{kind=link}
This readme describes the FTR questionnaire, as well as providing a guide to how to recreate the methods reported in Robertson & Roberts (2020) and Robertson, Roberts, Dunbar, & Majid (2020). Researchers interested in using the FTR questionnaire should consult these publications, where it is fully described. The description in this repository is designed to be useful in conjunction with these publications.
The FTR questionnaire is a language elicitation tool, designed to elicit speakers use of future time referring language. It may be used for a variety of purposes, including linguistic typology and psychological, and behavioural economics experiments.
It is designed to elicit usage across a range of: temporal distances from speaker "now", speaker certainty (numerically represented in percentages, as well as categorically, i.e. "certain","neutral","uncertain"), and FTR modes, i.e. whether the context involved a prediction, an intention, or a schedule.
The version of the FTR questionnaire which we recommend potentially interested researchers to use is given in ftr_questionnaire/questionnaire_master.xlsx and ftr_questionnaire/questionnaire_long.xlsx. These files contain identical data. The only difference is questionnaire_master.xlsx is in wide format while questionnaire_long.xlsx is in long format. The file code/questions_wide_to_long.py builds the long format from the master. Researchers seeking to change anything should therefore edit questionnaire_master.xlsx and then use questions_wide_to_long.py to build a new long file.
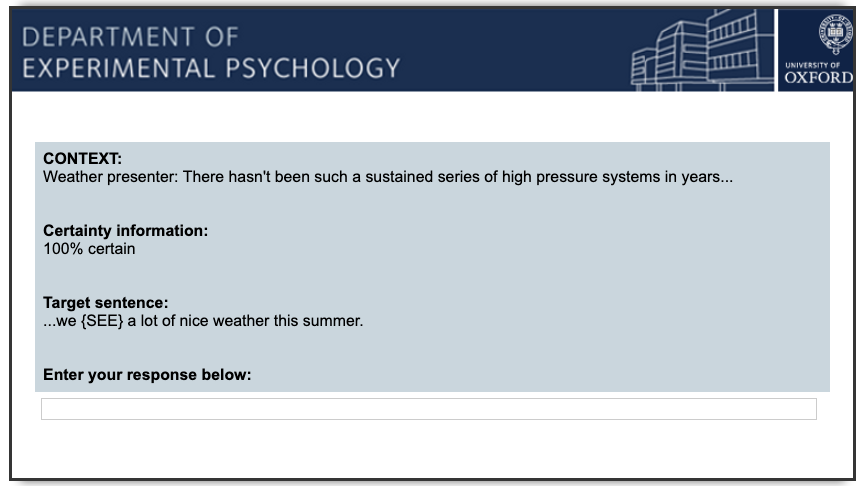
The script code/write_FTR_block.py is used to create the files in qualtrics_question_blocks/, which can be uploaded to the qualtrics survey hosting platform to create a usable survey block. This creates a usable block of questions which are formatted like this:
Older versions of the FTR elicitation questionnaire are given in ftr_questionnaire/drafts_e1_to_e4/questions.xlsx and ftr_questionnaire/drafts_e1_to_e4/questions_e3.xlsx. These files contain versions of the FTR questionnaire which were used to generate the data presented in Robertson & Roberts (2020) and Robertson, Roberts, Dunbar, & Majid (2020). A guide to how the items relate to the the data presented therein is given in the ftr_questionnaire/drafts_e1_to_e4/README.md in. It is not recommended researchers use these draft versions, as they contain significant inbalances between independent variables. They are included here for historical and transparency purposes.
The remainder of this readme will focus on explaining the significance of the columns in the recommended version of the FTR questionnaire. With reference to ftr_questionnaire/questionnaire_long.xlsx, the columns denote the following:
frame_distance: Denotes how far into the future from speaker "now" is explicitly stated or implied by each context.first_person: Only relevant whenftr_mode == intention OR scheduling, indexes whether the context is in the first, second, or third person.keep: Constant, left over from the writing process.ftr_mode: Indexes whether the context is a prediction, intention, or schedule (see: Dahl, 2000).rank: A subjective ranking of which questions the researchers thought were best (within eachframe_distance.notes: Constant, left over from the writing process.copy_edited: Constant, left over from the writing process.old_uneek: A key which is designed to relate updated questions back to earlier versions of the FTR questionnaire. Should not be used, as many questions may have been altered in the updating process even though they share the sameold_uneekkey as in previous FTR questionnaire versions.word: The word which is used to denote the "certainty information" given to participants. Is usually certain/zeker, but is decided whenftr_mode == intention.question: The actual quesion. Context is given in the[square brackets], target sentence afterwards.uneeka question index number which is unique acrosslanguage, andcertainty, conditions. That is to say, questions with the samequestion_formbut which are altered to acommodate differentcertaintyconditions will have differentuneekindexes. Likewise, the same question given in English and Dutch will have different values ofuneek.certainty: Numerical representation of "certainty information" designed to be given in percentages. Always100in thecertaincondition, one of[40,50,60]in theuncertaincondition, and not given[-999]in theneutralcondition.question_form: Indexes the general form of the question, i.e. is not unique acrosslanguage, andcertainty, conditions. That is to say, which are generally similar but are altered to acommodate differentcertaintyconditions will have the same value ofquestion_form. Likewise, the same question given in English and Dutch will have the same value ofquestion_form.language: Indexes the language of the question (english or dutch).probability: qualitative categorical representation of thecertaintycondition. In theneutralcondition no certainty information is given, in thecertaincondition, participants are informed they should imagine they are100%certain, and in theuncertaincondition, participants are informed should imagine they are one of[40,50,60]%certain. Since there is oneintentionandschedulingquestion perframe_distance, these are given50%certainty in theuncertaincondition. Since there are 3predictionquestions perframe_distancethese are given one each at40%,50%,60%certainty.question_no: Index which is unique across levels ofprobabilitybut not unique across levels oflanguage, i.e. within a level ofquestion_form, a question which had been altered to acommdate different levels of certainty information would have different value ofquestion_no, but value would be the same across translated versions of the same question.question_eng: An English translation of each question (the same asquestionwhenlanguage == english).
`