This repository contains implementations and tests for several fundamental neural network models applied to the Joint Intent Recognition (IR) and Slot Filling (SF) tasks.
- Intent Recognition (IR): Classifying the overall goal or intent of an utterance (e.g., "book a flight").
- Slot Filling (SF): Identifying and extracting specific pieces of information (slots) within the utterance that are relevant to the intent (e.g., "New York" as destination, "tomorrow" as date).
This project includes implementations for training and evaluating the following model architectures for the joint IR and SF tasks:
- Convolutional Neural Network (CNN)
- Long Short-Term Memory (LSTM)
- Gated Recurrent Unit (GRU)
- Result-based Bi-Feedback Network (RBFN)
- Transformer-based Models:
- Frozen Pre-trained BERT (using
bert-base-cased,model_type='bertfreeze') - Freezes the original BERT encoder and trains only the downstream task layers. - Custom-Configured Hugging Face BERT Model (using
transformers.BertModelwith custom config,model_type='bert') - Builds a BERT-like model from scratch using Hugging Face components. - PyTorch Transformer Encoder based Model (using
torch.nn.TransformerEncoder,model_type='transformer') - Builds a Transformer encoder model using standard PyTorch modules.
- Frozen Pre-trained BERT (using
The dataset used in this project is sourced from the AGIF repository. Please refer to their repository for details on how to obtain the raw data. After obtaining the raw data, use the data preprocessing script provided in this repository.
For the Frozen Pre-trained BERT (bertfreeze) model type, the bert-base-cased model from Hugging Face Transformers is used. If you are running experiments offline, ensure you have this model downloaded locally in the bert-base-cased directory at the root of this project. The other Transformer-based models (bert, transformer) are trained from scratch using custom configurations.
Base hyperparameters and training settings (like batch size, data path) can be adjusted by modifying the configs/config.yaml file. The hyperparameters specific to each model type for the search process are defined within the hyperparameter_search.py script.
-
Data Preprocessing: Prepare the dataset by running the preprocessing script. Ensure you have placed the raw data in the expected location (
data/folder as per yourconfig.yaml).python data_processing.py
-
Single Model Training (from config): Train a single model configuration as defined by the default settings in
main.pyor specified via the--model_typeargument.# Train the default model (e.g., as set in main.py) python main.py # Or train a specific model type python main.py --model_type lstm --data_path data/MixATIS_clean_processed.pth # Available types: cnn, lstm, gru, rbfn, bert-freeze, bert, transformer
The training process will output loss and evaluation metrics on the test set, and the trained model checkpoint will be saved to the
checkpoints/directory. -
Hyperparameter Search: To find potentially better hyperparameters for each model type, use the
hyperparameter_search.pyscript. This script iterates through predefined hyperparameter grids, trains each combination for a specified number of epochs, evaluates performance on the validation set (data['val']), and saves the best model and parameters found for each model type based on overall accuracy.A convenience shell script
search_all_models.shis provided to run the hyperparameter search sequentially for all implemented model types.# Run the hyperparameter search for all models ./search_all_models.sh # You can optionally specify the number of epochs for each trial (default is 10) # ./search_all_models.sh 20
The results, including the best parameters found (in a
.jsonfile) and the corresponding model checkpoint (in a.pthfile) for each model type, are saved in separate subdirectories within thecheckpoints/hyperparameter_search/directory (e.g.,checkpoints/hyperparameter_search/cnn/best_params_cnn.json).You can also run the search for a specific model type directly:
python hyperparameter_search.py --data_path data/MixATIS_clean_processed.pth --model_type cnn --search_epochs 15 --save_dir checkpoints/hyperparameter_search
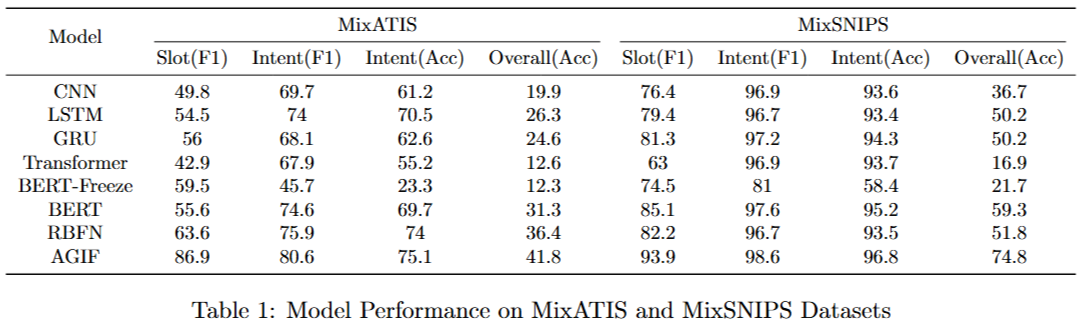
The prediction results of the model obtained using the optimal hyperparameters are as follows: