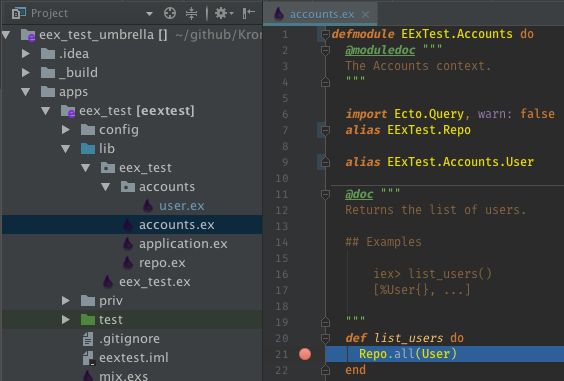
Features
-
Features
- Project
- Project Structure
- Project Settings
- Module Settings
- New Elixir File
- Syntax Highlighting and Semantic Annotation
- Grammar parsing
- Inspections
- Quick Fixes
- Commenter
- Credo
- Debugger
- Delimiters
- Embedded Elixir (EEx) Templates
- Building/Compiling
- Live Templates
- Run/Debug Configurations
- .beam Files
- Completion
- Go To Declaration
- Formatting
- Go To Related
- Go To Symbol
- Go To Test
- Go To Test Subject
- Find Usages and Show Usages
- Refactor
- SDK
- Structure
| Feature | Rich | Small | Alternative |
|---|---|---|---|
| Project | Yes | No | 1. Open directory 2. Setup the SDK |
| Project Structure | Automatic | Manual | |
| Project Settings | Yes | No | |
| Module Settings | Yes | No | |
| New Elixir File | Yes | Yes | |
| Syntax Highlighting and Semantic Annotation | Yes | Yes | |
| Grammar Parsing | Yes | Yes | |
| Inspections | Yes | Yes | |
| Quick Fixes | Yes | Yes | |
| Code Folding | Yes | Yes | |
| Commenter | Yes | Yes | |
| Debugger | Yes | Yes | |
| Delimiters | Yes | Yes | |
| Embedded Elixir (EEx) Templates | Yes | Yes | |
| Building/Compiling | Yes | No | Build/compile as part mix run configurations only |
| Live Templates | Yes | Yes | |
| Run Configurations | Yes | Yes | |
| Completion | Yes | Yes | |
| Decompilation | Yes | Yes | |
| Go To Declaration | Yes | Yes | |
| Formatting | Yes | Yes | |
| Go To Related | Yes | Yes | |
| Go To Symbol | Yes | Yes | |
| Go To Test | Yes | Yes | |
| Go To Test Subject | Yes | Yes | |
| Find Usage | Yes | Yes | |
| Refactor | Yes | Yes | |
| SDK | Yes | Yes | |
| Structure | Yes | Yes |
- Open Directory of the project
- Setup the SDK
If you've already created a mix project, you can load it as an Elixir project into the plugin.
-
File > New > Project From Existing Sources...
-
Select the root directory of your project.
-
Select "Import project from external model"
-
Select Mix

-
Click Next
-
Select a Project SDK directory by clicking Configure.
-
The plugin will automatically find the newest version of Elixir installed. (NOTE: SDK detection only works for Linux, homebrew installs on OSX, and Windows. Open an issue with information about Elixir install locations on your operating system and package manager to have SDK detection added for it.)
-
If the automatic detection doesn't find your Elixir SDK or you want to use an older version, manually select select the directory above the
bindirectory containingelixir,elixirc,iex, andmix. (On Windows it is the directory containingelixir.bat,elixirc.bat,iex.bat, andmix.bat.) -
Click Finish after you select SDK name from the Project SDK list.
-
The "Mix project root" will be filled in with the selected directory.
-
(Optional) Uncheck "Fetch dependencies with mix" if you don't want to run
mix deps.getwhen importing the project
- If "Fetch dependencies with mix" is checked both
mix local.hex --forceandmix deps.getwill be run.
- Click Next
- All directories with
mix.exsfiles will be selected as "Mix projects to import". To import just the main project and not its dependencies, click Unselect All. - Check the box next to the project root to use only its
mix.exs. (It will likely be the first checkbox at the top.) - Click Finish
If you've already created a (non-mix) project, you can load it as an Elixir project into the plugin.
- File > New > Project From Existing Sources...
- Select the root directory of your project.
- Leave the default selection, "Create project from existing sources"
- Click Next
- Project name will be filled with the basename of the root directory. Customize it if you like.
- Project location will be the root directory.
- Click Next.
- If you previously opened the directory in IntelliJ or another JetBrains IDE, you'll be prompted to overwrite the .idea directory. Click Yes.
- You'll be prompted with a list of detected Elixir project roots to add to the project. Each root contains a
mix.exs. Uncheck any project roots that you don't want added. - Click Next.
- Select a Project SDK directory by clicking Configure.
- The plugin will automatically find the newest version of Elixir installed. (NOTE: SDK detection only works for Linux, homebrew installs on OSX, and Windows. Open an issue with information about Elixir install locations on your operating system and package manager to have SDK detection added for it.)
- If the automatic detection doesn't find your Elixir SDK or you want to use an older version, manually select select
the directory above the
bindirectory containingelixir,elixirc,iex, andmix. - Click Next after you select SDK name from the Project SDK list.
- Click Finish on the framework page. (No framework detection is implemented yet for Elixir.)
- Choose whether to open in a New Window or in This Window.
If you want to create a basic (non-mix) Elixir project with a lib directory, perform the following steps.
-
File > New > Project

-
Select Elixir from the project type menu on the left
-
Click Next

-
Select a Project SDK directory by clicking Configure.

-
Select a Project SDK directory by clicking Configure.
-
The plugin will automatically find the newest version of Elixir installed.
- macOS / OSX
- Homebrew (
/usr/local/Cellar/elixir) - Nix (
/nix/store)
- Homebrew (
- Linux
/usr/local/lib/elixir- Nix and NixOS (
/nix/store)
- Windows
- 32-bit (
C:\Program Files\Elixir) - 64-bit (
C:\Program Files (x86)\Elixir) - (NOTE: SDK detection only works for Open an issue with information about Elixir install locations on your operating system and package manager to have SDK detection added for it.)
- 32-bit (
- macOS / OSX
-
If the automatic detection doesn't find your Elixir SDK or you want to use an older version, manually select select the directory above the
bindirectory containingelixir,elixirc,iex, andmix. If thebin,lib,orsrcdirectory is incorrectly selected, it will be corrected to the parent directory. -
Click Next after you select SDK name from the Project SDK list.
-
Change the
Project nameto the name your want for the project
-
(Optionally) change the
Project locationif the directory does not match what you want -
(Optionally) expand
More Settingsto change theModule name,Content root,Module file location, and/orProject format. The defaults derived from theProject nameandProject locationshould work for most projects. -
Click Finish
-
Choose whether to open in a New Window or in This Window.

- Excluded
-
_build(Output frommix) -
rel(Output fromexrm)
-
- Sources
lib
- Test Sources
test

The Project Settings include
- Project Name
- Project SDK

The Module Settings include Marking directories as
- Excluded
- Sources
- Tests

Module paths list the output directories when compiling code in the module. There is a an "Output path" for dev
MIX_ENV and "Test output path" for the test MIX_ENV.

Module dependencies are currently just the SDK and the sources for the module. Dependencies in deps are not
automatically detected at this time.
-
Right-click a directory (such as
libortestin the standardmix newlayout) -
Select New > Elixir File.

-
Enter an Alias for the Module name, such as
MyModuleorMyNamespace.MyModule. -
Select a Kind of Elixir File to use a different template.

An underscored file will be created in an underscored directory lib/my_namespace/my_module.ex) with the given module
name with be created:
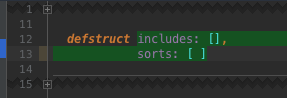
defmodule MyNamespace.MyModule do
@moduledoc false
endAn underscored file will be created in an underscored directory lib/my_namespace/my_module.ex) with the given module
name with be created. It will have a start/2 function that calls MyNamespace.MyModule.Supervisor.start_link/0.
defmodule MyNamespace.MyModule do
@moduledoc false
use Application
def start(_type, _args) do
MyNamespace.MyModule.Supervisor.start_link()
end
endAn underscored file will be created in an underscored directory lib/my_namespace/my_module.ex) with the given module
name with be created. It will have a start_link/1 function that calls Supervisor.start_link/0 and init/1 that sets
up the child specs. It assumes a MyWorker child that should be supervised :one_for_one.
defmodule MyNamespace.MyModule.Supervisor do
@moduledoc false
use Supervisor
def start_link(arg) do
Supervisor.start_link(__MODULE__, arg)
end
def init(arg) do
children = [
worker(MyWorker, [arg], restart: :temporary)
]
supervise(children, strategy: :one_for_one)
end
endAn underscored file will be created in an underscored directory lib/my_namespace/my_module.ex) with the given module
name with be created. It will have a start_link/2 function that calls GenServer.start_link/3 and the minimal
callback implementations for init/1, handle_call/3, and handle_cast/2.
The Elixir use GenServer supplies these callbacks, so this template is for when you want to change the callbacks, but
would like the stubs to get started without having to look them up in the documentation.
defmodule MyNamespace.MyModule do
@moduledoc false
use GenServer
def start_link(state, opts) do
GenServer.start_link(__MODULE__, state, opts)
end
def init(_opts) do
{:ok, %{}}
end
def handle_call(_msg, _from, state) do
{:reply, :ok, state}
end
def handle_cast(_msg, state) do
{:noreply, state}
end
endAn underscored file will be created in an underscored directory lib/my_namespace/my_module.ex) with the given module
name with be created. The minimal callback implementations for init/1, handle_event/2, and handle_call/2,
handle_info/2.
The Elixir use GenEvent supplies these callbacks, so this template is for when you want to change the callbacks, but
would like the stubs to get started without having to look them up in the documentation.
defmodule MyNamespace.MyModule do
@moduledoc false
use GenEvent
# Callbacks
def init(_opts) do
{:ok, %{}}
end
def handle_event(_msg, state) do
{:ok, state}
end
def handle_call(_msg, state) do
{:ok, :ok, state}
end
def handle_info(_msg, state) do
{:ok, state}
end
endSyntax highlighting of lexer tokens and semantic annotating of parser elements can be customized in in the Color Settings page for Elixir (Preferences > Editor > Color & Fonts > Elixir).
| Text Attribute Key Display Name | Tokens/Elements | Scheme | |||
|---|---|---|---|---|---|
| Default | Darcula | ||||
| Alias | String |

|

|
||
| Atom |
|

|

|
||
| Braces and Operators | Bit |
|

|

|
|
| Braces and Operators | Braces |
|

|

|
|
| Braces and Operators | Brackets |
|

|

|
|
| Braces and Operators | Character Token | ? |

|

|
|
| Braces and Operators | Comma | , |

|

|
|
| Braces and Operators | Dot | . |

|

|
|
| Braces and Operators | Interpolation |
|

|

|
|
| Braces and Operators | Maps and Structs | Maps |
|

|

|
| Braces and Operators | Maps and Structs | Maps |
|

|

|
| Braces and Operators | Operation Sign |
|

|

|
|
| Braces and Operators | Parentheses |
|

|

|
|
| Braces and Operators | Semicolon | ; |

|

|
|
| Calls | Function | inspect |
 *Only the Italic attribute *Only the Italic attribute
|
 *Only the Italic attribute *Only the Italic attribute
|
|
| Calls | Macro | inspect |
 *Only the Bold and Italic attributes *Only the Bold and Italic attributes
|
 *Only the Bold and Italic attributes *Only the Bold and Italic attributes
|
|
| Calls | Predefined |
|
 *Only the Foreground attribute *Only the Foreground attribute
|
 *Only the Foreground attribute *Only the Foreground attribute
|
|
| Comment | # Numbers |

|

|
||
| Keywords | end |

|

|
||
| Module Attributes | @custom_attr |

|

|
||
| Module Attributes | Documentation | @doc |

|

|
|
| Module Attributes | Documentation | Text | Simple module docstring |

|

|
| Module Attributes | Types | Callback | func |

|

|
| Module Attributes | Types | Specification | func |

|

|
| Module Attributes | Types | Type | parameterized |

|

|
| Module Attributes | Types | Type Parameter | type_parameter |

|

|
| Numbers | Base Prefix | Non-Decimal |
|

|

|
| Numbers | Base Prefix | Obsolete Non-Decimal |
|

|

|
| Numbers | Decimal Exponent, Mark, and Separator |
|

|

|
|
| Numbers | Digits | Invalid |
|

|

|
| Numbers | Digits | Valid |
|

|

|
| Textual | Character List |
'This is a list'
|

|

|
|
| Textual | Escape Sequence |
\x{12}
|

|

|
|
| Textual | Sigil |
|

|

|
|
| Textual | String |
"Hello world"
|

|

|
|
| Variables | Ignored |
_
|

|

|
|
| Variables | Parameter |
|
|||
Built on top of highlighted tokens above, the parser understands the following parts of Elixir grammar as valid or allows the grammar because they contain correctable errors:
-
Empty Parentheses (
()) -
Keyword Lists
- Keyword Keys - Aliases, identifiers, quotes, or operators when followed immediately by a colon and horizontal or vertical space.
- Keyword Values - Empty parentheses (
()) and matched expressions.
-
Matched Expressions,
in other words, unary and binary operations on variable, function, and macro names and values (numbers, strings,
char lists, sigils, heredocs,
true,false, andnil). -
No Parentheses expressions, which
are function calls with neither parentheses nor
doblocks that have either (1) a positional argument and keyword arguments OR (2) two or more positional arguments with optional keyword arguments. - Anonymous function calls
.()with either no arguments; a no parentheses arguments expression as an argument; keywords as an argument; positional argument(s); or positional arguments followed by keywords as arguments. - Remote function calls (
Alias.function,:atom.function, etc) and local function calls (function) with...- No Parentheses with...
- No Arguments (
Alias.function) - Keywords (
Alias.function key: value) - Nested No Parentheses Call (
Alias.function Inner.function positional, key: value) - Positional and Keyword arguments (
Alias.function positional, key: value) - Matched Expression (
Alias.function 1 + 2)
- No Arguments (
- Parentheses with...
- No arguments (
Alias.function()) - No Parentheses Call (
Alias.function(Inner.function positional, key: value) - Keywords (
Alias.function(key: value)) - Positional and Keyword arguments (
Alias.function(positional, key: value)) - Trailing parentheses for quoting (
def unquote(variable)(positional))
- No arguments (
- No Parentheses with...
- Bracket expression (
variable[key]) - Block expressions (
function do end) - Unmatched expressions, in other words combinations of block expressions and matched expressions.
Inspections mark sections of code with warnings and errors. They can be customized from the Preferences > Inspections > Elixir.

Detects when compiler will throw unexpected comma. Parentheses are required to solve ambiguity in nested calls.
Function calls with multiple arguments without parentheses cannot take as arguments functions with multiple arguments
without parentheses because which functional gets which arguments is unclear as in the following example:
outer_function first_outer_argument,
# second argument is another function call without parentheses, but with multiple arguments
inner_function first_inner_argument,
ambiguous_keyword_key: ambiguous_keyword_valueTo fix the ambiguity if first_inner_keyword_key: first_inner_keyword_value should be associated, add parentheses
around the inner function's arguments:
# keywords are for inner function
outer_function first_outer_argument
inner_function(
first_inner_argument
ambiguous_keyword_key: ambiguous_keyword_value
)
# keywords are for outer function
outer_function first_outer_argument
inner_function(
first_inner_argument
),
ambiguous_keyword_key: ambiguous_keyword_value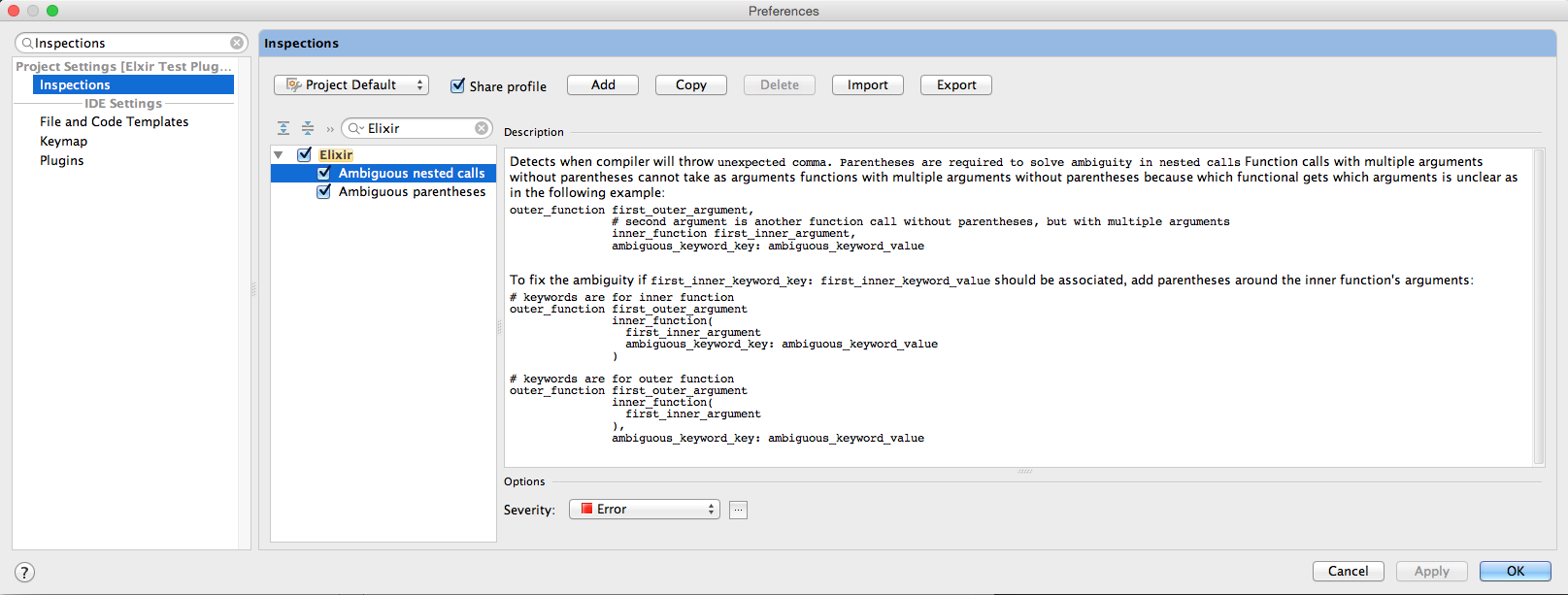
Preferences > Inspections > Elixir > Ambiguous nested calls

Ambiguous nested call inspection marks the error on the comma that causes the ambiguity.

Mousing over the comma marked as an error in red (or over the red square in the right gutter) will show the inspection describing the error.
Detects when compiler will throw unexpected parenthesis. If you are making a function call, do not insert spaces in between the function name and the opening parentheses.
Function calls with space between the function name and the parentheses cannot distinguish between function calls with
parentheses, but with an accidental space before the ( and function calls without parentheses where the first
positional argument is in parentheses.
function ()To fix the ambiguity remove the space or add outer parentheses without the space if the first argument should be ():
# extra space, no arguments to function
function()
# first argument is `()`
function(())function (key: value)Keywords inside parentheses is not valid, so the only way to fix this is to remove the space
function(key: value)function (first_positional, second_positional)A list of positional arguments in parenthenses is not valid, so the only way to fix this is to remove the space
function(first_positional, second_positional)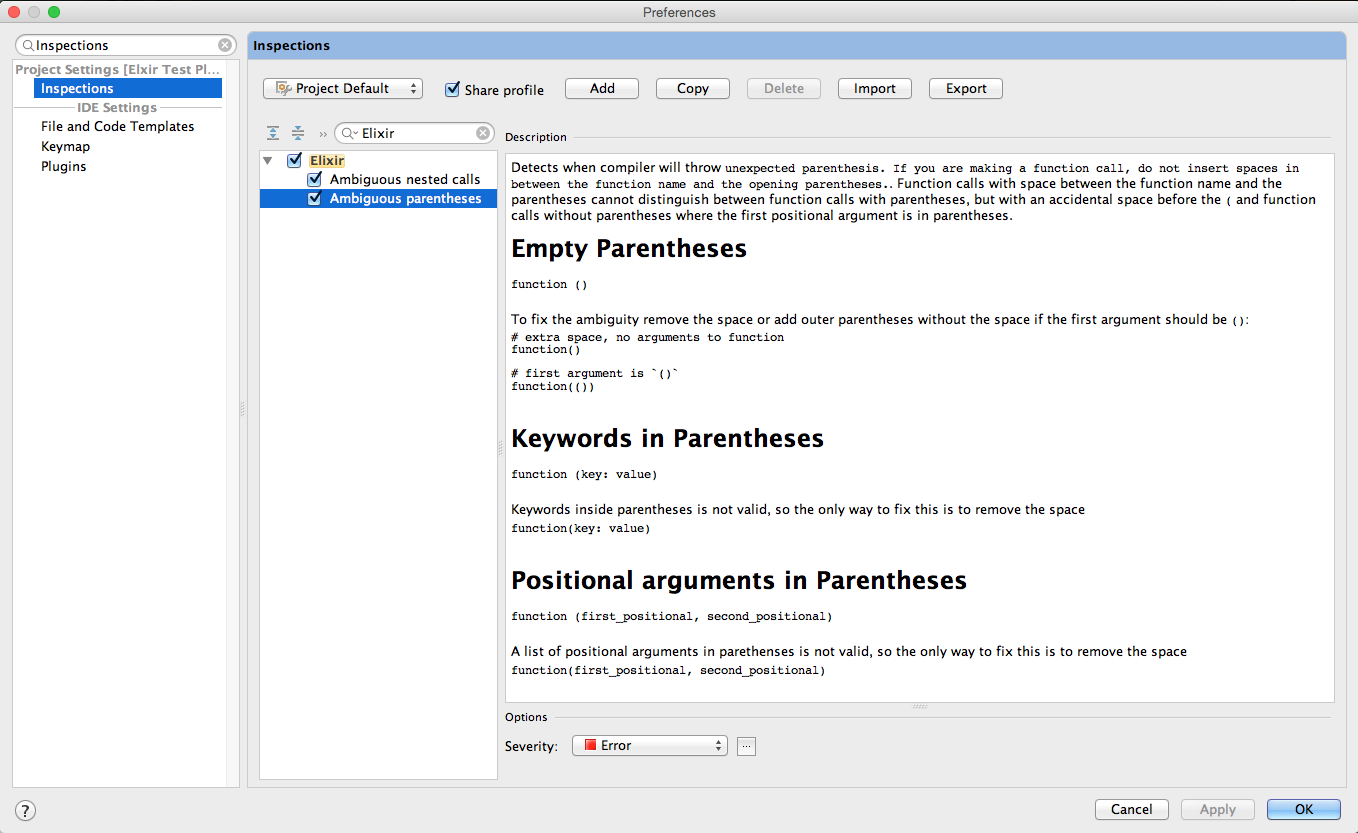
Preferences > Inspections > Elixir > Ambiguous parentheses

Ambiguous parentheses inspection marks the error on the parenthetical group surrounded by the parentheses that are ambiguous due to the preceding space.

Mousing over the parenthetical group marked as an error in red (or over the red square in the right gutter) will show the inspection describing the error.
Type specifications separate the name from the definition using ::.
@type name: definitionReplace the : with ::
@type name :: definitionone.(
one,
two positional, key: value,
three
)Keywords can only appear at the end of an argument list, so either surround the no parentheses expression argument with parentheses, or move the the keywords to the end of the list if it wasn't meant to be a no parentheses expression.
one.(
one
two(positional, key: value),
three
)OR
one.(
one,
two,
three,
key: value
)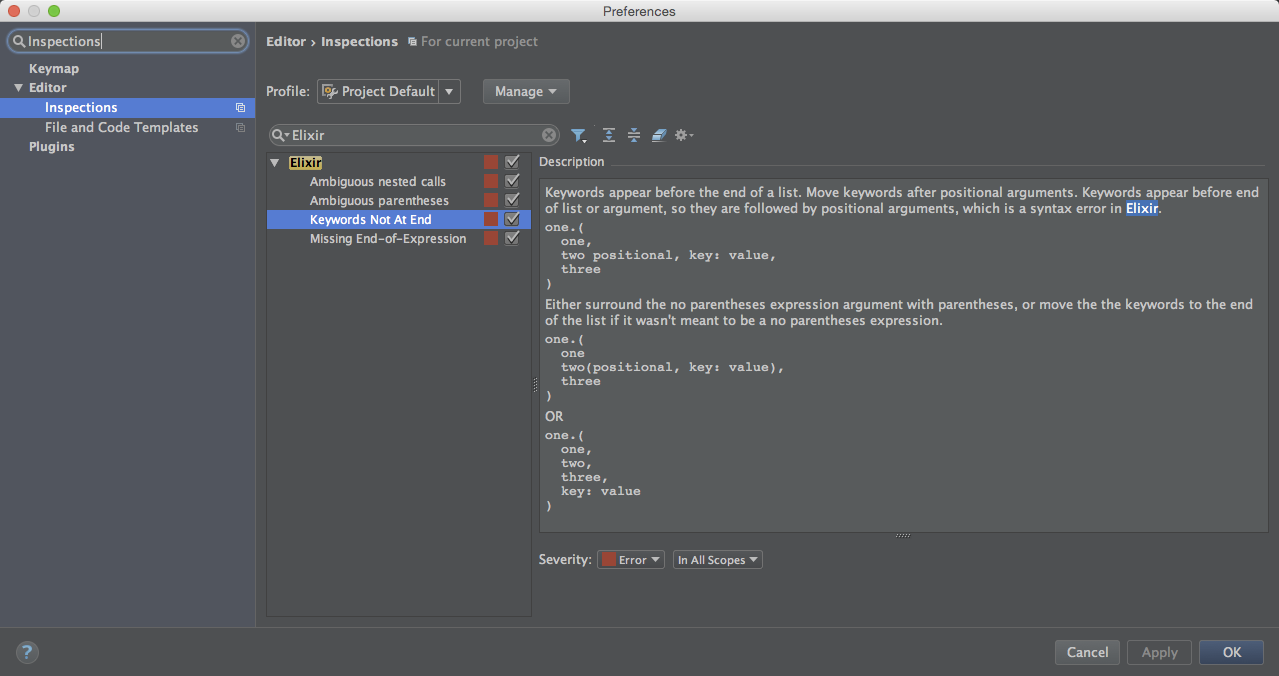
Preferences > Inspections > Elixir > Keywords Not At End

Keywords Not At End inspection marks the error over the keywords that need to be surrounded by parentheses or moved to the end of the list.

Mousing over the keywords marked as an error in red (or over the red square in the right gutter) will show the inspection describing the error.
Type specifications separate the name from the definition using ::.
@type name = definitionReplace the = with ::
@type name :: definitionQuick Fixes are actions IntelliJ can take to change your code to correct errors (accessed with Alt+Enter by default).
If a type specification uses a single : instead of ::, then hit Alt+Enter on the : to change it to :: and fix the type spec.
If a type specification uses = instead of ::, then hit Alt+Enter on the = to change it to :: and fix the type spec.
If a set of parentheses is marked as ambiguous then the space before it can be removed to disambiguate the parentheses with Alt+Enter. (Will vary based on keymap.)
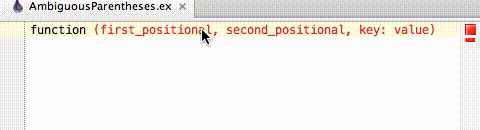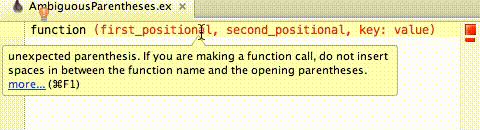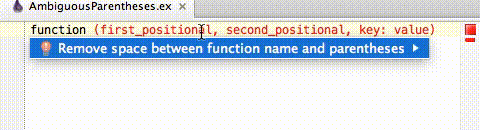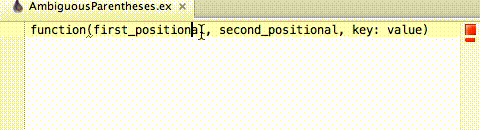
Hitting Alt+Enter on ambiguous parentheses error will bring up the Local Quick Fix, "Remove spaces between function name and parentheses". Hit Enter to accept and remove the space.
You can collapse (fold) pre-defined regions of your Elixir code to make it easier to quickly scroll through files or hide details you don't care about right now.
- Position cursor between lines with with downward facing - arrow and upward facing - arrow.
- Cmd+-
- Position cursor on the collapsed line with the square +
- Cmd++
| Expanded | Collapsed | Folded By Default? |
|---|---|---|
do end |
do: ... |
No |
-> and right operand |
-> ... |
No |
@doc VALUE |
@doc "..." |
No |
@moduledoc VALUE |
@moduledoc "..." |
No |
@typedoc VALUE |
@typedoc "..." |
No |
| alias ALIAS1 alias ALIAS1 |
alias ... |
Yes |
| import ALIAS1 import ALIAS2 |
import ... |
Yes |
| require ALIAS1 require ALIAS2 |
require ... |
Yes |
| use ALIAS1 use ALIAS2 |
use ALIAS1 |
Yes |
@for |
FOR in defimpl PROTOCOL, for: FOR
|
Yes |
@protocol |
PROTOCOL in defimpl PROTOCOL, for: FOR
|
Yes |
| @MODULE_ATTRIBUTE | VALUE in @MODULE_ATTRIBUTE VALUE
|
No |
You can comment or uncomment the current line or selected block of source. By selecting a block of source first you can quickly comment out and entire function if you're trying to track down a compiling or testing error that's not giving a helpful line number.
Using the menus
- Highlight one or more lines
- Comment (or Uncomment) with one of the following:
a. Code > Comment with Line Comment
b. On OSX the key binding is normally
Cmd+/.
When enabled, if credo is not installed as a project dependency, nothing will happen, but if it is installed, mix credo PATH will be called on any files after updates have quieted. Any credo check failures will show up as warning annotations

Individual check failures will show the explanation (from mix credo PATH:LINE(:COLUMN)) if you hover over the annotation

You can hover over the explanation and click the embedded links to jump to the line (and column) where the failure occurred.
The credo annotator is disabled by default as numerous users find running mix credo in the background has a negative impact on their system performance. If you like to try enabling the annotation, you can turn it on using the configuration.
- Preferences > Editor > Inspections > Elixir
- Check "Credo"
If you notice a degradation the in the responsiveness of the editor, it is recommended you disable the annotator again.
- Preferences > Editor > Inspections > Elixir
- Uncheck "Credo"
If you'd like to run the mix credo external annotator when it is disabled, you can run it using the inspection name.
- Analyze > Run Inspection By Name... (⌥⇧⌘I)
- Type "Credo"
- Select "Credo" from the shortened list
- Hit Enter.
You'll be presented with a "Run 'Credo'" dialog
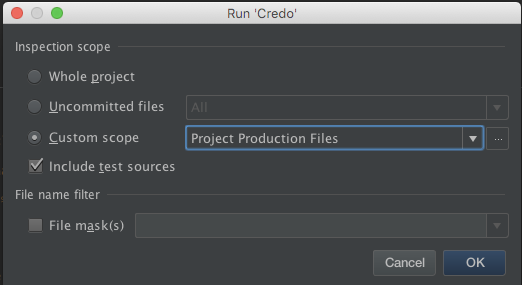
- Change the "Inspection scope" from "Whole project", which would include the
depsto "Custom scope" - Select "Project Production Files" from the "Custom scope" dropdown
- Click "OK"
The Inspections Result Tool Pane will open and show results as each file is processed.
-
Click the ▶ to expand the Credo section to show all warnings

