



![]()
![]()

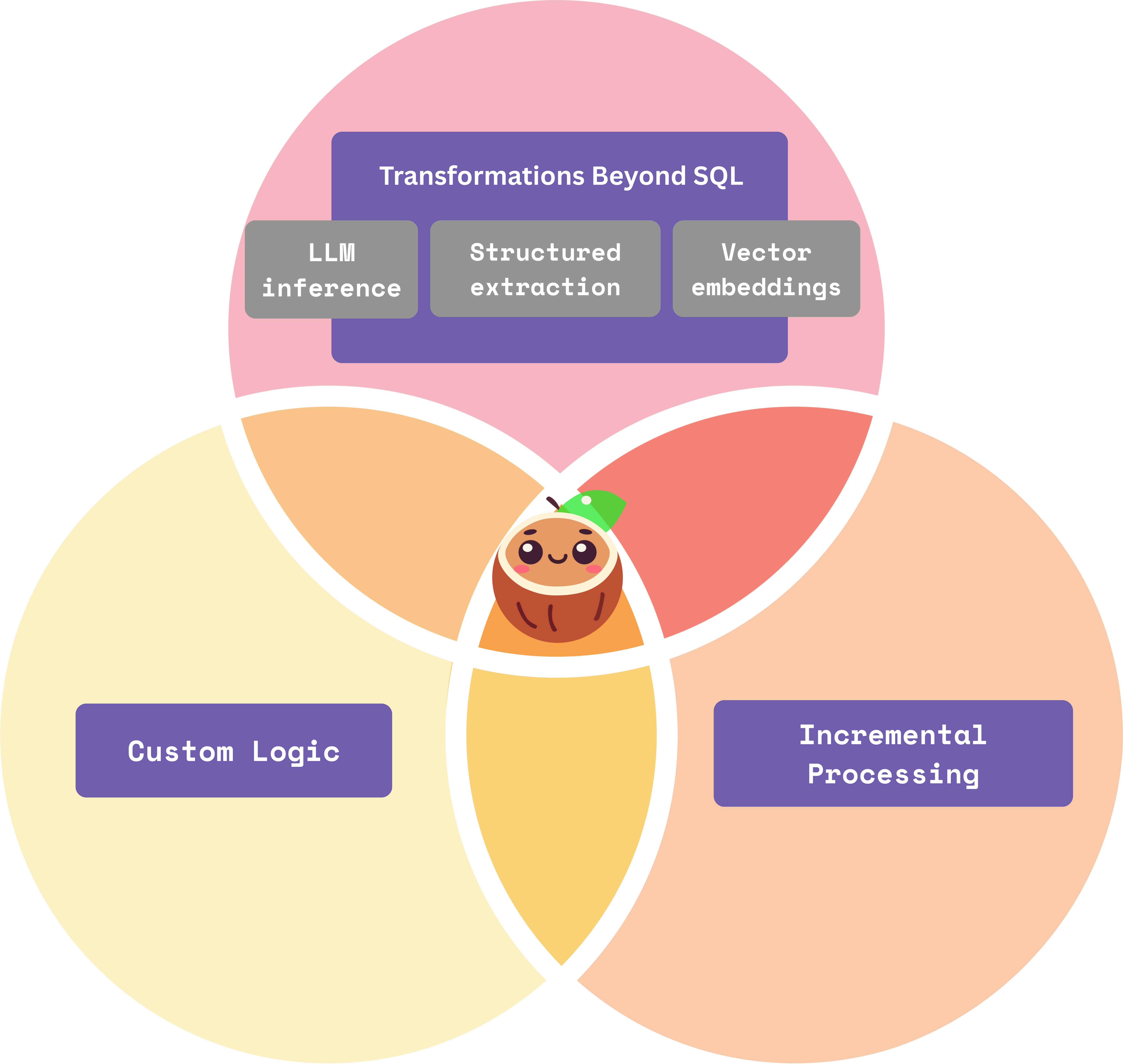
CocoIndex is an ultra performant data transformation framework, with its core engine written in Rust. The problem it tries to solve is to make it easy to prepare fresh data for AI - either creating embedding, building knowledge graphs, or performing other data transformations - and take real-time data pipelines beyond traditional SQL.
The philosophy is to have the framework handle the source updates, and having developers only worry about defining a series of data transformation, inspired by spreadsheet.
Unlike a workflow orchestration framework where data is usually opaque, in CocoIndex, data and data operations are first class citizens. CocoIndex follows the idea of Dataflow programming model. Each transformation creates a new field solely based on input fields, without hidden states and value mutation. All data before/after each transformation is observable, with lineage out of the box.
Particularly, users don't explicitly mutate data by creating, updating and deleting. Rather, they define something like - for a set of source data, this is the transformation or formula. The framework takes care of the data operations such as when to create, update, or delete.
# import
data['content'] = flow_builder.add_source(...)
# transform
data['out'] = data['content']
.transform(...)
.transform(...)
# collect data
collector.collect(...)
# export to db, vector db, graph db ...
collector.export(...)As a data framework, CocoIndex takes it to the next level on data freshness. Incremental processing is one of the core values provided by CocoIndex.

The frameworks takes care of
- Change data capture.
- Figure out what exactly needs to be updated, and only updating that without having to recompute everything.
This makes it fast to reflect any source updates to the target store. If you have concerns with surfacing stale data to AI agents and are spending lots of efforts working on infra piece to optimize the latency, the framework actually handles it for you.
If you're new to CocoIndex, we recommend checking out
- Install CocoIndex Python library
pip install -U cocoindex- Install Postgres if you don't have one. CocoIndex uses it for incremental processing.
Follow Quick Start Guide to define your first indexing flow. An example flow looks like:
@cocoindex.flow_def(name="TextEmbedding")
def text_embedding_flow(flow_builder: cocoindex.FlowBuilder, data_scope: cocoindex.DataScope):
# Add a data source to read files from a directory
data_scope["documents"] = flow_builder.add_source(cocoindex.sources.LocalFile(path="markdown_files"))
# Add a collector for data to be exported to the vector index
doc_embeddings = data_scope.add_collector()
# Transform data of each document
with data_scope["documents"].row() as doc:
# Split the document into chunks, put into `chunks` field
doc["chunks"] = doc["content"].transform(
cocoindex.functions.SplitRecursively(),
language="markdown", chunk_size=2000, chunk_overlap=500)
# Transform data of each chunk
with doc["chunks"].row() as chunk:
# Embed the chunk, put into `embedding` field
chunk["embedding"] = chunk["text"].transform(
cocoindex.functions.SentenceTransformerEmbed(
model="sentence-transformers/all-MiniLM-L6-v2"))
# Collect the chunk into the collector.
doc_embeddings.collect(filename=doc["filename"], location=chunk["location"],
text=chunk["text"], embedding=chunk["embedding"])
# Export collected data to a vector index.
doc_embeddings.export(
"doc_embeddings",
cocoindex.targets.Postgres(),
primary_key_fields=["filename", "location"],
vector_indexes=[
cocoindex.VectorIndexDef(
field_name="embedding",
metric=cocoindex.VectorSimilarityMetric.COSINE_SIMILARITY)])It defines an index flow like this:

| Example | Description |
|---|---|
| Text Embedding | Index text documents with embeddings for semantic search |
| Code Embedding | Index code embeddings for semantic search |
| PDF Embedding | Parse PDF and index text embeddings for semantic search |
| Manuals LLM Extraction | Extract structured information from a manual using LLM |
| Amazon S3 Embedding | Index text documents from Amazon S3 |
| Google Drive Text Embedding | Index text documents from Google Drive |
| Docs to Knowledge Graph | Extract relationships from Markdown documents and build a knowledge graph |
| Embeddings to Qdrant | Index documents in a Qdrant collection for semantic search |
| FastAPI Server with Docker | Run the semantic search server in a Dockerized FastAPI setup |
| Product Recommendation | Build real-time product recommendations with LLM and graph database |
| Image Search with Vision API | Generates detailed captions for images using a vision model, embeds them, enables live-updating semantic search via FastAPI and served on a React frontend |
More coming and stay tuned 👀!
For detailed documentation, visit CocoIndex Documentation, including a Quickstart guide.
We love contributions from our community ❤️. For details on contributing or running the project for development, check out our contributing guide.
Welcome with a huge coconut hug 🥥⋆。˚🤗. We are super excited for community contributions of all kinds - whether it's code improvements, documentation updates, issue reports, feature requests, and discussions in our Discord.
Join our community here:
- 🌟 Star us on GitHub
- 👋 Join our Discord community
▶️ Subscribe to our YouTube channel- 📜 Read our blog posts
We are constantly improving, and more features and examples are coming soon. If you love this project, please drop us a star ⭐ at GitHub repo
CocoIndex is Apache 2.0 licensed.