx changes, the delayed version will not change until the delay t has passed.
This example shows the delay being applied to a Var, but it could easily be applied to an Rx as well.
import rx.async._
import rx.async.Platform._
import scala.concurrent.duration._
val a = Var(10)
val b = a.debounce(200 millis)
a() = 5
println(b.now) // 5
a() = 2
println(b.now) // 5
eventually{
println(b.now) // 2
}
a() = 1
println(b.now) // 2
eventually{
println(b.now) // 1
}The debounce(t) combinator creates a version of an Rx which will not update more than once every time period t.
If multiple updates happen with a short span of time (less than t apart), the first update will take place immediately, and a second update will take place only after the time t has passed. For example, this may be used to limit the rate at which an expensive result is re-calculated: you may be willing to let the calculated value be a few seconds stale if it lets you save on performing the expensive calculation more than once every few seconds.
This meant that the syntax to write programs in a dependency-tracking way had to be as light weight as possible, that programs written using FRP had to look like their normal, old-fashioned, imperative counterparts. This meant using DynamicVariable instead of implicits to automatically pass arguments, sacrificing proper lexical scoping for nice syntax.
I ruled out using a purely monadic style (like reactive-web), as although it would be far easier to implement the library in that way, it would be a far greater pain to actually use it. I also didn't want to have to manually declare dependencies, as this violates DRY when you are declaring your dependencies twice: once in the header of the Rx, and once more when you use it in the body.
The goal was to be able to write code, sprinkle a few Rx{}s around and have the dependency tracking and change propagation just work. Overall, I believe it has been quite successful at that!
This means many things, but most of all it means having no globals. This greatly simplifies many things for someone using the library, as you no longer need to reason about different parts of your program interacting through the library. Using Scala.Rx in different parts of a large program is completely fine; they are completely independent.
Another design decision in this area was to have the parallelism and propagation-scheduling be left mainly to an implicit ExecutionContext, and have the default to simply run the propagation wave on whatever thread made the update to the dataflow graph.
- The former means that anyone who is used to writing parallel programs in Scala/Akka is already familiar with how to deal with parallelizing Scala.Rx
- The latter makes it far easier to reason about when propagations happen, at least in the default case: it simply happens right away, and by the time that
Var.update()function has returned, the propagation has completed.
Overall, limiting the range of side effects and removing global state makes Scala.Rx easy to reason about, and means a developer can focus on using Scala.Rx to construct dataflow graphs rather than worry about un-predictable far-reaching interactions or performance bottlenecks.
This meant that it had to be easy for a programmer to drop in and out of the FRP world. Many of the papers I read in preparing for Scala.Rx described systems that worked brilliantly on their own, and had some amazing properties, but required that the entire program be written in an obscure variant of an obscure language. No thought at all was given to inter-operability with existing languages or paradigms, which makes it impossible to incrementally introduce FRP into an existing codebase.
With Scala.Rx, I resolved to do things differently. Hence, Scala.Rx:
- Is written in Scala: an uncommon, but probably less-obscure language than Haskell or Scheme
- Is a library: it is plain-old-scala. There is no source-to-source transformation, no special runtime necessary to use Scala.Rx. You download the source code into your Scala project, and start using it
- Allows you to use any programming language construct or library functionality within your Rxs: Scala.Rx will figure out the dependencies without the programmer having to worry about it, without limiting yourself to some inconvenient subset of the language
- Allows you to use Scala.Rx within a larger project without much pain. You can easily embed dataflow graphs within a larger object-oriented universe and interact with them via setting Vars and listening to Obss
Many of the papers reviewed show a beautiful new FRP universe that we could be programming in, if only you ported all your code to FRP-Haskell and limited yourself to the small set of combinators used to create dataflow graphs. On the other hand, by letting you embed FRP snippets anywhere within existing code, using FRP ideas in existing projects without full commitment, and allowing you easy interop between your FRP and non-FRP code, Scala.Rx aims to bring the benefits FRP into the dirty, messy universe which we are programming in today.
Scala.Rx has a number of significant limitations, some of which arise from trade-offs in the design, others from the limitations of the underlying platform.
The API of Rxs in Scala.Rx tries to follow the collections API as far as possible: you can map, filter and reduce over the Rxs, just as you can over collections. However, it is currently impossible to have a Rx which is empty in the way a collection can be empty: filtering out all values in a Rx will still leave at least the initial value (even if it fails the predicate) and Async Rxs need to be given an initial value to start.
This limitation arises from the difficulty in joining together possibly empty Rxs with good user experience. For example, if I have a dataflow graph:
val a = Var()
val b = Var()
var c = Rx{
.... a() ...
... some computation ...
