WARCannon was built to simplify and cheapify the process of 'grepping the internet'.
With WARCannon, you can:
- Build and test regex patterns against real Common Crawl data
- Easily load Common Crawl datasets for parallel processing
- Scale compute capabilities to asynchronously crunch through WARCs at frankly unreasonable capacity.
- Store and easily retrieve the results
WARCannon leverages clever use of AWS technologies to horizontally scale to any capacity, minimize cost through spot fleets and same-region data transfer, draw from S3 at incredible speeds (up to 100Gbps per node), parallelize across hundreds of CPU cores, report status via DynamoDB and CloudFront, and store results via S3.
In all, WARCannon can process multiple regular expression patterns across 400TB in a few hours for around $30.
The fastest and easiest way to get up and running is to use the AWS CloudShell. Just paste this one-liner:
source <(curl https://raw.githubusercontent.com/c6fc/warcannon/master/cloudshell/deploy.sh)If you want to use a non-master branch of WARCannon, just type:
export GIT_BRANCH=branch_name
source <(curl https://raw.githubusercontent.com/c6fc/warcannon/$GIT_BRANCH/cloudshell/deploy.sh)Note: CloudShell deployment uses ephemeral storage, which means custom regex patterns will be lost when the CloudShell exits. If you are going to use WARCannon frequently, I recommend using the 'Local Installation' below.
WARCannon requires that you have the following installed:
- awscli (v2)
- cmake3
- node.js (v17.0.1+)
ProTip: To keep things clean and distinct from other things you may have in AWS, it's STRONGLY recommended that you deploy WARCannon in a fresh account. You can create a new account easily from the 'Organizations' console in AWS. By 'STRONGLY recommended', I mean 'seriously don't install this next to other stuff'.
First, clone the repo and copy the example settings.
$ git clone [email protected]:c6fc/warcannon.git
$ cd warcannon
warcannon$ cp settings.json.sample settings.jsonEdit settings.json to taste:
Required settings
nodeInstanceType: An array of instance types to use for parallel processing. 'c'-types are best value for this purpose, and any size can be used.["c5n.18xlarge"]is the recommended value for true campaigns.nodeCapacity: The number of nodes to request during parallel processing. The resulting nodes will be an arbitrary distribution of thenodeInstanceTypesyou specify.nodeParallelism: The number of simultaneous WARCs to process per vCPU.2is a good number here. If nodes have insufficient RAM to run at this level of parallelism (as you might encounter with 'c'-type instances), they'll run at the highest safe parallelism instead.nodeMaxDuration: The maximum lifespan of compute nodes in seconds. Nodes will be automatically terminated after this time if the job has still not completed. Default value is 24 hours.
Optional settings (leave them out entirely if unused)
sshKeyName: The name of an EC2 SSH Key that already exists in us-east-1.allowSSHFrom: A CIDR mask to allow SSH from. Typically this will be<yourpublicip>/32
To install, run this:
$ npm install
$ npm link
$ warcannon deployRunning a campaign in WARCannon uses a simple, easy-to-follow workflow that can be best described in these few steps:
- Deploy the infrastructure:
warcannon deploy - Develop, then test regex patterns locally:
warcannon testLocal -s - Verify regex patterns in AWS via Lambda:
warcannon test - Show available crawls:
warcannon list 2022 - Populate the queue with the crawl of your choice:
warcannon populate 2022-21 - Execute the campaign:
warcannon fire - Wait for the campaign to finish, then retrieve the results from S3 with
warcannon syncResults
Read on for a more detailed understanding of each step.
WARCannon is fed by Common Crawl via the AWS Open Data program. Common Crawl is unique in that the data retrieved by their spiders not only captures website text, but also other text-based content like JavaScript, TypeScript, full HTML, CSS, etc. By constructing suitable Regular Expressions capable of identifying unique components, researchers can identify websites by the technologies they use, and do so without ever touching the website themselves. The problem is that this requires parsing hundreds of terabytes of data, which is a tall order no matter what resources you have at your disposal. Fortunately WARCannon has several tools you can use to get this done!
Grepping the internet isn't for the faint of heart, but starting with an effective seive is the first start. WARCannon supports this by enabling local verification of regular expressions against real Common Crawl data. First, open lambda_functions/warcannon/matches.js and modify the regex_patterns object to include the regular expressions you wish to use in name: pattern format. Here's an example from the default search set:
exports.regex_patterns = {
"access_key_id": /(\'A|"A)(SIA|KIA|IDA|ROA)[JI][A-Z0-9]{14}[AQ][\'"]/g,
};Strings matching this expression will be saved under the corresponding key in the results; access_key_id in this case. Protip: Use RegExr with the 'JavaScript' format to build and test regular expressions against known-good matches.