-
Click an entry for the details of an individual warning with a code highlighting.
The view will show the parts of the file that aren't annotated as collapsed with the discontinuous line number indicating the jumps.
If you click on + collapse markers, you can expand the collapsed sections to see the full context
Or you can hover over the collapsed section to see a tooltip preview of the expansion
| Preferences > Editor > Inspections | Preferences > Editor > Inspections > Credo | Editor | Inspections | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Elixir > Credo | Include Explanation | Highlight | Message | Explanation in tooltip |
mix credo Runs
|
Highlight | Message |
mix credo Runs
|
Action | ||
| Per File | Per Issue | Working Directory | Inspect Code | Run Inspection By Name | |||||||
| ☑ | ☑ | Yes | Yes | Yes | 1 | 1 | Yes | Yes | 1 | Yes | Yes |
| ☑ | ☐ | Yes | Yes | No | 1 | 0 | Yes | Yes | 1 | Yes | Yes |
| ☐ | ⁿ/ₐ | No | No | No | 0 | 0 | Yes | Yes | 1 | No | Yes |
If you want to limit the performance impact of the credo annotator because mix credo spikes your CPU, you can limit the number of mix credo runs to 1 per open file by disabling the Explanation tooltip
- Preferences > Editor > Inspections > Credo
- Uncheck "Include Explanation"
If you don't want the annotator to run at all on open editors, then you can disable the paired inspection
- Preferences > Editor > Inspections
- Uncheck Elixir > Credo
Once the annotator is disabled, you can still run the inspection in batch mode
IntelliJ Elixir allows for graphical debugging of *.ex files using line breakpoints.
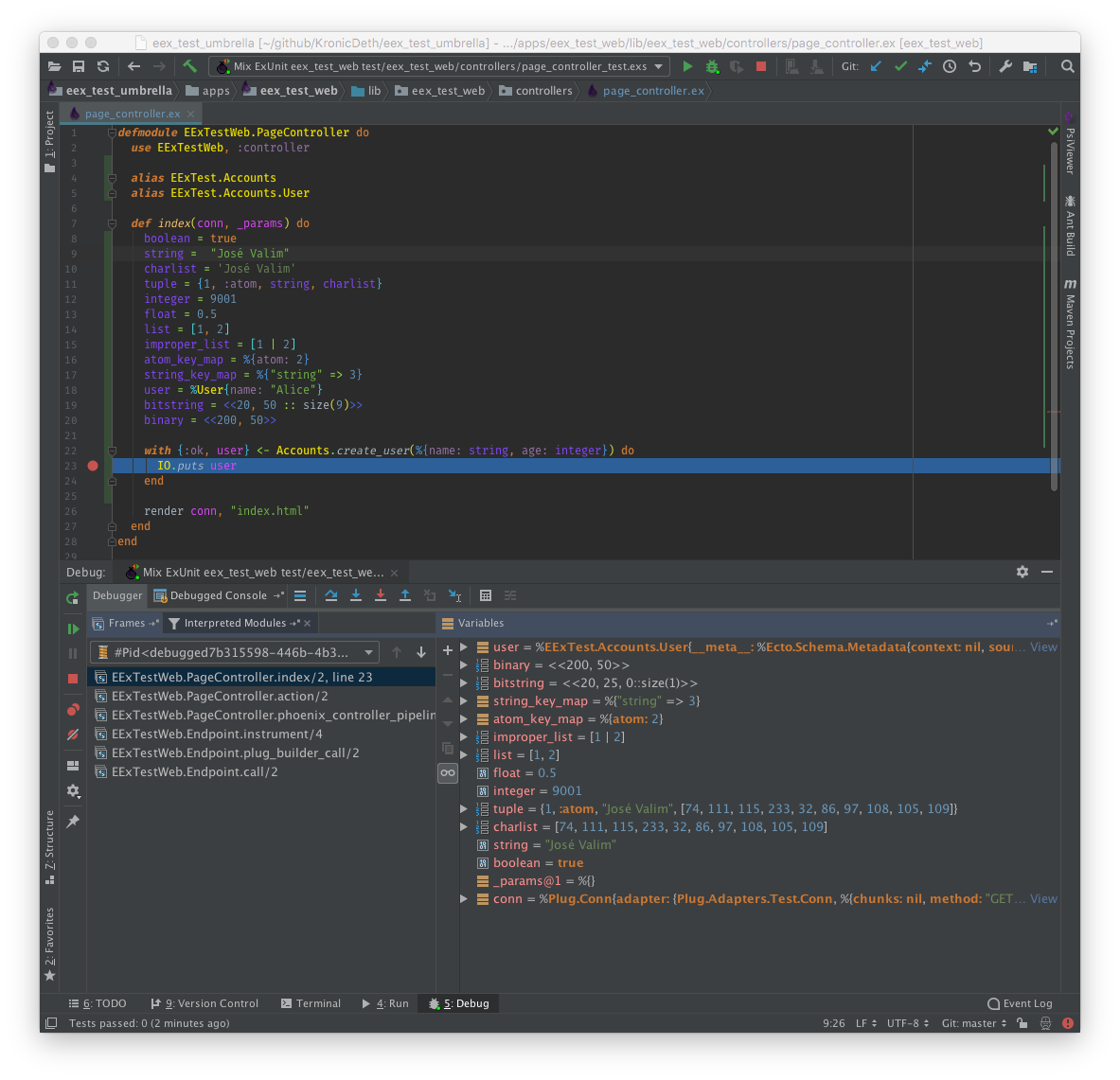
Line breakpoints can added by clicking in the left-hand gutter of an editor tab. A red dot will appear marking the breakpoint. When a Run Configuration is Run with the Debug (bug) instead of Run (arrow) button, execution will stop at the breakpoint and you can view the local variables (with Erlang names) and the stackframes.
- Define a run/debug configuration
-
Create breakpoints in the
*.exfiles - Launch a debugging session
- During the debugger session, step through the breakpoints, examine suspended program, explore frames, and evaluate code when suspended.
After you have configured a run configuration for your project, you can launch it in debug mode by pressing Ctrl+D.
| Action | Keyword Shortcut |
|---|---|
| Toggle Breakpoint | Cmd+F8 |
| Resume Program | Alt+Cmd+R |
| Step Over | F8 |
| Step Into | F7 |
| View breakpoint details/all breakpoints | Shift+Cmd+F8 |
By default, the debugger will scan all the load paths and build path for .beam files and the corresponding modules will be interpreted which causes the Module's Erlang abstract code chunk to be interpreted in Erlang instead of the bytecode chunk being executed in the C parts of the BEAM. This interpretation is much slower than execution, so by default all of the Elixir standard library and the common modules installed in Phoenix projects are excluded from being interpreted when the debugger starts. The modules can be still be stepped into or have breakpoints explicitly set.
- Preferences > Build, Execution, Deployment > Debugger > Stepping
- Scroll to Elixir
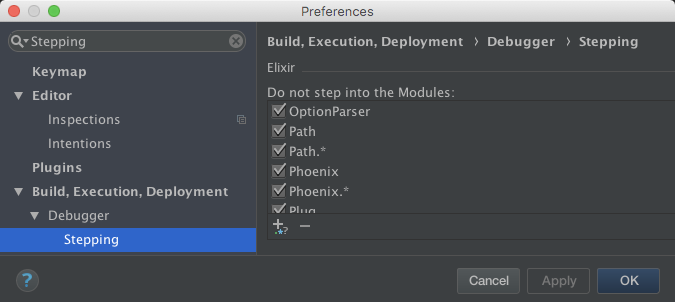
You can customize these module patterns as an application setting.
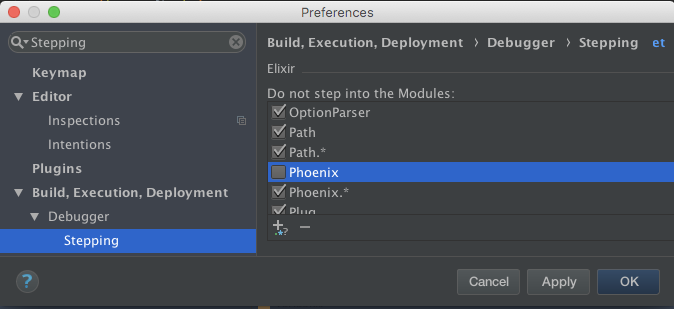
- Preferences > Build, Execution, Deployment > Debugger > Stepping
- Scroll to Elixir
- Click the Checkbox next to the pattern you want to disable
- Click Apply to save or OK to save and close Preferences
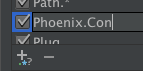
- Preferences > Build, Execution, Deployment > Debugger > Stepping
- Scroll to Elixir
- Click the pattern text box
- Click Apply to save or OK to save and close Preferences
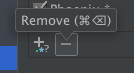
- Preferences > Build, Execution, Deployment > Debugger > Stepping
- Scroll to Elixir
- Click the row of the pattern you want to remove
- Click the "-" Remove button.
- Click Apply to save or OK to save and close Preferences
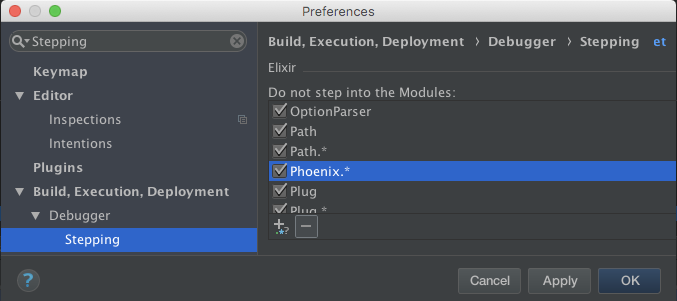
- Preferences > Build, Execution, Deployment > Debugger > Stepping
- Scroll to Elixir
- Click the "+" Add button
- Click the default "*" pattern to edit it
- Click Apply to save or OK to save and close Preferences
If you want to customize the modules to ignore on a per-Run-Configuration basis, you can set an environment variable in the Run Configuration.
| Variable | Example | Description |
|---|---|---|
| INTELLIJ_ELIXIR_DEBUG_BLACKLIST | iconv,some | Excluding modules from debugger |
Notice: If you want non Elixir. module in blacklist, write it with: :. This rule applies only to module atoms.
When a breakpoint is set, the editor displays a breakpoint icon in the gutter area to the left of the affected source code. A breakpoint icon denotes status of a breakpoint, and provides useful information about its type, location, and action.
The icons serve as convenient shortcuts for managing breakpoints. Clicking an icon removes the breakpoint. Successive use of Alt - click on an icon toggles its state between enabled and disabled. The settings of a breakpoint are shown in a tooltip when a mouse pointer hovers over a breakpoint icon in the gutter area of the editor.
| Status | Icon | Description |
|---|---|---|
| Enabled |  |
Indicates the debugger will stop at this line when the breakpoint is hit. |
| Disabled |  |
Indicates that nothing happens when the breakpoint is hit. |
| Conditionally Disabled |  |
This state is assigned to breakpoints when they depend on another breakpoint to be activated. |
When the button  is pressed in the toolbar of the Debug tool window, all the breakpoints in a project are muted, and their icons become grey:
is pressed in the toolbar of the Debug tool window, all the breakpoints in a project are muted, and their icons become grey:  .
.
To view the list of all breakpoints and their properties, do one of the following:
- Run > View Breakpoints
Shift+Cmd+F8- Click the

- Breakpoints are visible in the Favorites tool window.
To view properties of a single breakpoint
- Right-Click a breakpoint icon in the left gutter of the editor.
To configure actions, suspend policy and dependencies of a breakpoint
- Open the Breakpoint Properties
- Right-click a breakpoint in the left gutter, then click the More link or press
Shift+Cmd+F8 - Open the Breakpoints dialog box and select the breakpoint from the list
- In the Favorites tool window, select the desired breakpoint, and click the pencil icon.
- Right-click a breakpoint in the left gutter, then click the More link or press
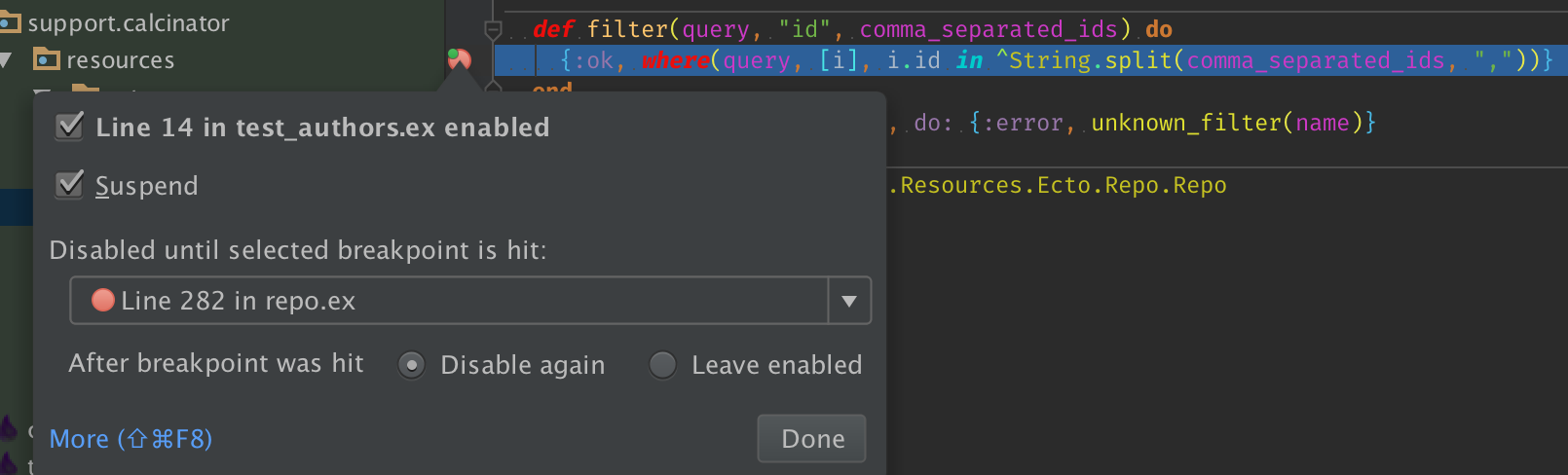
- Define the actions to be performed by IntelliJ IDEA on hitting breakpoint:
- To notify about the reaching of a breakpoint with a text message in the debugging console, check the "Log message to console" check box. A message of the format
*DBG* 'Elixir.IntellijElixir.DebugServer' got cast {breakpoint_reached, PID}will appear in the console. - To set a breakpoint the current one depends on, select it from the "Disabled until selected breakpoint hit" drop-down list. Once dependency has been set, the current breakpoint is disabled until selected one is hit.
- Choose the "Disable again" radio button to disable the current breakpoint after selected breakpoint was hit.
- Choose the "Leave enabled" radio button to keep the current breakpoint enabled after selected breakpoint was hit.
- Enable suspending an application upon reaching a breakpoint by checking the "Suspend" check box.
- To notify about the reaching of a breakpoint with a text message in the debugging console, check the "Log message to console" check box. A message of the format
A line breakpoint is a breakpoint assigned to a specific line in the source code.
Line breakpoints can be set on executable lines. Comments, declarations and empty lines are not valid locations for the line breakpoints. Line break points can be set in .ex and .eex files.
.eex line breaks will only work on Elixir code that is used in Phoenix view modules.
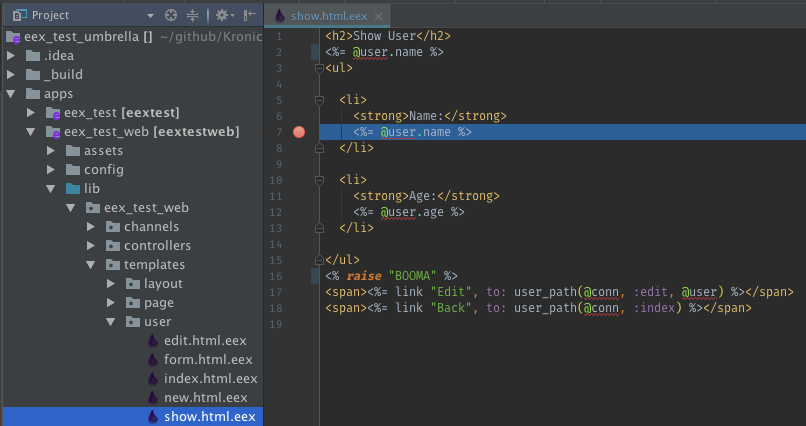
.eex breakpoints only work if a .beam file using the template's relative can be found. This means that the Phoenix view module .beam file must exist in _build prior to setting a breakpoint. Run the Run Configuration once, before debugging to complete the build if setting a breakpoint does not work.
- Place the caret on the desired line of the source code.
- Do one of the following:
- Click the left gutter area at a line where you want to toggle a breakpoint
- Run > Toggle Line Breakpoint
Cmd+F8
- Open the Breakpoints dialog
- Right-click the breakpoint you want to describe
- Select "Edit description" from the context menu
- In the "Edit Description" dialog box, type the desired description.
- Open the Breakpoints dialog
- Start typing the description of the desired breakpoint
- To view the selected breakpoint without closing the dialog box, use the preview pane.
- To open the file with the selected breakpoint for editing, double-click the desired breakpoint.
- To close Breakpoints dialog, press
Cmd+Down. The caret will be placed at the line marked with the breakpoint in question.
When you temporarily disable or enable a breakpoint, its icon changes from to and vice versa.
- Place the caret at the desired line with a breakpoint.
- Do one of the following:
- Run > Toggle Breakpoint Enable
- Right-click the desired breakpoint icon, select or deselect the enabled check box, and then click Done.
- Alt-click the breakpoint icon
Do one of the following:
- In the Breakpoints dialog box, select the desired line breakpoint, and click the red minus sign.
- In the editor, locate the line with the line breakpoint to be deleted, and click its icon in the left gutter.
- Place caret on the desired line and press
Cmd+F8.
- Select the run/debug configuration to execute
- Do one of the following
- Click
 on the toolbar
on the toolbar - Run > Debug
Ctrl+D
- Click
OR
Debug quick menu
Ctrl+Alt+D- Select the configuration from the pop-up menu
- Hit
Enter
It takes awhile, once the debugged process is started to configure the debugger in BEAM. To ensure that breakpoints are setup before allow the debugged code to run, the debugger blocks until setup is complete.
-
The debugged process will wait for the debugger to attach

-
Breakpoints will be set
-
The debugger will mark modules to be interpreted
- The code paths will be scanned for
.beamfiles- Code paths from the Elixir SDK will be skipped

-
.beamfiles will be interpreted unless they match the Module Filter Pattern
- Code paths from the Elixir SDK will be skipped
- The code paths will be scanned for
-
The debugger attaches (so it can receive breakpoint events) and allows the debugged process to continue.

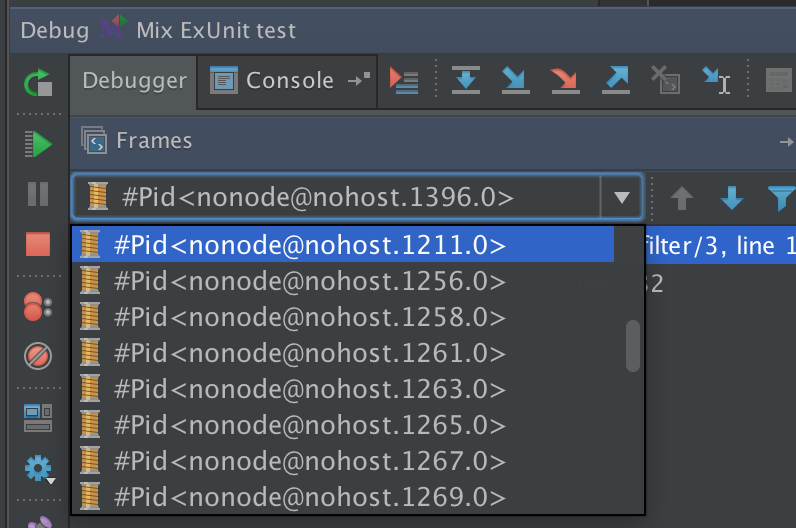
The "Thread" drop-down lists the current processes in the local node. Only the current process is suspended. The rest of the processes are still running.

The Frames for the current process can be navigated up and down using the arrow keys or clicking on the frame.
- Press
UporDownto change frames - Click the stack_frame from the list
When changing frames or jumping to definitions, you can lose track of where the debugger is paused. To get back to the current execution point, do one of the following:
- Run > Show Execution Point.
Alt+F10- Click
 on the stepping toolbar of the Debug tool window.
on the stepping toolbar of the Debug tool window.
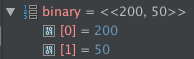
Binaries show each byte at the byte's offset.
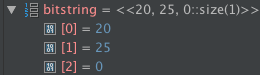
Bitstrings show each byte with any partial byte annotated with its bitwidth.

Boolean variables are rendered as their value.

Charlists show the integer values because they're treated as lists
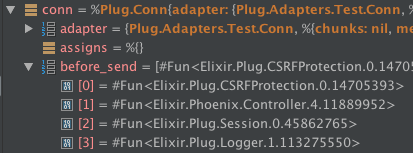
Functions don't have literal representation, so the inspect form starting with #Fun<...> is shown
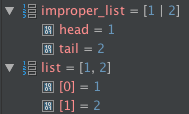
Lists render differently based on whether the list is improper or not. Improper lists show the head and tail while proper lists show their element by offset.
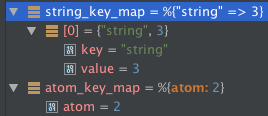
Maps render differently based on the key type. If the map uses all atom keys, the key will equal the value in the nested children while non-atom keys are shown as entries at a specific offset with the key and value. This is done, so that complex keys that have subterms can be expanded or collapsed, which is not possible for the simpler atom rendering.
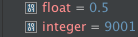
Floats and integers are rendered as literals.

Pids are broken up into their hidden node, id, and serial`.

Strings show their literal value and unicode is fully supported.

Tuples show their elements at their offsets.
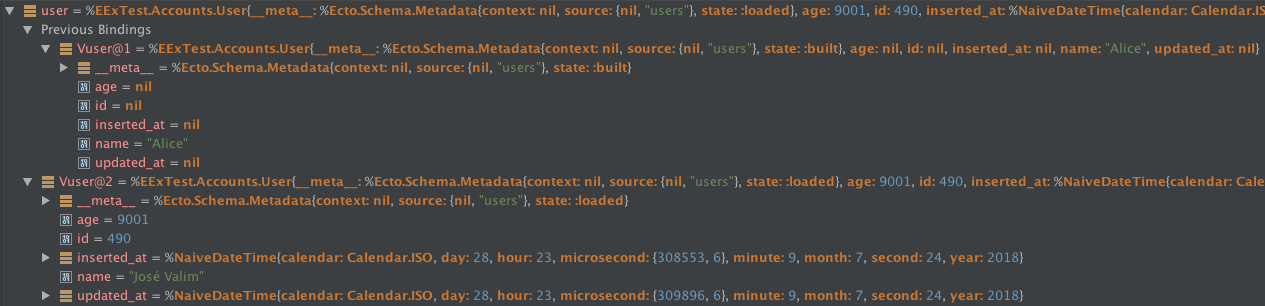
While Elixir allows rebinding variable names, Erlang does not, so when viewed in the Variables pane, rebound variables will have an @VERSION after their name indicating which rebinding of a the variable is.
When stopped at a breakpoint, you can use the Evaluate button (it looks like a simple pocket calculator) to open an editor to type code to be executed in the current stack frame.

The evaluator supports the full syntax.
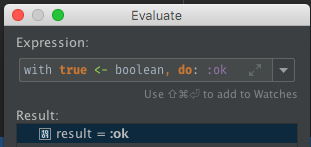
The result of evaluating the code with be shown as the value of result below the entered "Expression".
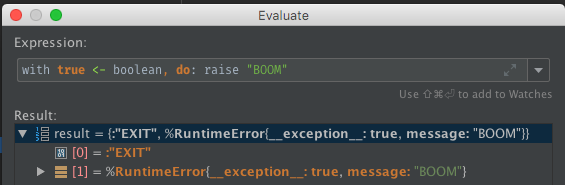
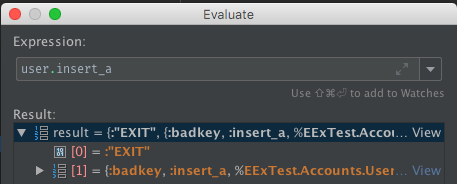
Errors in the code will report back as a result tuple with an :EXIT tag. This reflects that the error has crashed the process that was evaluating the code. Thankfully, due to how how the interpreter is written, this does not lose the current stack frame and stepping or other evaluation can continue.
| Action | Icon | Shortcut | Description |
|---|---|---|---|
| Show Execution Point | |
Alt+F10 |
Click this button to highlight the current execution point in the editor and show the corresponding stack frame in the Frames pane. |
| Step Over |  |
F8 |
Click this button to execute the program until the next line in the current function or file, skipping the function referenced at the current execution point (if any). If the current line is the last one in the function, execution steps to the line executed right after this function. |
| Step Into |  |
F7 |
Click this button to have the debugger step into the function called at the current execution point. |
| Step Out |  |
Shift+F8 |
Click this button to have the debugger step out of the current function, to the line executed right after it. |
The right-delimiter will be automatically inserted when the left delimiter is typed. In some cases, to prevent false positives, the the delimiter is only completed if when used for sigils.
| Preceded By | Left | Right |
|---|---|---|
do |
end |
|
fn |
end |
|
[ |
] |
|
{ |
} |
|
( |
) |
|
' |
' |
|
''' |
''' |
|
" |
" |
|
""" |
""" |
|
<< |
>> |
|
~<sigil-name> |
< |
> |
~<sigil-name> |
/ |
/ |
~<sigil-name> |
` | ` |
All delimiters that are auto-inserted are also matched for highlighting
| Left | Right |
|---|---|
do |
end |
fn |
end |
[ |
] |
{ |
} |
( |
) |
' |
' |
''' |
''' |
" |
" |
""" |
""" |
<< |
>> |
< |
> |
/ |
/ |
| ` | ` |
Any file with .eex as the final extension will be treated as Embedded Elixir (EEx) templates. To determine the Template Data Language, the .eex extension will be stripped and any remaining extension will be looked up to get the File Type and its associated Language. For example, *.txt.eex will be EEx with Plain Text (.txt) as the Data Template Language. Likewise, *.html.eex will be EEx with HTML as the Data Template Language. There's no need to register *.txt.eex or *.html.eex or any other *.DATA_TEMPLATE_LANGUAGE_EXTENSION.eex pattern explicitly: the nested extension will be looked up using the normal extension setup.


If you need more file-by-file configuration of the Template Data Language than can be achieved with a file extension/pattern, IntelliJ IDEA (Community or Ultimate Edition) has support for setting the Template Data Language on a specific path.
- Preferences > Languages and Frameworks > Template Data Languages
See JetBrains Documentation for more details.

- Compile project with mix (use
mix compileinstead ofelixircdirectly) - Attach docs (don't use
--no-docselixircflag) - Attach debug info (don't use
--no-debug-infoelixircflag) - Warnings as errors (use
--warnings-as-errorselixircflag) - Ignore module conflict (use
--ignore-module-conflictelixircflag)
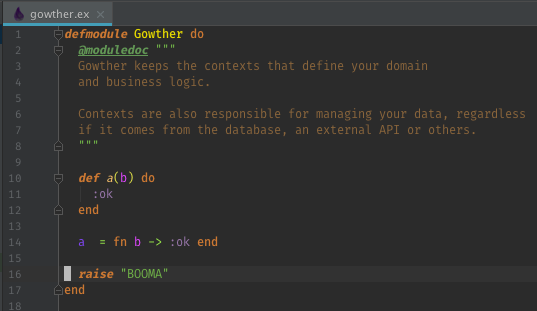
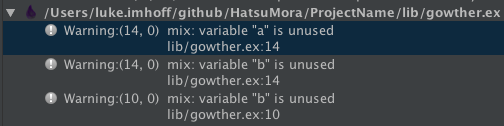
If a file has errors and warnings, they are group together in Build Messages under that file.
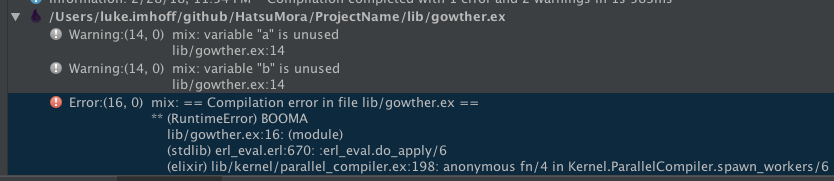
You can jump to errors and warnings in the Build Messages
-
Highlight the error or warning you want to jump to source
-
Do one of the following
-
Right-Click the error or warning
-
Select Jump to Source from the context menu

OR
- Click the error or warning
- Press Cmd+Down
-
You can also turn on Autoscroll to Source, which will Jump To Source whenever you Click or select an error or warning.

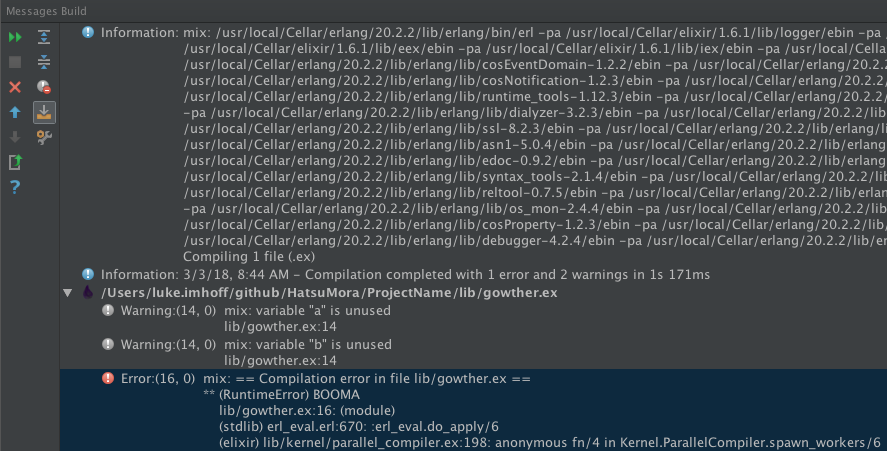
If you enable Warnings as Errors in the settings, then the Warnings will be treated as Errors by elixirc and mix and the Build Messages will show the Warnings as Errors.

If only warnings remain in the source.
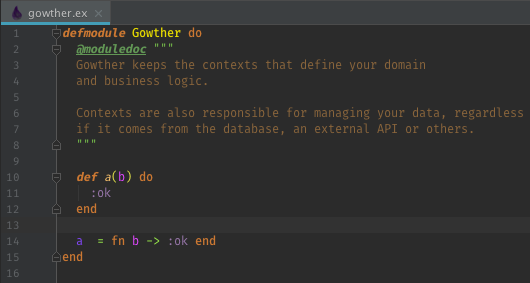
With Warnings as Errors On, all the Warnings will appear as Errors and still fail the build
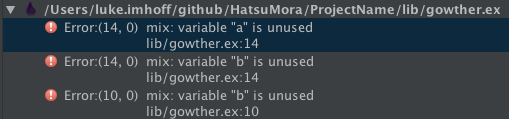
With Warnings as Errors Off, the Warnings will appear as Warnings and the build will succeed
- Have a file selected in Project view with the Project view in focus OR have an Editor tab in focus
- Build > Compile 'FILE_NAME'
- Build results will be shown
- If compilation is successful, you'll see "Compilation completed successfully" in the Event Log
- If compilation had errors, you'll see "Compilation completed with N errors and M warnings" in the Event Log and
the Messages Compile tab will open showing a list of Errors

- Build > Build Project
- Build results will be shown
- If compilation is successful, you'll see "Compilation completed successfully" in the Event Log
- If compilation had errors, you'll see "Compilation completed with N errors and M warnings" in the Event Log and
the Messages Compile tab will open showing a list of Errors
Live Templates are snippets of code that can be inserted quickly and have placeholder locations that the cursor will automatically jump to when using the template. Whenever you start typing, Live Templates will start matching against the shortcuts. A template can be selected with Tab.
Live Templates can be customized in Preferences > Editor > Live Templates > Elixir.
| Shortcut | Code |
|---|---|
@doc
|
|
case
|
|
cond
|
|
def
|
|
def,
|
|
defi
|
|
defm
|
|
defmac
|
|
defmacp
|
|
defover
|
|
defp
|
|
defpro
|
|
defs
|
|
do
|
|
doc
|
|
fn
|
|
for
|
|
if
|
|
ife
|
|
ii
|
|
mdoc
|
|
rec
|
|
test
|
|
try
|
|
Distillery's mix release produces a CLI for running the release.
-
Build the release:
mix release==> Release successfully built! You can run it in one of the following ways: Interactive: _build/ENV/rel/NAME/bin/NAME console Foreground: _build/ENV/rel/NAME/bin/NAME foreground Daemon: _build/ENV/rel/NAME/bin/NAME start
-
Run > Edit Configurations...

-
Click +
-
Select "Distillery Release CLI"
-
Fill in the "Release CLI Path" with the full path to the
_build/ENV/rel/NAME/bin/NAMEpath produed bymix releaseabove. -
Fill in the "Release CLI arguments".
-
consoleruns a shell with the release loaded similar toiex -S mix. -
foregroundto runs the release without a shell, likemixormix run. The available commands are controlled by your release configrel/config.exsthat Distillery uses.
-
-
(Optionally) fill in "
erlarguments" with arguments toerlbefore it runselixir. This is the same as theERL_OPTSenvironment variable supported by Distillery. -
(Optionally) fill in "
elixir -extraarguments" with arguments to pass toelixirbefore it run the release. This is the same as theEXTRA_OPTSenvironment variable supported by Distillery. -
(Optionally) change the Code Loading Mode This is the same as the
CODE_LOADING_MODEenvironment variable supported by Distillery.- Use Default - use whatever is configured in
rel/config.exs. Don't setCODE_LOADING_MODEenvironment variable. -
embedded- load all code immediately on boot. SetCODE_LOADING_MODE=embedded. -
interactive- load code on-demand as it is needed/referenced. SetCODE_LOADING_MODE=interactive.
- Use Default - use whatever is configured in
-
(Optionally) set the "Log Directory" This is the same as the
RUNNER_LOG_DIRenvironment variable supported by Distillery. -
(Optionally) change "Replace OS Vars" This is the same as the
REPLACE_OS_VARSenvironment variable supported by Distillery.- Use Default - use whatever is configured in
rel/config.exs. Don't setREPLACE_OS_VARSenvironment variable. -
false- don't replace "${A_VAR_NAME}" in the generated configuration withA_VARenvironment variable at runtime. SetREPLACE_OS_VARS=false. -
true- replace "${A_VAR_NAME}" in the generated configuration withA_VARenvironment variable at runtime. SetREPLACE_OS_VARS=true.
- Use Default - use whatever is configured in
-
(Optionally) set "
sys.configFile" This is the same theSYS_CONFIG_PATHenvironment variable supported by Distillery. -
(Optionally) set "Release Config Directory". This is the same as the
RELEASE_CONFIG_DIRenvironment variable supported by Distillery. -
(Optionally) set "Pipe directory". This is the same as the
PIPE_DIRenvironment variable supported by Distillery. -
(Optionally) set "Use Pseudo-terminal (PTY). If checked use PTY for interactive shells. Automatically on when "Release CLI Arguments" starts with one of the known interactive commands (
attach,console,console_boot,console_clean, orremote_console). -
Fill in the "Working directory.
- Type the absolute path to the directory.
- Select the path using directory picker by clicking the
...button
-
(Optionally) click the
...button on the "Environment variables" line to add environment variables. -
Click "OK" to save the Run Configuration and close the dialog
- Click the Run Arrow in the Toolbar to run the
_build/ENV/rel/NAME/bin/NAME - The Run pane will open
- If the either "Use Pseduo-terminal (PTY)" is checked of the "Release CLI Arguments" are known to need a PTY, an interactive shell will appear in the Run pane where you can enter
iexcommands. - Otherwise, the output of running the command will be shown.
- If the either "Use Pseduo-terminal (PTY)" is checked of the "Release CLI Arguments" are known to need a PTY, an interactive shell will appear in the Run pane where you can enter
- (Optionally) before debugging, customize the modules that will be interpreted.
- Run > Edit Configurations...
- Click the "Interpreted Modules" tab next to default "Configuration" tab.
- Enable/Disable "Inherit Application Module Filters". Will change the Module Filters show in the below "Do not interpreter modules matching patterns" list.
- Uncheck any inherited module filters that you would rather be interpreted and therefore debuggable
- Click + to add module filters that are specific to this configuration. This can be useful if you know interpreting a specific module in your project's dependencies or project leads to too much slowdown when debugging or causes the debugger to hang/crash.
- Click - to remove configuration-specific module filters added with +. Inherited module filters cannot be removed with -, they can only be disabled by unchecking.
- Add the
:debuggerapplication to your release- Open
rel/config.exs - In the
release NAMEblock, in theset :applicationsblock add:debugger:--- a/rel/config.exs +++ b/rel/config.exs @@ -41,6 +41,8 @@ end release :intellij_elixir do set version: current_version(:intellij_elixir) set applications: [ + # needed for IntelliJ Elixir debugger + :debugger, :runtime_tools ] end
- Open
- For how to use the debugger, including how to set breakpoints see the Debugger section.
- Click the Debug bug in the Toolbar to debug the
mix tests
Although it is exceedingly rare, as most Elixir projects use mix, it is supported to run/debug elixir directly, such as when doing elixir script.exs.
-
Run > Edit Configuations...
-
Click +
-
Select "Elixir"

-
Fill in the "
elixirarguments". -
(Optionally) fill in "
erlarguments" with arguments toerlbefore it runselixir. -
Fill in the "Working directory"
- Type the absolute path to the directory.
- Select the path using directory picker by clicking the
...button
- (Optionally) click the
...button on the "Environment variables" line to add environment variables. - Click "OK" to save the Run Configuration and close the dialog
With the Run Configuration defined, you can either Run or Debug elixir
-
Click the Run arrow in the Toolbar to run
elixir.
-
The Run pane will open, showing the results of
elixir.
- (Optionally) before debugging, customize the modules that will be interpreted.
- Run > Edit Configurations...
- Click the "Interpreted Modules" tab next to default "Configuration" tab.
- Enable/Disable "Inherit Application Module Filters". Will change the Module Filters show in the below "Do not interpreter modules matching patterns" list.
- Uncheck any inherited module filters that you would rather be interpreted and therefore debuggable
- Click + to add module filters that are specific to this configuration. This can be useful if you know interpreting a specific module in your project's dependencies or project leads to too much slowdown when debugging or causes the debugger to hang/crash.
- Click - to remove configuration-specific module filters added with +. Inherited module filters cannot be removed with -, they can only be disabled by unchecking.
- For how to use the debugger, including how to set breakpoints see the Debugger section.
- Click the Debug bug in the Toolbar to debug
elixir
iex run configurations allow you to run iex with IntelliJ Elixir attached. It is most useful when debugging, but it also allows you save customizations in the configuration when it is more complicated than just iex.
-
Run > Edit Configurations...
-
Click +
-
Select "IEx"

-
(Optionally) fill in "
iexarguments" with arguments toiex. -
(Optionally) full in "
erlarguments" with arguments toerlbefore it runsiex. -
Fill in the "Working directory"
- Type the absolute path to the directory.
- Select the path using directory picker by clicking the
...button
- (Optionally) click the
...button on the "Environment variables" line to add environment variables. - Click "OK" to save the Run Configuration and close the dialog
With the Run Configuration defined, you can either Run or Debug the iex configuration.
-
Click the Run arrow in the Toolbar to run
iex
- (Optionally) before debugging, customize the modules that will be interpreted.
- Run > Edit Configurations...
- Click the "Interpreted Modules" tab next to default "Configuration" tab.
- Enable/Disable "Inherit Application Module Filters". Will change the Module Filters show in the below "Do not interpreter modules matching patterns" list.
- Uncheck any inherited module filters that you would rather be interpreted and therefore debuggable
- Click + to add module filters that are specific to this configuration. This can be useful if you know interpreting a specific module in your project's dependencies or project leads to too much slowdown when debugging or causes the debugger to hang/crash.
- Click - to remove configuration-specific module filters added with +. Inherited module filters cannot be removed with -, they can only be disabled by unchecking.
- For how to use the debugger, including how to set breakpoints see the Debugger section.
- Click the Debug bug in the Toolbar to debug
iex.
Much like rake tasks in Rubymine, this plugin can run mix tasks.
-
Run > Edit Configurations...
-
Click +
-
Select "Elixir Mix"

-
Fill in the "
mixarguments" starting with the name of themixtask followed by any arguments to that task. -
(Optionally) fill in "
elixirarguments" with arguments toelixirbefore it runsmix. -
(Optionally) fill in "
erlarguments" with arguments toerlbefore it runselixir. -
Fill in the "Working directory"
- Type the absolute path to the directory.
- Select the path using directory picker by clicking the
...button
- (Optionally) click the
...button on the "Environment variables" line to add environment variables. - Click "OK" to save the Run Configuration and close the dialog
With the Run Configuration defined, you can either Run or Debug the Mix Task
-
Click the Run arrow in the Toolbar to run the
mixtask
-
The Run pane will open, showing the results of the
mixtask.-
If there is an error with a FILE:LINE stack stack_frame, it will be a clickable link that will take you to that location

-
- (Optionally) before debugging, customize the modules that will be interpreted.
- Run > Edit Configurations...
- Click the "Interpreted Modules" tab next to default "Configuration" tab.
- Enable/Disable "Inherit Application Module Filters". Will change the Module Filters show in the below "Do not interpreter modules matching patterns" list.
- Uncheck any inherited module filters that you would rather be interpreted and therefore debuggable
- Click + to add module filters that are specific to this configuration. This can be useful if you know interpreting a specific module in your project's dependencies or project leads to too much slowdown when debugging or causes the debugger to hang/crash.
- Click - to remove configuration-specific module filters added with +. Inherited module filters cannot be removed with -, they can only be disabled by unchecking.
- For how to use the debugger, including how to set breakpoints see the Debugger section.
- Click the Debug bug in the Toolbar to debug the
mixtask
If you want to run iex in the context of the project, you need to run iex -S mix, but if you don't want to have to worry about forgetting whether it's -s or -S or if it is mix -S iex or iex -S mix, you can use an IEx Mix configuration.
-
Run > Edit Configurations...
-
Click +
-
Select "IEx Mix"
-
(Optionally) fill in "
mixarguments", such asphx.serverif you want to launch Phoenix inside ofiex. -
(Optionally) fill in "
iexarguments" with arguments toiexbefore-S mix. -
(Optionally) full in "
erlarguments" with arguments toerlbefore it runsiex. -
Fill in the "Working directory"
- Type the absolute path to the directory.
- Select the path using directory picker by clicking the
...button
- (Optionally) click the
...button on the "Environment variables" line to add environment variables. - Click "OK" to save the Run Configuration and close the dialog
Wih the Run Configuration defined, you can either Run or Debug iex -S mix
- Click the Run Arrow in the Toolbar to run
iex -S mix
- (Optionally) before debugging, customize the modules that will be interpreted.
- Run > Edit Configurations...
- Click the "Interpreted Modules" tab next to default "Configuration" tab.
- Enable/Disable "Inherit Application Module Filters". Will change the Module Filters show in the below "Do not interpreter modules matching patterns" list.
- Uncheck any inherited module filters that you would rather be interpreted and therefore debuggable
- Click + to add module filters that are specific to this configuration. This can be useful if you know interpreting a specific module in your project's dependencies or project leads to too much slowdown when debugging or causes the debugger to hang/crash.
- Click - to remove configuration-specific module filters added with +. Inherited module filters cannot be removed with -, they can only be disabled by unchecking.
- For how to use the debugger, including how to set breakpoints see the Debugger section.
- Click the Debug bug in the Toolbar to debug
iex -S mix.
The mix espec task gets a special type of Run Configuration, Elixir Mix Espec. Using this Run Configuration type instead, of the basic Elixir Mix Run Configuration will cause the IDE to attach a special formatter to mix espec, so that you get the standard graphical tree of Test Results.
The Run pane will show Test Results. If there is a compilation error before or during mix espec, it will be shown as a test failure. If the compilation failure is in a _spec.exs file can it can be inferred from the stacktrace, the compilation error will show up as a test failure in that specific module.
If you override the default formatters you will need to add the following code to your spec_helper.exs.
If you override formatters similar to below
ESpec.configure fn(config) ->
config.formatters ...
ESpec.configure fn(config) ->
config.formatters [
{ESpec.Formatters.Json, %{out_path: "results.json"}},
{ESpec.Formatters.Html, %{out_path: "results.html"}},
{ESpec.Formatters.Doc, %{details: true, out_path: "results.txt"}},
{ESpec.Formatters.Doc, %{details: true, diff_enabled?: false, out_path: "results-no-diff.txt"}},
{ESpec.CustomFormatter, %{a: 1, b: 2}},
]
endReplace them with code that checks for the graphical formatter TeamCityESpecFormatter and uses only it when available.
ESpec.configure fn(config) ->
config.formatters(if Code.ensure_loaded?(TeamCityESpecFormatter) do
[{TeamCityESpecFormatter, %{}}]
else
...
end)
endESpec.configure fn(config) ->
config.formatters(if Code.ensure_loaded?(TeamCityESpecFormatter) do
[{TeamCityESpecFormatter, %{}}]
else
[
{ESpec.Formatters.Json, %{out_path: "results.json"}},
{ESpec.Formatters.Html, %{out_path: "results.html"}},
{ESpec.Formatters.Doc, %{details: true, out_path: "results.txt"}},
{ESpec.Formatters.Doc, %{details: true, diff_enabled?: false, out_path: "results-no-diff.txt"}},
{ESpec.CustomFormatter, %{a: 1, b: 2}},
]
end)
end-
Run > Edit Configurations...
-
Click +
-
Select "Elixir Mix ESpec"

-
Fill in the "
mix especarguments" with the argument(s) to pass tomix espec. Normally, this will be list of*_spec.exsfiles, relative to the "Working directory".NOTE: Unlike
mix test,mix especdoes not support directories as arguments. -
(Optionally) fill in "
elixirarguments" with the arguments toelixirbefore it runsmix test. -
(Optionally) fill in "
erlarguments"with the arguments toerlbefore it runselixir`. -
Fill in the "Working directory"
- Type the absolute path to the directory.
- Select the path using directory picker by clicking the
...button
-
(Optionally) click the
...button on the "Environment variables" line to add environment variables. -
Click "OK" to save the Run Configuration and close the dialog
With the Run Configuration defined you can either Run or Debug the mix especs
- Click the Run arrow in the Toolbar to run the
mix testtask - The Run pane will open showing the Test Results

- (Optionally) before debugging, customize the modules that will be interpreted.
- Run > Edit Configurations...
- Click the "Interpreted Modules" tab next to default "Configuration" tab.
- Enable/Disable "Inherit Application Module Filters". Will change the Module Filters show in the below "Do not interpreter modules matching patterns" list.
- Uncheck any inherited module filters that you would rather be interpreted and therefore debuggable
- Click + to add module filters that are specific to this configuration. This can be useful if you know interpreting a specific module in your project's dependencies or project leads to too much slowdown when debugging or causes the debugger to hang/crash.
- Click - to remove configuration-specific module filters added with +. Inherited module filters cannot be removed with -, they can only be disabled by unchecking.
- For how to use the debugger, including how to set breakpoints see the Debugger section.
- Click the Debug bug in the Toolbar to debug the
mix tests
While you can create Elixir Mix ESpec run configurations manually using the Run > Edit Configurations... menu, it is probably more convenient to use the context menu.
The context menu must know that the the directory, file, or line you are right-clicking is a test. It does this by checking if the current directory or an ancestor is marked as a Test Sources Root and contains or is a *_spec.exs file(s)
- In the Project pane, ensure your OTP application's
especdirectory is marked as a Test Sources Root - Check if the
especdirectory is green. If it is, it is likely a Test Sources Root. This color may differ in different themes, so to be sure you can check the context menu - Right-click the
testdirectory. - Hover over "Mark Directory As >"
-
If "Unmark as Test Sources Root" is shown, then the directory is already configured correctly, and create from context will work.

-
If "Test Sources Root" is shown, then the directory need to be configured by clicking that entry

-
-
Right-click the directory in the Project pane
-
Click "Run Mix ExUnit", which will both create the Run Configuration and Run it.

- If you want to only create the Run Configuration, select "Create Mix ESpec" instead
Alternatively, you can use keyboard shortcuts
- Select the directory in the Project pane.
-
Ctrl+Shift+Rwill create the Run Configuration and Run it.
- Right-click the file in the Project pane
- Click "Run Mix ESpec", which will both create the Run Configuration and Run it.
- If you want to only create the Run Configuration, select "Create Mix ESpec" instead
Alternatively, you can use keyboard shortcuts
- Select the directory in the Project pane.
-
Ctrl+Shift+Rwill create the Run Configuration and Run it.
Finally, you can use the editor tabs
-
Right-click the editor tab for the test file you want to run

-
Click "Run Mix ESpec", which will both create the Run Configuration and Run it.
- If you want to only create the Run Configuration, select "Create Mix ESpec" instead
If you want to be able to run a single test, you can create a Run Configuration for a line in that test
-
Right-click a line in the test file

-
Click "Run Mix ESpec", which will both create the Run Configuration and Run it.
- If you want to only create the Run Configuration, select "Create Mix ESpec" instead
Alternatively, you can use keyboard shortcuts
- Place the cursor on the line you want to test
-
Ctrl+Shift+Rwill create the Run Configuration and Run it.
The mix test task gets a special type of Run Configuration, Elixir Mix ExUnit. Using this Run Configuration type instead, of the basic Elixir Mix Run Configuration will cause the IDE to attach a special formatter to mix test, so that you get the standard graphical tree of Test Results
The Run pane will show Test Results. If there is a compilation error before or during mix test, it will be shown as a test failure. If the compilation failure is in a _test.exs file can it can be inferred from the stacktrace, the compilation error will show up as a test failure in that specific module.
doctest names are rearranged to emphasize the function being tested: "test doc at MODULE.FUNCTION/ARITY (COUNT)" becomes "MODULE.FUNCTION/ARITY doc (COUNT)". If MODULE is the same as the test case without the Test suffix, then MODULE is stripped too and the test name becomes only FUNCTION/ARITY doc (COUNT).
-
Run > Edit Configurations...
-
Click +
-
Select "Elixir Mix ExUnit"

-
Fill in the "
mix testarguments" with the argument(s) to pass tomix test. Normally, this will be a directory liketest, relative to the "Working directory" -
(Optionally) fill in "
elixirarguments" with the arguments toelixirbefore it runsmix test. -
(Optionally) fill in "
erlarguments"with the arguments toerlbefore it runselixir`. -
Fill in the "Working directory"
- Type the absolute path to the directory.
- Select the path using directory picker by clicking the
...button
-
(Optionally) click the
...button on the "Environment variables" line to add environment variables. -
Click "OK" to save the Run Configuration and close the dialog
With the Run Configuration defined you can either Run or Debug the mix tests
- Click the Run arrow in the Toolbar to run the
mix testtask - The Run pane will open showing the Test Results

- (Optionally) before debugging, customize the modules that will be interpreted.
- Run > Edit Configurations...
- Click the "Interpreted Modules" tab next to default "Configuration" tab.
- Enable/Disable "Inherit Application Module Filters". Will change the Module Filters show in the below "Do not interpreter modules matching patterns" list.
- Uncheck any inherited module filters that you would rather be interpreted and therefore debuggable
- Click + to add module filters that are specific to this configuration. This can be useful if you know interpreting a specific module in your project's dependencies or project leads to too much slowdown when debugging or causes the debugger to hang/crash.
- Click - to remove configuration-specific module filters added with +. Inherited module filters cannot be removed with -, they can only be disabled by unchecking.
- For how to use the debugger, including how to set breakpoints see the Debugger section.
- Click the Debug bug in the Toolbar to debug the
mix tests
While you can create Elixir Mix ExUnit run configurations manually using the Run > Edit Configurations... menu, it is probably more convenient to use the context menu.
The context menu must know that the the directory, file, or line you are right-clicking is a test. It does this by checking if the current directory or an ancestor is marked as a Test Sources Root.
- In the Project pane, ensure your OTP application's
testdirectory is marked as a Test Sources Root - Check if the
testdirectory is green. If it is, it is likely a Test Sources Root. This color may differ in different themes, so to be sure you can check the context menu - Right-click the
testdirectory. - Hover over "Mark Directory As >"
-
If "Unmark as Test Sources Root" is shown, then the directory is already configured correctly, and create from context will work.

-
If "Test Sources Root" is shown, then the directory need to be configured by clicking that entry

-
-
Right-click the directory in the Project pane
-
Click "Run Mix ExUnit", which will both create the Run Configuration and Run it.

- If you want to only create the Run Configuration, select "Create Mix ExUnit" instead
Alternatively, you can use keyboard shortcuts
- Select the directory in the Project pane.
-
Ctrl+Shift+Rwill create the Run Configuration and Run it.
- Right-click the file in the Project pane
- Click "Run Mix ExUnit", which will both create the Run Configuration and Run it.
- If you want to only create the Run Configuration, select "Create Mix ExUnit" instead
Alternatively, you can use keyboard shortcuts
- Select the directory in the Project pane.
-
Ctrl+Shift+Rwill create the Run Configuration and Run it.
Finally, you can use the editor tabs
-
Right-click the editor tab for the test file you want to run

-
Click "Run Mix ExUnit", which will both create the Run Configuration and Run it.
- If you want to only create the Run Configuration, select "Create Mix ExUnit" instead
If you want to be able to run a single test, you can create a Run Configuration for a line in that test
-
Right-click a line in the test file

-
Click "Run Mix ExUnit", which will both create the Run Configuration and Run it.
- If you want to only create the Run Configuration, select "Create Mix ExUnit" instead
Alternatively, you can use keyboard shortcuts
- Place the cursor on the line you want to test
-
Ctrl+Shift+Rwill create the Run Configuration and Run it.
.beam files are the compiled version of modules on the BEAM virtual machine used by Elixir and Erlang. They are the equivalent of .class files in Java.
.beam files are not detected purely by their file extension: the BEAM file format starts with a magic number, FOR1, that is checked for before decompiling.
.beam files have 2 editors registered: decompiled Text and BEAM Chunks

If the .beam module was compiled with the compressed compiler directive, which in Erlang looks like
-compile([compressed])and in Elixir looks like
@compile [:compressed]then the outer file format is GZip (which is detected by checking for the gzip magic number, 1f 8b, at the start of the file) and the .beam will be (stream) decompressed before the .beam header is checked and the chunks decoded.
.beam files are composed of binary chunks. Each chunk is formatted
| Offset | +0 | +1 | +2 | +3 |
|---|---|---|---|---|
| 0 | Name (ASCII Characters) | |||
| 4 | Length (`unsigned-big-integer`) | |||
| 8+ | Chunk-Specific | |||
This format is generically referred to as Type-Length-Value
The BEAM Chunks editor tab is subdivided into further tabs, one for each chunk in the .beam file.

The tabs are listed in the order that the chunks occur in the .beam file.
The Atom chunk holds LATIN-1 encoded atoms while AtU8 chunk holds UTF-8 atoms. There will only be one of these atom-related chunks in any given .beam file. AtU8 is used in newer versions of OTP that support UTF-8 atoms. AtU8 was introduced in OTP 20.
| Offset | +0 | +1 | +2 | +3 |
|---|---|---|---|---|
| 0 | atom count (`unsigned-big-integer`) | |||
| 4 | length1 (`unsigned-byte`) | bytes (for length1) | ||
| 4+length1+...+lengthn-1 | lengthn (`unsigned-byte`) | bytes (for lengthn) | ||
The Atom/AtU8 tab shows a table with the columns
| Column | Description | Source |
|---|---|---|
| Index | 1-based to match Erlang convention. In the Code chunk, atom(0) is reserved to always translate to nil
|
Derived |
| Byte Count | The byte count for the atom's bytes | Raw |
| Characters | From encoding the bytes as LATIN-1 for Atom chunk or UTF-8 for AtU8 chunk |
Derived |

The Attr chunk holds the module attributes, but only those that are persisted. Erlang module attributes are persisted by default, but in Elixir module attributes need to be marked as persisted with Module.register_attribute/3
The Attr chunk uses External Term Format (term_to_binary's output) to encode a proplist, which is similar to, but not quite the same an Elixir Keyword list
All modules will have a :vsn attribute that is either set explicitly or defaults to the MD5 of the module.
The Attr tab shows a table with the columns
| Column | Description | Source |
|---|---|---|
| Key | Attribute name | Raw |
| Value | Attribute value. Note: The value always appears as a list as read from the binary format. I don't know why. | Raw |
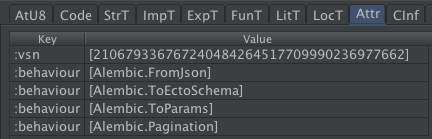
The CInf chunk is the Compilation Information for the Erlang or Erlang Core compiler. Even Elixir modules have it because Elixir code passes through this part of the Erlang Core compiler
The CInf chunk uses External Term Format (term_to_binary's output) to encode a proplist, which is similar to, but not quite the same an Elixir Keyword list
The CInf tab shows a table with the columns
| Column | Description | Source |
|---|---|---|
| Key | Option name | Raw |
| Value | Inspected value | Raw |

The Code chunk contains the byte code for the module.
It is encoded in BEAM Compact Term Encoding, which differs from the binary format produced by term_to_binary.
The Code tab shows a read-only editor with one byte code operation on each line. For ease of reading, operations are grouped by function and then label block with indentation indicating scope.
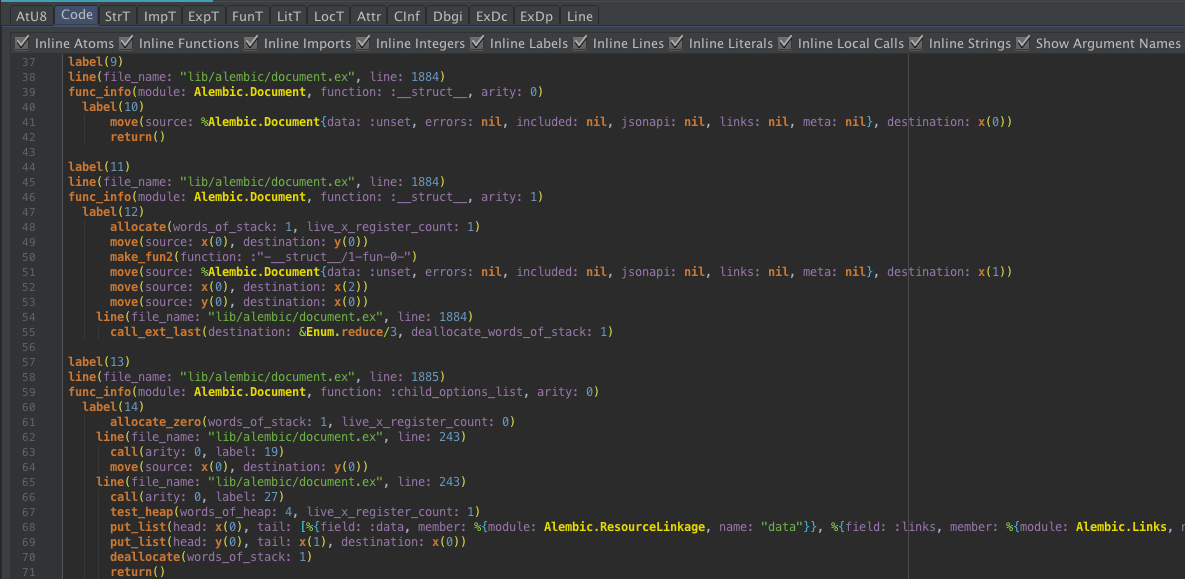
By default as many references to other chunks and references to other parts of Code chunk are inlined to ease understanding. If you want to see the raw byte code operations, you can turn off the various inliners.
####### Controls
| Control | On | Off |
|---|---|---|
| Inline Atoms |
atom(0) is inlined as nil
|
atom(N) if "Inline Integers" is Off
|
atom(n) looks up index `n` in `Atom`/`AtU8` chunk and inlines its `inspect`ed version
|
N if "Inline Integers" is On and the argument supports "Inline Integers"
|
|
| Inline Functions |
literal(n) looks up index n in FunT chunk and inlines the name if the argument supports "Inline Functions"
|
literal(n) if "Inline Integers" is Off
|
n if "Inline Integers" is On and the argument supports "Inline Integers"
|
||
| Inline Imports |
literal(n) looks up index n in ImpT and inlines it as a function reference: &module.name/arity if argument supports "Inline Functions"
|
literal(n) if "Inline Integers" Is Off
|
n if "Inline Integers" is On and the argument supports "Inline Integers"
|
||
| Inline Integers |
atom(n) and literal(n) inline as n if argument supports "Inline Integers" |
atom(n), integer(n), and literal(n)
|
integer(n) inlines as n
|
||
| Inline Labels |
label(n) inlines as n if argument supports "Inline Labels" |
label(n) |
| Inline Lines |
line(literal(n)) looks up index `n` in the "Line Reference" table in the `Lines` chunk. The Line Reference contains a file name index and line. The file name index is looked up in the "File Name" table in the `Lines` chunk. The line from the Line Reference and the File name from the "File Name" table are inlined as `line(file_name: file_name, line: line)`. |
line operations are left as is |
| Inline Literals |
literal(n) looks up index n in LitT chunk and inlines its `inspect`ed version if the argument supports "Inline Literals" |
literal(n) |
| Inline Local Calls |
label(n) finds label(n) in Code chunk, then searches back for the previous func_info operation, then inlines it as a function reference: &module.name/arity if argument supports "Inline Local Calls" |
label(n) |
| Inline Strings | Looks up bit_length
|
bit_length |
| Show Argument Names | Adds keyword argument names before each argument value | Leaves values as positional arguments |
If any of the inliners are incorrect or you have an argument name that makes more sense, please open an issue.
The Dbgi chunk contains Debug Info. It was introduced in OTP 20 as a replacement for the Abst chunk. While the Abst chunk was required to contain the Erlang AST, the Dbgi format can contain the debug info for other languages, such as Elixir quoted form AST.
Because the format is language neutral, the format is a set of nested, versioned formats. The outer most layer is
{:debug_info_v1, backend, metadata | :none}For :debug_info_v1, Elixir's backend is :elixir_erl. The metadata for :elixir_erl is further versioned: {:elixir_v1, map, specs}.
map contains the bulk of the data.
| Key | Value |
|---|---|
:attributes |
Attributes similar to the Attr chunk, but at the Elixir, instead of Core Erlang level. Usually they match with the exception that attributes doesn't contain vsn when Attr contains the MD5 version |
:compile_opts |
Compilation options similar to CInf chunk's options key, but at for Elixir, instead of Core Erlang level. |
:definitions |
The Elixir quoted AST for reach function clause. |
:file |
The name of the file the module was generated from. |
:line |
The line in :file where the module was defined, such as the line defmodule occurred. |
:module |
The name of the module as an atom
|
:unreachable |
Unreachable functions |
The Dbgi tab appearance varies based on whether it was created with Erlang or Elixir, reflecting the fact that the Dbgi format is dependent on the backend that wrote it.
####### Elixir (:elixir_erl backend)
The Dbgi tab show the single value map entries: :file, :line, and :module.

For the multi-value keys: :attributes, :compile_opts, and :definitions, there are individual tabs.

######## Attributes
The Attributes tab has the same format as the Attrs chunk.
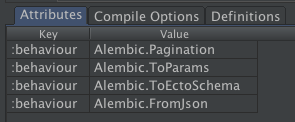
######## Compile Options
The Compile Options tab is usually empty, much like the CInf options key for Erlang.
######## Definitions
The Definitions tab is split between a tree of Module, Function/Arity and clauses.
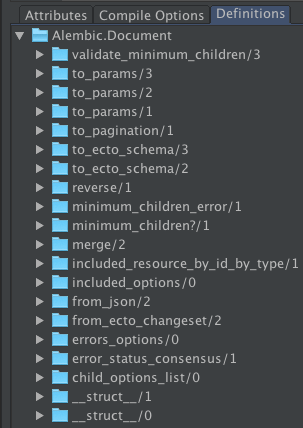
Clicking on a clause will show only that clause, but clicking on a higher level in the tree will show all clauses in the function or the entire Module.


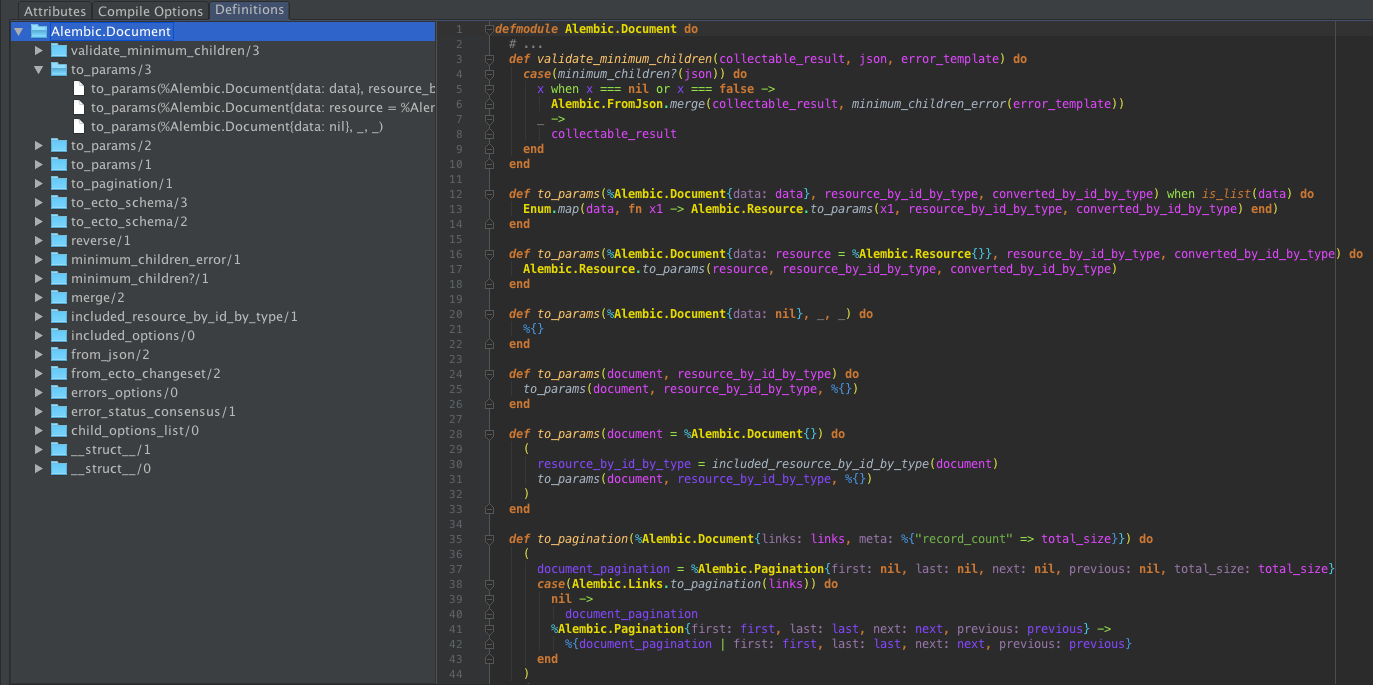
The AST stored in the definitions tab and the process of converting it back to code is not format preserves, so it will not look precisely like the source code as the AST has undergone some macro expansion before its put in the Dbgi chunk. As common idioms are understood, reversals will be add to the renderer.
######## Type Specifications
The Type Specifications tab is split between a tree of the Module, Module Attribute, and type specifications.
Clicking on a type specification will show only that type specification, but clicking on a higher in the tree will show all type specifications for the same module attribute or the entire Module.
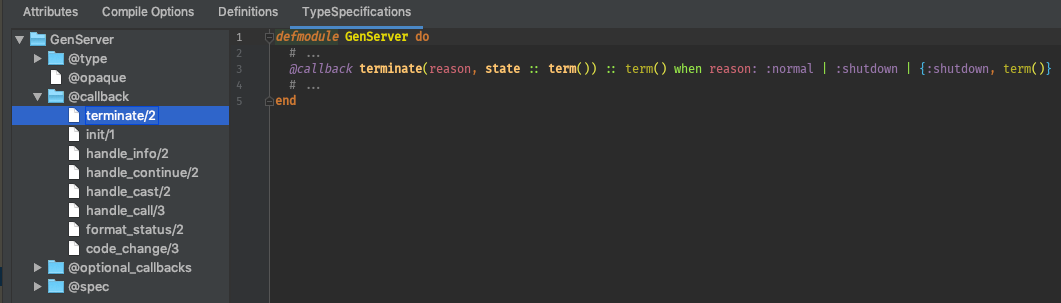

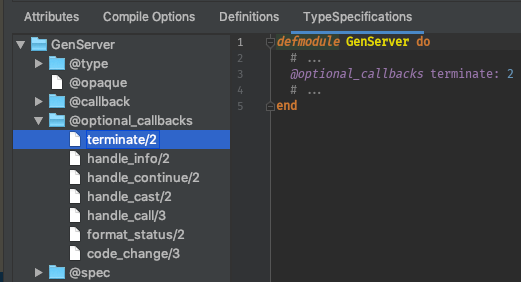
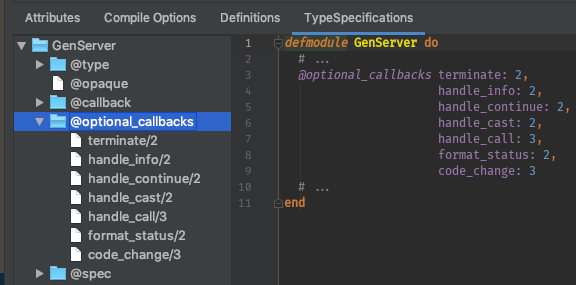

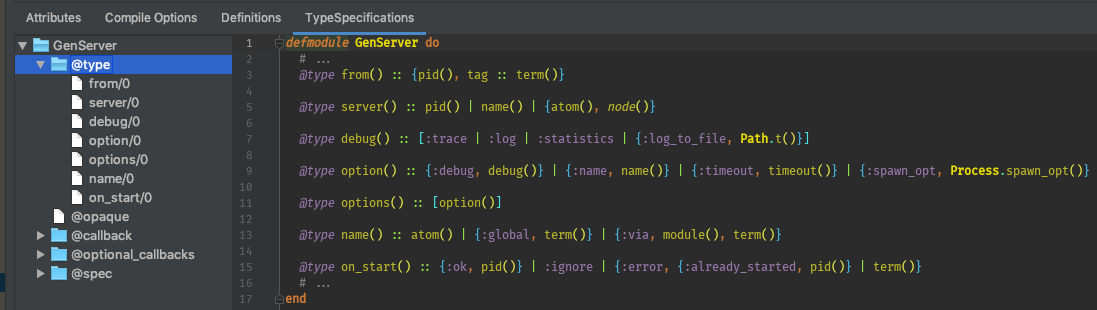

####### Erlang (:erlang_abstract_code backend)
The Dbgi tab has Abstract Code and Compile Options tabs.

######## Abstract Code
The Abstract Code tab is split between a tree of Attributes, Functions, Function/Arity, and clauses.
Clicking on a clause will show only that clause, but clicking on a higher level in the tree will show all clauses in the function or the entire Module.

The abstract code stored in the :erlang_abstract_code backend format is the Erlang Abstract Format. Instead of converting the Erlang Abstract Format back to Erlang, which would require IntelliJ Erlang to highlight and annotate and for you to be used to reading Erlang, the Erlang Abstract Format is translated back to Elixir. Using the BEAM Chunk Dbgi viewer can be a way to convert compiled Erlang code to Elixir source automatically.
The ExDc chunk stores ExDoc. Not the rendered HTML from the ex_doc package, but the the @doc, @moduledoc, and @typedoc attribute values that work even without ex_doc installed. This chunk is what is consulted when the h helper is used in iex.
The ExDc chunk is the encoded with term_to_binary. The term format is a versioned as {version, versioned_format}. The current version tag is :elixir_docs_v1 and the versioned_format is a Keyword.t with keys matching the Code.get_docs/2 tags :callback_docs, :docs, :moduledoc, and :type_docs keys.
Like Dbgi, the ExDc tab is split between a tree to navigate and an editor to show the decompiled value.
Click on a node in the tree will show all docs at that level and any descendants.
| Node | Description |
|---|---|
| Root | All docs |
| Module | @moduledoc |
| Types | All @typedocs |
| Types child | A specific @typedoc
|
| Callbacks | All @callback @docs |
| Callbacks child | A specific @callback's @doc
|
| Functions/Macros | All @docs for functions/macros |
| Functions/Macros child | A specific function/macro's @doc
|
The ExpT chunk is the Export Table. The name "Export" derives from the Erlang module attribute -export, which is used to "export" functions from a module. It is the equivalent of making a function or macro public with def and defmacro as opposed to making it private with defp and defmacrop in Elixir.
The BEAM format and the ExpT chunk, being made for Erlang, has no concept of macros. It only understands functions, so Elixir macros, like __using__/1 called by use are compiled to plain Erlang functions with MACRO- prefixed to their name and an extra argument (the __CALLER__ environment) as the first argument, which increases the arity, yielding a full MFA of MACRO-__using__/2 as seen above.
The ExpT tab shows a table with the columns
| Column | Description | Source |
|---|---|---|
| Atom Index | Index into the Atom or AtU8 chunk for the function's name |
Raw |
| Name | The atom referenced by "Atom Index" | Derived |
| Arity | The arity (argument count) of the function | Raw |
| Label | Label index in the Code chunk where the function is defined. This label is usually immediately after the func_info operation and before the first pattern match or guard operation. |
Raw |
The ImpT chunk is the Import Table. It DOES NOT encode just the Erlang -import attributes or Elixir import macro calls: it tracks any external function or macro called from another module. call_ext_* operations in the Code chunk don't store the Module and Function (MF) of the function they will call directly in the bytecode, instead, one of the arguments is an index into the ImpT chunk. This way, all external calls are normalized into the ImpT chunk instead of being denormalized to the call site. The arity still appears at the call site to help with checking the argument count.
You may notice that erlang.byte_size/1 is included in the table. This is because even BIFs are referenced by MFA and not a pre-assigned number as would be the case for system calls in operating systems like Linux. BEAM is like an Operation System, but not in all ways.
The ImpT tab shows a table with the columns
| Column | Description | Source |
|---|---|---|
| Index | 0-based index used by references in the Code chunk. |
Derived |
| Module Atom Index | Index into the Atom or AtU8 chunk for the Module's name |
Raw |
| Module Atom | The atom referenced by "Module Atom Index". | Derived |
| Function Atom Index | Index into the Atom or AtU8 chunk for the functon's name |
Raw |
| Function Atom | The atom referened by "Function Atom Index". | Derived |
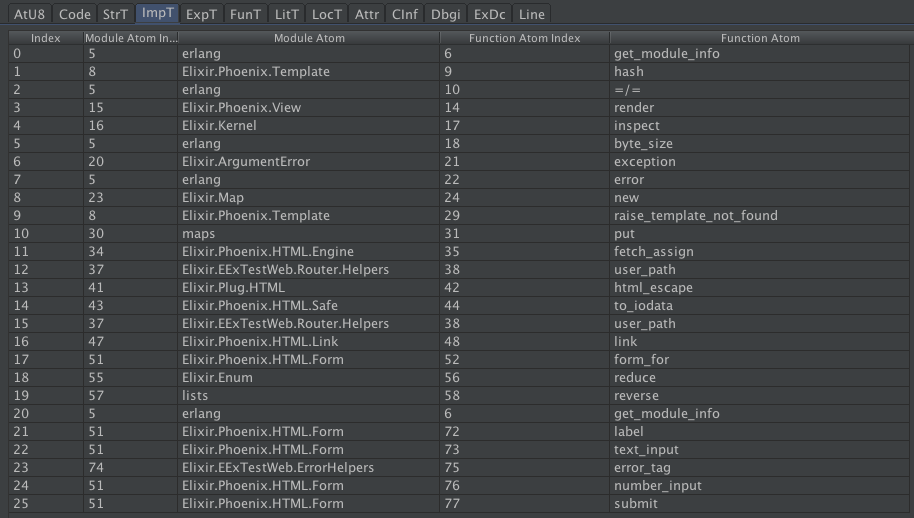
The LitT chunk contains literals loaded as arguments in Code chunk.
Confusingly, in the Code chunk sometimes the literal(N) term is used to encode integer N, an index into another chunk, or an actual index into the LitT. How literal terms are handled is completely dependent on the specific operation, so without having outside knowledge about the bytecode operation arguments for BEAM, the best way to figure out if literal terms are an integer or an index is to toggle the various controls in the Code tab to see if literal with no inlining turns into a LitT literal, FunT function reference, ImpT function reference, or integer.
The LitT tab shows a table with the columns
| Column | Description | Source |
|---|---|---|
| # | 0-based index used by references in the Code chunk. |
Derived |
| Term | The equivalent of `raw | > binary_to_term() |

