diff --git a/_queries/getting-started-crypto-cagg.md b/_queries/getting-started-crypto-cagg.md
new file mode 100644
index 0000000000..2834d8ea02
--- /dev/null
+++ b/_queries/getting-started-crypto-cagg.md
@@ -0,0 +1,19 @@
+SELECT * FROM assets_candlestick_daily
+ORDER BY day DESC, symbol
+LIMIT 10;
+
+-- Output
+
+day | symbol | high | open | close | low
+-----------------------+--------+----------+--------+----------+----------
+2025-01-30 00:00:00+00 | ADA/USD | 0.9708 | 0.9396 | 0.9607 | 0.9365
+2025-01-30 00:00:00+00 | ATOM/USD | 6.114 | 5.825 | 6.063 | 5.776
+2025-01-30 00:00:00+00 | AVAX/USD | 34.1 | 32.8 | 33.95 | 32.44
+2025-01-30 00:00:00+00 | BNB/USD | 679.3 | 668.12 | 677.81 | 666.08
+2025-01-30 00:00:00+00 | BTC/USD | 105595.65 | 103735.84 | 105157.21 | 103298.84
+2025-01-30 00:00:00+00 | CRO/USD | 0.13233 | 0.12869 | 0.13138 | 0.12805
+2025-01-30 00:00:00+00 | DAI/USD | 1 | 1 | 0.9999 | 0.99989998
+2025-01-30 00:00:00+00 | DOGE/USD | 0.33359 | 0.32392 | 0.33172 | 0.32231
+2025-01-30 00:00:00+00 | DOT/USD | 6.01 | 5.779 | 6.004 | 5.732
+2025-01-30 00:00:00+00 | ETH/USD | 3228.9 | 3113.36 | 3219.25 | 3092.92
+(10 rows)
diff --git a/_queries/getting-started-crypto-srt-orderby.md b/_queries/getting-started-crypto-srt-orderby.md
new file mode 100644
index 0000000000..4aaad26f1c
--- /dev/null
+++ b/_queries/getting-started-crypto-srt-orderby.md
@@ -0,0 +1,20 @@
+SELECT * FROM crypto_ticks srt
+WHERE symbol='ETH/USD'
+ORDER BY time DESC
+LIMIT 10;
+
+-- Output
+
+time | symbol | price | day_volume
+-----------------------+--------+----------+------------
+2025-01-30 12:05:09+00 | ETH/USD | 3219.25 | 39425
+2025-01-30 12:05:00+00 | ETH/USD | 3219.26 | 39425
+2025-01-30 12:04:42+00 | ETH/USD | 3219.26 | 39459
+2025-01-30 12:04:33+00 | ETH/USD | 3219.91 | 39458
+2025-01-30 12:04:15+00 | ETH/USD | 3219.6 | 39458
+2025-01-30 12:04:06+00 | ETH/USD | 3220.68 | 39458
+2025-01-30 12:03:57+00 | ETH/USD | 3220.68 | 39483
+2025-01-30 12:03:48+00 | ETH/USD | 3220.12 | 39483
+2025-01-30 12:03:20+00 | ETH/USD | 3219.79 | 39482
+2025-01-30 12:03:11+00 | ETH/USD | 3220.06 | 39472
+(10 rows)
diff --git a/_queries/getting-started-srt-orderby.md b/_queries/getting-started-srt-orderby.md
index a0afde5a41..a1831ca158 100644
--- a/_queries/getting-started-srt-orderby.md
+++ b/_queries/getting-started-srt-orderby.md
@@ -1,20 +1,20 @@
SELECT * FROM stocks_real_time srt
-WHERE symbol='TSLA' and day_volume is not null
-ORDER BY time DESC, day_volume desc
+WHERE symbol='TSLA'
+ORDER BY time DESC
LIMIT 10;
-- Output
-time | symbol | price | day_volume
+time | symbol | price | day_volume
-----------------------+--------+----------+------------
-2023-07-31 16:52:54+00 | TSLA | 267.88 | 55220135
-2023-07-31 16:52:53+00 | TSLA | 267.9141 | 55218795
-2023-07-31 16:52:52+00 | TSLA | 267.8987 | 55218669
-2023-07-31 16:52:51+00 | TSLA | 267.89 | 55218368
-2023-07-31 16:52:49+00 | TSLA | 267.87 | 55217109
-2023-07-31 16:52:49+00 | TSLA | 267.862 | 55216861
-2023-07-31 16:52:48+00 | TSLA | 267.8649 | 55216275
-2023-07-31 16:52:46+00 | TSLA | 267.88 | 55215737
-2023-07-31 16:52:44+00 | TSLA | 267.88 | 55215060
-2023-07-31 16:52:44+00 | TSLA | 267.88 | 55214966
+2025-01-30 00:51:00+00 | TSLA | 405.32 | NULL
+2025-01-30 00:41:00+00 | TSLA | 406.05 | NULL
+2025-01-30 00:39:00+00 | TSLA | 406.25 | NULL
+2025-01-30 00:32:00+00 | TSLA | 406.02 | NULL
+2025-01-30 00:32:00+00 | TSLA | 406.10 | NULL
+2025-01-30 00:25:00+00 | TSLA | 405.95 | NULL
+2025-01-30 00:24:00+00 | TSLA | 406.04 | NULL
+2025-01-30 00:24:00+00 | TSLA | 406.04 | NULL
+2025-01-30 00:22:00+00 | TSLA | 406.38 | NULL
+2025-01-30 00:21:00+00 | TSLA | 405.77 | NULL
(10 rows)
diff --git a/about/changelog.md b/about/changelog.md
index 06df29e191..7e29f6a69a 100644
--- a/about/changelog.md
+++ b/about/changelog.md
@@ -8,6 +8,7 @@ keywords: [changelog, upgrades, updates, releases]
All the latest features and updates to Timescale products.