You also have the option of only capturing results from specified domains. To do this, simply populate the domains array with the FQDNs that you wish to include. It is recommended that you leave this empty [] since it's almost never worthwhile (the processing effort saved is very small), but it can be useful in some niche cases.
exports.domains = ["example1.com", "example2.com"];Once the matches.js is populated, run the following command:
warcannon$ warcannon testLocal -sYou can optionally add a path to a WARC in the commoncrawl S3 bucket if you'd like, but a hardcoded default will be used otherwise.
WARCannon will stream process the WARC file (or download it entirely if you omit -s) to find your configured matches. WARCannon will save the results to the ~/.warcannon/ folder when you interrupt with ctrl+c or when the processing finishes. This makes it easy to test common matches very rapidly with minimal bandwidth.
On top of everything else, WARCannon will attempt to evaluate the total compute cost of your regular expressions when run locally. This way, you can be informed if a given regular expression will significantly impact performance before you execute your campaign.
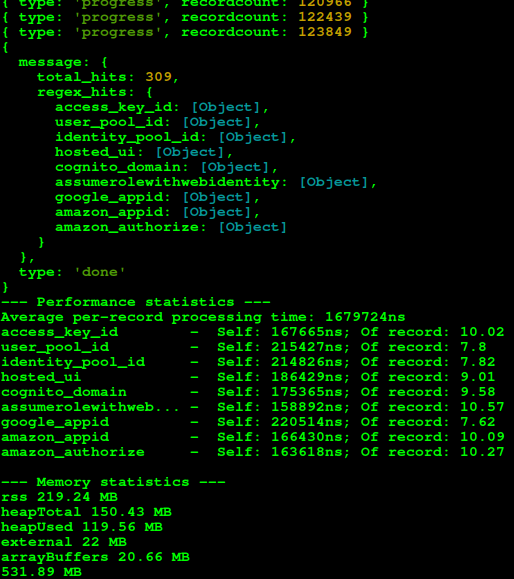
Sometimes a simple regex pattern isn't sufficient on its own, and you need some additional steps to ensure you're returning the right information. In this case, simply adding a function to the exports.custom_functions object with the same key name allows you to perform any additional processing you see fit.
exports.regex_patterns = {
"access_key_id": /(\'A|"A)(SIA|KIA|IDA|ROA)[JI][A-Z0-9]{14}[AQ][\'"]/g,
};
exports.custom_functions = {
"access_key_id": function(match) {
// Ignore matches with 'EXAMPLE' in the text, since this is common for documentation.
if (match.text(/EXAMPLE/) != null) {
// Returning a boolean 'false' discards the match.
return false
}
}
}Note: WARCannon is meant to crunch through text at stupid speeds. While it's certainly possible to perform any type of operation you'd like, adding high-latency custom functions such as network calls can significantly increase processing time and costs. Network calls could also result in LOTS of calls against a website, which could get you in trouble. Be smart about how you use these functions.
The costs of AWS can be anxiety-inducing, especially when you're only looking to do some research. WARCannon is built to allow both one-off executions in addition to full campaigns, so you can be confident in the results you'll get back. Once you're happy with the results you get with testLocal, you can deploy your updated matches and run a cloud-backed test easily:
warcannon$ warcannon deploy
warcannon$ warcannon testAgain, you can optionally include a WARC Path if you'd like, though it's not required.
This will synchronously execute a Lambda function with the regular expressions you've configured, and immediately return the results. This process takes about 2.5 minutes, so don't be afraid to wait while it does its magic.
Once you're happy with the results you get in Lambda, you're ready to grep the internet for real. We'll first go over some basic housekeeping, then kick it off.
WARCannon uses AWS Simple Queue Service to distribute work to the compute nodes. To ensure that your results aren't tainted with any prior runs, you can tell WARCannon to empty the queue:
warcannon$ warcannon emptyQueue
[+] Cleared [ 15 ] messages from the queueYou can then verify the state of the queue:
warcannon$ warcannon status
Deployed: [ YES ]; SQS Status: [ EMPTY ]
Job Status: [ INACTIVE ]
Active job url: https://d201offlnmhkmd.cloudfront.netVerify the following before proceeding:
- The SQS Queue is empty
- The job status is 'INACTIVE'
In order to create the queue messages that the compute nodes will consume, you must first populate SQS with crawl data. WARCannon has several commands to help with this, starting with the ability to show the available scans. In this case, let's look at the scans available for the year 2021:
warcannon$ warcannon list 2021
CC-MAIN-2021-04
CC-MAIN-2021-10We have two scans matching the string "2021" to work with. We can now instruct WARCannon to populate the queue based on one of these scans. This time, we need to provide a parameter that uniquely identifies one of the scans. "2021-04" will do the trick. We could choose to populate only a partial scan by also specifying a number of chunks and a chunk size, but we'll skip that for now.
