crawler爬虫框架是基于python的scrapy框架,完善了动态页面静态化,数据持久化,功能模块化
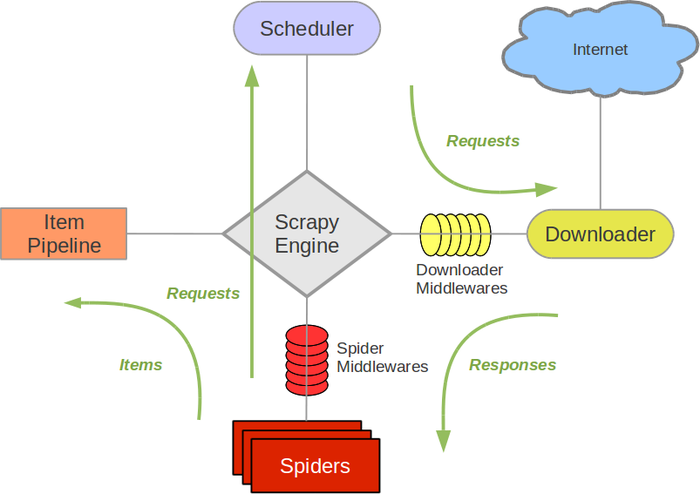
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。 其最初是为了 页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。
引擎负责控制数据流在系统中所有组件中流动,并在相应动作发生时触发事件。 详细内容查看下面的数据流(Data Flow)部分。
此组件相当于爬虫的“大脑”,是整个爬虫的调度中心。
调度器从引擎接受request并将他们入队,以便之后引擎请求他们时提供给引擎。
初始的爬取URL和后续在页面中获取的待爬取的URL将放入调度器中,等待爬取。同时调度器会自动去除重复的URL(如果特定的URL不需要去重也可以通过设置实现,如post请求的URL)
下载器负责获取页面数据并提供给引擎,而后提供给spider。
Spider是Scrapy用户编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。 每个spider负责处理一个特定(或一些)网站。
Item Pipeline负责处理被spider提取出来的item。典型的处理有清理、 验证及持久化(例如存取到数据库中)。
当页面被爬虫解析所需的数据存入Item后,将被发送到项目管道(Pipeline),并经过几个特定的次序处理数据,最后存入本地文件或存入数据库。
下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
通过设置下载器中间件可以实现爬虫自动更换user-agent、IP等功能。
Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
引擎打开一个网站(open a domain),找到处理该网站的Spider并向该spider请求第一个要爬取的URL(s)。
引擎从Spider中获取到第一个要爬取的URL并在调度器(Scheduler)以Request调度。
引擎向调度器请求下一个要爬取的URL。
调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载中间件(请求(request)方向)转发给下载器(Downloader)。
一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(返回(response)方向)发送给引擎。
引擎从下载器中接收到Response并通过Spider中间件(输入方向)发送给Spider处理。
Spider处理Response并返回爬取到的Item及(跟进的)新的Request给引擎。
引擎将(Spider返回的)爬取到的Item给Item Pipeline,将(Spider返回的)Request给调度器。
(从第二步)重复直到调度器中没有更多地request,引擎关闭该网站。
在开始爬取之前,首先要创建一个新的Scrapy项目。这里以爬取我的博客为例,进入你打算存储代码的目录中,运行下列命令:
scrapy startproject scrapyspider 该命令将会创建包含下列内容的scrapyspider目录:
scrapyspider/
scrapy.cfg
scrapyspider/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...
这些文件分别是:
scrapy.cfg: 项目的配置文件。 scrapyspider/: 该项目的python模块。之后您将在此加入代码。 scrapyspider/items.py: 项目中的item文件。 scrapyspider/pipelines.py: 项目中的pipelines文件。 scrapyspider/settings.py: 项目的设置文件。 scrapyspider/spiders/: 放置spider代码的目录。
Spider是用户编写用于从单个网站(或者一些网站)爬取数据的类。
其包含了一个用于下载的初始URL,如何跟进网页中的链接以及如何分析页面中的内容, 提取生成 item 的方法。
为了创建一个Spider,您必须继承 scrapy.Spider 类, 且定义以下三个属性:
- name: 用于区别Spider。 该名字必须是唯一的,您不可以为不同的Spider设定相同的名字。
- start_urls: 包含了Spider在启动时进行爬取的url列表。 因此,第一个被获取到的页面将是其中之一。 后续的URL则从初始的URL获取到的数据中提取。
- parse() 是spider的一个方法。 被调用时,每个初始URL完成下载后生成的 Response 对象将会作为唯一的参数传递给该函数。 该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL的 Request 对象。
from scrapy.spiders import Spider
class BlogSpider(Spider):
name = 'woodenrobot'
start_urls = ['http://woodenrobot.me']
def parse(self, response):
titles = response.xpath('//a[@class="post-title-link"]/text()').extract()
for title in titles:
print title.strip()
启动爬虫 打开终端进入项目所在路径(即:scrapyspider路径下)运行下列命令:
scrapy crawl woodenrobot
# 八桂职教
from datetime import time
import scrapy
from scrapy_splash import SplashRequest
from lib.common import save_to_file
from unsun.items import CommonItem
from unsun.spiders.cn_hvc_edu import CNHvcEduSpider
class BGzjSpider(scrapy.Spider):
name = 'bgzj_edu_info'
allowed_domains = ['ep12.com']
start_urls = ['http://www.ep12.com/a/xinwen/dongtai', 'http://www.ep12.com/a/xinwen/yaowen']
## 数据源id
origin_id = 0
def __init__(self, oderurl=None, origin_id=None, *args, **kwargs):
super(BGzjSpider, self).__init__(*args, **kwargs)
# 将传入的url赋值给start_urls
self.start_urls = ['%s' % oderurl]
# 将数据源id赋值给origin_id
self.origin_id = '%s' % origin_id
# 开始页面 初始化page参数为1
def start_requests(self):
for url in self.start_urls:
# 开始
yield SplashRequest(url, callback=self.parse)
def parse(self, response):
origin = "广西八桂职教"
print(origin)
# 保存下载html文件
save_to_file("gfjyb_edu_info.html", response.text)
next_url = response.xpath(
"//div[@class='d-h d-h-content']/div[@class='container clearfix']/div[@class='search_fl_Content']/div[@id='d_pagination']/a[@class='next']/@href").extract_first()
next_page = response.urljoin(next_url)
items = response.xpath(
"//div[@class='d-h d-h-content']/div[@class='container clearfix']/div[@class='search_fl_Content']/div[@class='top-10']/div[@class='title trim']")