The Line chunk encodes both the file name and line number for each line(literal(n)) operation in the Code chunk. The n in line(literal(n)) is an index in to the Line References table in the Line chunk. This is used in Phoenix view modules to show where code from templates comes from.
The Line chunk is composed of 2 subsections: (1) Line References and (2) File Names. First there is a header setting up the number of each entry to expect.
| Offset | +0 | +1 | +2 | +3 |
|---|---|---|---|---|
| 0 | emulator version (`unsigned-big-integer`) | |||
| 4 | flags (`unsigned-big-integer`) | |||
| 8 | Line Instruction Count (`unsigned-big-integer`) | |||
| 12 | Line Reference Count (`unsigned-big-integer`) | |||
| 16 | File Name Count (`unsigned-big-integer`) | |||
####### Line References
This uses the Compact Term Format used for the Code chunk. The format ends up producing {file_name_index, line} pairs using the following algorithm:
| Term | Interpretation |
|---|---|
atom(n) |
Change file_name_index to n
|
integer(n) |
Add {file_name_index, n} to end of Line References |
####### File Names
| Offset | +0 | +1 | +2 | +3 |
|---|---|---|---|---|
| 0 | Byte Count (`unsigned-big-integer`) | Bytes | ||
The Line tab has one subtab for each subsection in the tab. Each subsection has its own table.
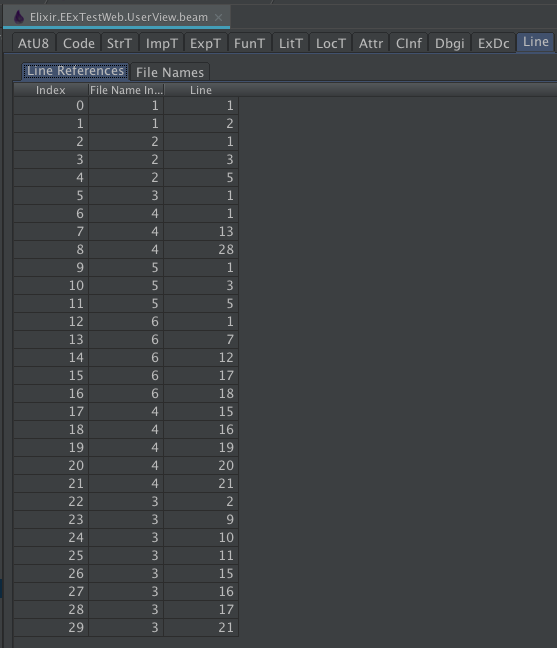

The LocT chunk is the dual to the ExpT chunk: it contains all private functions and macros.
You'll notice entries like -__struct__/1-fun-0-, starts with - and have a / suffix with fun in it. This naming scheme is used for anonymous functions such as those defined with fn or the capture operator (&) in Elixir. Much like how macros don't really exist and use a MACRO- suffix, anonymous functions/lambdas don't exist, and instead use a distinct naming scheme -<PARENT_FUNCTION>/*fun*. Unlike MACRO-, which is an Elixir invention, anonymous functions/lambdas really being local named functions with derived names is also done in pure Erlang modules. Erlang's anonymous functions are defined with fun, which is where the fun part of the naming scheme comes from.
The LocT tab shows a table with the columns
| Column | Description | Source |
|---|---|---|
| Atom Index | Index into the Atom or AtU8 chunk for the function's name |
Raw |
| Name | The atom referenced by "Atom Index" | Derived |
| Arity | The arity (argument count) of the function | Raw |
| Label | Label index in the Code chunk where the function is defined. This label is usually immediately after the func_info operation and before the first pattern match or guard operation. |
Raw |
The StrT chunk contains all Erlang strings (that is, Elixir charlists) used in the Code chunk.
The StrT chunk contains a single contiguous pool. These strings are used for byte code operations like bs_put_string. Not all strings appear in StrT. Some strings, including most Elixir strings (Erlang binaries) appear in the LitT chunk that holds literals. I'm not sure how the compiler determines whether to use StrT or LitT. I think it all depends on the byte code operation.
Instead of encoding the start and length of each string in the chunk itself, the start and length for any given string is passed as arguments to the byte code operations in the Code chunk. By doing this, shared substrings can be efficiently encoded in StrT.

.beam files, such as those in the Elixir SDK, the Elixir SDK's Internal Erlang SDK, and in your project's build directory will be decompiled to equivalent def and defmacro calls. The bodies will not be decompiled, only the call definition head and placeholder parameters. These decompiled call definition heads are enough to allow Go To Declaration, the Structure pane, and Completion to work with the decompiled .beam files.
It turns out that in the .beam binary format there are no macros. This makes sense since the BEAM format was made for Erlang, which does not have macros, and only has functions. Elixir marks its macros in the compiled .beam by prefixing them with MACRO-.
There are 2 chunks in the BEAM format for function references: ExpT, which is for exports (because in Erlang module they are from -export), which are the public functions and macros; and LocT, which is for locals (anything not exported in Erlang), which are private functions and macros.
| BEAM Chunk | Atom Prefix | Macro |
|---|---|---|
ExpT |
MACRO- |
defmacro |
ExpT |
N/A | def |
LocT |
MACRO- |
defmacrop |
LocT |
N/A | defp |
Much like there are no macros in BEAM, there are no anonymous functions either. Any anonymous function (using fn in Elixir or fun in Erlang) ends up being a named function in the LocT chunk. Anonymous functions names start with -, then the parent function's name, a / and a unique number for that scope.
As an example, Kernel has
defp unquote(:"-MACRO-binding/2-fun-0-")(p0, p1, p2, p3) do
# body not decompiled
endwhich is generated from the for in
defmacro binding(context \\ nil) do
in_match? = Macro.Env.in_match?(__CALLER__)
for {v, c} <- __CALLER__.vars, c == context do
{v, wrap_binding(in_match?, {v, [generated: true], c})}
end
endFunctions and macros can have names that aren't valid identifier names, so the decompiler has special handlers to detect these invalid identifiers and escape them to make decompiled code that is parsable as valid Elixir.
| Handler | Name/Arity | Decompiled | Reason |
| Infix Operator | !=/2 |
left != right |
Infix operators are defined in infix position |
!==/2 |
left !== right |
||
&&/2 |
left && right |
||
&&&/2 |
left &&& right |
||
*/2 |
left * right |
||
=+/2 |
left + right |
||
=++/2 |
left ++ right |
||
-/2 |
left - right |
||
--/2 |
left -- right |
||
->/2 |
left -> right |
||
../2 |
left .. right |
||
//2 |
left / right |
||
::/2 |
left :: right |
||
</2 |
left < right |
||
<-/2 |
left <- right |
||
<<</2 |
left <<< right |
||
<<~/2 |
left <<~ right |
||
<=/2 |
left <= right |
||
<>/2 |
left <> right |
||
<|>/2 |
left <|> right |
||
<~/2 |
left <~ right |
||
<~>/2 |
left <~> right |
||
=/2 |
left = right |
||
==/2 |
left == right |
||
===/2 |
left === right |
||
=>/2 |
left => right |
||
=~/2 |
left =~ right |
||
>/2 |
left > right |
||
>=/2 |
left >= right |
||
>>>/2 |
left >>> right |
||
\\/2 |
left \\\\ right |
||
^/2 |
left ^ right |
||
^^^/2 |
left ^^^ right |
||
and/2 |
left and right |
||
in/2 |
left in right |
||
or/2 |
left or right |
||
|>/2 |
left |> right |
||
||/2 |
left || right |
||
|||/2 |
left ||| right |
||
~=/2 |
left ~= right |
||
~>/2 |
left ~> right |
||
~>>/2 |
left ~>> right |
||
| Prefix Operator | +/1 |
(+value) |
To prevent precedence errors, unary prefix operators, which also have binary infix operators of the same name need to be defined inside parentheses |
-/1 |
(-value) |
||
| Unquoted | %/2 |
unquote(:%)(p0, p1) |
Special forms need to defined as atom passed to unquote, as special forms are handled before macros defining the calls are applied |
%{}/1 |
unquote(:%{})(p0) |
||
&/1 |
unquote(:&)(p0) |
||
./2 |
unquote(:.)(p0, p1) |
||
<<>>/1 |
unquote(:<<>>)(p0) |
||
do/n |
unquote(:do)(p0, ...) |
Keywords need to be escaped | |
fn/1 |
unquote(:fn)(p0) |
Special forms need to defined as atom passed to unquote, as special forms are handled before macros defining the calls are applied | |
unquote/1 |
unquote(:unquote)(p0) |
||
unquote_splicing/1 |
unquote(:unquote_splicing)(p0) |
||
{}/n |
unquote(:{})(p0, ...) |
||
Capitalized/n |
unquote(:Capitalized)(p0, ...) |
Part of the Corba libraries in OTP have functions starting with a capital letter, which would be parsed as an Alias in Elixir if not unquoted. | |
#text#/1 |
unquote(:"#text#")(p0) |
Part of the XML libraries in OTP have functions
that start with or contain `#`, which would parse as a comment in Elixir if not unquoted in a double quoted
atom.
|
|
| Default | name/n |
name(p0, ...) |
If no specialized handler is required, functions and macros are defined normally with pN for each parameter in the Nth position |
When you start typing an Alias, completion will look in three locations:
-
aliasaliased names in the current file-
Suffixforalias Prefix.Suffix -
MultipleAliasAorMultipleAliasBforalias Prefix.{MultipleAliasA, MultipleAliasB} -
Asforalias Prefix.Suffix, as: As
-
- Indexed module names (as available from Go To Symbol)
-
Prefix.Suffixfromdefmodule Prefix.Suffix -
MyProtocolfromdefprotocol MyProtocol -
MyProtocol.MyStructdefimpl MyProtocol, for: MyStruct-
defimpl MyProtocolnested underdefmodule MyStruct
-
- Nested modules under aliased names
-
Suffix.Nestedforalias Prefix.SuffixwherePrefix.Suffix.Nestedis an indexed module, implementation or protocol name. -
MultipleAliasA.Nestedforalias Prefix.{MultipleAliasA, MultipleAliasB}wherePrefix.MultipleAliasA.Nestedalias Prefix.{MultipleAliasA, MultipleAliasB}is an indexed module, implementation or protocol name. -
As.Nestedforalias Prefix.Suffix, as: AswherePrefix.Suffix.Nestedis an indexed module, implementation, or protocol name.
-
When you start typing inside { } for alias Prefix.{} or import Prefix.{}, completion will look for nested modules under Prefix and then remove the Prefix., so completion will look like Suffix.
Completion uses the same presentation as Structure, so you can tell whether the name is function/macro (Time), whether it is public/private (Visibility) and the Module where it is defined. Between the icons and the Modules is the name itself, which is highlighted in bold, the parameters for the call definition follow, so that you can preview the patterns required for the different clauses.

Qualified functions and macro calls will complete using those functions and macros defined in the qualifying Module (defmodule), Implementation (defimpl) or Protocol (defprotocol). Completion starts as shown as . is typed after a qualifying Alias.
Function and macro calls that are unqualified are completed from the index of all function and macro definitions, both public and private. (The index contains only those Elixir functions and macro defined in parsable source, such as those in the project or its dependencies. Erlang functions and Elixir functions only in compiled .beam files, such as the standard library will not complete.) Private function and macros are shown, so you can choose them and then make the chosen function or macro public if it is a remote call.
Module attributes declared earlier in the file can be completed whenever you type @ and some letter. If you want to see all module attributes, you can type @a, wait for the completions to appear, then delete the @ to remove the filtering to a.
Parameter and variable usages can be completed whenever typing an identifier. The completions will include all variables know up from that part of the file. It can include variables from outside macros, like quote blocks.
Go To Declaration is a feature of JetBrains IDEs that allows you to jump from the usage of a symbol, such as a Module
Alias, to its declaration, such as the defmodule call.
- Place the cursor over an Alias with an aliased name setup by
alias-
Suffixifalias Prefix.Suffixcalled -
MultipleAliasAifalias Prefix.{MultipleAliasA, MultipleAliasB}called -
Asifalias Prefix.Suffix, as: As
-
- Activate the Go To Declaration action with one of the following:
Cmd+B- Select Navigate > Declaration from the menu.
Cmd+Click
- A Go To Declaration lookup menu will appear, allowing you to jump either the
aliasthat setup the aliased name or jumping directly todefmoduleof the unaliased name. Select which declaration you want- Use arrow keys to select and hit
Enter Click
- Use arrow keys to select and hit
You'll know if function or macro usage is resolved and Go To Declaration will work if the call is annotated, which in the default themes will show up as italics.
- Place the cursor over name of the function or macro call.
- Activate the Go to Declaration action with one of the following:
Cmd+B- Select Navigate > Declaration from the menu.
Cmd+Click
- A Go To Declaration lookup menu will appear, allowing you to jump to either the
importthat imported the function or macro or jumping directly to the function or macro definition clause. Select which declaration you want.- Use arrow keys to select and hit
Enter Click
- Use arrow keys to select and hit
- Place the cursor over name of the function or macro call.
- Activate the Go to Declaration action with one of the following:
Cmd+B- Select Navigate > Declaration from the menu.
Cmd+Click
- Whether a lookup a Go To Declaration lookup menu appears depends on the number of clauses in the function or macro definition:
- If there is only one clause in the function or macro definition, you'll jump immediately to that clause
- If there is more than one clause in the function or macro definition, a Go To Declaration lookup menu will appear, allowing you to jump to either the
importthat imported the function or macro or jumping directly to the function or macro definition clause. Select which declaration you want.- Use arrow keys to select and hit
Enter Click
- Use arrow keys to select and hit
- Place the cursor over name of the function or macro call that is qualified by an Alias.
- Activate the Go to Declaration action with one of the following:
Cmd+B- Select Navigate > Declaration from the menu.
Cmd+Click
-
- If there is only one clause in the function or macro definition, you'll jump immediately to that clause
- If there is more than one clause in the function or macro definition, a Go To Declaration lookup menu will appear, allowing you to jump to either the
importthat imported the function or macro or jumping directly to the function or macro definition clause. Select which declaration you want.- Use arrow keys to select and hit
Enter Click
- Use arrow keys to select and hit
- Place the cursor over a fully-qualified Alias
-
A.BinA.B.func() -
A.Binalias A.B -
Binalias A.{B, C}
-
- Activate the Go To Declaration action with one of the following:
Cmd+B- Select Navigate > Declaration from the menu.
Cmd+Click
If you hold Cmd and hover over the Alias before clicking, the target declaration will be shown.
- Place the cursor over a
@module_attribute - Activate the Go To Declaration action with one of the following:
Cmd+B- Select Navigate > Declaration from the menu.
Cmd+Click
If you hold Cmd and hover over the @module_attribute before clicking, the target declaration will be shown.
- Place the cursor over a parameter or variable usage
- Active the Go To Declaration action with one of the following:
Cmd+B- Select Navigate > Declaration from the menu.
Cmd+Click
If you hold Cmd and hover over the variable before clicking, it will say parameter or variable, which matches the annotation color.
IntelliJ Elixir can reformat code to follow a consistent style.
-
doblock lines are indented -
doblocksendas the last argument of a no parentheses call unindents to the start of the call - If one clause of a multi-clause anonymous function wraps, all clauses wrap.
- Indent after
else - Indent map and struct keys
- All keys wrap if any key wraps
- No spaces around...
.
- Spaces around...
andinorwhen
- Configure spaces around...
=-
<-and\\ -
!=,==,=~,!==, and=== -
<,<=,>=, and> -
+and- -
*and/ - Unary
+,-,!,^, and~~~ ->::|-
||and||| -
&&and&&& -
<~,|>,~>,<<<,<<~,<|>,<~>,>>>, and~>> ..^^^-
++,--,..,<> =>
- Configure spaces before...
,
- No space after...
@
- Spaces after...
notfnaftercatchrescuekey:
- Configure space after...
&,
- Configure spaces within...
{ }<< >>[ ]( )
- No space around
/in&NAME/ARITYand&QUALIFIER.NAME/ARITY -
whenwraps when its right operand wraps, so that guards start withwhenon a newline when they are too long. - Align
|>at start of indented line for pipelines - Align
endwith start of call instead of start of line fordoblocks in pipelines - Indent list elements when wrapped
- Indent tuple elements when wrapped
- Align type definition to right of
:: - Align guard to right of
whenwhen guards span multiple lines - Align two operator (
++,--,..,<>) operands, so that<>binaries are multiple lines align their starts instead of using continuation indent and being indented relative to first operand. - Align pipe
|operands, so that alternates in types and specs are aligned instead of continuation indented relative to the first operand. - Comments in
spec(that is above operands to|align with the operands - Remove newlines from pipelines, so that all pipelines start with an initial value or call and each
|>is the start of a successive line. - Key exclusivity: if an association operation or keyword key is already on a line, the container value automatically has it's elements wrapped if there is nested associations or keyword pairs, so that two levels of keys are not on the same line.
- Indent bit string (
<< >>) elements when wrapped
All files in a directory can be reformatted.
Using context menu:
- Open the Project pane
- Right-click the directory
- Select Reformat Code
- Set the desired options in the Reformat Code dialog
- Click Run
Using keyboard shortcuts:
- Open the Project pane
- Select the directory
Alt+Cmd+L- Set the desired options in the Reformat Code dialog
- Click Run
All lines in a file can be reformatted.
Using context menu:
- Open the Project pane
- Right-click the file
- Select Reformat Code
- Set the desired options in the Reformat Code dialog
- Click OK
Using keyboard shortcuts:
- Open the Project pane
- Select the file
Alt+Cmd+L- Set the desired options in the Reformat Code dialog
- Click OK
All the lines in the current editor tab file can be reformatted with the current settings.
- Code > Reformat
-
Alt+Cmd+L-
Alt+Shift+Cmd+Lto get the Reformat Code dialog.
-
A subset of a file can be reformatted.
- Highlight the selection
- Use the Reformat Code action
- Code > Reformat Code
Alt+Shift+Cmd+L
Go To Related is like Go To Declaration, but more general, for anything that is related to an element, but not its declaration.
In IntelliJ Elixir, Go To Related can be used to go to the decompiled version of a modular (defimpl, defprotocol, or defmodule) or a callable (def, defp, defmacro, defmacrop) definition.
-
Place the cursor on the name of the modular, such as
EExTest.Accountsindefmodule EExTest.Accounts do -
Go To Related
- Navigate > Related Symbol
Ctrl+Cmd+Up
-
Select a "Decompiled BEAM" target from the "Choose Target" context menu

