{kind=link}
{kind=link}
实际运行多线程后,发现经常decrypt失败,后来了解一下加密的原理才发现瞎忙一场。 咳,考虑不周,因为chacha是带状态的流加密,所以不能拆分成多线程,但是tinc默认就只有一个连接,所以如果不分块或者对连接动手的话,没啥用。 树莓派的AES性能又垃圾到不行,怎么办才好呢。
- 在线程中处理包
chacha20-poly1305不能多线程同时对一个流加解密。。所以。。
因为资源大部分都消耗在加密解密上,所以应该把加密解密分离到其他的线程。但是由于tinc本身是单线程设计的,因此其中的数据访问并没有进行多线程的保护。不过sptps协议设计的比较简单,而且本身很容易设计成异步执行,所以我是这样想的:
上半部分,处理sptps协议
Thread:
Thread pool: encrypt/decrypt
dequeue Thread: send a io request to libevent
sptps_receive_data -> in queue -> decrypt by thread pool -> dequeue
sptp_send_data -> in queue -> encrypt by thread pool -> dequeue
下半部分,main thread中收发包
dequeue(io notify)-> (main thread)io watch -> sptps callback
不过要注意的是,握手和其他明文包也需要按序列发送,所以也应该由thread pool来处理,但是协议中间不会发送有更新key什么的消息,我觉得只需要把DATA交给thread pool就行
使用sptps_speed 测试的结果, 比以前还慢了很多,感觉上是用pipe同步callback和dequeue的原因 想了一下,应该是sptps_speed的实现是一收一发,所以没有享受到多线程的增益,因为队列里最多就一个数据等待加密或者解密
-O3
chk@T620:~/tinc-local-offload-thread/src % ./sptps_speed 1
Generating keys for 1 seconds: 4775.39 op/s
Ed25519 sign for 1 seconds: 4687.92 op/s
Ed25519 verify for 1 seconds: 1457.95 op/s
ECDH for 1 seconds: 1167.75 op/s
SPTPS/TCP authenticate for 1 seconds: 554.28 op/s
SPTPS/TCP transmit for 1 seconds: 637.49 Mbit/s
SPTPS/TCP MP transmit for 1 seconds: 504.10 Mbit/s
SPTPS/UDP authenticate for 1 seconds: 552.58 op/s
SPTPS/UDP transmit for 1 seconds: 642.62 Mbit/s
-O0
chk@T620:~/tinc-local-offload-thread/src % ./sptps_speed 1
Generating keys for 1 seconds: 2258.62 op/s
Ed25519 sign for 1 seconds: 2162.85 op/s
Ed25519 verify for 1 seconds: 824.04 op/s
ECDH for 1 seconds: 610.23 op/s
SPTPS/TCP authenticate for 1 seconds: 298.93 op/s
SPTPS/TCP transmit for 1 seconds: 205.14 Mbit/s
SPTPS/TCP MP transmit for 1 seconds: 279.38 Mbit/s
SPTPS/UDP authenticate for 1 seconds: 298.59 op/s
SPTPS/UDP transmit for 1 seconds: 205.06 Mbit/s
- 为本地路由的包增加一个type