... b() ...
result
}Where a and b are initially empty, I have basically four options:
- Block the current thread which is computing
c, waiting foraand thenbto become available. - Throw an exception when
a()andb()are requested, aborting the computation ofcbut registering it to be restarted whena()orb()become available. - Re-write this in a monadic style using for-comprehensions.
- Use the delimited continuations plugin to transform the above code to monadic code automatically.
The first option is a performance problem: threads are generally extremely heavy weight on most operation systems. You cannot reasonably make more than a few thousand threads, which is a tiny number compared to the amount of objects you can create. Hence, although blocking would be the easiest, it is frowned upon in many systems (e.g. in Akka, which Scala.Rx is built upon) and does not seem like a good solution.
The second option is a performance problem in a different way: with n different dependencies, all of which may start off empty, the computation of c may need to be started and aborted n times even before completing even once. Although this does not block any threads, it does seem extremely expensive.
The third option is a no-go from a user experience perspective: it would require far reaching changes in the code base and coding style in order to benefit from the change propagation, which I'm not willing to require.
The last option is problematic due to the bugginess of the delimited continuations plugin. Although in theory it should be able to solve everything, a large number of small bugs (messing up type inferencing, interfering with implicit resolution) combined with a few fundamental problems meant that even on a small scale project (less than 1000 lines of reactive code) it was getting painful to use.
As mentioned earlier, Scala.Rx can perform automatic parallelization of updates occurring in the dataflow graph: simply provide an appropriate ExecutionContext, and independent Rxs will have their updates spread out over multiple cores.
However, this only works for updates, and not when the dataflow graph is being initially defined: in that case, every Rx evaluates its body once in order to get its default value, and it all happens serially on the same thread. This limitation arises from the fact that we do not have a good way to work with "empty" Rxs, and we do not know what an Rxs dependencies are before the first time we evaluate it.
Hence, we cannot start all our Rxs evaluating in parallel as some may finish before others they depend on, which would then be empty, their initial value still being computed. We also cannot choose to parallelize those which do not have dependencies on each other, as before execution we do not know what the dependencies are!
Thus, we have no choice but to have the initial definitions of Rxs happen serially. If necessary, a programmer can manually create independent Rxs in parallel using Futures.
In the context of FRP, a glitch is a temporary inconsistency in the dataflow graph. Due to the fact that updates do not happen instantaneously, but instead take time to compute, the values within an FRP system may be transiently out of sync during the update process. Furthermore, depending on the nature of the FRP system, it is possible to have nodes be updated more than once in a propagation.
This may or may not be a problem, depending on how tolerant the application is of occasional stale inconsistent data. In a single-threaded system, it can be avoided in a number of ways
- Make the dataflow graph static, and perform a topological sort to rank nodes in the order they are to be updated. This means that a node always is updated after its dependencies, meaning they will never see any stale data
- Pause the updating of a node when it tries to call upon a dependency which has not been updated. This could be done by blocking the thread, for example, and only resuming after the dependency has been updated.
However, both of these approaches have problems. The first approach is extremely constrictive: a static dataflow graph means that a large amount of useful behavior, e.g. creating and destroying sections of the graph dynamically at run-time, is prohibited. This goes against Scala.Rx's goal of allowing the programmer to write code "normally" without limits, and letting the FRP system figure it out.
The second case is a problem for languages which do not easily allow computations to be paused. In Java, and by extension Scala, the threads used are operating system (OS) threads which are extremely expensive. Hence, blocking an OS thread is frowned upon. Coroutines and continuations could also be used for this, but Scala lacks both of these facilities.
The last problem is that both these models only make sense in the case of single threaded, sequential code. As mentioned on the section on Concurrency and Parallelism, Scala.Rx allows you to use multiple threads to parallelize the propagation, and allows propagations to be started by multiple threads simultaneously. That means that a strict prohibition of glitches is impossible.
Scala.Rx maintains somewhat looser model: the body of each Rx may be evaluated more than once per propagation, and Scala.Rx only promises to make a "best-effort" attempt to reduce the number of redundant updates. Assuming the body of each Rx is pure, this means that the redundant updates should only affect the time taken and computation required for the propagation to complete, but not affect the value of each node once the propagation has finished.
In addition, Scala.Rx provides the Obss, which are special terminal-nodes guaranteed to update only once per propagation, intended to produce some side effect. This means that although a propagation may cause the values of the Rxs within the dataflow graph to be transiently out of sync, the final side-effects of the propagation will only happen once the entire propagation is complete and the Obss all fire their side effects.
If multiple propagations are happening in parallel, Scala.Rx guarantees that each Obs will fire at most once per propagation, and at least once overall. Furthermore, each Obs will fire at least once after the entire dataflow graph has stabilized and the propagations are complete. This means that if you are relying on Obs to, for example, send updates over the network to a remote client, you can be sure that you don't have any unnecessary chatter being transmitted over the network, and when the system is quiescent the remote client will have the updates representing the most up-to-date version of the dataflow graph.
