{kind=link}
{kind=link}
diRAGnosis is a lightweight framework, built with LlamaIndex, that allows you to evaluate the performance of LLMs and retrieval models in RAG frameworks with your documents. It can be used as an application (thanks to FastAPI + Gradio) running locally on your machine, or as a python package.
Clone the application:
git clone https://github.com/AstraBert/diRAGnosis.git
cd diRAGnosis/Docker (recommended)🐋
Required: Docker and docker compose
- Launch the Docker application:
# If you are on Linux/macOS
bash run_services.sh
# If you are on Windows
.\run_services.ps1Or, if you prefer:
docker compose up db -d
docker compose up dashboard -dYou will see the application running on http://localhost:8000/dashboard and you will be able to use it. Depending on your connection and on your hardware, the set up might take some time (up to 30 mins to set up) - but this is only for the first time your run it!
Source code🗎
Required: Docker, docker compose and conda
- Set up diRAGnosis app using the dedicated script:
# For MacOs/Linux users
bash setup.sh
# For Windows users
.\setup.ps1- Or you can do it manually, if you prefer:
docker compose up db -d
conda env create -f environment.yml
conda activate eval-framework
cd scripts/
uvicorn main:app --host 0.0.0.0 --port 8000
conda deactivateYou will see the application running on http://localhost:8000/dashboard and you will be able to use it.
As a python package, you will be able to install diRAGnosis using pip:
pip install diragnosisOnce you have installed it, you can import the four functions (detailed in the dedicated reference file) available for diRAGnosis like this:
from diragnosis.evaluation import generate_question_dataset, evaluate_llms, evaluate_retrieval, display_available_providersOnce you imported them, this is an example of how you can use them:
from qdrant_client import QdrantClient, AsyncQdrantClient
import asyncio
import os
from dotenv import load_dotenv
import json
load_dotenv()
# import your API keys (in this case, only OpenAI)
openai_api_key = os.environ["OPENAI_API_KEY"]
# define your data
input_files = ["file1.pdf", "file2.pdf"]
# create a Qdrant client (asynchronous and synchronous)
qdrant_client = QdrantClient("http://localhost:6333")
qdrant_aclient = AsyncQdrantClient("http://localhost:6333")
# display available LLM and Embedding model providers
display_available_providers()
async def main():
# generate dataset
question_dataset, docs = await generate_question_dataset(input_files = input_files, llm = "OpenAI", model="gpt-4o-mini", api_key = openai_api_key, questions_per_chunk = 10, save_to_csv = "questions.csv", debug = True)
# evaluate LLM performance
binary_pass, scores = await evaluate_llms(qc = qdrant_client, aqc = qdrant_aclient, llm = "OpenAI", model="gpt-4o-mini", api_key = openai_api_key, docs = docs, questions = question_dataset, embedding_provider = "HuggingFace", embedding_model = "Alibaba-NLP/gte-modernbert-base", enable_hybrid = True, debug = True)
print(json.dumps(binary_pass, indent=4))
print(json.dumps(scores, indent=4))
# evaluate retrieval performance
retrieval_metrics = await evaluate_retrieval(qc = qdrant_client, aqc = qdrant_aclient, input_files = input_files, llm = "OpenAI", model="gpt-4o-mini", api_key = openai_api_key, embedding_provider = "HuggingFace", embedding_model = "Alibaba-NLP/gte-modernbert-base", questions_per_chunk = 5, enable_hybrid = True, debug = True)
print(json.dumps(retrieval_metrics, indent=4))
if __name__ == "__main__":
asyncio.run(main())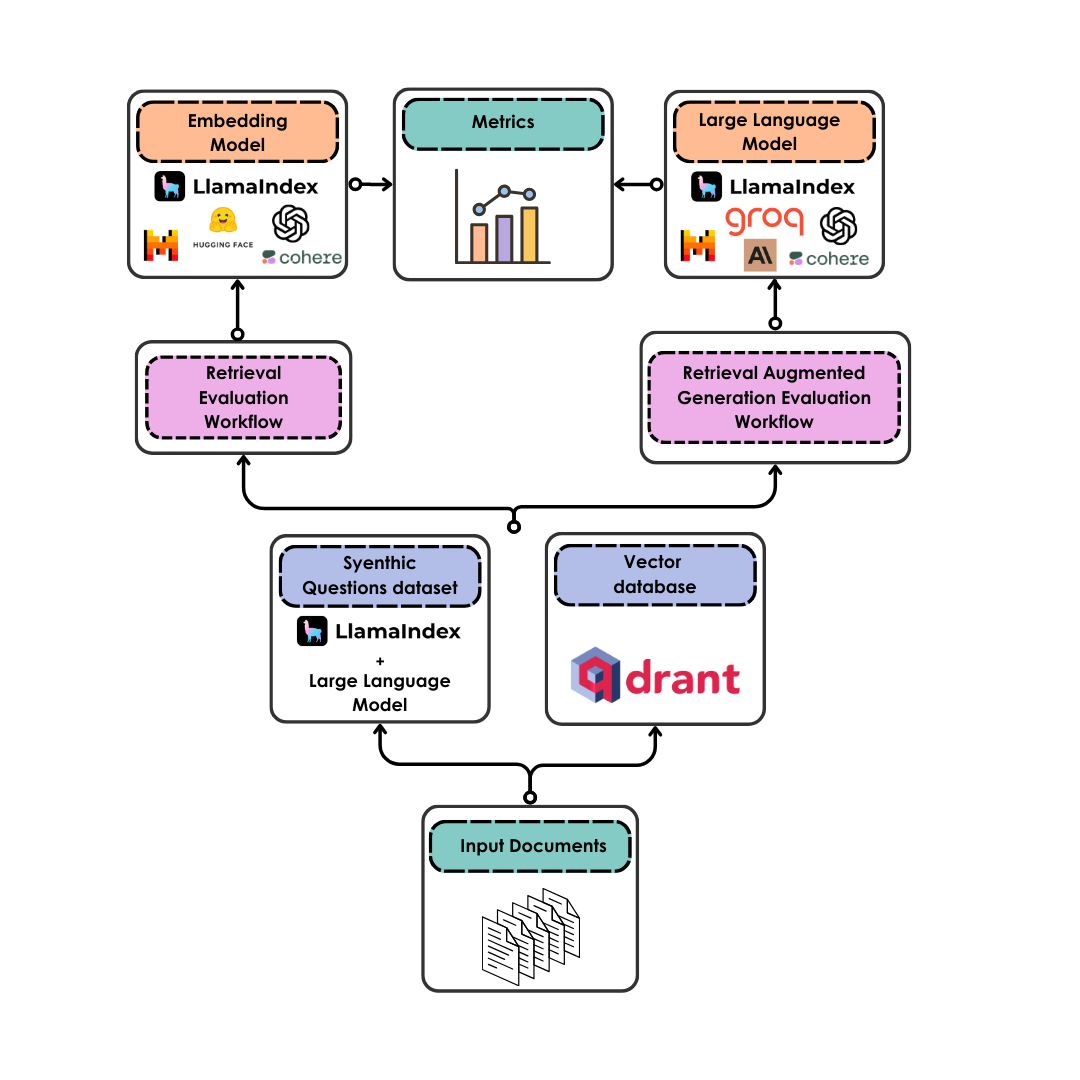
diRAGnosis takes care of the evaluation of LLM and retrieval model performance on your documents in a completely automated way:
- Once your documents are uploaded, they are converted into a synthetic question dataset (either for Retrieval Augmented Generation or for retrieval only) by an LLM of your choice
- The documents are also chunked and uploaded to a vector database served by Qdrant - you can choose a semantic search only or an hybrid search setting
- The LLMs are evaluated, with binary pass and with scores, on the faithfulness and relevancy of their answers based on the questions they are given and on the retrieved context that is associated to each question
- The retrieval model is evaluated according to hit rate (retrieval of the correct document as first document) and to MRR (Mean Reciprocal Ranking, i.e. the positioning of the correct document in the ranking of the retrieved documents)
- The metrics are returned to the user
Contributions are always welcome! Follow the contributions guidelines reported here.
The software is provided under MIT license.