发送sptps packet的时候,tinc会首先在本地route,寻找目标node,然后把(source, dest)放在压缩的packet前,这样下一跳收到包后就可以不解压直接根据dest id来确定是不是要转发到下一个节点。 如果dest id是自己则再路由一次,路由后可能发给自己或者发给别的节点(如果设置StrictSubnets,每个节点的路由表并非一定一致) 为了解决如下需求, 增加本地路由的feature:
- 想要每个节点的接口地址被广播,即不能设置StrictSubnets
- 根据目的IP来路由包到不同的节点,比如大陆地址只到大陆的节点,但是不能让tinc的路由表太大,否则遍历路由表会花费太多时间(foreach in splay tree)
具体实现:
- 增加route文件夹,里面每个文件用主机名命名,每一行都是一个subnet:x.x.x.x/prefixlen,tinc启动或reload时加载到lctire,成为本地路由表
- 在搜索tinc路由表之前,搜索本地路由表,如果找得到,则通过sptps协议发送,不再使用直接发送tcp及udp报文
- 节点收到sptps packet后,如果DSTID = myself,则直接发送到接口,不再做一次route
首先,请记住5月31日这个日子,防火墙从这一天开始彻底疯了。。。
对于国内外分流,我知道的方案有iptables,或者添加路由,当然如果是PC客户端的话,也可以用PAC。
-
使用路由的: https://github.com/FQrabbit/VPN-skip-China-route-Window
-
使用iptables的: https://github.com/houzhenggang/turn-socks-to-vpn
上面两种都可以配合chinadns来实现国内外流量分流。
下面是这里描述的另外一种方案
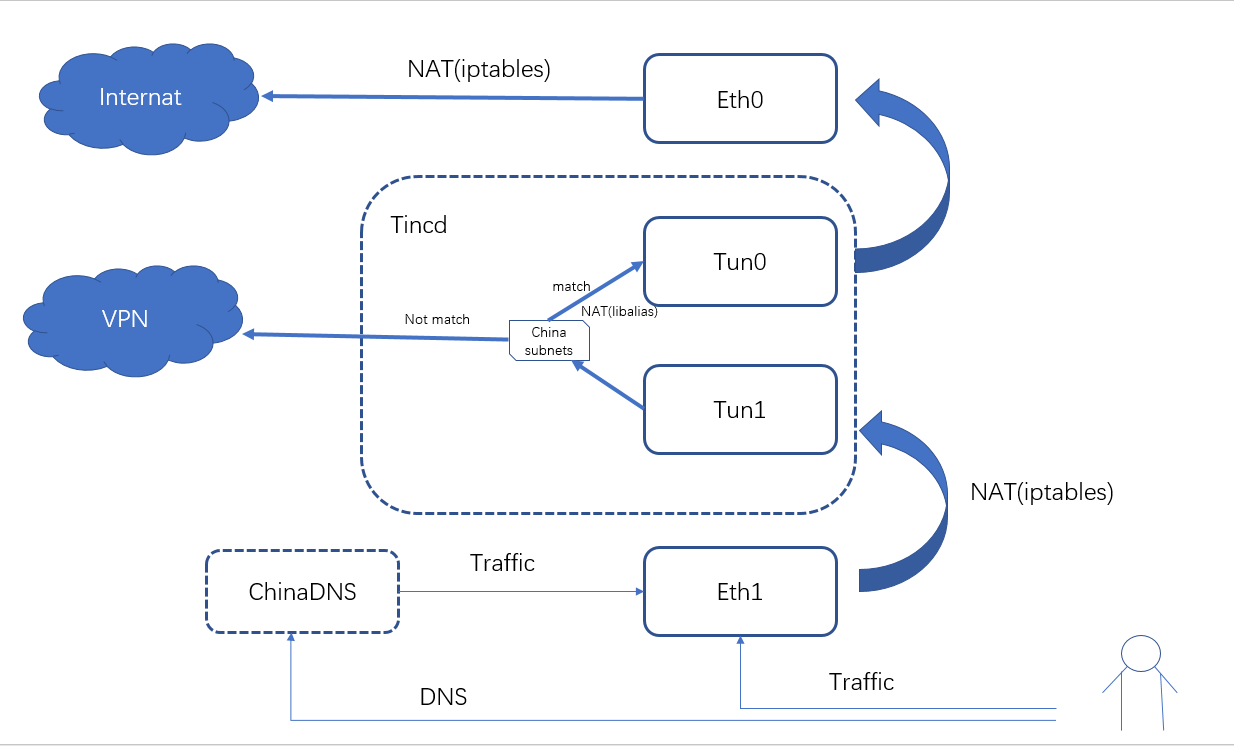
在tinc中启动两个接口,当tun0中接收到报文时,如果目标地址匹配china subnets的话,转发到另外一个接口,如果设置了NAT地址,则把源地址进行NAT后送出去。
国内流量的方向
eth1下的设备->eth1->tun1->tun0->eth0
国外流量的方向
eth1下的设备->eth1->tun1->VPN 服务器
配合chinaDNS(https://github.com/cherrot/gochinadns) 可以实现国内域名发送到国内地址, 国外域名发送到国外地址
修改的路由及iptables部分(iptables 做NAT,ip rule实现源地址路由):
# $INTERFACE = tun1
# $INTERFACELOCAL = tun0
ip route add default via 192.168.1.1 dev eth0 200
ip route add default dev $INTERFACE scope link table 500
ip rule add from 192.168.200.100 lookup 500
ip rule add from all iif $INTERFACELOCAL lookup 200
iptables -t nat -A POSTROUTING -o $INTERFACE -j MASQUERADE
iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE
修改的tinc代码:
- 增加tun1设备
- 使用https://github.com/chuckination/lctrie 来进行目标地址匹配(Intel 3205U测试,单线程匹配5000条国内子网表,大概10Mqps,对于大部分机器来说都不是瓶颈了)
- 移植freebsd下的libalias(https://wiki.freebsd.org/Libalias) 来执行NAT(不执行NAT也可以,但是iptables似乎无法正确在出口对tun0进来的包进行NAT)
- tinc-1.1pre17无法在freebsd链接libz,需要删除__nonull__的定义 (bug of tinc)
- lctrie 中的ip addr结构与tinc有冲突,用uint32_t 传递IP地址
- libalias 中的LIST_NEXT等宏在linux中未定义,引入freebsd的queue头文件
- libalias 中检测头文件是否包含的宏与linux头文件定义不一致