warcannon$ warcannon populate 2021-04
{Created 799 chunks of 100 from 79840 available segments"
"StatusCode": 200,
"ExecutedVersion": "$LATEST"
}During deployment, WARCannon automatically provisions a database (warcannon_commoncrawl) and workgroup (warcannon) in Athena that can be used to rapidly query information from CommonCrawl. This can be especially useful for populating sparse campaigns based on certain queries. For example, the following query will search for WARCs that contain responses from 'example.com'
SELECT
warc_filename,
COUNT(url_path) as num
FROM
warcannon_commoncrawl.ccindex
WHERE
subset = 'warc' AND
url_host_registered_domain IN ('example.com') AND
crawl = 'CC-MAIN-2021-04'
GROUP BY warc_filename
ORDER BY num DESCYou can use the Athena console to fine-tune your results, but you must run the query from the WARCannon command line if you intend to populate a job with it:
warcannon queryAthena "SELECT warc_filename, COUNT(url_path) as num FROM warcannon_commoncrawl.ccindex WHERE subset = 'warc' AND url_host_registered_domain IN ('example.com') AND crawl = 'CC-MAIN-2021-04' GROUP BY warc_filename ORDER BY num DESC"
[+] Query Exec Id: 0319486e-1846-491c-badf-2e23ae213974 .. SUCCEEDED
WARCannon can then use the results of a query to populate the queue, and does so based on the warc_filename column from the resultset. As such, it's recommended that you either group by this column or use distinct() to avoid duplicates. WARCannon will throw an error if this field isn't present. Populate the queue with Athena results by passing the Query Execution ID to the populateAthena command.
warcannon populateAthena 0319486e-1846-491c-badf-2e23ae213974
{Created 26 chunks of 10 from 251 available segments"
"StatusCode": 200,
"ExecutedVersion": "$LATEST"
}Note: While populating a sparse job for a single domain might seem like a good idea, it often isn't. The responses from a single domain tend to be spread widely across a large subset of WARCs. This can be seen clearly using the example query above to see that of the ~150,000 records in each WARC, the largest single hit for moderate-sized websites can be in the single-digits.
With the queue populated, we're ready to fire. WARCannon will do a few sanity checks to ensure everything is in order, then show you the configuration of the campaign and give you one last opportunity to abort before you finalize the order.
warcannon$ warcannon fire
[!] This will request [ 6 ] spot instances of type [ m5n.24xlarge, m5dn.24xlarge ]
lasting for [ 86400 ] seconds.
To change this, edit your settings in settings.json and run warcannon deploy
--> Ready to fire? [Yes]: Pull the trigger by responding with 'Yes'.
--> Ready to fire? [Yes]: Yes
{
"SpotFleetRequestId": "sfr-03dd32b8-51f7-4c8e-802b-a702fc3c8c95"
}
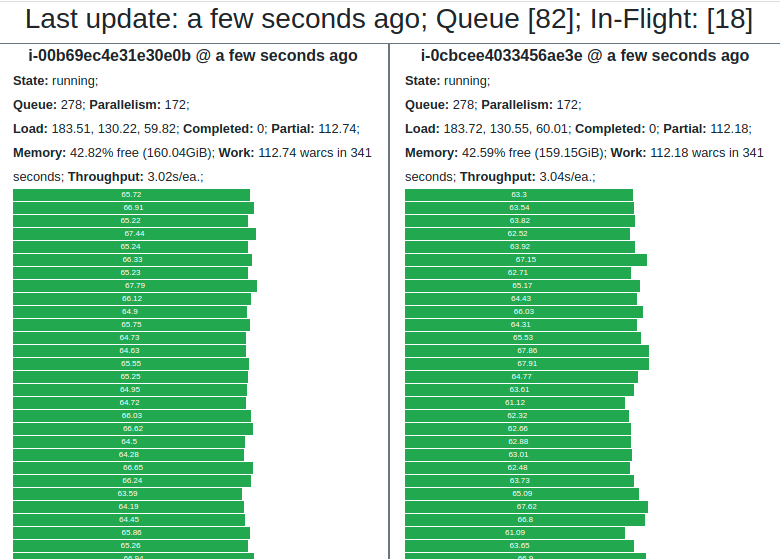
[+] Spot fleet request has been sent, and nodes should start coming online within ~5 minutes.
Monitor node status and progress at https://d201offlnmhkmd.cloudfront.netThe response includes a link to your unique status URL, where you can monitor the progress of your campaign and the performance of each node.
WARCannon results are stored in S3 in JSON format, broken down by each node responsible for producing the results. Athena results are stored in the same bucket under the /athena/ prefix. You can sync the results of a campaign to the ~/.warcannon/ folder on your local machine using the syncResults command.
warcannon syncResults
sync: s3://warcannon-results-202...
sync: s3://warcannon-results-202...
sync: s3://warcannon-results-202...
...You can then empty the results buckets with clearResults
warcannon clearResults
delete: s3://warcannon-results-202...
delete: s3://warcannon-results-202...
delete: s3://warcannon-results-202...
...
[+] Deleted [ 21 ] files from S3.Have questions, need help, want to contribute or brag about a win? Come hang out on Discord!
