TensorRT LLM provides users with an easy-to-use Python API to define Large Language Models (LLMs) and supports state-of-the-art optimizations to perform inference efficiently on NVIDIA GPUs.
Architecture | Performance | Examples | Documentation | Roadmap
-
[02/06] Accelerating Long-Context Inference with Skip Softmax Attention ✨ ➡️ link
-
[01/09] Optimizing DeepSeek-V3.2 on NVIDIA Blackwell GPUs ✨ ➡️ link
-
[10/13] Scaling Expert Parallelism in TensorRT LLM (Part 3: Pushing the Performance Boundary) ✨ ➡️ link
-
[09/26] Inference Time Compute Implementation in TensorRT LLM ✨ ➡️ link
-
[09/19] Combining Guided Decoding and Speculative Decoding: Making CPU and GPU Cooperate Seamlessly ✨ ➡️ link
-
[08/29] ADP Balance Strategy ✨ ➡️ link
-
[08/05] Running a High-Performance GPT-OSS-120B Inference Server with TensorRT LLM ✨ ➡️ link
-
[08/01] Scaling Expert Parallelism in TensorRT LLM (Part 2: Performance Status and Optimization) ✨ ➡️ link
-
[07/26] N-Gram Speculative Decoding in TensorRT LLM ✨ ➡️ link
-
[06/19] Disaggregated Serving in TensorRT LLM ✨ ➡️ link
-
[06/05] Scaling Expert Parallelism in TensorRT LLM (Part 1: Design and Implementation of Large-scale EP) ✨ ➡️ link
-
[05/30] Optimizing DeepSeek R1 Throughput on NVIDIA Blackwell GPUs: A Deep Dive for Developers ✨ ➡️ link
-
[05/23] DeepSeek R1 MTP Implementation and Optimization ✨ ➡️ link
-
[05/16] Pushing Latency Boundaries: Optimizing DeepSeek-R1 Performance on NVIDIA B200 GPUs ✨ ➡️ link
-
[08/05] 🌟 TensorRT LLM delivers Day-0 support for OpenAI's latest open-weights models: GPT-OSS-120B ➡️ link and GPT-OSS-20B ➡️ link
-
[07/15] 🌟 TensorRT LLM delivers Day-0 support for LG AI Research's latest model, EXAONE 4.0 ➡️ link
-
[06/17] Join NVIDIA and DeepInfra for a developer meetup on June 26 ✨ ➡️ link
-
[05/22] Blackwell Breaks the 1,000 TPS/User Barrier With Meta’s Llama 4 Maverick ✨ ➡️ link
-
[04/10] TensorRT LLM DeepSeek R1 performance benchmarking best practices now published. ✨ ➡️ link
-
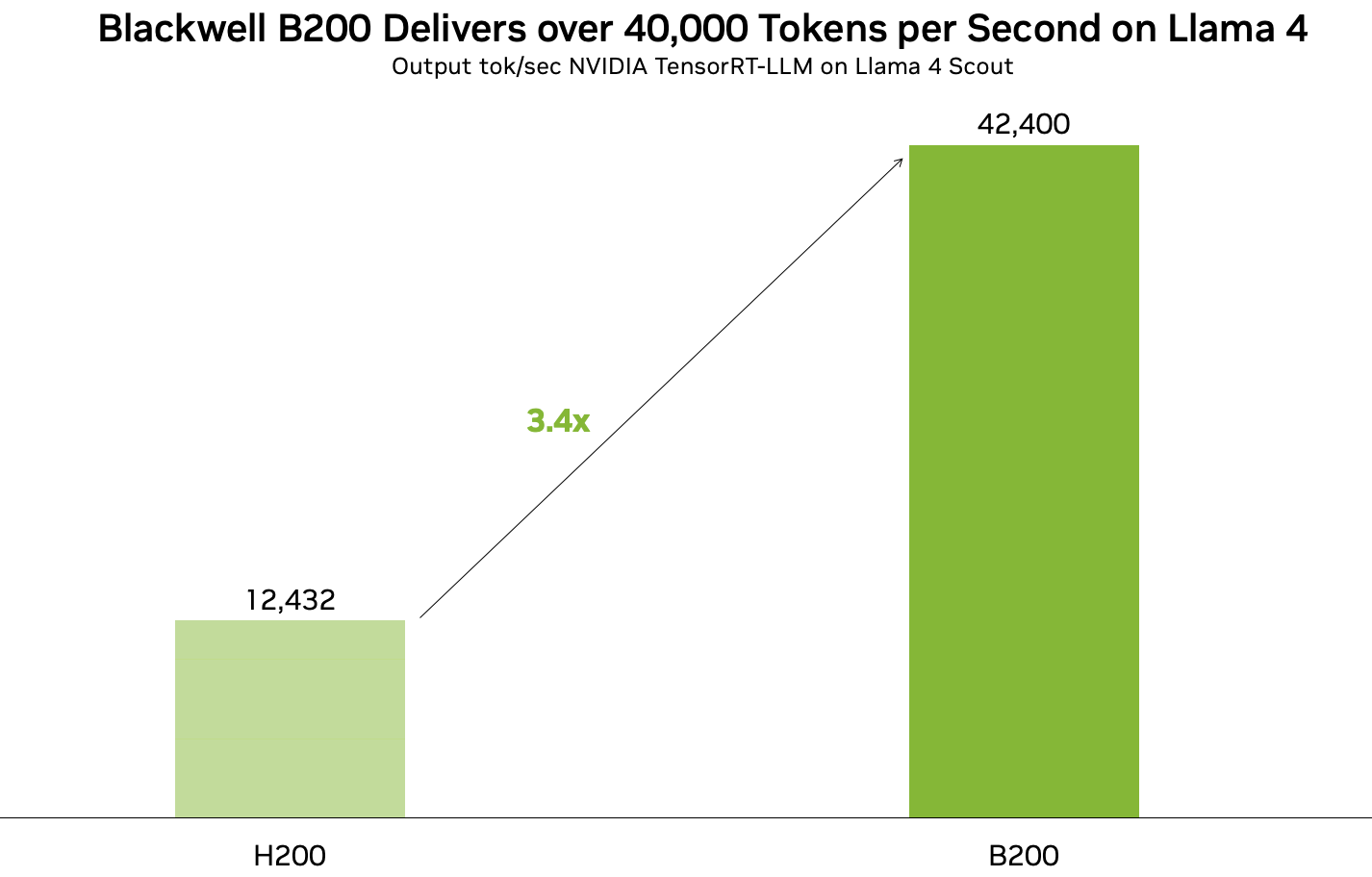
[04/05] TensorRT LLM can run Llama 4 at over 40,000 tokens per second on B200 GPUs!
-
[03/22] TensorRT LLM is now fully open-source, with developments moved to GitHub!
-
[03/18] 🚀🚀 NVIDIA Blackwell Delivers World-Record DeepSeek-R1 Inference Performance with TensorRT LLM ➡️ Link
-
[02/28] 🌟 NAVER Place Optimizes SLM-Based Vertical Services with TensorRT LLM ➡️ Link
-
[02/25] 🌟 DeepSeek-R1 performance now optimized for Blackwell ➡️ Link
-
[02/20] Explore the complete guide to achieve great accuracy, high throughput, and low latency at the lowest cost for your business here.
-
[02/18] Unlock #LLM inference with auto-scaling on @AWS EKS ✨ ➡️ link
-
[02/12] 🦸⚡ Automating GPU Kernel Generation with DeepSeek-R1 and Inference Time Scaling ➡️ link
-
[02/12] 🌟 How Scaling Laws Drive Smarter, More Powerful AI ➡️ link
Previous News
-
[2025/01/25] Nvidia moves AI focus to inference cost, efficiency ➡️ link
-
[2025/01/24] 🏎️ Optimize AI Inference Performance with NVIDIA Full-Stack Solutions ➡️ link
-