+
## Agent Mode for PopSQL and more
diff --git a/getting-started/aggregation.md b/getting-started/aggregation.md
deleted file mode 100644
index d9850f0f52..0000000000
--- a/getting-started/aggregation.md
+++ /dev/null
@@ -1,214 +0,0 @@
----
-title: Continuous aggregation
-excerpt: A must have for real-time analytics, continuous aggregates summarize your data and stay up-to-date as new data pours in. Create and query a continuous aggregate in Timescale Cloud
-products: [cloud]
-keywords: [continuous aggregates, create]
-layout_components: [next_prev_large]
-content_group: Getting started
----
-
-import CaggsIntro from "versionContent/_partials/_caggs-intro.mdx";
-import CaggsTypes from "versionContent/_partials/_caggs-types.mdx";
-import CandlestickIntro from "versionContent/_partials/_candlestick_intro.mdx";
-
-# Continuous aggregation
-
-Aggregation is a way of combing data to get insights from it. At its simplest,
-aggregation is something like looking for an average. For example, if you have
-data showing temperature changes over time, you can calculate an average of
-those temperatures, or a count of how many readings have been taken. Average,
-sum, and count are all example of simple aggregates.
-
-However, aggregation calculations can get big and slow, quickly. If you want to
-find the average open and closing values of a range of stocks for each day, then
-you need something a little more sophisticated. That's where Timescale
-continuous aggregates come in. Continuous aggregates can minimize the number of
-records that you need to look up to perform your query.
-
-## Continuous aggregates
-
-
-
-
-
-In this section, you create a continuous aggregate, and query it for more
-information about the trading data.
-
-
-
-## Create an aggregate query
-
-
-
-In this section, you use a `SELECT` statement to find the high and low values
-with `min` and `max` functions, and the open and close values with `first` and
-`last` functions. You then aggregate the data into 1 day buckets, like this:
-
-
-
-Then, you organize the results by day and symbol:
-
-
-
-
-
-### Creating an aggregate query
-
-1. At the command prompt, use the `psql` connection string from the cheat sheet
- you downloaded to connect to your database.
-1. At the `psql` prompt, type this query:
-
-
-
-1. Type `q` to return to the `psql` prompt.
-
-
-
-## Create a continuous aggregate
-
-Now that you have an aggregation query, you can use it to create a continuous
-aggregate.
-
-In this section, your query starts by creating a materialized view called
-`stock_candlestick_daily`, then converting it into a Timescale continuous
-aggregate:
-
-
-
-Then, you give the aggregate query you created earlier as the contents for the
-continuous aggregate:
-
-
-
-When you run this query, you create the view, and populate the view with the
-aggregated calculation. This can take a few minutes to run, because it needs to
-perform these calculations across all of your stock trade data the first time.
-
-When you continuous aggregate has been created and the data aggregated for the
-first time, you can query your continuous aggregate. For example, you can look
-at all the aggregated data, like this:
-
-
-
-Or you can look at a single stock, like this:
-
-
-
-
-
-### Creating a continuous aggregate
-
-1. At the command prompt, use the `psql` connection string from the cheat sheet
- you downloaded to connect to your database.
-1. At the `psql` prompt, type this query:
-
- ```sql
- CREATE MATERIALIZED VIEW stock_candlestick_daily
- WITH (timescaledb.continuous) AS
- SELECT
- time_bucket('1 day', "time") AS day,
- symbol,
- max(price) AS high,
- first(price, time) AS open,
- last(price, time) AS close,
- min(price) AS low
- FROM stocks_real_time srt
- GROUP BY day, symbol;
- ```
-
-1. Query your continuous aggregate for all stocks:
-
-
-
-1. Query your continuous aggregate for Tesla stock:
-
-
-
-
-
-For more information about how continuous aggregates work, see the
-[continuous aggregates section][continuous-aggregates].
-
-[continuous-aggregates]: /use-timescale/:currentVersion:/continuous-aggregates
-[time-buckets]: /use-timescale/:currentVersion:/time-buckets/
diff --git a/getting-started/next-steps.md b/getting-started/next-steps.md
deleted file mode 100644
index 7b0b33bbcc..0000000000
--- a/getting-started/next-steps.md
+++ /dev/null
@@ -1,25 +0,0 @@
----
-title: Next steps
-excerpt: Explore the features that are available for your real-time analytics workloads after you have created a Timescale Cloud account and launched your first service
-products: [cloud]
-keywords: [data migration, ingest, visualize, connect]
-layout_components: [next_prev_large]
-content_group: Getting started
----
-
-# Where to next?
-
-To continue exploring Timescale, here are some things you might like to try:
-
-* Try some [tutorials][tutorials].
-* Write a program using a Timescale database backend in
- [your favorite programming language][connect-with-code].
-* Get your Timescale database integrated with a range of
- [third-party tools][integrations]
- for tasks like data ingestion, visualization, and logging.
-* Extend your Timescale database with [PostgreSQL extensions][extensions].
-
-[connect-with-code]: /quick-start/:currentVersion:/
-[integrations]: /use-timescale/:currentVersion:/integrations/
-[extensions]: /use-timescale/:currentVersion:/extensions/
-[tutorials]: /tutorials/:currentVersion:/
diff --git a/getting-started/page-index/page-index.js b/getting-started/page-index/page-index.js
index 6ec2fac83e..01cc595287 100644
--- a/getting-started/page-index/page-index.js
+++ b/getting-started/page-index/page-index.js
@@ -9,16 +9,16 @@ module.exports = [
href: "services",
excerpt: "Create a Timescale service and connect to it",
},
+ {
+ title: "Try the key Timescale features",
+ href: "try-key-features-timescale-products",
+ excerpt: "Improve database performance with Hypertables, time bucketing, continuous aggregates, compression, data tiering, and high availability",
+ },
{
title: "Run your queries from Timescale Console",
href: "run-queries-from-console",
excerpt: "Run your queries securely from inside Timescale Console",
},
- {
- title: "Try out key features of Timescale products",
- href: "try-key-features-timescale-products",
- excerpt: "Improve database performance with Hypertables, time bucketing, continuous aggregates, compression, data tiering, and high availability",
- },
],
},
];
diff --git a/getting-started/queries.md b/getting-started/queries.md
deleted file mode 100644
index aa0d812dff..0000000000
--- a/getting-started/queries.md
+++ /dev/null
@@ -1,217 +0,0 @@
----
-title: Queries
-excerpt: Timescale Cloud supports full SQL, so you don't need to learn a custom query language. Construct and run simple SQL queries on your Timescale Cloud service
-products: [cloud]
-keywords: [queries]
-layout_components: [next_prev_large]
-content_group: Getting started
----
-
-# Queries
-
-Timescale supports full SQL, so you don't need to learn a custom query language.
-This section contains some simple queries that you can run directly on this
-page. When you have constructed the perfect query, use the copy button to use it
-on your own database.
-
-Most of the queries in this section look for the last four days of data. This is
-to account for the fact there are no stock trades over the weekends, and to make
-sure that you always get some data in your results.
-
-The main building block of all SQL queries is the `SELECT` statement. It is an
-instruction to select data from a database. Doing a quick `SELECT` query is
-often the first thing you do with a new database, just to make sure that your
-data is stored in your database in the way you expect it to be.
-
-## Use SELECT to return data
-
-This first section uses a `SELECT` statement to ask your database to return
-every column, represented by the asterisk, from the `stocks_real_time srt`
-table, like this:
-
-
-
-If your table is very big, you might not want to return every row. You can
-limit the number of rows that get returned with a `LIMIT` clause:
-
-
-
-
-
-### Using SELECT to return data
-
-1. At the command prompt, use the `psql` connection string from the cheat sheet
- you downloaded to connect to your database.
-1. At the `psql` prompt, type this query.
-
-
- Get a sneak peek at the results by clicking "Run query" below. This runs the
- SQL query against a live instance curated by Timescale.
-
-
-
-
-1. Type `q` to return to the `psql` prompt.
-
-
-
-## Use ORDER BY to organize results
-
-In the previous section, you saw a selection of rows from the table. Usually,
-you want to order the rows so that you see the most recent trades. You can
-change how your results are displayed using an `ORDER BY` statement.
-
-In this section, you query Tesla's stock with a `SELECT` query like this,
-which asks for all of the trades from the `stocks_real_time srt` table, with the
-`TSLA` symbol, and which has day volume data:
-
-
-
-Then, you add an `ORDER BY` statement to order the results by time in descending
-order, and also by day volume in descending order. The day volume shows the
-total number of trades for this stock for the day. Every time another trade
-occurs, the day volume figure increases by 1. Here is the `ORDER BY` statement:
-
-
-
-Finally, to limit the number of results, you can use a `LIMIT` clause again:
-
-
-
-
-
-### Using ORDER BY to organize results
-
-1. At the command prompt, use the `psql` connection string from the cheat sheet
- you downloaded to connect to your database.
-1. At the `psql` prompt, type this query:
-
-
-
- There are multiple trades every second, but you know that the order is
- correct, because the `day_volume` column is ordered correctly.
-
-
-
-## Get the first and last value
-
-Timescale has custom SQL functions that can help make time-series analysis
-easier and faster. In this section, you learn about two common Timescale
-functions: `first` to find the earliest value within a group, and `last` to find
-the most recent value within a group.
-
-The `first()` and `last()` functions retrieve the first and last value of one
-column when ordered by another. For example, the stock data has a timestamp
-column called `time`, and a numeric column called `price`. You can use
-`first(price, time)` to get the first value in the `price` column when ordered
-with an increasing `time` column.
-
-In this query, you start by selecting the `first()` and `last()` trading price
-for every stock in the `stocks_real_time srt` table for the last four days:
-
- now() - INTERVAL '4 days'
-`} />
-
-Then, you organize the results so that you can see the first and last value for
-each stock together with a `GROUP BY` statement, and in alphabetical order with
-an `ORDER BY` statement, like this:
-
-
-
-For more information about these functions, see the API documentation for
-[first()][first], and [last()][last].
-
-
-
-### Getting the first and last value
-
-1. At the command prompt, use the `psql` connection string from the cheat sheet
- you downloaded to connect to your database.
-1. At the `psql` prompt, type this query:
-
-
-
-1. Type `q` to return to the `psql` prompt.
-
-
-
-## Use time buckets to get values
-
-To make it easier to look at numbers over different time ranges, you can use the
-Timescale `time_bucket` function. Time buckets are used to group data, so that
-you can perform calculations over different time periods. Time buckets represent
-a specific point in time, so all the timestamps for data in a single time bucket
-use the bucket timestamp.
-
-In this section, you use the same query as the previous section to find the
-`first` and `last` values, but start by organizing the data into 1-hour time
-buckets. In the last section, you retrieves the first and last value of a
-column, this time, you retrieve the first and last value for a 1-hour time bucket.
-
-Start by declaring the time bucket interval to use, and give your time bucket a
-name:
-
-
-
-Then, you can add the query in the same way as you used before:
-
- now() - INTERVAL '4 days'
-`} />
-
-Finally, organize the results by time bucket, using the `GROUP BY` statement,
-like this:
-
-
-
-For more information about time bucketing, see the [time bucket section][time-buckets].
-
-
-
-### Using time buckets to get values
-
-1. At the command prompt, use the `psql` connection string from the cheat sheet
- you downloaded to connect to your database.
-1. At the `psql` prompt, type this query:
-
-
-
-1. Type `q` to return to the `psql` prompt.
-
-
- When you create a hypertable, Timescale automatically creates an index on
- the time column. However, you often need to filter your time-series data on
- other columns as well. Using indexes appropriately helps your queries
- perform better. For more information about indexing, see the
- [about indexing section](https://docs.timescale.com/use-timescale/latest/schema-management/about-indexing/)
-
-
-
-
-[first]: /api/:currentVersion:/hyperfunctions/first/
-[last]: /api/:currentVersion:/hyperfunctions/last/
-[time-buckets]: /use-timescale/:currentVersion:/time-buckets/
diff --git a/getting-started/services.md b/getting-started/services.md
index 9ca39ab1a1..e602e202b5 100644
--- a/getting-started/services.md
+++ b/getting-started/services.md
@@ -24,9 +24,6 @@ To start using $CLOUD_LONG for your data:
1. [Create a $COMPANY account][create-an-account]: register in $CONSOLE to get a centralized point to administer and interact with your data.
