两人组队形式完成交通科技创新竞赛实验训练,是课程期末成绩的重要评价标准,请认真对待!
Note
创新是最大的加分项!
作业鼓励交流,但是禁止抄袭
自行拍一段30s左右的视频,将识别结果存成 txt,csv 或其他格式,用于后续分析,对于视频每一帧图像 包括:
- 当前帧数(第几帧)
- 每一个目标:类别,置信度,boundingbox 对角点坐标 (左上与右下角点坐标)

以下是往届自定义目标的示例:
- 统计当前帧每个车道车辆数,并实时显示。(拉取四边形代表某条车道范 围,判断该四边形内有多少各目标。)
- 统计每条车道累计车辆数。(划定虚拟检测线 or 线圈,经过则计数。)
根据检测结果与目标,在实验结果中进一步分析。(如讨论交通量、光照、遮挡,使用的算法等影响因素对结果的影响,该部分同样纳入作业评定中。)
阅读YOLOv3 目标检测算法《YOLO: Real-Time Object Detection》的论文和官方权重地址,推荐阅读教程:

压缩包包含以下内容,在四周之后的24:00之前发送至[email protected]
/src:可执行的源代码
/video:原始视频和识别后的视频
/output:识别结果文件
/report:分析报告(实验目标、方法、结果、讨论、参考)
wget https://pjreddie.com/media/files/yolov3.weights # 保存权重到根目录
python detect.py #图片识别
python video.py --video run.mp4 #视频识别
示例代码一(line 160):对output的结果进行计数,并write到frame上
示例代码二(line 174):判断是否在四边形区域中,可以作为虚拟线圈和车道流量识别参考

Accompanying code for Paperspace tutorial series "How to Implement YOLO v3 Object Detector from Scratch"
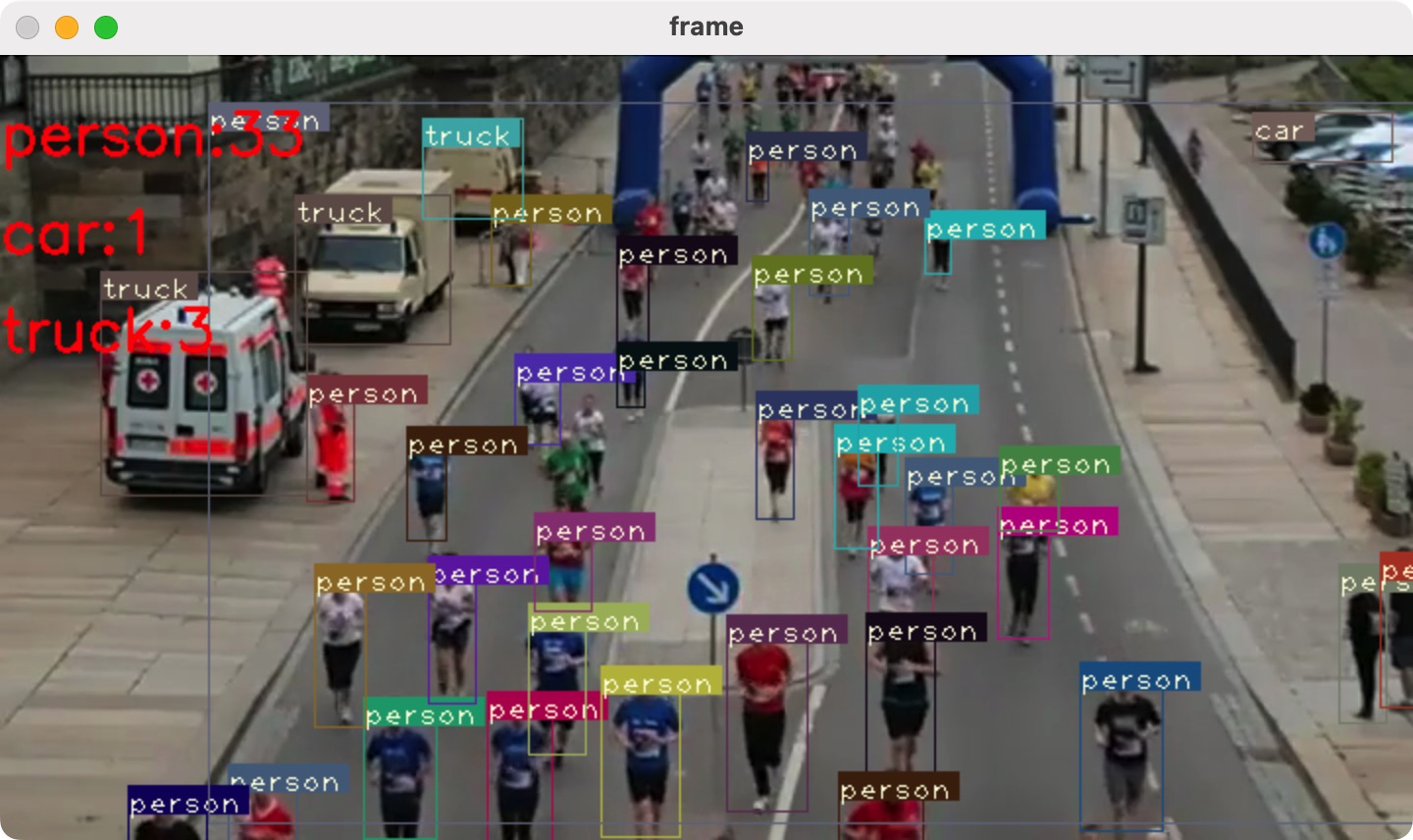
Here's what a typical output of the detector will look like ;)
{kind=link}
This code is only mean't as a companion to the tutorial series and won't be updated. If you want to have a look at the ever updating YOLO v3 code, go to my other repo at https://github.com/ayooshkathuria/pytorch-yolo-v3
输出结果:

如果有更进一步的希望可以训练自己的YOLOv3权重的,可以参考GitHub上的其他教程(不推荐),参考仓库:[PyTorch-YOLOv3_kiki]https://github.com/kikizxd/PyTorch-YOLOv3_kiki
Cheers