【2020 USENIX ATC CCFA】Serverless in the Wild Characterizing and Optimizing the Serverless Workload at a Large Cloud Provider #1
Comments
|
这篇文章的主要贡献有两点
FaaS Workloads Characterization三个重要观察结论
Functions, Applications, and Triggers
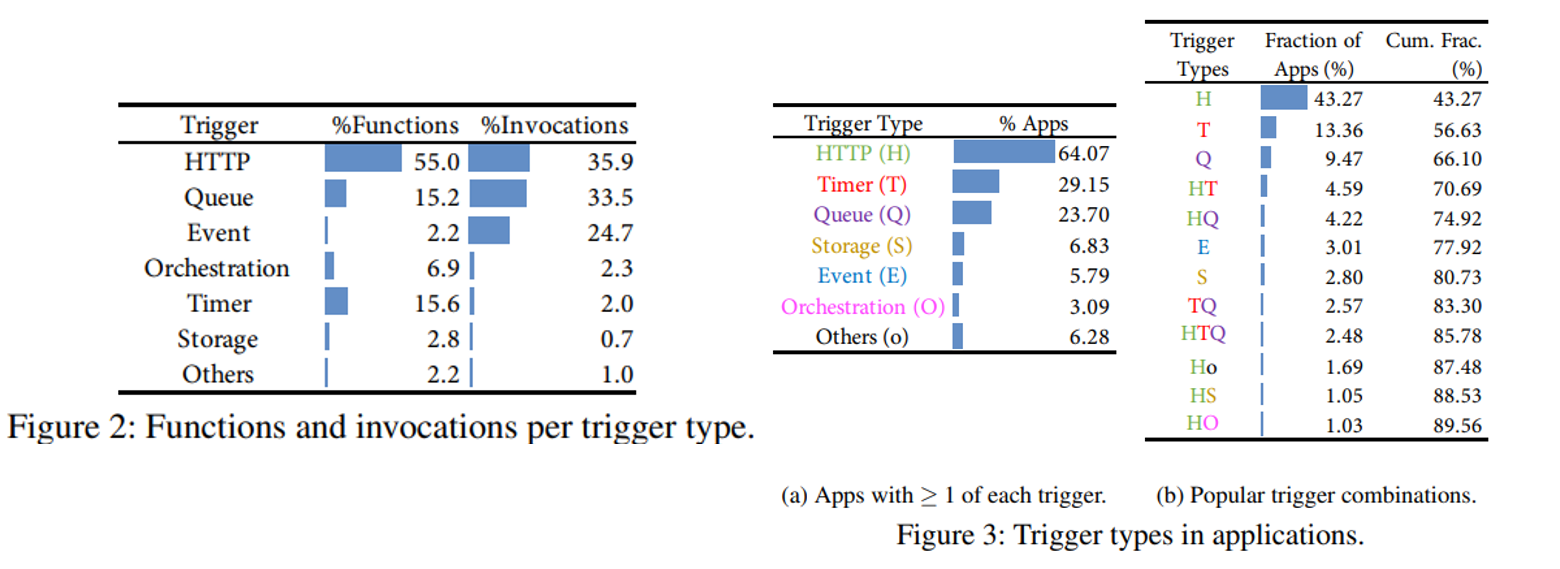
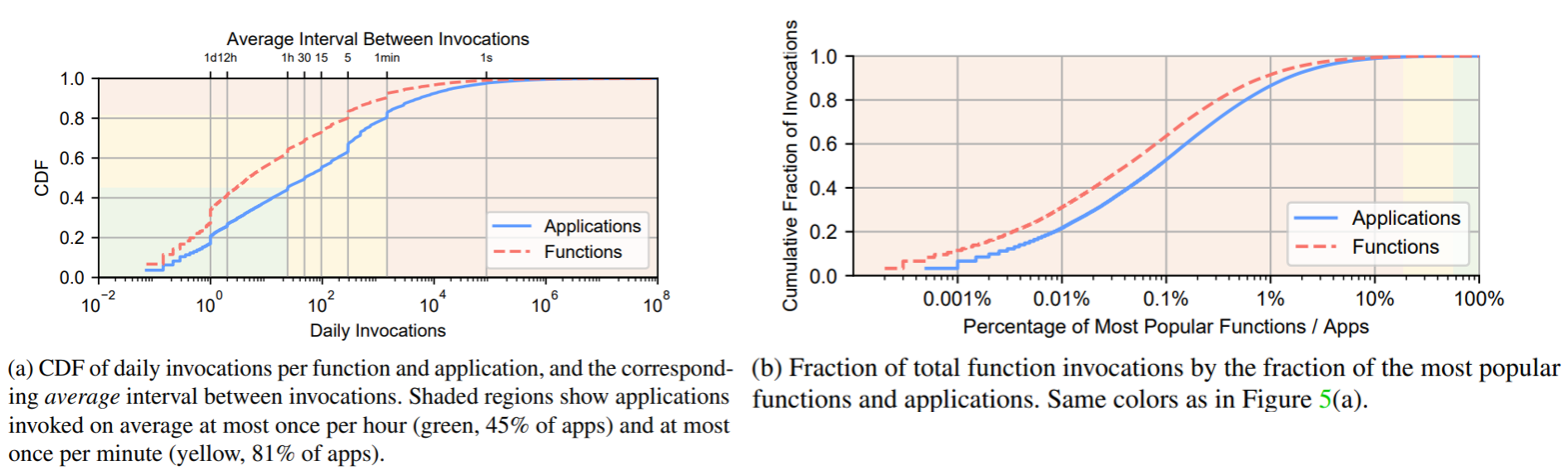
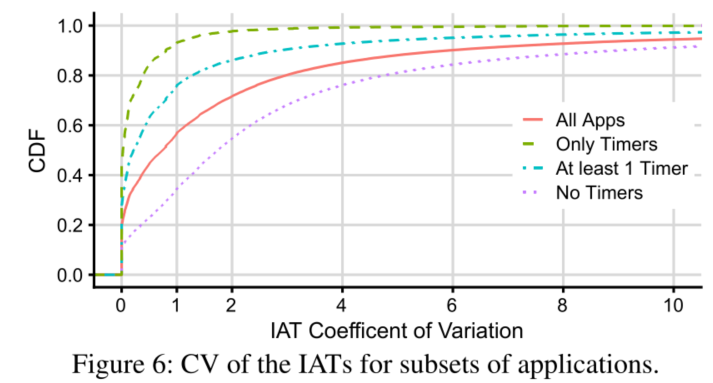
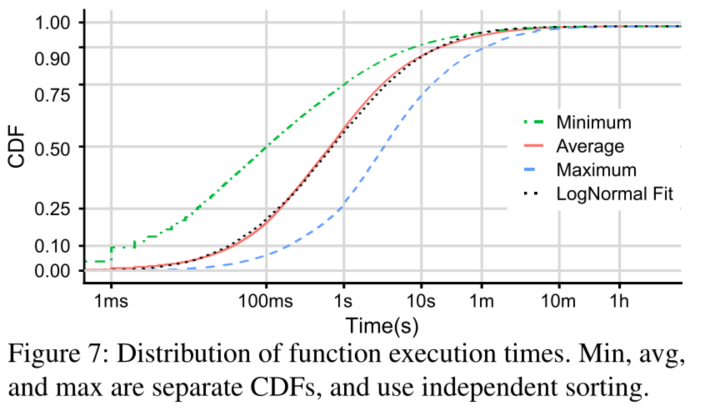
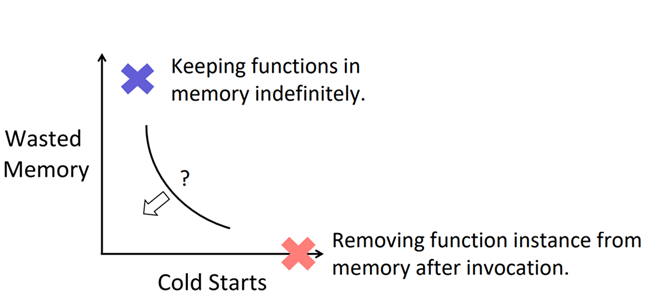
图3a显示了应用程序由许多不同类型的触发器组合而成,图3b根据触发器组合模式对应用程序进行了分区。 Invocation Patterns图 5a 展示了平均每天应用程序/函数调用次数的 CDF(应用程序的调用次数是其它自身所有函数调用总和),从横坐标可以看出不同 app/函数在调用次数上相差超过8 个数量级,而且绝大多数 app 和函数调用次数都很低,45%的应用程序每小时被调用一次或更少(对应于图5a中的绿色阴影部分),81% 的应用程序每分钟被调用一下或更少。这表明,相比于总执行计费时间,keep alive 的代价其实很高。 图 5b 则展示最受欢迎的函数/应用的累积调用比例,橙色阴影区域中的应用最受欢迎的,占比18.6%,平均每分钟至少被调用一次,但它们却占所有函数调用的99.6%。