



baha-crawler 是一個專門用來爬巴哈姆特各版資料的爬蟲模組。
baha-crawler is a web crawler module designed to scarp data from Bahamut Forum.
巴哈姆特是台灣最大的電玩討論區,也是許多台灣玩家不可不知的電玩資訊網站。 找了一下,似乎巴哈的爬蟲少之又少,更別說是用Javascript所寫的模組了。 本人為了在Node.js上爬巴哈姆特,乾脆就自己用javascript打造一個簡單的爬蟲模組,並且分享給大家使用。
Bahamut Forum is the most famous and biggest game forum in Taiwan and game plays are well-know forum.
Just search a while, Bahamut Forum crawler modules are not easy to be found especially written by javascript.
In order to scrap data from Bahamut Forum by Node.js,
I just create a simple Bahamut Forum crawler module by javascript and share it to everyone to use.
- 爬巴哈姆特任意版上資料。
Scraping posts of any board on 巴哈姆特 - 可以爬多頁資料。
Support to scrape pages in one time - 爬資料時,可選擇是否忽略置頂文。
Support to skip fixed upper posts - 爬的資料以單一帖發文為單位,其中包含該帖的主題及超連結。(其他資料如推文數、日期及作者等,因為個人目前用不到,所以尚未實作,有興趣歡迎fork and PR)
Scraped posts contain titles and hyperlinks.(Other data like authers, dates, likes,... are not implimented yet and welcome to fork send PR)
- 利用 npm 套件進行下載
Use npm to install
npm install @waynechang65/baha-crawler
- 在您的專案環境中,引用 baha-crawler模組。
Include @waynechang65/baha-crawler package in your project
const baha_crawler = require('@waynechang65/baha-crawler');- 接下來,用async函式包含下面幾行程式就搞定了。
Add programs below in an async function in your project
// *** Initialize ***
await baha_crawler.initialize();
// *** GetResult ***
let baha = await baha_crawler.getResults({
board: '23805',
pages: 3,
skipTPs: true
}); // ToS Board(23805), 3 pages, skip fixed upper posts
// *** Close ***
await baha_crawler.close();- 爬完的資料會透過函式 getResults() 回傳一個物件,裏面各陣列放著爬完的資料,結構如下:
Scraped data will be returned with an object by getResults() function, it shows below.
{ titles[], urls[] }- 從Github下載baha-crawler專案程式碼。
Clone baha-crawler from GitHub
git clone https://github.com/WayneChang65/baha-crawler.git
- 進入baha-crawler專案目錄
Get into baha-crawler directory
cd baha-crawler
- 下載跑範例程式所需要的環境組件
Install dependencies in the cloned baha-crawler folder
npm install
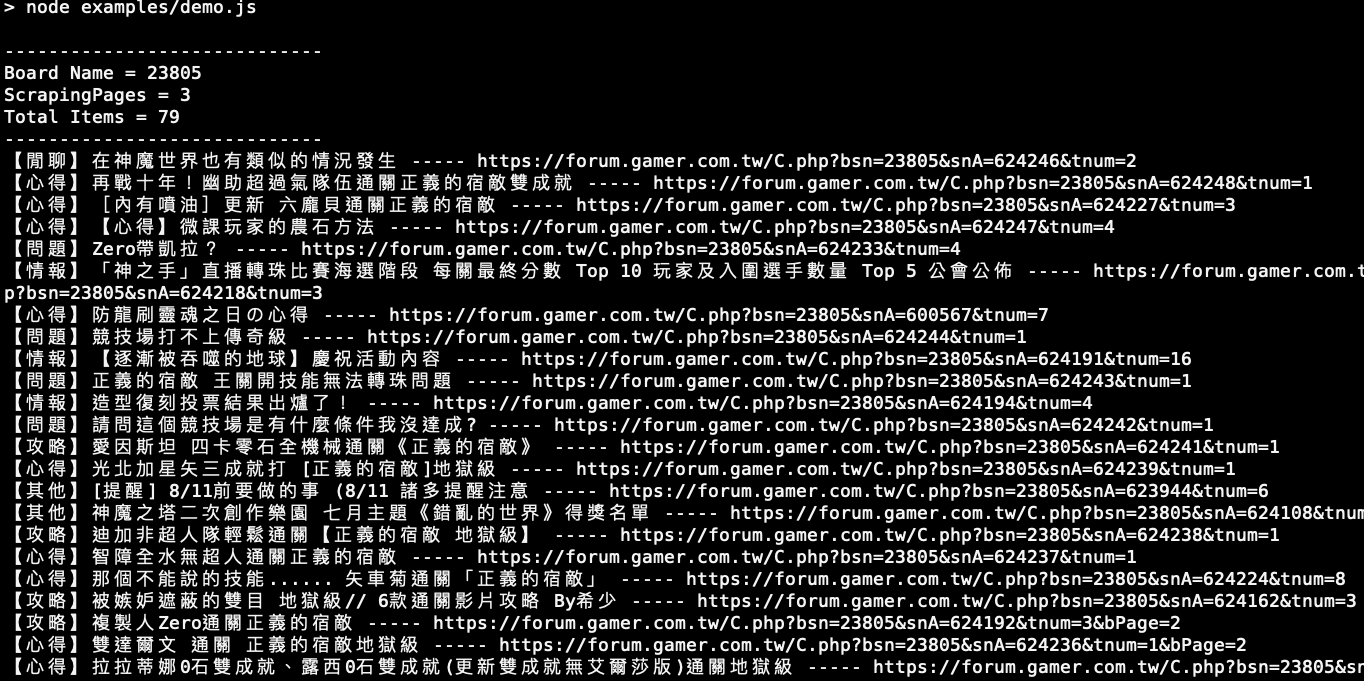
- 透過 npm 直接使用以下指令。(實際範例程式在 ./examples/demo.js)
Run it with npm. (the demo example is in ./examples/demo.js)
npm run start
- initialize(): 初始化物件, initialize baha-crawler object
- getResults(options): 開始爬資料,scrape data
options.board: 欲爬的巴哈版名編號, board name of baha
options.pages: 要爬幾頁, pages
options.skipTPs: 是否忽略置頂文, skip fixed upper posts or not
- close(): 關閉物件, close baha-crawler object
baha-crawler 雖然是一個小模組,但本人還是希望這個專案能夠持續進步!若有發現臭蟲(bug)或問題,請幫忙在Issue留言告知詳細情形。
歡迎共同開發。歡迎Pull Request,謝謝。:)
Even though baha-crawler is a small project, I hope it can be improving. If there is any issue, please comment and welcome to fork and send Pull Request. Thanks. :)