1. [Create a $SERVICE_LONG][create-a-service]: that is, a PostgreSQL database instance, powered by [$TIMESCALE_DB][timescaledb], built for production, and extended with cloud features like transparent data tiering to object storage.
1. [Connect to your $SERVICE_LONG][connect-to-your-service]: to run queries, add and migrate your data from other sources.
-1. [Create a hypertable][create-a-hypertable]: create a standard PostgreSQL table in your service, then convert it into a [hypertable][hypertables].
-
- Anything you can do with regular PostgreSQL tables, you can do with hypertables, just with much better performance and improved user experience for real-time analytics workloads.
diff --git a/getting-started/tables-hypertables.md b/getting-started/tables-hypertables.md
deleted file mode 100644
index f336016e83..0000000000
--- a/getting-started/tables-hypertables.md
+++ /dev/null
@@ -1,108 +0,0 @@
----
-title: Tables and hypertables
-excerpt: Create tables and hypertables in your Timescale account
-products: [cloud]
-keywords: [hypertables, create]
-layout_components: [next_prev_large]
-content_group: Getting started
----
-
-import HypertableIntro from "versionContent/_partials/_hypertables-intro.mdx";
-
-# Tables and hypertables
-
-
-
-In this section, you create a hypertable for time-series data, and regular
-PostgreSQL tables for relational data. You also create an index on your
-hypertable, which isn't required, but can help your queries run more efficiently.
-One of the other special qualities of hypertables is that you can also create
-indexes later on, if you need to.
-
-For more information, see
-[the hypertables section][hypertable-how-to].
-
-## Create your first hypertable
-
-For the financial dataset used in this guide, create a hypertable named
-`stocks_real_time` that contains second-by-second stock-trade data for the top
-100 most-traded symbols.
-
-
-
-### Creating your first hypertable
-
-1. At the command prompt, use the `psql` connection string from the cheat sheet
- you downloaded to connect to your database.
-1. Create a regular PostgreSQL table to store the real-time stock trade data
- using `CREATE TABLE`:
-
- ```sql
- CREATE TABLE stocks_real_time (
- time TIMESTAMPTZ NOT NULL,
- symbol TEXT NOT NULL,
- price DOUBLE PRECISION NULL,
- day_volume INT NULL
- );
- ```
-
-1. Convert the regular table into a hypertable partitioned on the `time` column
- using the `create_hypertable()` function provided by Timescale. You must
- provide the name of the table (`stocks_real_time`) and the column in that
- table that holds the timestamp data to use for partitioning (`time`):
-
-
-
-1. Create an index to support efficient queries on the `symbol` and `time`
- columns:
-
-
-
-
-
-## Create regular PostgreSQL tables for relational data
-
-Timescale isn't just for hypertables. When you have other relational data that
-enhances your time-series data, you can create regular PostgreSQL tables just as
-you would normally. For this dataset, there is one other table of data called
-`company`.
-
-
-
-### Creating regular PostgreSQL tables
-
-1. Add a table to store the company name and symbol for the stock trade data:
-
- ```sql
- CREATE TABLE company (
- symbol TEXT NOT NULL,
- name TEXT NOT NULL
- );
- ```
-
-1. You now have two tables within your Timescale database. One hypertable named
- `stocks_real_time`, and one normal PostgreSQL table named `company`. You can
- check this by running this command at the `psql` prompt:
-
-
-
- This command returns information about your tables, like this:
-
-
-
-
-
-[hypertable-how-to]: /use-timescale/:currentVersion:/hypertables/
diff --git a/getting-started/time-series-data.md b/getting-started/time-series-data.md
deleted file mode 100644
index b4d7aff625..0000000000
--- a/getting-started/time-series-data.md
+++ /dev/null
@@ -1,62 +0,0 @@
----
-title: Time-series data
-excerpt: Find out what time-series data is, how it is generated, and how you can run real-time analytics on it with Timescale Cloud
-products: [cloud]
-keywords: [ingest]
-tags: [add, data, time-series]
-layout_components: [next_prev_large]
-content_group: Getting started
----
-
-import TimeseriesIntro from "versionContent/_partials/_timeseries-intro.mdx";
-
-# Time-series data
-
-
-
-To explore Timescale's features, you need some sample data. This guide
-uses real-time stock trade data, also known as tick data, from
-[Twelve Data][twelve-data].
-
-## About the dataset
-
-The dataset contains second-by-second stock-trade data for the top 100
-most-traded symbols, in a hypertable named `stocks_real_time`. It also includes
-a separate table of company symbols and company names, in a regular PostgreSQL
-table named `company`.
-
-The dataset is updated on a nightly basis and contains data from the last four
-weeks, typically ~8 million rows of data. Stock trades are recorded in real-time
-Monday through Friday, during normal trading hours of the New York Stock
-Exchange (9:30 AM - 4:00 PM EST).
-
-## Ingest the dataset
-
-To ingest data into the tables that you created, you need to download the
-dataset and copy the data to your database.
-
-
-
-1. Unzip [real_time_stock_data.zip](https://assets.timescale.com/docs/downloads/get-started/real_time_stock_data.zip) to your local device.
- This archive one `.csv` file with company information, and one with real-time stock trades for
- the past month.
-
-1. At the `psql` prompt, use the `COPY` command to transfer data into your
- Timescale instance. If the `.csv` files aren't in your current directory,
- specify the file paths in the following commands:
-
-
-
-
-
- Because there are millions of rows of data, the `COPY` process may take a few
- minutes depending on your internet connection and local client resources.
-
-
-
-[twelve-data]: https://twelvedata.com/
-[console-services]: https://console.cloud.timescale.com/dashboard/services
diff --git a/getting-started/try-key-features-timescale-products.md b/getting-started/try-key-features-timescale-products.md
index 842cf1afb6..70f3863eb4 100644
--- a/getting-started/try-key-features-timescale-products.md
+++ b/getting-started/try-key-features-timescale-products.md
@@ -1,5 +1,5 @@
---
-title: Try out key features of Timescale products
+title: Try the key Timescale features
excerpt: Improve database performance with hypertables, time bucketing, compression and continuous aggregates.
products: [cloud]
content_group: Getting started
@@ -8,7 +8,7 @@ content_group: Getting started
import HASetup from 'versionContent/_partials/_high-availability-setup.mdx';
import IntegrationPrereqs from "versionContent/_partials/_integration-prereqs.mdx";
-# Try out key features of Timescale products
+# Try the key Timescale features
$CLOUD_LONG scales PostgreSQL to ingest and query vast amounts of live data. $CLOUD_LONG
provides a range of features and optimizations that supercharge your queries while keeping the
@@ -16,9 +16,10 @@ costs down. For example:
* The hypercore row-columnar engine makes queries up to 350x faster, ingests 44% faster, and reduces storage by 90%.