Scala.Rx was not created in a vacuum, and borrows ideas and inspiration from a range of existing projects.
Scala.React, as described in Deprecating the Observer Pattern, contains a reactive change propagation portion (there called Signals) which is similar to what Scala.Rx does. However, it does much more than that: It contains implementations for using event-streams, and multiple DSLs using delimited continuations in order to make it easy to write asynchronous workflows.
I have used this library, and my experience is that it is extremely difficult to set up and get started. It requires a fair amount of global configuration, with a global engine doing the scheduling and propagation, even running its own thread pools. This made it extremely difficult to reason about interactions between parts of the programs: would completely-separate dataflow graphs be able to affect each other through this global engine? Would the performance of multithreaded code start to slow down as the number of threads rises, as the engine becomes a bottleneck? I never found answers to many of these questions, and had did not manage to contact the author.
The global propagation engine also makes it difficult to get started. It took several days to get a basic dataflow graph (similar to the example at the top of this document) working. That is after a great deal of struggling, reading the relevant papers dozens of times and hacking the source in ways I didn't understand. Needless to say, these were not foundations that I would feel confident building upon.
reactive-web was another inspiration. It is somewhat orthogonal to Scala.Rx, focusing more on event streams and integration with the Lift web framework, while Scala.Rx focuses purely on time-varying values.
Nevertheless, reactive-web comes with its own time-varying values (called Signals), which are manipulated using combinators similar to those in Scala.Rx (map, filter, flatMap, etc.). However, reactive-web does not provide an easy way to compose these Signals: the programmer has to rely entirely on map and flatMap, possibly using Scala's for-comprehensions.
I did not like the fact that you had to program in a monadic style (i.e. living in .map() and .flatMap() and for{} comprehensions all the time) in order to take advantage of the change propagation. This is particularly cumbersome in the case of [nested Rxs](Basic-Usage#nesting), where Scala.Rx's
// a b and c are Rxs
x = Rx{ a() + b().c() }becomes
x = for {
va <- a
vb <- b
vc <- vb.c
} yield (va + vc)As you can see, using for-comprehensions as in reactive-web results in the code being significantly longer and much more obfuscated.
Knockout.js does something similar for Javascript, along with some other extra goodies like DOM-binding. In fact, the design and implementation and developer experience of the automatic-dependency-tracking is virtually identical. This:
this.firstName = ko.observable('Bob');
this.lastName = ko.observable('Smith');
fullName = ko.computed(function() {
return this.firstName() + " " + this.lastName();
}, this);is semantically equivalent to the following Scala.Rx code:
val firstName = Var("Bob")
val lastName = Var("Smith")
fullName = Rx{ firstName() + " " + lastName() }a ko.observable maps directly onto a Var, and a kocomputed maps directly onto an Rx. Apart from the longer variable names and the added verbosity of Javascript, the semantics are almost identical.
Apart from providing an equivalent of Var and Rx, Knockout.js focuses its efforts in a different direction. It lacks the majority of the useful combinators that Scala.Rx provides, but provides a great deal of other functionality, for example integration with the browser's DOM, that Scala.Rx lacks.
This idea of change propagation, with time-varying values which notify any value which depends on them when something changes, part of the field of Functional Reactive Programming. This is a well studied field with a lot of research already done. Scala.Rx builds upon this research, and incorporates ideas from the following projects:
All of these projects are filled with good ideas. However, generally they are generally very much research projects: in exchange for the benefits of FRP, they require you to write your entire program in an obscure variant of an obscure language, with little hope inter-operating with existing, non-FRP code.
Writing production software in an unfamiliar paradigm such as FRP is already a significant risk. On top of that, writing production software in an unfamiliar language is an additional variable, and writing production software in an unfamiliar paradigm in an unfamiliar language with no inter-operability with existing code is downright reckless. Hence it is not surprising that these libraries have not seen significant usage. Scala.Rx aims to solve these problems by providing the benefits of FRP in a familiar language, with seamless interop between FRP and more traditional imperative or object-oriented code.
- Dropped Scala 2.10 support
- Added Bidirectional
Vars and friends - Fixed multiple rx "glitches"
- Bumped to Scala 2.12.0.
-
Fixed leak with observers (they also require an owning context).
-
Fixed type issue with
flatMap
-
Introduced
OwnerandDatacontext. This is a completely different implementation of dependency and lifetime managment that allows for safe construction of runtime dynamic graphs. -
More default combinators:
foldandflatMapare now implemented by default.
Copyright (c) 2013, Li Haoyi (haoyi.sg at gmail.com)
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.