- libalias 中的ip, tcp, udp等结构与linux中定义不一致,引入宏定义 -DNO_FW_PUNCH -D_BSD_SOURCE -D__BSD_SOURCE -D__FAVOR_BSD
- chinadns 实现中的upstream DNS server会根据IP来决定是否Trusted,修改为全部Untrusted(因为需要使用内网dns服务器进行缓存)
最后的最后,如果使用源地址路由的话,请修改下面的系统配置:
# 不添加iptables出口NAT不正常
for x in `ls /proc/sys/net/ipv4/conf/*/accept_source_route`; do echo 1 > $x ; done
# 不添加则系统会丢弃tun0接收到的报文
for x in `ls /proc/sys/net/ipv4/conf/*/rp_filter`; do echo 0 > $x ; done
tun1 是本地卸载端口
tun0 为入口
/0 /1 /2 /3 /4 /5 /6 /7 /8 /9 /10
Load Average |||
Interface Traffic Peak Total
ng0 in 197.185 KB/s 204.577 KB/s 100.123 MB
out 4.938 MB/s 5.104 MB/s 1.323 GB
tun1 in 197.118 KB/s 204.297 KB/s 84.025 MB
out 5.669 MB/s 5.862 MB/s 654.152 MB
tun0 in 5.653 MB/s 5.846 MB/s 2.072 GB
out 209.493 KB/s 217.079 KB/s 176.669 MB
ue0.3 in 0.000 KB/s 1.372 KB/s 1.530 GB
out 0.000 KB/s 1.243 KB/s 1.447 GB
ue0 in 5.977 MB/s 6.188 MB/s 24.051 GB
out 5.210 MB/s 5.385 MB/s 24.024 GB
lo0 in 0.000 KB/s 0.000 KB/s 9.403 MB
out 0.000 KB/s 0.000 KB/s 9.403 MB
usb用的cpu多是因为树莓派的网口其实是挂在usb下面
基本上50Mbps就是极限了,本身网口也只是100M的
/0 /1 /2 /3 /4 /5 /6 /7 /8 /9 /10
Load Average |||||||
/0% /10 /20 /30 /40 /50 /60 /70 /80 /90 /100
root tincd XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
root idle XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
root usb XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
root idle XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
root idle XXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
root idle XXXXXXXXXXXXXXXXXXXXXXXXX
root rand_harve X
root intr X
基本上可以一直开着,打游戏延迟正常,淘宝优酷正常
ng0是pppoe接口,我一般用pppoe拨号来从PC连接到本地VPN,可以保证易用性和以及在PC上稳定的路由
ue0.3是提供vpn的vlan接口
至于如何让不同的设备来无缝连接VPN,又是另外一个故事了。
另外TAP方案已经放弃了(太过繁琐)
/0 /1 /2 /3 /4 /5 /6 /7 /8 /9 /10
Load Average
Interface Traffic Peak Total
ng0 in 0.179 KB/s 0.350 KB/s 7.424 MB
out 0.140 KB/s 2.591 KB/s 45.293 MB
tun1 in 0.132 KB/s 0.282 KB/s 4.928 GB
out 0.052 KB/s 0.119 KB/s 62.587 GB
tun0 in 0.140 KB/s 2.591 KB/s 100.533 GB