* Tiered storage seamlessly moves your data from high performance storage for frequently access data to low cost bottomless storage for rarely accessed data.
-The following figure shows the main features and tiered data in $CLOUD_LONG:
+The following figure shows how $CLOUD_LONG optimizes your data for superfast real-time analytics and reduced
+costs:
-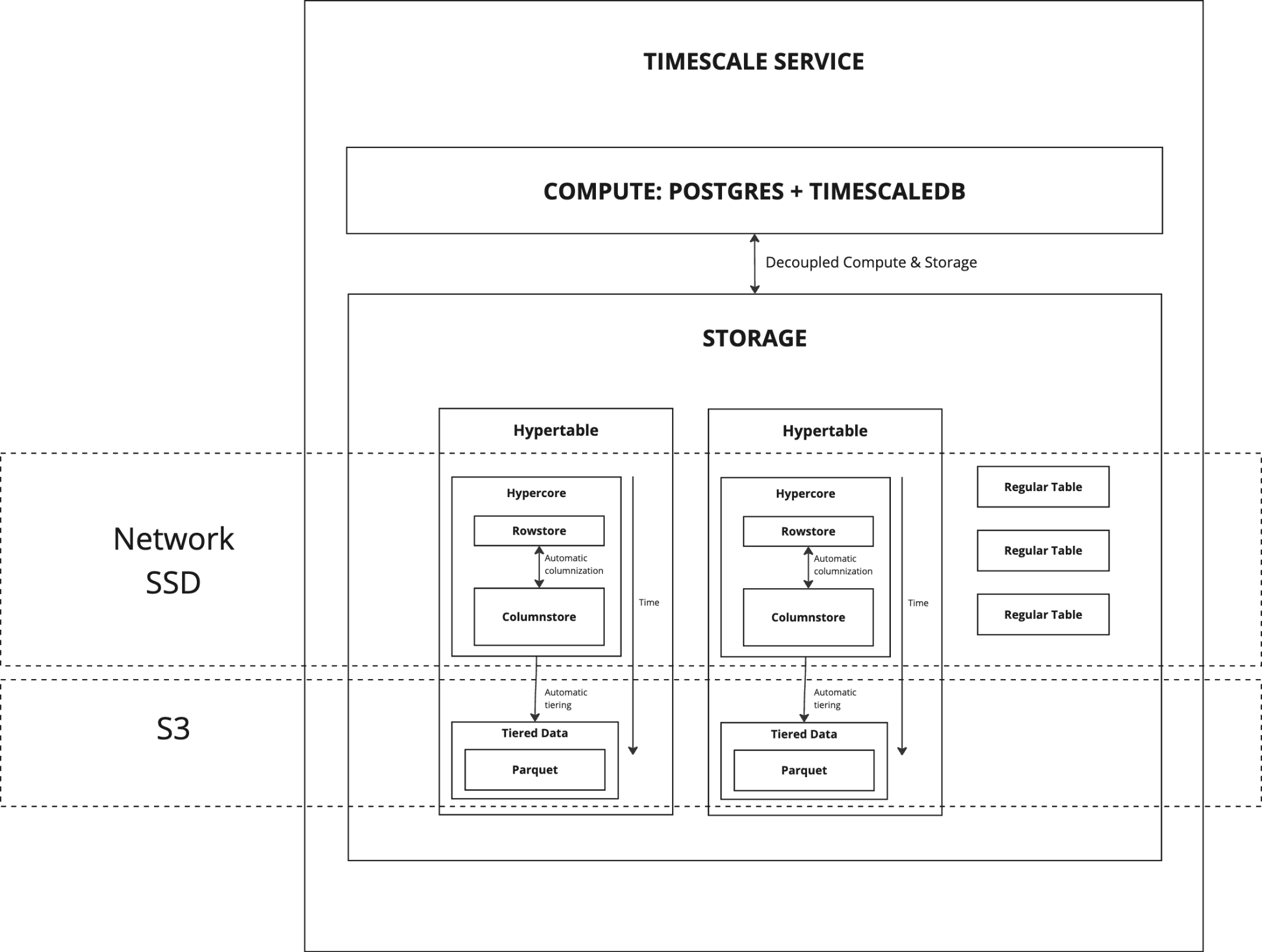
+
This page gives shows you how to rapidly implement the features in $CLOUD_LONG that enable you to
ingest and query data faster while keeping prices low.
@@ -48,10 +49,10 @@ relational and time-series data from external files.
1. **Import some time-series data into your hypertable**
- 1. Unzip [real_time_stock_data.zip](https://assets.timescale.com/docs/downloads/get-started/real_time_stock_data.zip) to a ``.
+ 1. Unzip [crypto_sample.zip](https://assets.timescale.com/docs/downloads/candlestick/crypto_sample.zip) to a ``.
- This test dataset contains second-by-second stock-trade data for the top 100 most-traded symbols
- and a regular table of company symbols and company names.
+ This test dataset contains second-by-second trade data for the most-traded crypto-assets
+ and a regular table of asset symbols and company names.
To import up to 100GB of data directly from your current PostgreSQL based database,
[migrate with downtime][migrate-with-downtime] using native PostgreSQL tooling. To seamlessly import 100GB-10TB+
@@ -66,12 +67,15 @@ relational and time-series data from external files.
The $CONSOLE data upload creates the tables for you from the data you are uploading:
1. In [$CONSOLE][portal-ops-mode], select the service to add data to, then click **Actions** > **Upload CSV**.
- 1. Drag `/tutorial_sample_tick.csv` to `Upload .CSV` and change `New table name`, to `stocks_real_time`.