图5a和图5b的颜色具有相同的代表意义。 Inter-arrival time(IAT) variabilityIAT:到达间隔时间,两次函数调用的到达间隔 用 CV 衡量该指标,CV 为标准偏差除以平均值。因此如果是一个定时任务,那么 CV = 0,如果人为产生的调用 符合泊松到达过程,则CV=1。 图6说明真实的 IAT 分布比简单的周期分布和指数分布(无记忆分布)要复杂得多。例如在仅有定时器触发器的应用程序中(绿色曲线),竟只有50%的CV=0,对于至少有一个定时器的应用,这个比例低于 30%,具有不同周期的多个定时器将增加 CV 值。而10% 没有定时器的应用程序的 CV 接近0,这意味着它们是相当周期性的,应该是可预测的。另一方面,只有一小部分应用的 CV 值接近于 1,这意味着简单的泊松到达不是常态。这些结果表明,有相当一部分应用程序应该具有相当可预测的 IAT,即使它们没有定时器触发器。同时,对于许多应用来说,预测 IAT 并不是一件小事。 Function Execution Times50% 的函数平均执行时间小于1s,50% 的函数最大执行时间短于 ∼3s;90% 的函数最多花 60s,96% 的函数平均花不到 60s。而且函数执行时间与冷启动函数所需的时间在同一个量级,因此减少冷启动次数或大幅提高冷启动速度至关重要。 Trade between cold starts and memory wasted如果一直将函数镜像内容保存在内存中,这样无疑会避免冷启动问题,但付出的代价太昂贵,服务提供商是无法接受的,如果一旦函数执行完毕,就将函数卸载,移出内存,很显然又会出现冷启动问题,因此需要在冷启动和内存消耗之间作一个平衡。 