A small, standalone version of llamapcpp with an API wrapper and Vulkan GPU acceleration.
There seems to be no trivial way to initialize, send text, and receive text from language models directly in C++ code. This project aims to make the process extremely simple by adding a few functions that take care of everything under the hood. Vulkan was chosen as the accelerator due to its crossplatform GPU and OS support.
- Clone or download a zip of the project
- launch "llamacpp wrapper.vcxproj" using Visual Studio 2022
- Ensure the project is in release mode, not debug mode
- Download the Vulkan SDK. It might work without the SDK if n_gpu_layers is set to 0, untested
- Update: You will need to adjust the include and library / linker directory names based on your version of the SDK
- Change 'the_language_model.params.model' in "main.cpp" to the path of your language model. A language model is not included with this project
- Optionally comment the fixed 'params.seed' assignment in "api_wrapper.cpp" to get a different response each time the program runs
- Run the Local Windows Debugger
Note: This project was a proof of concept, do not expect the dependencies to be updated.
Code initialization (main.cpp) looks like this:
#include "api_wrapper.h"
void main() {
language_model the_language_model;
the_language_model.params.model = "C:/Users/Quill/Documents/ai/models/mistral-7b-v0.1.Q8_0.gguf";
the_language_model.params.interactive = true;
the_language_model.params.interactive_first = true;
the_language_model.params.antiprompt.push_back("User:");//the phrase the model outputs when it passes control back. Some models might output EOS instead
the_language_model.params.n_gpu_layers = 81;
the_language_model.initialize();
std::string input_text;
std::string output_text;
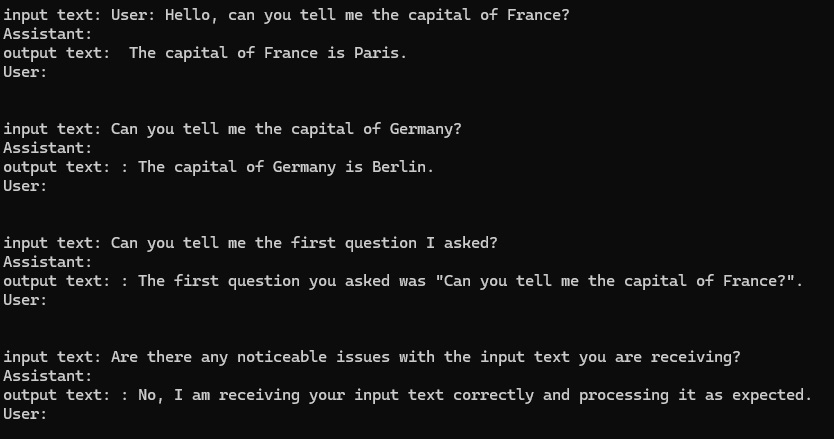
input_text = "User: Hello, can you tell me the capital of France?\nAssistant:";
output_text.resize(0);
the_language_model.send_input_and_receive_output(input_text, output_text);
printf("\n\n");
printf("input text: %s\n", input_text.c_str());
printf("output text: %s\n", output_text.c_str());Using the Mistral 7B Q8_0 GGUF model with a fixed params.seed of 12345678 yields the following result. It should be noted that different model and seed combinations may result in the model failing to output the reverse-prompt token and getting stuck: