建立本仓库的核心在于:
- 交通学院人工智能导论课程提供作业问题
- 为师弟师妹们提供学习指导,为了帮助大家更快速的融入,这里为大家推荐一些课程和资料。
| 课程链接 | 课程简介 | 课程备注 |
|---|---|---|
| CS 188:introduction to AI | 人工智能导论基础,从行为流派介绍如何实现帮助人们工作的人工智能。从搜索问题、约束规划问题、马尔科夫决策过程、强化学习、机器学习、神经网络等内容 | 课程内容为科普性,内容简单,其中吃豆人小游戏作为本次作业1 |
| CS 61A: Structure and Interpretation of Computer Programs | 程序构造与运行原理,课程地位类似于同济本科学习的程序设计,这里主要以 Python 出发介绍程序设计中的函数式编程、控制语句、类和对象等等 | 推荐观看并做完课程,提升自身的代码能力 |
| CS 285:Deep Reinforcement Learning | Sergey Levine老师的深度强化学习基础,从深度强化学习领域的基础知识到最先进展的延伸,非常值得学习 | 难度较高,推荐观看和写完作业 |
| CS229: Machine Learning | Andrew Wu(吴恩达)老师的机器学习课程,主要从概率统计和数学推导介绍机器学习中模型基本原理,包括但不限于广义线性模型、聚类模型、树模型、集成学习理论等 | 非常推荐观看,同时把提供的课程作业给做了 |
| 《动手学深度学习》 | 李沐老师的深度学习课程,基于 PyTorch 编程为大家介绍卷积神经网络、循环神经网络、注意力机制带来的计算机视觉、自然语言处理中的常见模型原理 | 非常推荐观看,也记得关注李沐老师的 B 站 |
| 优化课程 | 待定 | 待定 |
本部分目录为[search],更详细的材料可以阅读
搜索问题(Search problem)是已知一个问题的初始状态和目标状态,希望找到一个操作序列来是的原问题的状态能从初始状态转移到目标状态,搜索问题的基本要素:
a. 初始状态
b. 转移函数,从当前状态输出下一个状态
c. 目标验证,是否达到最终的目标状态
d. 代价函数,状态转移需要的代驾
搜索算法(Search algorithm)指的是利用计算机的高性能来有目的穷举一个问题解空间的部分或者所有可能情况,从而求出对于问题的解的一种方法,常见的搜索算法包括枚举算法、深度优先、广度有限、A star算法、回溯算法、蒙特卡洛树搜索等等。搜索算法的基本过程:
a. 从初始或者目标状态出发
b. 扫描操作的算子,来得到候选状态
c. 检查是否为最终状态
a) 满足,则得到解
b) 不满足,则将新状态作为当前状态,进行搜索
选择一个你身边的示例,抽象为搜索问题,并思考吃豆人游戏中的状态、动作、奖励是什么,运行下列命令开始运行 pacman
python pacman.py自行学习下列算法,写出中文伪代码,利用[class SearchProble]的提供的 API 基础上时在[Search.py]中利用代码实现:
- 深度优先搜索 (Deep Search First,DFS)
- 广度有限搜索 (Board Search First,BFS)
- 一致代价搜索 (Uniform Cost Search,UCS)
- A star 搜索
允许下列代码可以观察你的效果
python pacman.py -l mediumMaze -p SearchAgent -a fn=dfs完成搜索算法基础上,修改 [SearchAgents.py] 实现吃豆人游戏(Corner problem) 的求解
- 完善Corner problem
- 利用 DFS 吃掉角落的豆