已知云服务提供商的策略如下: Amazon Lambda:Fixed 10-minute keep-alive Azure Functions:Fixed 20-minute keep-alive OpenWhisk:Fixed 10-minute keep-alive |
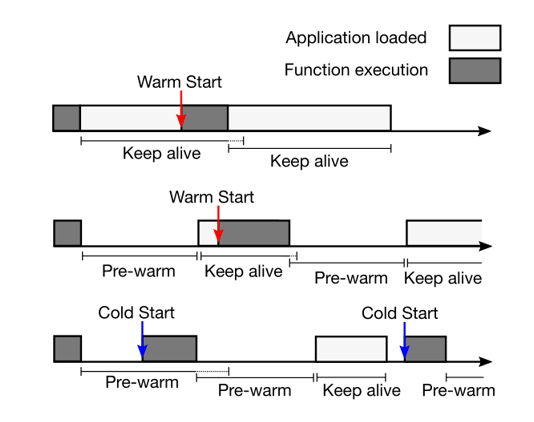
Hybrid Histogram Policy在上一节的末尾已经提到云服务提供商在寻求一种在冷启动和内存消耗之间一个平衡资源管理策略。而且由Azure FaaS函数工作负载得到的结果可知,不同应用程序和函数在调用次数上次数上相差超过8 个数量级,绝大多数 app 和函数调用次数都很低。因此对于Amazon Lambda和 Azure Functions这种采用固定keep-alive(分别10分钟和20分钟)时间,显然会浪费更多资源,论文里作者提出了一种i新的资源管理策略--混合直方图策略。 混合直方图策略提出了两个窗口:
如上图所示每个应用/函数,都有一个自己的 pre-warming window 和 keep-alive window。 图顶部的情况为 pre-warming window为 0,函数调用后,函数不被卸载,继续保持,因此后续调用都是 warm start; 图中间的情况为在经过 pre-warming window 这段时间后,函数被启动(函数镜像重新被装载进内存)然后这中间发生了调用,是一次 warm-start,函数执行完后被卸载,同时开始新的 pre-warming window 等待下次调用; 图底部是一个失败的情况,函数在 pre-warming window 期间发生了调用,是一次冷启动。