- 1. Enable `hypertable partition` for the `time` column and click `Upload CSV`.
+ 1. Drag `/tutorial_sample_tick.csv` to `Upload .CSV` and change `New table name`, to `crypto_ticks`.
+ 1. Enable `hypertable partition` for the `time` column and click `Upload CSV`.
+
The upload wizard creates a hypertable containing the data from the CSV file.
- 1. When the data is uploaded, close `Upload .CSV`.
+ 1. When the data is uploaded, close `Upload .CSV`.
+
If you want to have a quick look at your data, press `Run` .
- 1. Repeat the process with `/tutorial_sample_company.csv` and rename to `company`.
+ 1. Repeat the process with `/tutorial_sample_assets.csv` and rename to `crypto_assets`.
+
There is no time-series data in this table, so you don't see the `hypertable partition` option.
@@ -90,16 +94,16 @@ relational and time-series data from external files.
1. In your sql client, create a normal PostgreSQL table:
```sql
- CREATE TABLE stocks_real_time (
+ CREATE TABLE crypto_ticks (
time TIMESTAMPTZ NOT NULL,
symbol TEXT NOT NULL,
price DOUBLE PRECISION NULL,
day_volume INT NULL
);
```
- 1. Convert `stocks_real_time` to a hypertable:
+ 1. Convert `crypto_ticks` to a hypertable:
```sql
- SELECT create_hypertable('stocks_real_time', by_range('time'));
+ SELECT create_hypertable('crypto_ticks', by_range('time'));
```
To more fully understand how hypertables work, and how to optimize them for performance by
tuning chunk intervals and enabling chunk skipping, see [the hypertables documentation][hypertables-section].
@@ -108,7 +112,7 @@ relational and time-series data from external files.
In your sql client, create a normal PostgreSQL table:
```sql
- CREATE TABLE company (
+ CREATE TABLE crypto_assets (
symbol TEXT NOT NULL,
name TEXT NOT NULL
);
@@ -116,8 +120,8 @@ relational and time-series data from external files.
3. Upload the dataset to your $SERVICE_SHORT
```sql
- \COPY stocks_real_time from './tutorial_sample_tick.csv' DELIMITER ',' CSV HEADER;
- \COPY company from './tutorial_sample_company.csv' DELIMITER ',' CSV HEADER;
+ \COPY crypto_ticks from './tutorial_sample_tick.csv' DELIMITER ',' CSV HEADER;
+ \COPY crypto_assets from './tutorial_sample_company.csv' DELIMITER ',' CSV HEADER;
```
@@ -135,11 +139,11 @@ relational and time-series data from external files.
- **SQL editor**: write, fix, and organize SQL faster and more accurately in [$CONSOLE][portal-ops-mode] for a $SERVICE_LONG.
- **psql**: easily run queries on your $SERVICE_LONGs or self-hosted TimescaleDB deployment from Terminal.
-
+
-## Write fast analytical queries on frequently access data using time buckets and continuous aggregates
+## Write fast and efficient analytical queries
Aggregation is a way of combing data to get insights from it. Average, sum, and count are all
example of simple aggregates. However, with large amounts of data aggregation slows things down, quickly.
@@ -176,19 +180,19 @@ $CONSOLE. You can also do this using psql.
PostgreSQL `MATERIALIZED VIEW` in a hypertable. `timescaledb.continuous` ensures that this data
is always up to date.
In your SQL editor, use the following code to create a continuous aggregate on the real time data in
- the `stocks_real_time` table:
+ the `crypto_ticks` table:
```sql
- CREATE MATERIALIZED VIEW stock_candlestick_daily
+ CREATE MATERIALIZED VIEW assets_candlestick_daily
WITH (timescaledb.continuous) AS
SELECT
- time_bucket('1 day', "time") AS day,
- symbol,
- max(price) AS high,
- first(price, time) AS open,
- last(price, time) AS close,
- min(price) AS low
- FROM stocks_real_time srt
+ time_bucket('1 day', "time") AS day,
+ symbol,
+ max(price) AS high,
+ first(price, time) AS open,
+ last(price, time) AS close,
+ min(price) AS low
+ FROM crypto_ticks srt
GROUP BY day, symbol;
```
@@ -198,7 +202,7 @@ $CONSOLE. You can also do this using psql.
1. **Create a policy to refresh the view every hour**
```sql
- SELECT add_continuous_aggregate_policy('stock_candlestick_daily',
+ SELECT add_continuous_aggregate_policy('assets_candlestick_daily',
start_offset => INTERVAL '3 weeks',
end_offset => INTERVAL '24 hours',
schedule_interval => INTERVAL '3 hours');
@@ -206,8 +210,8 @@ $CONSOLE. You can also do this using psql.
1. **Have a quick look at your data**
- You query continuous aggregates exactly the same way as your other tables. To query the `stock_candlestick_daily`
- continuous aggregate for all stocks:
+ You query continuous aggregates exactly the same way as your other tables. To query the `assets_candlestick_daily`
+ continuous aggregate for all assets:
@@ -221,28 +225,28 @@ $CONSOLE. You can also do this using psql.
1. **In [$CONSOLE][portal-ops-mode], select the service you uploaded data to**.
-1. **Click `Operations` > `Continuous aggregates`, select `stocks_real_time`, then click `Create continuous aggregate`**.
- 
-1. **Create a view called `stock_candlestick_daily` on the `time` column with an interval of `1 day`, then click `Next step`**.
+1. **Click `Operations` > `Continuous aggregates`, select `crypto_ticks`, then click `Create continuous aggregate`**.