- 利用启发式(heuristic)
本章节对应目录为 p2_machine_learning
尝试利用机器学习对给定的数据集进行异常点检测。可以尝试:
- 高斯模型 GMM
- 孤立森林
- 基于密度的方法
其中数据说明
| 变量 | 注释 |
|---|---|
| X.npy | 待标记点坐标 |
| X_val.npy | 已标记点坐标 |
| yval.npy | 已标记点标签 |

离散选择模型主要用于建模决策者在有限多个选择中做出选择的过程。它基于效用最大化理论,即假设每个选择对应一个效用,决策者倾向于选择带来最大效用的选项。典型的离散选择模型包括二元选择模型(如Logit、Probit模型)和多项选择模型(如多项Logit模型)。这些模型在交通运输、市场营销、经济学等领域中广泛应用,用于解释个体如何在选项之间做出决策。
Dataset 中给出了上海定制公交线路开关的面板数据,其中字段信息详细可以查询该论文,其中 label 表示的线路开关状态,请建立多个模型对比分析其中的影响因素:
- 利用离散选择库 Biogeme构建合适的逻辑回归模型
- 基于树模型构建特征重要性的解释,至少实现下列一个:Ada boost、LightGBM、XGBoost、CatBoost 等
- 基于因果理论分析因果效应,至少实现下列一个
- 基于 uplift 模型的因果效应辨识
- 基于约束的因果关系发现
- 基于 Null importance 的因果反驳
牛顿法(英语:Newton's method)又称为牛顿-拉弗森方法(英语:Newton-Raphson method),它是一种在实数域和复数域上近似求解方程的方法。
- 选择一个接近函数零点的 x
- 根据对应点和斜率更新 x
- 迭代收敛得到零点
完成 new_ton 脚本中的 update 函数逻辑,同时增加可视化过程
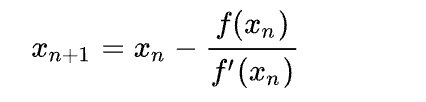
本章节对应目录为 deeplearning,更多详细信息可以参考阅读:https://zh-v1.d2l.ai/index.html
深度学习是人工智能和机器学习的一个分支。其主要希望利用多层的人工神经网络来实现特定的任务目标,包括但不限于目标检测、语音识别、语音翻译、文本生成、图文匹配等功能。其优点是可以自动的是图像、视频、文本、音频中自动的学习特征,而不需要引入人类领域的知识。
CV 文件夹中展示如何使用MLP 和 CNN 来实现手写数据集的识别,现在希望你做下列优化:
a. 从数据层面,解释 PCA 分别在 MLP 和 CNN 的是否起作用的原因?
b. 自定义模型,参考AlextNet网络架构- ImageNet Classification with Deep Convolutional Neural Networks 设计你的卷积模型,并解释为什么 AlexNet 解决了“深度卷积”网络学习的什么问题?
c. 对比分析不同的效果?
PS:可以考虑使用PyTorch来替换上述的Tensorflow代码
NLP 文件夹下的 prebert.ipynb 初步完成了基于transformer 库的 BERT-BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 微调方案来实现情绪识别的方案。其中数据集处理、模型训练已经完善,需要你完成
a. 在原有 BERT 模型上增加一层 MLP 来满足二分类任务,即需要修改BertSST2Model 的信息,此处需要学习 PyTorch.module实验
b. 编写网络训练过程,以及如何定期保存模型,在训练循环中
c. 介绍 BERT 模型中的损失函数是什么?为什么不用MSE 作为损失函数?
利用生成对抗网络 GAN - Generative Adversarial Networks 生成动漫头像,数据集下载地址,本题任务有
a. 理解GAN目录文件,绘制出训练结果
b. 解释 GAN 出现维度坍塌的问题,并尝试对baseline 进行修改
深度强化学习侧重于如何基于环境行动并最大化预期收益,随着深度学习发展,原有的强化学习算法中的智能体可以有更高的感知能力,配合自身算法的“探索-利用”来实现对复杂问题的决策和解决。
DQN 是经典的深度强化学习算法,后人对其有诸多的改进,这里要求阅读其中Rainbow: Combining Improvements in Deep Reinforcement Learning.,增强理解
由于本文处理的是视频,因此可以考虑将状态以图像的方式传入,并增加 CNN 模块来进行图像提取,减少模型的参数,并提升网络的泛化性能。因此需要 Q-Network 进行修改
Pyomo(Python Optimization Modeling Objects):优化建模对象,支持复杂优化应用的数学模型的建立和分析,是一种功能齐全的高级编程语言,包含一组丰富的支持库;建模的过程是科学研究、工程和商业许多方面的基本过程,建模涉及系统或现实世界对象的简化表示的制定。运筹优化问题通常求解包括精确求解和近似求解:
精确求解方法旨在寻找最优解,确保最终解是问题的全局最优解。它们在理论上能够保证最优解的正确性,适用于问题规模较小或结构良好的情况。常见求解器包括
- GLPK(GNU Linear Programmed Kit)是GNU维护一个线形规划工具包,对于求解大规模的额线性规划问题速度缓慢
- CPLEX,是IBM开发的商业线性规划求解器,可以求解LP,QP,QCQP,SOCP等四类基本问题和对应的MIP,社区版仅支持低于1000变量的使用,教育版无限制,建模时间长,但是求解速度非常快
- Gurobi,是CPLEX团队创始人重新创建的商业求解器,和cplex速度差别不大,相对来说比Cplex好一点
- OR-Tools,谷歌开发的商业求解
近似求解方法(也称为启发式或元启发式方法)在理论上不保证最优解,但能够在合理时间内找到接近最优的解。它们常用于NP-hard问题或超大规模问题。
- GeatPY 高性能的Python遗传和进化算法工具箱。
假设你有 100 万美元要投资于三种资产(资产 1、资产 2 和资产 3),每种资产的预期回报率和风险如下表所示:
| 预期回报率 | 风险系数 | |
|---|---|---|
| 资产 1 | 10% | 0.5 |
| 资产 2 | 12% | 0.7 |
| 资产 3 | 8% | 0.4 |
目标是在总投资回报率不低于 105 的情况下,最小化总投资的风险,要求使用 Pyomo 建立并调用求解器优化该问题,输出每种资产的投资金额和最小化的风险值。
使用 GeatPy 求解 TSP 问题,进化算法的逻辑过程包括:
- 开始,初始化初始种群
- 开始迭代知道满足终止条件
- 计算种群中的适应度
- 开始进化,包括选择、重组和编译
- 得到下一代种群
- 结束条件
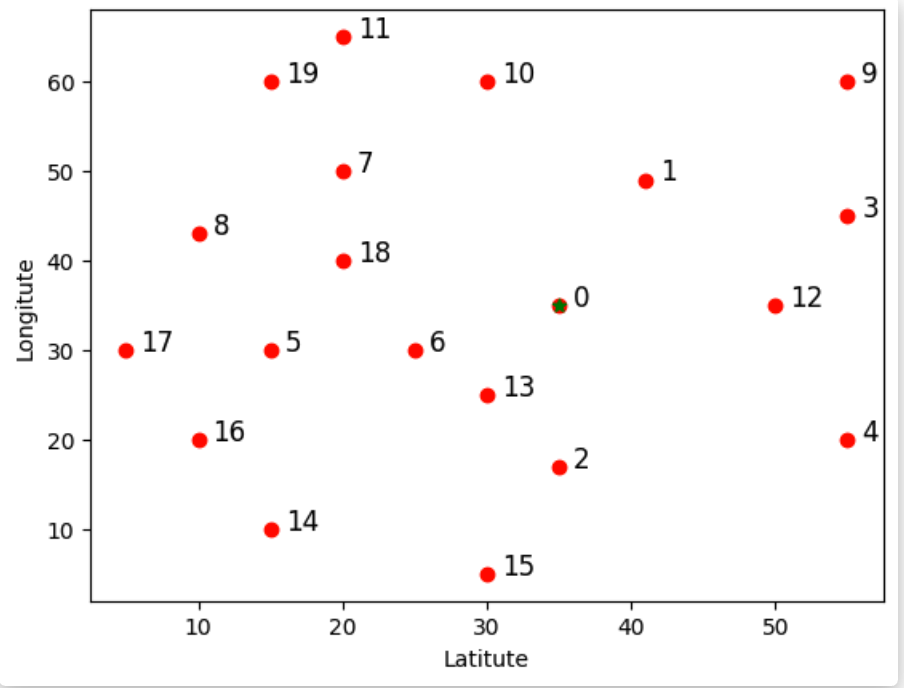
现在要求定义启发式方法求解下列的 TSP 问题,目标输出是最小路径