函数执行完后重新开始计时 pre-warming window,然后 keep-alive。keep-alive 期间没有发生调用,函数被卸载,重新进入 pre-warming window计时,但是此处又发生了调用,再次触发冷启动。这是由于设置的pre-warming window窗口大小不合适导致的。 可见为每个应用程序/函数设计合适的 pre-warming window 和 keep-alive window 窗口时间大小,对减少函数冷启动次数和降低内存资源浪费很重要。Hybrid Histogram Policy策略主要有三部分规则构成:
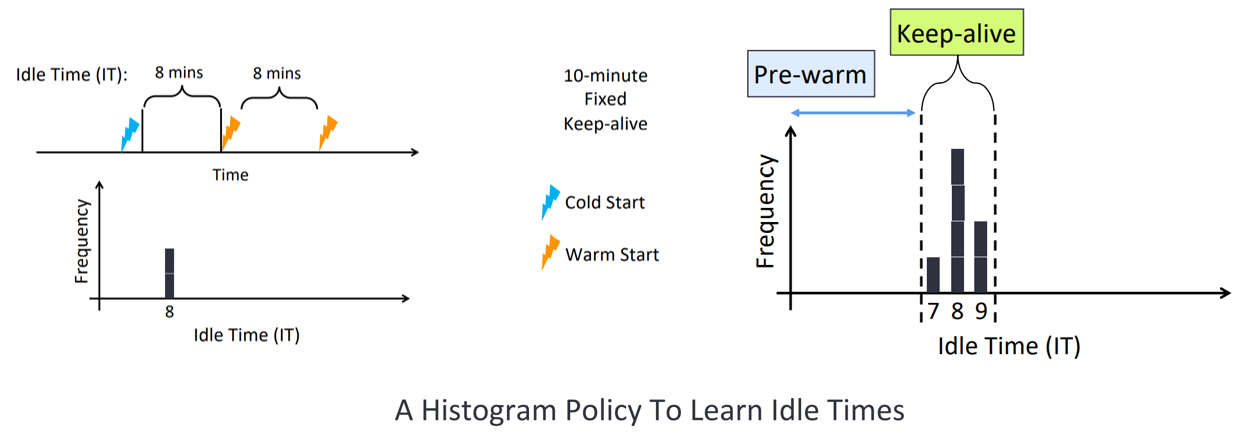
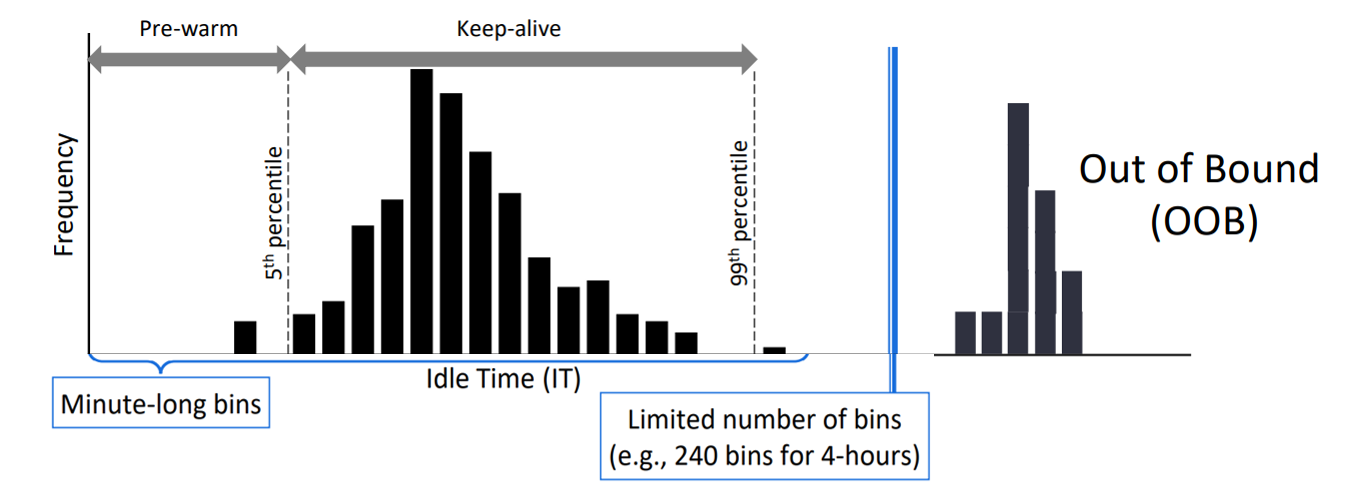
1.Range-limited histogram捕获每个程序/函数的IT(idel time )时间,绘制直方图 图左显示了,对于固定的keep-alive策略,调用周期如果是8分钟的话,刚好每次启动都是热启动,而如果调用周期是11分钟的话,则每次启动就是冷启动了。我们统计函数的IT空闲等待时间,并绘制出如图右所示的直方图,在直方图中横坐标以1分钟为一个区间。如果直方图具有代表性时,就可以如图右所示根据IT分布的 5%-99%百分位来设置 pre-warming window 和 keep-alive window。 2.Standard keep-alive when the histogram is not representative如何判定直方图是否具有代表性,是通过计算直方图横坐标区间跨度的CV得到的,如果直方图只有一个计数较高且所有其他区间值均为0的直方图,则会有较高的CV。