A multimodal chat interface with access to many tools.
YAIA is a sophisticated multimodal chat interface powered by advanced AI models and equipped with a variety of tools. It can:
- Search and browse the web in real-time
- Query Wikipedia for information
- Perform news and map searches
- Safely execute Python code that can produce text and images such as charts and diagrams
- Compose long-form articles mixing text and images
- Generate, search, and compare images
- Analyze documents and images
- Search and download arXiv papers
- Generate and save conversations as text and audio files
- Save files to the output directory
- Track personal improvements
- Manage checklists for task tracking
These are the main components:
- Gradio 5 for the web interface
- Amazon Bedrock to handle conversation and tool use
- Anthropic Claude 3.5 Sonnet as main model
- Amazon Titan Text and Multimodal Embeddings models
- Amazon Titan Image Generator
- OpenSearch for text and multimodal indexes
- Amazon Polly for voices
- AWS Lambda for the code interpreter
Here are examples of how to use various tools:
-
Web Search: "Search the web for recent advancements in quantum computing."
-
Wikipedia: "Find Wikipedia articles about the history of artificial intelligence."
-
Python Scripting: "Create a Python script to generate a bar chart of global CO2 emissions by country."
-
Sketchbook: "Start a new sketchbook and write an introduction about how to compute Pi with numerical methods."
-
Image Generation: "Generate an image of a futuristic city with flying cars and tall skyscrapers."
-
Image Search: "Search the image catalog for pictures of endangered species."
-
arXiv Integration: "Search for recent research papers on deep learning in natural language processing."
-
Conversation Generation: "Create a conversation between three experts discussing how to set up multimodal RAG."
-
File Management: "Save a summary of our discussion about climate change to a file named 'climate_change_summary.txt'."
-
Personal Improvement: "Here's a suggestion to improve: to improve answers, search for official sources."
-
Checklist: "Start a new checklist to follow a list of tasks one by one."
-
Web Interaction:
- DuckDuckGo Text Search: Performs web searches
- DuckDuckGo News Search: Searches for recent news articles
- DuckDuckGo Maps Search: Searches for locations and businesses
- DuckDuckGo Images Search: Searches for publicly available images
- Web Browser: Browses websites and retrieves their content
-
Wikipedia Tools:
- Wikipedia Search: Finds relevant Wikipedia pages
- Wikipedia Geodata Search: Locates Wikipedia articles by geographic location
- Wikipedia Page Retriever: Fetches full Wikipedia page content
-
Python Scripting:
- Runs Python scripts for computations, testing, and output generation, including text and images
- Python modules can be added to the Python interpreter
- Python code is run in a secure environment provided by AWS Lambda
-
Content Management:
- Personal Archive: Stores and retrieves text, Markdown, or HTML content, using a semantic database
- Sketchbook: Manages a multi-page sketchbook for writing and reviewing long-form content. Supports multiple output formats:
- Markdown (.md): For easy reading and editing
- Word Document (.docx): For document editing
-
Image Handling:
- Image Generation: Creates images based on text prompts
- Image Catalog Search: Searches images by description
- Image Similarity Search: Finds similar images based on a reference image
- Random Images: Retrieves random images from the catalog
- Get Image by ID: Retrieves a specific image from the catalog using its ID
- Image Catalog Count: Returns the total number of images in the catalog
- Download Image: Adds images from URLs to the catalog
-
arXiv Integration:
- Search and download arXiv papers
- Store paper content in the archive for easy retrieval
-
Conversation Generation:
- Transform content into a conversation between two to four people
- Generate audio files for the conversation using text-to-speech
-
File Management:
- Save File: Allows saving text content to a file with a specified name in the output directory
-
Personal Improvement:
- Track suggestions and mistakes for future enhancements
-
Checklist:
- Manage task lists with the ability to add items, mark them as completed, and review progress
For a comprehensive list of available tools and their usage, refer to ./Config/tools.json.