out 0.188 KB/s 0.836 KB/s 59.464 GB
ue0.3 in 0.000 KB/s 0.416 KB/s 10.125 GB
out 0.000 KB/s 0.323 KB/s 9.604 GB
ue0 in 0.673 KB/s 3.643 KB/s 174.907 GB
out 0.703 KB/s 3.599 KB/s 194.651 GB
将tun0 修改成tap与出口网口进行桥接,内置dhcp client,就不再需要源地址路由了。
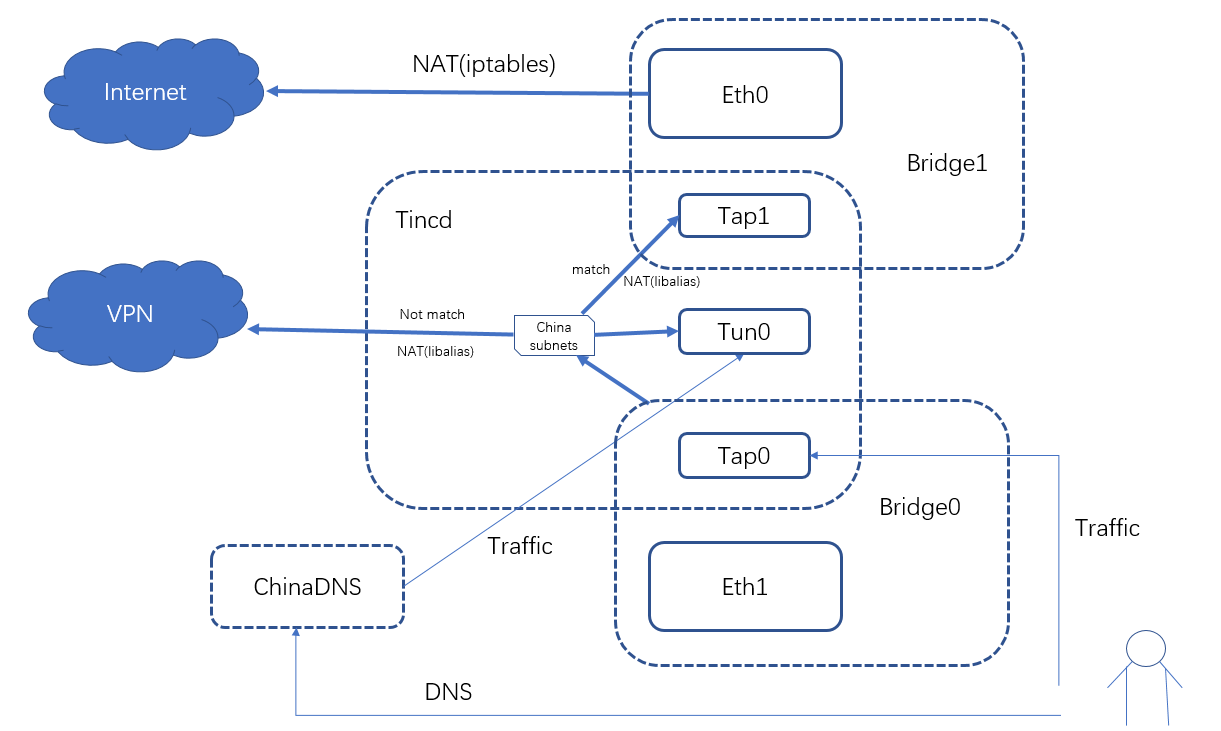
tap1/tun1 for offload data
tun0 for local access
tap0 for remote access
Process step:
remote data -> tap0 -> if match china -> send to tap1/tun1
-> if not match china -> NAT and send outside
Local data -> tun0 -> if match china -> send to tap1/tun1
-> if not match china -> send outside
VPN -> tinc -> try de-alias to tap0 -> success -> send to tap0
-> fail -> send to tun0
From china -> tap1/tun1 -> de-alias -> if dest addr = tun0 -> tun0
-> else -> tap0
For example:
LAN = 192.168.200.0/24
tap0 = 192.168.200.2
tun0 = 192.168.192.211
tap1 = 192.168.1.2
tap0 gateway = 192.168.1.1
packet flow:
To VPN
tap0 tinc VPN(other node)
request 192.168.200.3->8.8.8.8
192.168.192.210->8.8.8.8
192.168.192.210->8.8.8.8
reply: 8.8.8.8->192.168.192.210
8.8.8.8->192.168.192.210
8.8.8.8->192.168.200.3
tun0 tinc VPN(other node)
request 192.168.192.211->8.8.8.8
192.168.192.211->8.8.8.8
192.168.192.211->8.8.8.8
reply: 8.8.8.8->192.168.192.211
8.8.8.8->192.168.192.211
8.8.8.8->192.168.192.211
To china
tap0 tinc tap1/tun1
request 192.168.200.3->114.114.114.114
192.168.200.3->114.114.114.114
192.168.1.2->114.114.114.114
reply: 114.114.114.114->192.168.1.2
114.114.114.114->192.168.200.3
114.114.114.114->192.168.200.3
tun0 tinc tap1/tun1
request 192.168.192.211->114.114.114.114
192.168.192.211->114.114.114.114
192.168.1.2->114.114.114.114
reply: 114.114.114.114->192.168.1.2
114.114.114.114->192.168.192.211
114.114.114.114->192.168.192.211
需要处理的问题:
- 对tinc内部接口的ICMP的返回
- 请求目标地址的arp并存储,但是不需要响应arp查询,系统会自动处理这部分
- 是否需要portmap?
更新:
- ICMP未处理
- 自己实现了arp协议,启动的时候分配子网大小的arp表,有点耗内存,但是一般客户端很少会有特别大的子网
- portmap暂时搁置
- 没有实现dhcp协议,所以只能设置静态IP
- 测试正常