[2025/01/23] 🚀 Fast, Low-Cost Inference Offers Key to Profitable AI ➡️ link
-
[2025/01/16] Introducing New KV Cache Reuse Optimizations in TensorRT LLM ➡️ link
-
[2025/01/14] 📣 Bing's Transition to LLM/SLM Models: Optimizing Search with TensorRT LLM ➡️ link
-
[2025/01/04] ⚡Boost Llama 3.3 70B Inference Throughput 3x with TensorRT LLM Speculative Decoding ➡️ link
-
[2024/12/10] ⚡ Llama 3.3 70B from AI at Meta is accelerated by TensorRT-LLM. 🌟 State-of-the-art model on par with Llama 3.1 405B for reasoning, math, instruction following and tool use. Explore the preview ➡️ link
-
[2024/12/03] 🌟 Boost your AI inference throughput by up to 3.6x. We now support speculative decoding and tripling token throughput with our NVIDIA TensorRT-LLM. Perfect for your generative AI apps. ⚡Learn how in this technical deep dive ➡️ link
-
[2024/12/02] Working on deploying ONNX models for performance-critical applications? Try our NVIDIA Nsight Deep Learning Designer ⚡ A user-friendly GUI and tight integration with NVIDIA TensorRT that offers: ✅ Intuitive visualization of ONNX model graphs ✅ Quick tweaking of model architecture and parameters ✅ Detailed performance profiling with either ORT or TensorRT ✅ Easy building of TensorRT engines ➡️ link
-
[2024/11/26] 📣 Introducing TensorRT LLM for Jetson AGX Orin, making it even easier to deploy on Jetson AGX Orin with initial support in JetPack 6.1 via the v0.12.0-jetson branch of the TensorRT LLM repo. ✅ Pre-compiled TensorRT LLM wheels & containers for easy integration ✅ Comprehensive guides & docs to get you started ➡️ link
-
[2024/11/21] NVIDIA TensorRT LLM Multiblock Attention Boosts Throughput by More Than 3x for Long Sequence Lengths on NVIDIA HGX H200 ➡️ link
-
[2024/11/19] Llama 3.2 Full-Stack Optimizations Unlock High Performance on NVIDIA GPUs ➡️ link
-
[2024/11/09] 🚀🚀🚀 3x Faster AllReduce with NVSwitch and TensorRT LLM MultiShot ➡️ link
-
[2024/11/09] ✨ NVIDIA advances the AI ecosystem with the AI model of LG AI Research 🙌 ➡️ link
-
[2024/11/02] 🌟🌟🌟 NVIDIA and LlamaIndex Developer Contest 🙌 Enter for a chance to win prizes including an NVIDIA® GeForce RTX™ 4080 SUPER GPU, DLI credits, and more🙌 ➡️ link
-
[2024/10/28] 🏎️🏎️🏎️ NVIDIA GH200 Superchip Accelerates Inference by 2x in Multiturn Interactions with Llama Models ➡️ link
-
[2024/10/22] New 📝 Step-by-step instructions on how to ✅ Optimize LLMs with NVIDIA TensorRT-LLM, ✅ Deploy the optimized models with Triton Inference Server, ✅ Autoscale LLMs deployment in a Kubernetes environment. 🙌 Technical Deep Dive: ➡️ link
-
[2024/10/07] 🚀🚀🚀Optimizing Microsoft Bing Visual Search with NVIDIA Accelerated Libraries ➡️ link
-
[2024/09/29] 🌟 AI at Meta PyTorch + TensorRT v2.4 🌟 ⚡TensorRT 10.1 ⚡PyTorch 2.4 ⚡CUDA 12.4 ⚡Python 3.12 ➡️ link
-
[2024/09/17] ✨ NVIDIA TensorRT LLM Meetup ➡️ link
-
[2024/09/17] ✨ Accelerating LLM Inference at Databricks with TensorRT-LLM ➡️ link
-
[2024/09/17] ✨ TensorRT LLM @ Baseten ➡️ link
-
[2024/09/04] 🏎️🏎️🏎️ Best Practices for Tuning TensorRT LLM for Optimal Serving with BentoML ➡️ link
-
[2024/08/20] 🏎️SDXL with #Model Optimizer ⏱️⚡ 🏁 cache diffusion 🏁 quantization aware training 🏁 QLoRA 🏁 #Python 3.12 ➡️ link
-
[2024/08/13] 🐍 DIY Code Completion with #Mamba ⚡ #TensorRT #LLM for speed 🤖 NIM for ease ☁️ deploy anywhere ➡️ link
-
[2024/08/06] 🗫 Multilingual Challenge Accepted 🗫 🤖 #TensorRT #LLM boosts low-resource languages like Hebrew, Indonesian and Vietnamese ⚡➡️ link
-
[2024/07/30] Introducing🍊 @SliceXAI ELM Turbo 🤖 train ELM once ⚡ #TensorRT #LLM optimize ☁️ deploy anywhere ➡️ link
-
[2024/07/23] 👀 @AIatMeta Llama 3.1 405B trained on 16K NVIDIA H100s - inference is #TensorRT #LLM optimized ⚡ 🦙 400 tok/s - per node 🦙 37 tok/s - per user 🦙 1 node inference ➡️ link
-
[2024/07/09] Checklist to maximize multi-language performance of @meta #Llama3 with #TensorRT #LLM inference: ✅ MultiLingual ✅ NIM ✅ LoRA tuned adaptors➡️ Tech blog
-
[2024/07/02] Let the @MistralAI MoE tokens fly 📈 🚀 #Mixtral 8x7B with NVIDIA #TensorRT #LLM on #H100. ➡️ Tech blog
-
[2024/06/24] Enhanced with NVIDIA #TensorRT #LLM, @upstage.ai’s solar-10.7B-instruct is ready to power your developer projects through our API catalog 🏎️. ✨➡️ link
-
[2024/06/18] CYMI: 🤩 Stable Diffusion 3 dropped last week 🎊 🏎️ Speed up your SD3 with #TensorRT INT8 Quantization➡️ link
-
[2024/06/18] 🧰Deploying ComfyUI with TensorRT? Here’s your setup guide ➡️ link
-
[2024/06/11] ✨#TensorRT Weight-Stripped Engines ✨ Technical Deep Dive for serious coders ✅+99% compression ✅1 set of weights → ** GPUs ✅0 performance loss ✅** models…LLM, CNN, etc.➡️ link
-
[2024/06/04] ✨ #TensorRT and GeForce #RTX unlock ComfyUI SD superhero powers 🦸⚡ 🎥 Demo: ➡️ link 📗 DIY notebook: ➡️ link
-
[2024/05/28] ✨#TensorRT weight stripping for ResNet-50 ✨ ✅+99% compression ✅1 set of weights → ** GPUs\ ✅0 performance loss ✅** models…LLM, CNN, etc 👀 📚 DIY ➡️ link
-
[2024/05/21] ✨@modal_labs has the codes for serverless @AIatMeta Llama 3 on #TensorRT #LLM ✨👀 📚 Marvelous Modal Manual: Serverless TensorRT LLM (LLaMA 3 8B) | Modal Docs ➡️ link
-
[2024/05/08] NVIDIA Model Optimizer -- the newest member of the #TensorRT ecosystem is a library of post-training and training-in-the-loop model optimization techniques ✅quantization ✅sparsity ✅QAT ➡️ blog
-
[2024/05/07] 🦙🦙🦙 24,000 tokens per second 🛫Meta Llama 3 takes off with #TensorRT #LLM 📚➡️ link
-
[2024/02/06] 🚀 Speed up inference with SOTA quantization techniques in TRT-LLM
-
[2024/01/30] New XQA-kernel provides 2.4x more Llama-70B throughput within the same latency budget
-
[2023/12/04] Falcon-180B on a single H200 GPU with INT4 AWQ, and 6.7x faster Llama-70B over A100
-
[2023/11/27] SageMaker LMI now supports TensorRT LLM - improves throughput by 60%, compared to previous version
-
[2023/11/13] H200 achieves nearly 12,000 tok/sec on Llama2-13B
-
[2023/10/22] 🚀 RAG on Windows using TensorRT LLM and LlamaIndex 🦙
-
[2023/10/19] Getting Started Guide - Optimizing Inference on Large Language Models with NVIDIA TensorRT-LLM, Now Publicly Available
-
[2023/10/17] Large Language Models up to 4x Faster on RTX With TensorRT LLM for Windows
TensorRT LLM is an open-sourced library for optimizing Large Language Model (LLM) inference. It provides state-of-the-art optimizations, including custom attention kernels, inflight batching, paged KV caching, quantization (FP8, FP4, INT4 AWQ, INT8 SmoothQuant, ...), speculative decoding, and much more, to perform inference efficiently on NVIDIA GPUs.
Architected on PyTorch, TensorRT LLM provides a high-level Python LLM API that supports a wide range of inference setups - from single-GPU to multi-GPU or multi-node deployments. It includes built-in support for various parallelism strategies and advanced features. The LLM API integrates seamlessly with the broader inference ecosystem, including NVIDIA Dynamo and the Triton Inference Server.
TensorRT LLM is designed to be modular and easy to modify. Its PyTorch-native architecture allows developers to experiment with the runtime or extend functionality. Several popular models are also pre-defined and can be customized using native PyTorch code, making it easy to adapt the system to specific needs.
To get started with TensorRT-LLM, visit our documentation:
- Quick Start Guide
- Installation Guide for Linux
- Installation Guide for Grace Hopper
- Supported Hardware, Models, and other Software
- Benchmarking Performance
- Release Notes
Deprecation is used to inform developers that some APIs and tools are no longer recommended for use. Beginning with version 1.0, TensorRT LLM has the following deprecation policy:
- Communication of Deprecation
- Deprecation notices are documented in the Release Notes.
- Deprecated APIs, methods, classes, or parameters include a statement in the source code indicating when they were deprecated.
- If used, deprecated methods, classes, or parameters issue runtime deprecation warnings.
- Migration Period
- TensorRT LLM provides a 3-month migration period after deprecation.
- During this period, deprecated APIs, tools, or parameters continue to work but trigger warnings.
- Scope of Deprecation
- Full API/Method/Class Deprecation: The entire API/method/class is marked for removal.
- Partial Deprecation: If only specific parameters of an API/method are deprecated (e.g., param1 in LLM.generate(param1, param2)), the method itself remains functional, but the deprecated parameters will be removed in a future release.
- Removal After Migration Period
- After the 3-month migration period ends, deprecated APIs, tools, or parameters are removed in a manner consistent with semantic versioning (major version changes may include breaking removals).
- Quantized models on Hugging Face: A growing collection of quantized (e.g., FP8, FP4) and optimized LLMs, including DeepSeek FP4, ready for fast inference with TensorRT LLM.
- NVIDIA Dynamo: A datacenter scale distributed inference serving framework that works seamlessly with TensorRT LLM.
- AutoDeploy: A beta backend for TensorRT LLM to simplify and accelerate the deployment of PyTorch models.
- WeChat Discussion Group: A real-time channel for TensorRT LLM Q&A and news.