+ 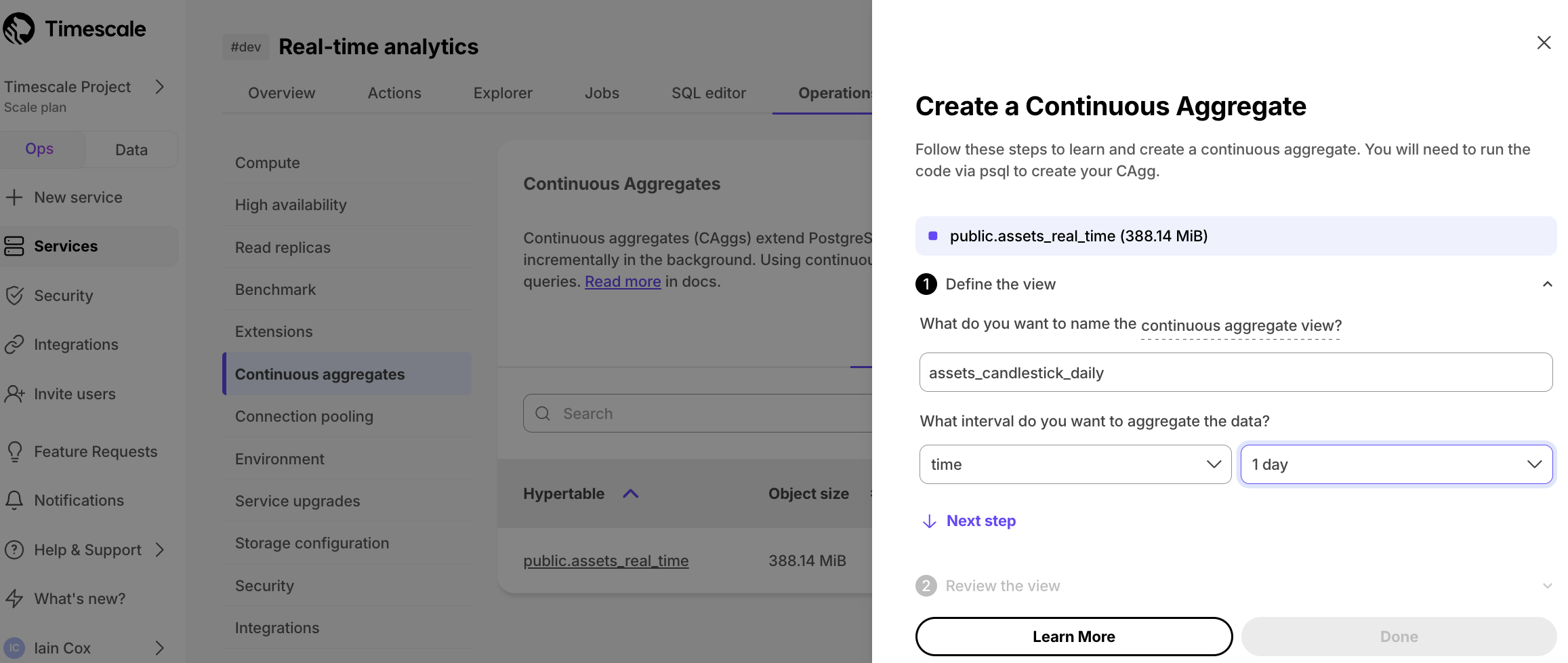
+1. **Create a view called `assets_candlestick_daily` on the `time` column with an interval of `1 day`, then click `Next step`**.
1. **Update the view SQL with the following functions, then click `Run`**
```sql
- CREATE MATERIALIZED VIEW stock_candlestick_daily
- WITH (timescaledb.continuous) AS
- SELECT
+ CREATE MATERIALIZED VIEW assets_candlestick_daily
+ WITH (timescaledb.continuous) AS
+ SELECT
time_bucket('1 day', "time") AS bucket,
symbol,
max(price) AS high,
first(price, time) AS open,
last(price, time) AS close,
min(price) AS low
- FROM "public"."stocks_real_time" srt
- GROUP BY bucket, symbol;
+ FROM "public"."crypto_ticks" srt
+ GROUP BY bucket, symbol;
```
1. **When the view is created, click `Next step`**
1. **Define a refresh policy with the following values, then click `Next step`**
- - `Set the start offset`: `3 weeks`
- - `Set the end offset`: `24 hours`
- - `Set the schedule interval`: `3 hours`
+ - `How far back do you want to materialize?`: `3 weeks`
+ - `What recent data to exclude?`: `24 hours`
+ - `How often do you want the job to run?`: `3 hours`
1. **Click `Create continuous aggregate`, then click `Run`**
$CLOUD_LONG creates the continuous aggregate and displays the aggregate ID in $CONSOLE. Click `DONE` to close the wizard.
@@ -257,20 +261,23 @@ To see the change in terms of query time and data returned between a regular que
a continuous aggregate, run the query part of the continuous aggregate
( `SELECT ...GROUP BY day, symbol;` ) and compare the results.
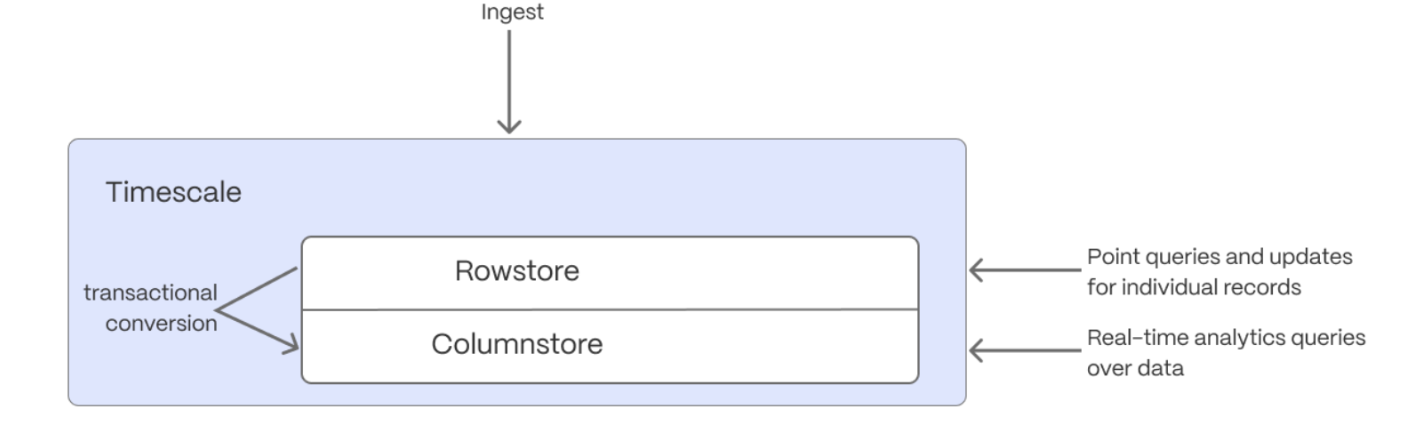
-## Prepare your data for real-time analytics with hypercore
+
+## Enhance query performance for analytics
Hypercore is the Timescale hybrid row-columnar storage engine, designed specifically for real-time analytics and
powered by time-series data. The advantage of Hypercore is its ability to seamlessly switch between row-oriented and
column-oriented storage. This flexibility enables Timescale Cloud to deliver the best of both worlds, solving the key
challenges in real-time analytics.