而如果所有具有相同值的直方图则会有CV=0。直方图在CV较高的情况下最有效,在该情况下,函数IT大量集中,当函数IT较为分散时,它就不那么有效了。因此,如果CV低于阈值,我们将使用标准的保活方法。 标准的保热方法:每个应用程序/函数根据自己的直方图设置窗口阈值为pre-warming window=0,keep-alive window=直方图的范围(eg:0-4h 最大范围,还要根据直方图具体确定函数保热窗口时间范围)。 混合直方图策略中的标准的保热方法与云服务商采取的固定保热时间还是有区别的,fixed keep-alive策略是每个应用程序的keep alive时间都是一样的,而这种设置 明显是不符合FaaSh工作负载中函数的调用分布的,标准的保热方法是根据每个函数的IT直方图,为每个函数设置单独的keep alive时间。 3.Time-series analysis为了减少混合直方图策略本身所带来的资源消耗,因此该策略的核心就是设计一个紧凑的IT直方图分布,将横坐标时间范围限定为0-4h,所以对于那些不经常被调用的函数,直方图是无法捕捉到这些函数IT的,因为会超出时间限制范围,对于这些应用程序使用时间序列预测策略 ARIMA来设置窗口阈值 上图时间限定范围左边采用前两种规则(主要看直方图是否具有代表性),图右边(超过时间限定范围)采用时间序列预测。 |
pdf、ppt、以及演讲视频
https://www.usenix.org/conference/atc20/presentation/shahrad
The text was updated successfully, but these errors were encountered: