DATASETS
PyLIDAR-SLAM integrates the following LiDAR Datasets:
The following describes for each dataset the installation instructions, how to adapt the configurations, and how to run the SLAM on these Datasets.
For each dataset a default YAML config file is given in the folder dataset. These configs are loaded by the scripts
run.pyandtrain.pywhile loading the config. To select the appropriate dataset, use the command argumentdataset=<dataset_name>where<dataset_name>is the name of the associated hydra config. For examplepython run.py dataset=kittiwill launch the default SLAM on the KITTI benchmark.
The hydra dataset config files are:
To modify fields of a
datasetconfig in the command line, pass it as argument using hydra's mechanism, (e.g.python run.py dataset=kitti dataset.lidar_height=64 dataset.lidar_width=840will project the dataset pointclouds in vertex maps of dimension 3x64x840)
/!\ Note that the dataset config files will require some environment variables to be set which points to the root folder of each datasets. If error arise, make sure that the environment variables (mentioned below) have been properly set.
The configurations can also be defined programmatically (ie not using the scripts
run.pynottrain.py). Each dataset defines aDatasetConfigis the (abstract) configuration dataclass matching a hydra's config file. And aDatasetLoaderwhich can load each sequence defined in the dataset as atorch.utils.data.Dataset.
The odometry benchmark of KITTI's dataset (follow link) consists of 21 sequences, 11 of which have the ground truth poses (for more than 20k lidar frames). The LiDAR sensor capturing the environment is a rotating 64 LiDAR Channel.
/!\ The frame are corrected using pose obtained from a Visual-SLAM, and is thus not the raw data obtained from the sensor.

- Download the lidar frames of the odometry benchmark (at this download link (~80GB))
- Download the ground truth poses of the odometry benchmark (at this download link)
- Extract both archives in the same root directory
The layout of KITTI's data on disk must be as follows:
├─ <KITTI_ODOM_ROOT> # Root of the Odometry benchmark data
├─ poses # The ground truth files
├─ 00.txt
├─ 01.txt
...
└─ 10.txt
└─ sequences
├─ 00
├─ calib.txt
└─ velodyne
├─ 000000.bin
├─ 000001.bin
...
├─ 01
├─ calib.txt
└─ velodyne
├─ 000000.bin
...
...Before calling run.py or train.py, the following environment variables must be set:
KITTI_ODOM_ROOT: points to the root dataset as defined above.
For example, to run the ICP odometry on KITTI:
# Set up the following required environment variables
KITTI_ODOM_ROOT=<path-to-kitti-odometry-root-directory>
# Run the script
python run.py dataset=kitti ... (other parameters)See kitti_dataset.py for more details.
Following the KITTI dataset, the same team introduced KITTI-360 with much longer sequences and motion which is not corrected (by opposition to the KITTI benchmark).
Similarly to KITTI:
- Download the lidar frames from the main page KITTI-360
- Extract the archives to the root directory
The layout of KITTI-360's data on disk must be as follows:
├─ <KITTI_360_ROOT>
├─ data_3d_raw # The ground truth files
├─ 2013_05_28_drive_0000_sync
├─ velodyne_points
├─ timestamps.txt
├─ data
├─ 0000000000.bin
├─ 0000000001.bin
├─ ...
...
├─ data_poses # The ground truth files
├─ 2013_05_28_drive_0000_sync
├─ poses.txt
├─ cam0_to_world.txt
Before calling run.py or train.py, the following environment variables must be set:
KITTI_360_ROOT: points to the root dataset as defined above.
For example, to run the ICP odometry on KITTI-360:
# Set up the following required environment variables
KITTI_360_ROOT=<path-to-kitti-360-root-directory>
# Run the script
python run.py dataset=kitti_360 ... (other parameters)The Ford Campus Dataset consists of 2 large sequences of LiDAR data acquired with a HDL-64 with GPS ground truth (see the page Ford Campus for more details).
- Download the two sequences of the dataset: dataset-1 ~78GB, dataset-2 ~119GB
- Alternatively download the sampled data of the dataset-1 ~6GB
- Extract both archives in the same root directory
The expected layout of Ford Campus data on disk is as follows:
├─ <FORD_ROOT> # Root of the data
├─ IJRR-Dataset-1
└─ SCANS # The pointclouds are read from the Scan files
├─ Scan0075.mat
├─ Scan0076.mat
...
└─ IJRR-Dataset-2
...Before calling run.py or train.py, the following environment variables must be set:
-
FORD_ROOT: points to the root dataset as defined above.
Example running the ICP odometry on Ford Campus:
# Set up the following required environment variables
FORD_ROOT=<path-to-ford-campus-root-directory>
# Run the script
python run.py dataset=ford_campusSee ford_dataset.py for more details.
NCLT contains multiple sequences of the same environment captured with multiple sensors including a HDL-32 mounted on a segway and accurate GPS groundtruth.
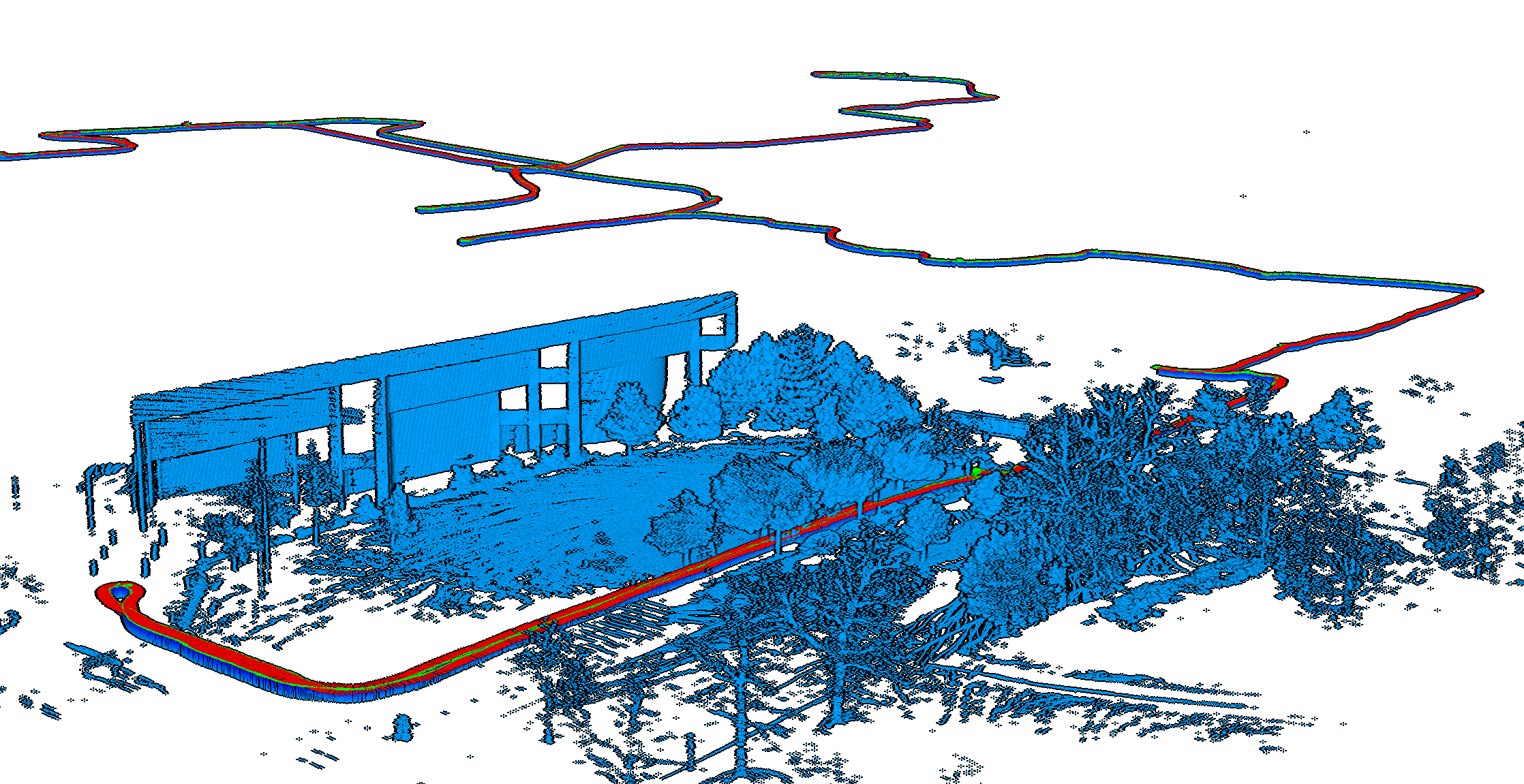
The data for each sequences can be downloaded on the dataset main page NCLT.
- Download the sequences you are interested in (column
Velodyne) - For each sequence downloaded, download the associated ground truth (column
Ground Truth Pose) - Extract from the archives of each sequence the files with the following layout:
├─ <NCLT_ROOT> # Root of the data
├─ 2012-04-29 # Date of acquisition of the sequence
└─ velodyne_sync # The folder containing the velodyne aggregated pointclouds
├─ 1335704127712909.bin
├─ 1335704127712912.bin
...
└─ groundtruth_2012-04-29.csv # Corresponding ground truth file
... # Idem for other sequencesBefore calling run.py or train.py, the following environment variables must be set:
-
NCLT_ROOT: points to the root dataset as defined above.
Example running the ICP odometry on NCLT:
# Set up the following required environment variables
NCLT_ROOT=<path-to-ford-campus-root-directory>
# Run the script
python run.py dataset=nclt ...See nclt_dataset.py for more details.
Contains long sequences of a college campus acquired with a Ouster LiDAR sensor with 64 channels, mounted on a handheld acquisition platform. The dataset has accurate ground truth acquired by registration of ouster scan on a precise 3D map acquired with a survey-grade laser scanner.
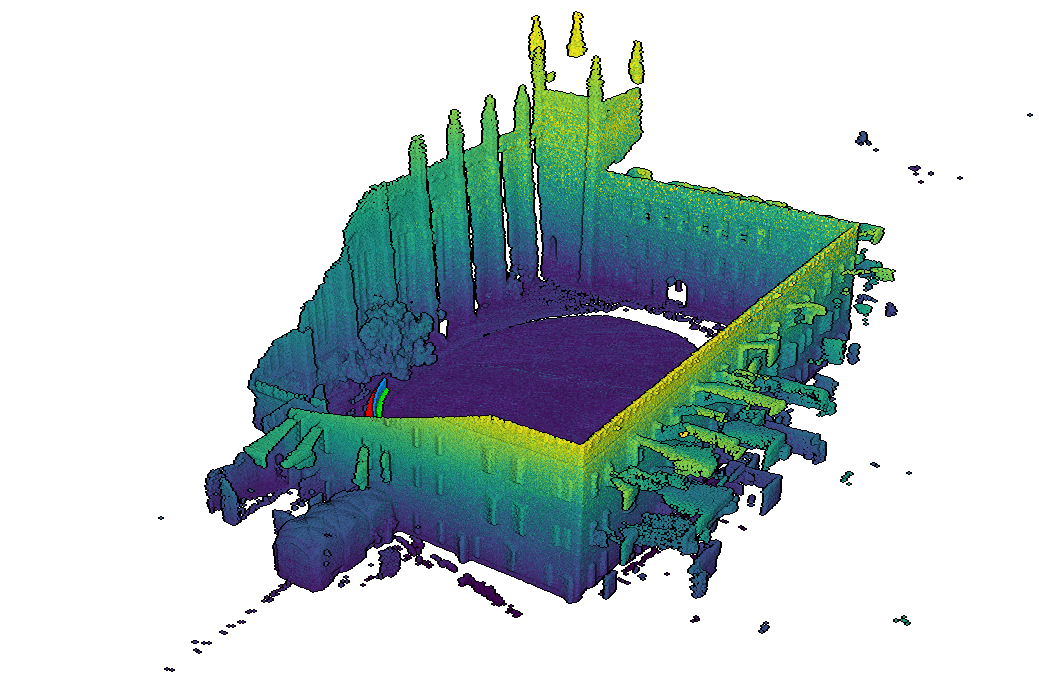
- Go to the dataset webpage and register to access the google drive.
- Download from
01_short_experimentand02_long_experimentfolders on the drive the poses (relative path:ground_truth/registered_poses.csv) and the ouster scans as.pcdfiles (in the relative pathraw_format/ouster_scan/.) - Extract the zip files in order to have the following layout on disk:
├─ <NHCD_ROOT> # Root of the data
├─ 01_short_experiment # Date of acquisition of the sequence
└─ ouster_scan # The folder containing the ouster scans
├─ cloud_1583836591_182590976.pcd
...
└─ ground_truth # The sequence ground truth files (in the reference frame of the left camera)
├─ registered_poses.csv
... # Idem for other sequenceBefore calling run.py or train.py, the following environment variables must be set:
-
NHCD_ROOT: points to the root dataset as defined above.
Example running the ICP odometry on the Newer Handheld College Dataset:
# Set up the following required environment variables
export NHCD_ROOT=<path-to-ford-campus-root-directory>
# Run the script
python run.py dataset=nhcdSee nhcd_dataset.py for more details.
pyLiDAR-SLAM also support Rosbags, using the python package
rosbag(see INSTALLATION for more details on how to install the rosbag support).
To use pyLiDAR-SLAM with a rosbag, you need to define the main_topic (ie the point cloud topic), the path to the rosbag. Note that ros drivers for different lidars will aggregate the pointcloud differently. For some LiDAR sensors, the ros-drivers will return the aggregated pointclouds with/without timestamps (corresponding to a full 360 sweep for rotating sensors), or small timestamped packets (as in the public raw data from CARTOGRAPHER used in the introduction).
We provide the option to accumulate scans. See below an example of usage:
python3 run.py /
dataset=rosbag /
dataset.main_topic=<the-main-point-cloud-topic> /
dataset.accumulate_scans=<whether-to-accumulate-scans> /
dataset.frame_size=<nb-frames-to-accumulate> /
dataset.file_path=<path-to-the-rosbag>
...
Note: This should be considered an experimental feature (as there is still some work to be done to integrate properly)
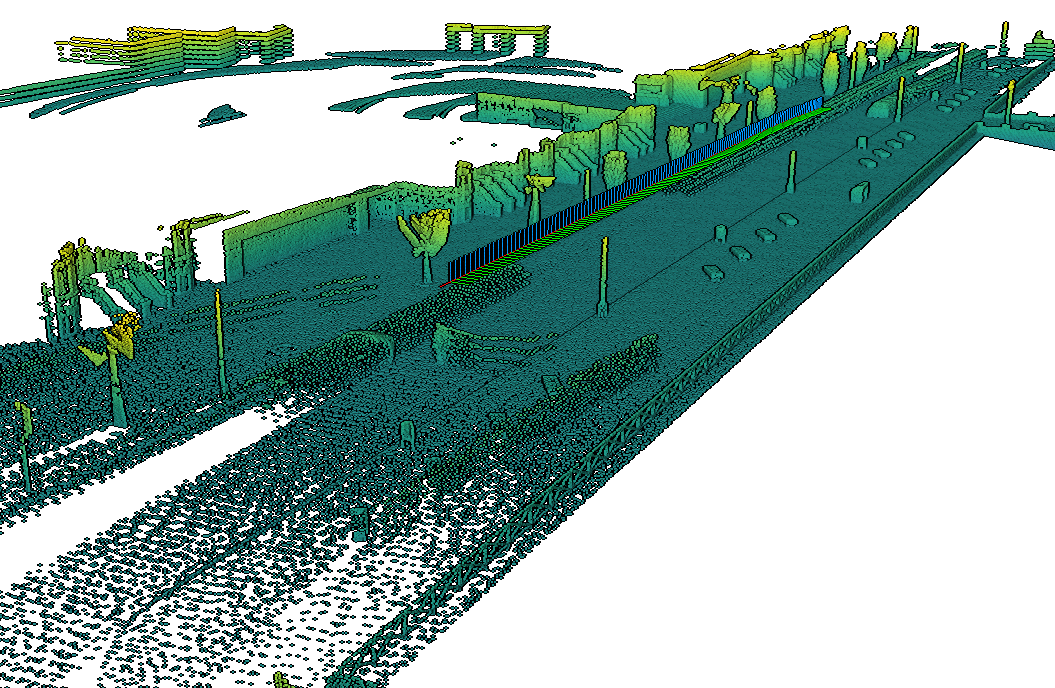
In our work
CT-ICPwe made publically available multiple datasets with as convenient PLY file formats.We make these datasets with pyLiDAR-SLAM. Follow the download instructions of the project's main page, and to use CT-ICP with pyLiDAR-SLAM see below:
python3 run.py /
dataset=ct_icp
dataset.options.dataset=KITTI_CARLA
dataset.options.root_path=<path-to-KITTI_CARLA_ROOT>
dataset.train_sequences=[Town01]
...
Note: You need to install
pyct_icpto run this module. See INSTALLATION for more details.