Cloud uploader

In the frontend we store Cloud::EC2::Configuration which holds the user external ID and ARN. For every upload the user trigger, we store an EC2::User::UploadJob object which only stores the backend id. This is necessary as the backend has no user concept and we need to query the backend for e.g. all user upload jobs.
The users will obtain an external ID (automatically created and unique) and the OBS account ID to create an Identity and Access Management (IAM) role. After the user created the role, he needs to provide the Amazon Resource Name (ARN) of the role to OBS which stores it in Cloud::EC2::Configuration. OBS will use the ARN to obtain temporary credentials for the users account to upload the appliance. The ARN and the external ID are not considered as a secret.
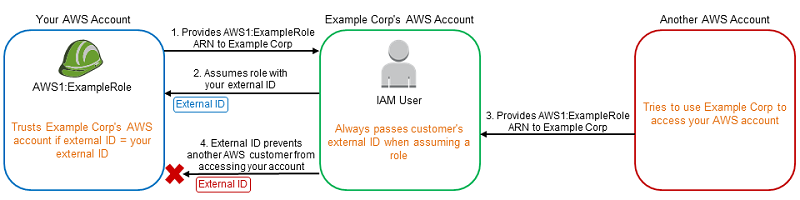
The whole workflow is described in the AWS documentation.
-
awsCLI to obtain the temporary credentials -
ec2uploadimgto execute the actual upload job
The configurations are stored in /etc/obs/cloudupload (the clouduploader home directory). In this directory is a .ec2utils.conf which contains e.g. the helper instance AMIs. In /.aws/credentials are the AWS credentials of the OBS account stored.
The job triggers the /root/bs/clouduploader script, see the next section for the parameters etc.
API call:
POST /cloudupload?
project=project_name&
package=package_name&
repository=repository_name&
arch=architecture_name&
user=user_name&
target=target_name
The target is the target platform, valid values are: ec2.
As body it will accept JSON data which will be provided to the upload script.
For EC2 it is:
{
'arn': 'amazon resource name', # stored in Cloud::Ec2::Configuration
'external_id': 'external_id', # stored in Cloud::Ec2::Configuration
'region': 'us-east-1'
}
The body data will be available to the uploader script as a file input.
Response:
The return of the POST is a xml data, like this:
<clouduploadjob name="6">
<state>created</state>
<details>waiting to receive image</details>
<created>1513604055</created>
<user>mlschroe</user>
<target>ec2</target>
<project>Base:System</project>
<repository>openSUSE_Factory</repository>
<package>rpm</package>
<arch>x86_64</arch>
<filename>rpm-4.14.0-504.2.x86_64.rpm</filename>
<size>1690860</size>
</clouduploadjob>
The job id is returned in the name attribute and will be stored in Cloud::User::UploadJob.
The UploadJob can have the following states:
created # job was just created
receiving # the image is transfered to the upload server
scheduled # ready for upload, waiting for free slot
uploading # upload in progress
succeeded # upload is done
failed # upload did not work
The upload scripts are currently called with the following arguments:
<user> <target> <upload_file> <targetdata> <logfile>
The file contains the body of the POST. The upload script is located here: /usr/lib/obs/server/clouduploader. To get to know how these scripts work, please have a look at the according wiki pages.
API call:
GET /cloudupload?name=job_id&name=job_id...
Response:
<clouduploadjoblist>
<clouduploadjob name="2">
<state>uploading</state>
<created>1513603428</created>
<user>mlschroe</user>
<target>ec2</target>
<project>Base:System</project>
<repository>openSUSE_Factory</repository>
<package>rpm</package>
<arch>x86_64</arch>
<filename>rpm-4.14.0-504.2.x86_64.rpm</filename>
<size>1690860</size>
<pid>18788</pid>
</clouduploadjob>
<clouduploadjob name="3">
<state>uploading</state>
<created>1513603663</created>
<user>mlschroe</user>
<target>ec2</target>
<project>Base:System</project>
<repository>openSUSE_Factory</repository>
<package>rpm</package>
<arch>x86_64</arch>
<filename>rpm-4.14.0-504.2.x86_64.rpm</filename>
<size>1690860</size>
<pid>18790</pid>
</clouduploadjob>
</clouduploadjoblist>
API call:
GET /cloudupload/<job>/_log
Response:
The log file of the upload job.
API call:
POST /cloudupload/<job>
with POST data command=kill
Reponse:
- The upload job exists
Kills the upload job and return the status xml of the job (see GET /cloudupload?name=job_id).
- The upload job does not exist
The backend will response with a 404.
Note: For now the backend will only kill the running job, there will be no cleanup in the cloud (e.g. stopping of running helper instances) neither will the backend delete the files on the backend. The frontend will also keep the Cloud::User::UploadJobs as history in the database.