-
You will be taken to the decompiled module

-
Place the cursor on the name of the call, such as
get_user!indef get_user!(id) -
Go To Related
- Navigate > Related Symbol
Ctrl+Cmd+Up
-
Select a "Decompiled BEAM" target from the "Choose Target" context menu

-
You will be taken to the decompiled module
Go To Symbol is a way to search for any of the following by name:
- Call definition clauses (
def,defp,defmacro, anddefmacrop) - Callbacks (
@callbackand@macrocallback) - Call definition specifications (
@spec) - Call definition heads (
foo(bar)) for delegation (defdelegate foo(bar), to: BAZ) - Implementations (
defimpl) - Protocols (
defprotocol)
You can bring up Go To Symbol with the keyboard shortcut (⌥⌘O on OSX) or using the menus (Navigate > Symbol...).
Go to Test allows you to jump from the a Source Module to its corresponding Test Module
- Have the cursor in the body of a Module
- Active the Go To Test action with one of the following:
Shift+Cmd+T- Select Navigate > Test from the menu.
Go to Test Subject allows you to jump from the a Test Module to its corresponding Source Module
- Have the cursor in the body of a Test Module
- Active the Go To Test Subject action with one of the following:
Shift+Cmd+T- Select Navigate > Test Subject from the menu.
Find Usages is a feature of JetBrains IDEs. It is the dual of Go To Declaration. While Go To Declaration jumps from a usage to the declaration, Find Usages finds all usages that could jump to a declaration. When used on a usage, Find Usage first finds the declaration(s) and then finds usages of those declaration(s).
Find Usages will open all the found usages in the Find Tool Window (unless you have it configured to not open and jump direct if only one usage is found). If you want to jump to usages quickly, Show Usages, which opens a lookup dialog at the cursor and allows you to select a usage to jump to in the lookup dialog with the arrow keys may be more useful.
- Place the cursor over the name of a function, such as
hdin the definitiondef hd([h | t]]) doorhdin a usagehd(list). - Active the Find Usages action with one of the following:
Alt+F7- Select Edit > Find > Find Usages from the menu.
- A Find Usages dialog will appear in the Find Tool Window.
If a function has multiple clauses, all clauses for the function will be resolved and used as targets.
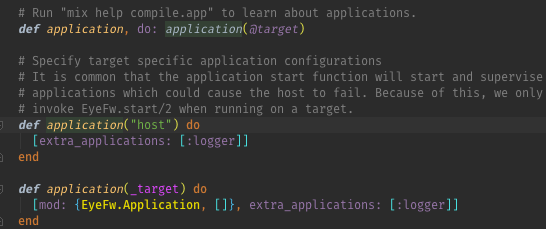
You can be sure that all clauses were correctly identified as targets because of the multiple entries in the top "Functions" target grouping.
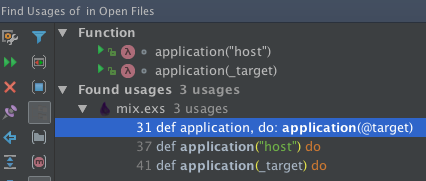
If instead of bringing up the Find Tool Window, you'd like a lookup dialog above the cursor, you can use Show Usages.
- Place the cursor over the name of a function, such as
hdindef hd([h | t]]) do - Active the Show Usages action with one of the following:
Alt+Cmd+F7- Select Edit > Find > Show Usages from the menu.
- A Usages lookup will appear above the cursor.
- Select an element from the lookup to jump to that usage
- Place cursor over an
defmoduleAlias. - Activate the Find Usage action with one of the following:
- From Context
- Right-click the Alias
- Select "Find Usages" from the context menu
- Select Edit > Find > Find Usages from the menu
Alt+F7
- From Context
- Place cursor over the
@module_attributepart of the declaration@module_attribute value. - Activate the Find Usage action with one of the following:
1.
1. Right-click the module attribute
2. Select "Find Usages" from the context menu
2. Select Edit > Find > Find Usages from the menu
3.
Alt+F7
- Place cursor over the parameter or variable declaration.
- Active the Find Usage action with one of the following:
1.
1. Right-click the Alias
2. Select "Find Usages" from the context menu
2. Select Edit > Find > Find Usages from the menu
3.
Alt+F7
- Place the cursor over the
@module_attributeusage or declaration. - Active the Rename Refactoring action with one of the following:
1.
1. Right-click the module attribute
2. Select Refactoring from the context menu
3. Select "Rename..." from the Refactoring submenu
2.
Shift+F6 - Edit the name inline and have the declaration and usages update.
- Place the cursor over the parameter or variable usage or declaration
- Active the Rename Refactoring action with one of the following:
1.
1. Right-click the module attribute
2. Select Refactoring from the context menu
3. Select "Rename..." from the Refactoring submenu
2.
Shift+F6 - Edit the name inline and have the declaration and usages update.
Because Elixir is built on top of Erlang, Elixir command line commands don't have OS native binaries, instead the OS native binaries from Erlang are used. In order to reliably find the Erlang OS native binaries, like erl and erl.exe, the path to BOTH the Erlang SDK and the Elixir SDK must be configured. This allows you to install Erlang and Elixir with completely different package managers too: you can install Erlang with kerl and Elixir with kiex and you don't have to worry about IntelliJ not seeing the environment variables set by kerl when launching IntelliJ from an application launchers instead of a terminal.
Since JetBrains' OpenAPI only supports one SDK per Project or Module, to support Elixir and Erlang SDK at the same time, the Elixir SDK keeps track of an Internal Erlang SDK. When setting up your first Elixir SDK, you will be prompted to create an Erlang SDK (if you have the intellij-erlang plugin installed) or and Erlang for Elixir SDK (if you don't have intellij-erlang installed and you need to use the minimal Erlang for Elixir SDK supplied by this plugin).
When configuring an SDK, if you don't want to use the suggested SDK home path, you'll need to know where each package manager puts Elixir and Erlang.
| Package Manager | SDK Type | Directory |
|---|---|---|
| ASDF | Elixir SDK |
~/.asdf/installs/elixir/VERSION
|
| Erlang SDK |
~/.asdf/installs/erlang/VERSION
|
|
| Erlang for Elixir SDK | ||
| Homebrew | Elixir SDK |
/usr/local/Cellar/elixir/VERSION
|
| Erlang SDK |
/usr/local/Cellar/erlang/VERSION/lib/erlang
|
|
| Erlang for Elixir SDK | ||
| Nix | Elixir SDK |
/nix/store/SHA256-elixir-VERSION/lib/elixir
|
| Erlang SDK |
/nix/store/SHA256-erlang-VERSION/lib/erlang
|
|
| Erlang for Elixir SDK |
If you can can't see hidden files, such as .asdf in your home directory (~), or system directories, such as /usr, you will need to enable Show Hidden Files in the Home Path dialog.
If your dialog looks like this, click the Show Hidden Files button

If you're using the macOS native File Picker, use the keyboard shortcut ⌘⇧. (Command+Shift+Period).
Rich IDEs can use the Project Structure system to configure Elixir and Erlang SDKs and select the Project/Module SDK.
With the Elixir SDK setup with an Internal Erlang SDK, you can see the Elixir SDK name and the home path, but unlike other SDKs, there's a dropdown for changing the Internal Erlang SDK.

You'll notice there is a mix of two different parent paths in Class Paths:
-
Those from the Elixir SDK Home Directory, which are the
lib/APP/ebinfor theAPPs that ships with Elixir:eex,elixir,ex_unit,iex,logger, andmix.
-
Those from the Internal Erlang SDK Home Directory, which are the
lib/APP-VERSION/ebinfor theAPPs that ship with OTP.
The Class Paths are combined from the two SDKs because OpenAPI doesn't allow to dynamically delegate to the Internal Erlang SDK when checking for Class Paths to scan for completion and running. If you change the Internal Erlang SDK in the dropdown, the Class Paths will be updated to remove the old Internal Erlang SDK Class Paths and add the new Internal Erlang SDK Class Paths.
These Class Paths are not just for code completion and search anymore, all paths listed as passed with -pa flag to erl or erl.exe when running mix, so that you can mix different versions of OTP applications shipped with different version of OTP, so you can take advantage of the independently updatable OTP apps in the release notes for OTP.

-
The default SDK for new projects can we set from the Configure menu on Welcome Screen
-
Hover over "Project Defaults" to see its submenu

-
Select "Project Structure" from the submenu

-
IntelliJ will start out with no default SDK. To make the default SDK, an Elixir SDK, Click New

-
Select "Elixir SDK"

-
You'll get "Cannot Create SDK" message because there are no Erlang SDKs for the Elixir SDK to use as an Internal Erlang SDK. Click OK to create the Erlang SDK first.

-
You'll be actually prompted to Select Home Directory for the Erlang SDK
-
If you have the
intellij-erlangplugin installed, you'll create an Erlang SDK from it.
NOTE: Erlang SDK's default Home Directory favors the oldest version of Erlang installed. You probably want the newest version. To manually select the Home Directory, it is the directory that contains the
bin,erts-VERSION, andlibsubdirectories. For Homebrew, the path looks like/usr/local/Cellar/erlang/VERSION/lib/erlang. It is important to select thelib/erlangdirectory and not theVERSIONdirectory forintellij-erlangto accept it as a Home Directory. -
If you don't have
intellij-erlanginstalled, then you'll create and Erlang for Elixir SDK, which is supplied by this plugin.
-
-
With an Erlang SDK available to use as the Internal Erlang SDK, you'll be prompted for the Home Directory for the Elixir SDK.

Because Small IDEs like Rubymine do not have Project Structure, the Elixir SDK, Erlang SDK, and selected SDK must be configured in Preferences.
Facets are a feature of JetBrains OpenAPI that allow additional languages and frameworks to be added to a Module. In Small IDEs, each Project has only one Module and its SDK MUST match the Small IDE's language, such as a Ruby SDK in Rubymine, so to allow an Elixir SDK to be selected, an Elixir Facet is added to the Module in Small IDEs.
To configure the Elixir Facet SDK
- Open Preferences > Languages & Frameworks > Elixir
- Select a previously created Elixir SDK from the SDK combo box.
- If there is no Elixir SDK, you can create one first.
- Click Apply to save the Preferences changes or OK to save and close.
In Small IDEs, Elixir SDKs are tracked as Application Preferences, so any Elixir SDK you create in one project will be usable in another and you won't have to create the SDK in each project, just select it.
-
Open Preferences > Languages & Frameworks > Elixir > SDKs
-
Click
+to add a new Elixir SDK
-
If you don't already have an Erlang SDK for Elixir SDK setup, you'll need to create one first.

-
You'll be prompted with the default path for the most recent version of Erlang installed.

You can change directory to a select a different version. The home directory for "Erlang SDK for Elixir SDK" for Homebrew is NOT
/usr/local/Cellar/erlang/VERSION, but/usr/local/Cellar/erlang/VERSION/lib/erlangdue to where the OTP appebindirectories are located. -
Click OK to create the Erlang SDK for Elixir SDK.
-
With at least one Erlang SDK for Elixir SDK setup, you'll be prompted with the default path for the most recent version of Elixir installed.

-
Click OK to create the Elixir SDK.
-
Click Apply to save the Preferences changes or OK to save and close.
You can further customize the Elixir SDK by selecting its name from the left list.

- Change Home Path
- Change Internal Erlang SDK
- Change
ebindirectories on the Classpath tab
If you want to change the Internal Erlang SDK, you'll need to create a new Erlang SDK for Elixir SDK.
-
Open Preferences > Languages & Frameworks > Elixir > Internal SDKs

-
Follow the same steps as above to create an SDK
You can view the structure of the currently open editor tab using the Structure tool window.
- View > Tool Windows > Structure
- Click the Structure Button (normally in the left tool buttons)
- If you can't see the Tool Buttons, they can be enabled with View > Tool Buttons
Cmd+7

The buttons in the Structure tool are broken into 4 categories:

| Icon | Tooltip | Description |
|---|---|---|
|
|
Sort by Time |
When the defined callable is usable:
|
|
|
Sort by Visibility |
Whether the element visible outside its defining module:
|
|
|
Sort Alphabetically | Sort by name |
NOTE: When any combination of sorters is turned on, they are sorted from left to right (as shown in the button bar), so with all 3 sorters on, the elements are first grouped by Time, then inside each Time group, they are sorted by Visibility, then in each Visibility group, they are sorted by name.

The providers add nodes not in the text of the file, but that will appear in the compiled Module.
| Icon | Tooltip | Description |
|---|---|---|
|
|
Show Used | In Modules that `use ` or `use , arg`, the elements from the last `quote` block in the `__using__/1` for `` are injected. |

The expanders expand or collapse all the elements in the Structure tool window.
| Icon | Tooltip | Description |
|---|---|---|
|
|
Expand All | Expand All Elements in the Structure tool window |
|
|
Collapse All | Collapse All Elements in the Structure tool window |

The autoscrollers link together the editor tab's location and the Structure tool windows selected element.
| Icon | Tooltip | Description |
|---|---|---|
|
|
Autoscroll to Source | Clicking an element in the Structure tool window will scroll the editor window to the location of the corresponding source. |
|
|
Autoscroll from Source | When moving the cursor in the editor window, the selected element in the Structure tool window will change to the corresponding element. |
The Time icons indicate whether the element is usable at compile time or runtime.
| Icon | Tooltip | Description |
|---|---|---|
|
|
Compile Time | The element is used or checked at compile time and (may) not even be accessible at run time, such as macros. |
|
|
Runtime | The element is usable at runtime, such as a function. |
The Visibility icons indicated whether the element is usable outside its defining Module.
| Icon | Tooltip | Description |
|---|---|---|
|
|
Public | Public elements are accessible outside their defining Module. |
|
|
Private |
Private elements are only accessible in their defining Module. The macros that define private elements usually
end in p.
|
| Call | Icons | Text | Description | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Macro Type | Time | Visibility | Function | Module Local | Overridable | Override | |||
def
|
|
|
|
NAME/ARITY
|
Groups together def with the same name and arity.
|
||||
|
|
|
|
|
NAME[(][ARGUMENTS][)][when ...]
|
The function head for function clause, including the name, arguments, and when if present
|
||||
defdelegate
|
|
|
defdelegate append_first: false|true, to: ALIAS|ATOM
|
Groups together all the delegated functions for a single defdelegate call.
|
|||||
defdelegate func(arg), to: ALIAS
|
|
|
|
NAME/ARITY
|
Groups together implied def and any explicit @spec for the given function head
(func(arg))
|
||||
defdelegate func(arg), to: ALIAS
|
|
|
|
|
func(arg)
|
The function head implied by the defdelegate list of function heads.
|
|||
defexception
|
|
RELATIVE_ALIAS
|
The exception has the same name as the parent Module, but will display with only the relative name (the last
Alias without a .) with its location as the qualifying Alias.
|
||||||
defexception
|
|
%RELATIVE_ALIAS{}
|
Exceptions are defined as structs, so any defexception
|
||||||
defexception list_or_keywords
|
|
NAME: DEFAULT_VALUE
|
The fields and default values (or nil if a list is used instead of a keyword list) for the struct
as passed in the first argument to defexception.
|
||||||
defimpl PROTOCOL, for: MODULE
|
|
|
MODULE (PROTOCOL)
|
defimpl defines a protocol implementation that defines a Module that concatenates the
PROTOCOL name and the MODULE name. If no :for is given, then the outer
Module is used.
|
|||||
defmacro
|
|
|
|
NAME/ARITY
|
Groups together defmacro with the same name and arity.
|
||||
|
|
|
|
|
NAME[(][ARGUMENTS][)][when ...]
|
The macro head for macro clause, including the name, arguments, and when if present
|
||||
defmacrop
|
|
|
|
NAME/ARITY
|
Groups together defmacrop with the same name and arity.
|
||||
|
|
|
|
|
NAME[(][ARGUMENTS][)][when ...]
|
The macro head for macro clause, including the name, arguments, and when if present
|
||||
defmacro AND defmacrop
|
|
|
|
NAME/ARITY
|
Groups together defmacro AND defmacrop with the same name and arity. This will be a
compile error, but is represented with
|
||||
defmodule ALIAS
|
|
RELATIVE_ALIAS (QUALIFIER)
|
Top-level Modules show only the ALIAS with no location, while qualified Aliases or nested Modules
show the RELATIVE_ALIAS and the QUALIFIER as the location.
|
||||||
defoverridable
|
|
Mark previously declared functions as overridable. Overridable functions are listed as children of this element. | |||||||
defoverridable NAME: ARITY, ...
|
|
|
|
|
NAME/ARITY
|
The NAME and ARITY of the function that is overridable. Matches the icon and text
for def, but with the addition of
|
|||
defp
|
|
|
|
NAME/ARITY
|
Groups together def with the same name and arity.
|
||||
|
|
|
|
|
NAME[(][ARGUMENTS][)][when ...]
|
The function head for function clause, including the name, arguments, and when if present
|
||||
def AND defp
|
|
|
|
NAME/ARITY
|
Groups together def AND defp with the same name and arity. This will be a
compile error, but is represented with
|
||||
defprotocol PROTOCOL
|
|
|
PROTOCOL
|
The protocol name. Functions required by the protocol are children of this element.
|
|||||
defstruct
|
|
%RELATIVE_ALIAS{}
|
Structs have the same RELATIVE_ALIAS
|
||||||
defstruct NAME: DEFAULT_VALUE, ...
|
|
NAME: DEFAULT_VALUE
|
The fields and default values (or nil if a list is used instead of a keyword list) for the struct.
|
||||||