RabbitMQ vs. ActiveMQ: Key Differences
RabbitMQ and ActiveMQ are two of the most popular open-source message brokers used in enterprise environments for asynchronous communication and system integration. While they serve similar purposes, they differ significantly in architecture, performance characteristics, and ideal use cases. This comprehensive comparison explores their key differences, helping you determine which solution best fits your specific needs.
RabbitMQ is an open-source message broker written in Erlang that implements the Advanced Message Queuing Protocol (AMQP). It focuses on reliability, flexibility, and ease of integration, providing built-in clustering capabilities for high availability and fault tolerance[1]. RabbitMQ is designed to get messages to their destination quickly and in the correct order, making it suitable for many real-time messaging scenarios[8].
ActiveMQ is an Apache open-source message broker written in Java that fully supports the Java Message Service (JMS) API. It's known for its broad protocol support, including AMQP, STOMP, MQTT, and others[3][10]. ActiveMQ offers flexibility and reliability with features like Master-Slave architecture and shared storage clustering, making it well-suited for enterprise applications, especially those heavily invested in Java technologies[3].
One of the most fundamental differences between these messaging platforms involves how brokers and clients interact:
RabbitMQ follows a "smart broker, dumb client" model where the broker handles the complexity of message routing and delivery[4]. This centralized intelligence allows for sophisticated message handling but can become a bottleneck at extremely high volumes.
ActiveMQ uses a more traditional approach that balances responsibilities between broker and client. While not as extreme as Kafka's "dumb broker, smart client" model, ActiveMQ provides more flexibility in how clients interact with the system.
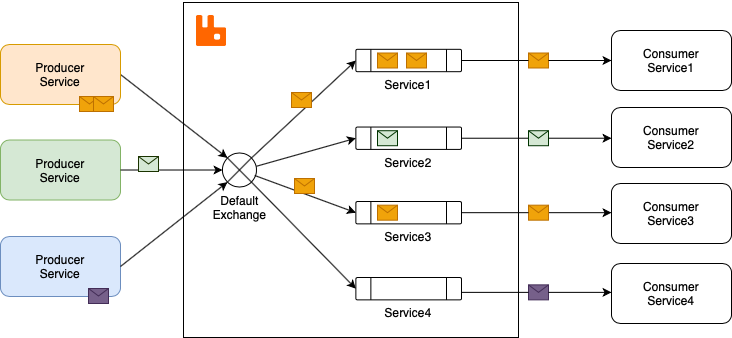
RabbitMQ uses an exchange-based architecture where:
-
Messages are published to exchanges
-
Exchanges route messages to queues based on bindings
-
Supports multiple exchange types (Direct, Fanout, Topic, Headers) for flexible routing[2][8]
ActiveMQ employs a more conventional destination-based model:
-
Messages are sent directly to queues or topics
-
Uses traditional JMS semantics
-
Provides network of brokers for distributed deployment[8]
|
Feature |
RabbitMQ |
ActiveMQ |
|---|---|---|
|
Implementation Language |
Erlang |
Java |
|
Primary Protocol |
AMQP |
JMS |
|
Additional Protocols |
MQTT, STOMP (via plugins) |
AMQP, STOMP, MQTT, OpenWire |
|
Message Routing |
Exchange/Binding/Queue model |
Traditional queues and topics |
|
High Availability |
Mirrored queues, quorum queues |
Master-Slave, shared storage |
|
Clustering |
Built-in clustering |
Network of brokers |
|
Management Interface |
Comprehensive web UI |
Web console |
|
Transaction Support |
Limited |
Full JMS transactions, XA support[11] |
|
Message Persistence |
Durable exchanges/queues |
JDBC, LevelDB, KahaDB |
|
Throughput |
Higher (5-6w TPS)[3] |
Lower (thousands TPS)[3] |
|
Latency |
Lower (can achieve ~1ms at proper load)[16] |
Higher than RabbitMQ |
|
Memory Utilization |
Memory-intensive with many queues |
JVM tuning required |
|
Deployment Complexity |
Moderate (requires Erlang) |
Moderate (requires Java) |
RabbitMQ typically outperforms ActiveMQ in scenarios requiring high message throughput. According to comparative data:
-
RabbitMQ can achieve approximately 5.95w messages per second in standard configurations, with mirrored queues reaching throughput of 38 MB/s[1][16]
-
ActiveMQ generally handles lower throughput (thousands of messages per second), making it suitable for most enterprise applications but potentially insufficient for high-volume scenarios[3]
In a benchmark comparing several messaging systems, RabbitMQ achieved impressive latencies of around 1ms at proper load levels (30 MB/s), though performance degraded significantly under higher loads[16].
RabbitMQ :
-
Erlang-based, optimized for concurrent operations
-
Memory usage increases with queue count
-
Generally efficient CPU utilization when properly configured
-
Performs well with smaller messages
ActiveMQ :
-
Java-based, requires careful JVM tuning
-
Memory usage varies based on message store
-
Typically higher CPU utilization than RabbitMQ
-
Handles larger messages more efficiently[10]
RabbitMQ is particularly well-suited for:
-
Complex routing scenarios requiring sophisticated message distribution patterns[2]
-
Financial services and payment systems needing strict message ordering and confirmation[3]
-
Microservices architectures benefiting from its flexible exchange types
-
Low-latency requirements where millisecond messaging is critical[1]
-
Polyglot environments using multiple programming languages[2]
ActiveMQ excels in these scenarios:
-
Java-centric environments heavily invested in JMS[2]
-
Traditional enterprise systems like ERP and CRM applications[3]
-
Multi-protocol requirements needing broad protocol support[14]
-
Systems requiring XA transactions for distributed transaction support[11]
-
Legacy system integration projects[3]
RabbitMQ's configuration centers around:
-
Configuration file structure : Primary rabbitmq.conf file with optional advanced.config for complex settings[5]
-
Virtual hosts : Logical groupings of resources
-
Exchange and queue definitions : Defining the messaging topology
-
Clustering configuration : For high availability setups
-
Use multiple channels over single connections to avoid connection churn; aim for one connection per process and one channel per thread[9]
-
Keep queues short to prevent resource overutilization in cluster deployments[9]
-
Implement proper queue length limits to prevent memory issues
-
Use appropriate exchange types for your routing needs
-
Set up dead-letter exchanges for handling failed message processing
ActiveMQ configuration focuses on:
-
XML-based configuration : Through activemq.xml file
-
Broker and connector settings : Defining transport and network options
-
Destination policies : Queue and topic configurations
-
Message store configuration : Persistence options
-
Security settings : Authentication and authorization
-
Optimize Producer Flow Control (PFC) to regulate message flow and prevent broker overload[7]
-
Configure appropriate memory settings to prevent out-of-memory errors
-
Select the right persistence store based on durability and performance requirements
-
Implement connection pooling to improve performance
-
Monitor broker health via JMX and other tools[7]
-
Memory management problems
-
Symptoms: High memory usage, broker crashes
-
Solutions: Implement queue length limits, use lazy queues, monitor memory usage metrics
-
-
Cluster synchronization issues
-
Symptoms: Slow node joining, performance degradation during sync
-
Solutions: Plan cluster changes during off-peak hours, monitor synchronization progress
-
-
Performance degradation with many queues
-
Symptoms: Increasing latency, decreased throughput
-
Solutions: Review queue architecture, consider queue consolidation or sharding
-
-
Message delivery delays
-
Symptoms: Increasing latency, message backlogs
-
Solutions: Monitor broker performance, optimize network configuration, increase memory allocation[6]
-
-
Connection issues
-
Symptoms: Failed connections, unpredictable disconnects
-
Solutions: Implement connection pooling, check network configuration, review security settings
-
-
Out-of-memory errors
-
Symptoms: Broker crashes, performance degradation
-
Solutions: Configure appropriate memory settings, implement producer flow control[7]
-
-
Installation requirements : Requires Erlang runtime
-
Clustering model : Nodes share users, virtual hosts, exchanges, and bindings
-
Monitoring tools : Built-in management UI, Prometheus integration
-
Resource sizing : Memory is particularly important; plan for queue growth
-
Installation requirements : Requires Java runtime
-
Clustering model : Network of brokers, Master-Slave configurations
-
Monitoring tools : Web console, JMX integration
-
Resource sizing : CPU and memory requirements depend on message volume and persistence type
Both RabbitMQ and ActiveMQ are mature, feature-rich message brokers that serve different strengths and use cases:
Choose RabbitMQ when :
-
Complex message routing is required
-
High throughput and low latency are critical
-
You need flexible exchange types for sophisticated messaging patterns
-
You're building microservices or distributed systems requiring reliable messaging
Choose ActiveMQ when :
-
JMS compliance is necessary
-
Your technology stack is heavily Java-based
-
You need broad multi-protocol support
-
Transaction support (including XA) is required
-
You're integrating with traditional enterprise systems
The decision ultimately depends on your specific requirements, existing technology stack, performance needs, and team expertise. Many organizations even use both solutions for different parts of their infrastructure, leveraging the strengths of each where they make the most sense.
If you find this content helpful, you might also be interested in our product AutoMQ. AutoMQ is a cloud-native alternative to Kafka by decoupling durability to S3 and EBS. 10x Cost-Effective. No Cross-AZ Traffic Cost. Autoscale in seconds. Single-digit ms latency. AutoMQ now is source code available on github. Big Companies Worldwide are Using AutoMQ. Check the following case studies to learn more:
-
Grab: Driving Efficiency with AutoMQ in DataStreaming Platform
-
Palmpay Uses AutoMQ to Replace Kafka, Optimizing Costs by 50%+
-
How Asia’s Quora Zhihu uses AutoMQ to reduce Kafka cost and maintenance complexity
-
XPENG Motors Reduces Costs by 50%+ by Replacing Kafka with AutoMQ
-
Asia's GOAT, Poizon uses AutoMQ Kafka to build observability platform for massive data(30 GB/s)
-
AutoMQ Helps CaoCao Mobility Address Kafka Scalability During Holidays
-
JD.com x AutoMQ x CubeFS: A Cost-Effective Journey at Trillion-Scale Kafka Messaging