bgzi_info_item = CommonItem()
bgzi_info_item['origin'] = origin
bgzi_info_item['birth'] = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
# for detail in detail_url:
# if detail is not None:
# yield SplashRequest(detail, callback=self.parse)
for item in items:
link = item.xpath("./a/@href").extract_first()
if link is not None:
bgzi_info_item['link'] = link
print(link)
yield SplashRequest(link, meta={"item": bgzi_info_item}, callback=self.parse_content)
# for item in items:
# title = item.xpath("./div[@class='title trim']/a/text()|./div[@class='title trim']/a/b/text()").extract_first()
# link = item.xpath("./div[@class='title trim']/a/@href").extract_first()
# # 栏目与生产日期
# messages = item.xpath("./div[@class='info']/text()").extract_first().split("   ")
# column = messages[0].replace('栏目:','')
# birth = messages[2].replace('日期:','')
# date = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
# edu_info_item = BGzjInfoItem()
# edu_info_item["origin"] = origin
# edu_info_item["column"] = column
# edu_info_item["title"] = title
# edu_info_item["link"] = link
# edu_info_item["birth"] = birth
# edu_info_item["date"] = date
# yield edu_info_item
if next_url is not None:
# 继续爬取分类分页的其它页面
try:
yield SplashRequest(next_page)
except:
pass
def parse_content(self, response):
item = CommonItem()
item['link'] = response.url
# 详情内容页面链接
# 标题
detail_title = response.xpath(
"//div[@class='container clearfix']/div[@class='search_fl_Content']/div[@class='fTitle']/text()").extract_first()
detail_url = response.xpath(
"//div[@class='search_fl_Content']/div[@class='top-10'] /div[@class='title trim']/a/@href")
# 数据来源 栏目
detail_column = response.xpath(
"//div[@class='container clearfix']/div[@class='search_fl_Content']/div[@class='top-10']/div[@class='fPost']/a[3]/text()").extract_first()
# 部分页面html不一样
other_detail_column = response.xpath(
"//div[@class='container clearfix']/div[@class='search_fl_Content']/div[@class='top-10']/div[@class='fPost']/a/text()").extract_first()
# 发文机构
detail_organ = response.xpath(
"//div[@class='container clearfix']/div[@class='search_fl_Content']/div[@class='flai']/span[1]/text()").extract_first()
# 发文作者
detail_author = response.xpath(
"//div[@class='container clearfix']/div[@class='search_fl_Content']/div[@class='flai']/span[2]/text()").extract_first()
# 发文时间
detail_birth = response.xpath(
"//div[@class='container clearfix']/div[@class='search_fl_Content']/div[@class='flai']/span[3]/text()").extract_first()
# 文章内容
detail_content = response.xpath(
"//div[@class='container clearfix']/div[@class='search_fl_Content']/div[@class='fcontent']/div[@class='contentBoxF']/p|//div[@class='container clearfix']/div[@class='search_fl_Content']/div[@class='fcontent']/div[@class='contentBoxF']/div")
item['title'] = detail_title
# print(bgzi_info_item)
if detail_column is not None:
item ['column'] = detail_column
else :
item['column'] =other_detail_column
# print(bgzi_info_item)
# if detail_source is not None:
item['organ'] = detail_organ
# print(bgzi_info_item)
item["dataOriginId"] = self.origin_id
# if detail_author is not None:
item['author'] = detail_author
# print(bgzi_info_item)
# if detail_birth is not None:
item['birth'] = detail_birth
# print(bgzi_info_item)
# if detail_content is not None:
detail_content_str = ""
# 图片路径相对路径转换为绝对路径
for content in detail_content:
old_src = content.xpath("./img/@src |./strong/img/@src ").extract_first()
if old_src is not None:
new_src = response.urljoin(old_src)
detail_content_str = detail_content_str + content.extract().replace(old_src, new_src)
else:
detail_content_str = detail_content_str + content.extract()
item['content'] = detail_content_str
item['date'] = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
# fo = open("rawcodes.txt", "wb")
# fo.write((item, -1))
#
# # 关闭打开的文件
# fo.close()
yield item