+
+
When you convert chunks from the rowstore to the columnstore, multiple records are grouped into a single row.
The columns of this row hold an array-like structure that stores all the data. Because a single row takes up less disk
space, you can reduce your chunk size by more than 90%, and can also speed up your queries. This saves on storage costs,
and keeps your queries operating at lightning speed.
-Best practice is to compress data that is no longer needed for highest performance queries, but is still accessed regularly. For example, last week's stock
-market data.
+Best practice is to compress data that is no longer needed for highest performance queries, but is still accessed
+regularly. For example, last week's market data.
@@ -279,7 +286,7 @@ market data.
Create a [job][job] that automatically moves chunks in a hypertable to the columnstore at a specific time interval.
```sql
- ALTER TABLE stocks_real_time SET (
+ ALTER TABLE crypto_ticks SET (
timescaledb.enable_columnstore = true,
timescaledb.segmentby = 'symbol');
```
@@ -288,14 +295,32 @@ market data.
For example, 60 days after the data was added to the table:
``` sql
- CALL add_columnstore_policy('stocks_real_time', after => INTERVAL '60d');
+ CALL add_columnstore_policy('crypto_ticks', after => INTERVAL '60d');
```
See [add_columnstore_policy][add_columnstore_policy].
+1. **View your data space saving**
+
+ When you convert data to the columnstore, as well as being optimized for analytics, it is compresses by more than
+ 90%. This saves on storage costs and keeps your queries operating at lightning speed. To see the amount of space
+ saved:
+ ``` sql
+ SELECT
+ pg_size_pretty(before_compression_total_bytes) as before,
+ pg_size_pretty(after_compression_total_bytes) as after
+ FROM hypertable_compression_stats('crypto_ticks');
+ ```
+ You see something like:
+
+ | Before | After |
+ |--------|---------|
+ | 32 MB | 3808 KB |
+
+
-## Reduce storage charges for rarely accessed data using tiered storage
+## Slash storage charges
In the previous sections, you used continuous aggregates to make fast analytical queries, and
compression to reduce storage costs on frequently accessed data. To reduce storage costs even more,
@@ -304,6 +329,8 @@ low-cost bottomless data storage built on Amazon S3. However, no matter the tier
[query your data when you need][querying-tiered-data]. $CLOUD_LONG seamlessly accesses the correct storage
tier and generates the response.
+
+
Data tiering is available in the [scale and enterprise][pricing-plans] pricing plans for $CLOUD_LONG.
To setup data tiering:
@@ -326,7 +353,7 @@ To setup data tiering:
In $CONSOLE, click `SQL Editor`, then enable data tiering on a hypertable with the following query:
```sql
- SELECT add_tiering_policy('stock_candlestick_daily', INTERVAL '3 weeks');
+ SELECT add_tiering_policy('assets_candlestick_daily', INTERVAL '3 weeks');
```
1. **Qeury tiered data**
@@ -334,14 +361,23 @@ To setup data tiering:
You enable reads from tiered data for each query, for a session or for all future
sessions. To run a single query on tiered data:
- ```sql
- set timescaledb.enable_tiered_reads = true; SELECT * FROM stocks_real_time srt LIMIT 10; set timescaledb.enable_tiered_reads = false;
- ```
+ 1. Enable reads on tiered data:
+ ```sql
+ set timescaledb.enable_tiered_reads = true
+ ```
+ 1. Query the data:
+ ```sql
+ SELECT * FROM crypto_ticks srt LIMIT 10
+ ```
+ 1. Disable reads on tiered data:
+ ```sql
+ set timescaledb.enable_tiered_reads = false;
+ ```
For more information, see [Querying tiered data][querying-tiered-data].
-## Reduce the risk of downtime and data loss with high availability
+## Reduce the risk of downtime and data loss
By default, all $SERVICE_LONGs have rapid recovery enabled. However, if your app has very low tolerance
for downtime, $CLOUD_LONG offers High Availability (HA) replicas. HA replicas are exact, up-to-date copies
@@ -350,6 +386,8 @@ HA replicas automatically take over operations if the original primary data node
The primary node streams its write-ahead log (WAL) to the replicas to minimize the chances of
data loss during failover.
+
+
High availability is available in the [scale and enterprise][pricing-plans] pricing plans for $CLOUD_LONG.
diff --git a/use-timescale/integrations/index.md b/use-timescale/integrations/index.md
index 369e1c05ca..f6d0748d1d 100644
--- a/use-timescale/integrations/index.md
+++ b/use-timescale/integrations/index.md
@@ -46,6 +46,7 @@ Some of the most in-demand integrations for $CLOUD_LONG are listed below, with l
+
## Data engineering and extract, transform, load
| Name | Description |
@@ -94,7 +95,8 @@ Some of the most in-demand integrations for $CLOUD_LONG are listed below, with l
[postgresql-integrations]: https://slashdot.org/software/p/PostgreSQL/integrations/
[decodable]: /use-timescale/:currentVersion:/integrations/decodable
[power-bi]: /use-timescale/:currentVersion:/integrations/power-bi
-[fivetran]: /use-timescale/:currentVersion:/integrations/fivetran
+[fivetran]: /use-timescale/:currentVersion:/integrations/
+
[prometheus]: /use-timescale/:currentVersion:/integrations/prometheus
[amazon-sagemaker]: /use-timescale/:currentVersion:/integrations/amazon-sagemaker
[postgresql]: /use-timescale/:currentVersion:/integrations/postgresql