- A container tool: Docker or Finch (to install Finch, follow the instructions here)
- Python 3.12 or newer
- AWS account with appropriate permissions to access Amazon Bedrock, AWS Lambda, and Amazon ECR
-
Clone the repository:
git clone https://github.com/danilop/multimodal-chat cd multimodal-chat -
Create and activate a virtual environment (optional but recommended):
python -m venv venv source venv/bin/activate # On Windows, use `venv\Scripts\activate` -
Install the required packages:
pip install -r requirements.txt -
Set up the AWS Lambda function for code execution:
cd LambdaFunction ./deploy_lambda_function.sh cd .. -
To use Selenium for web browsing, install ChromeDriver. Using Homebrew:
brew install --cask chromedriver -
To output audio, install
ffmpeg. Using Homebrew:brew install ffmpeg
You can either use a local OpenSearch instance or connect to a remote server. For local setup:
-
Navigate to the OpenSearch directory:
cd OpenSearch/ -
Set the admin password (first-time setup), this step will create the
.envfile and theopensearch_env.shfiles:./set_password.sh -
Start OpenSearch locally (it needs access to the
.envfile):./opensearch_start.sh -
Ensure OpenSearch (2 nodes + dashboard) starts correctly by checking the output
-
To update OpenSearch, download the new container images using this script:
./opensearch_update.sh
For remote server setup, update the client creation code in the main script.
To change password, you need to delete the container using finch or docker and then set a new password.
Default models for text, images, and embeddings are in the Config/config.ini file. The models to use are specified using Amazon Bedrock model IDs or cross-region inference profile IDs. You need permissions and access to these models as described in Access foundation models.
This section assumes OpenSearch is running locally in another terminal window as described before.
-
Load the OpenSearch admin password into the environment:
source OpenSearch/opensearch_env.sh -
Run the application:
python multimodal_chat.py -
To reset the text and multimodal indexes (note: this doesn't delete images in
./Images/):python multimodal_chat.py --reset-index -
Open a web browser and navigate to http://127.0.0.1:7860/ to start chatting.
Here are a few examples of what you can do this application.
In this demo:
- Browse websites using Selenium and specific tools for DuckDuckGo (search, news, geosearch) and Wikipedia
- Use the semantic text archive tool to archive documents and retrieve by keywords
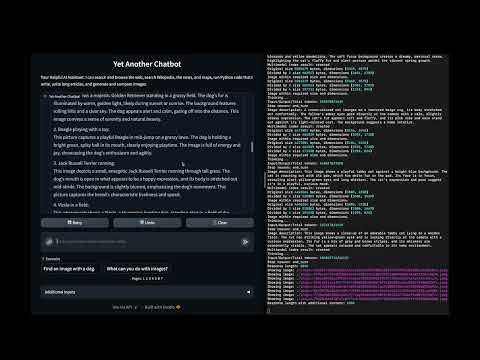
In this demo:
- Using a multimodal index and the local file system to manage an image catalog
- Store images with a generated description
- Retrieve images by text description (semantic search)
- Retrieve images by similarity to another image
- Retrieve random images
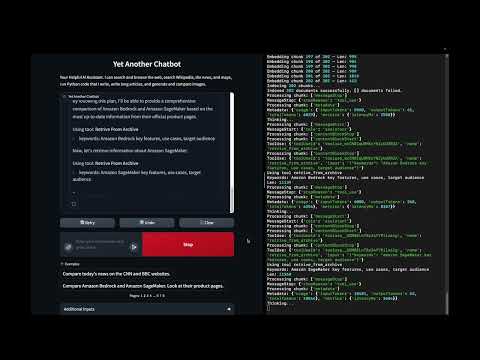
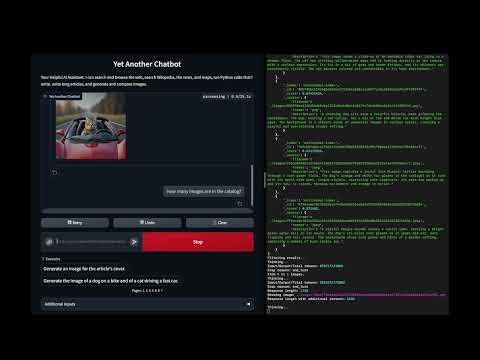
In this demo:
- Generate images from a textual description
- The text-to-image prompt is generated from chat instructions
- This approach allows to use the overall conversation to improve the prompt
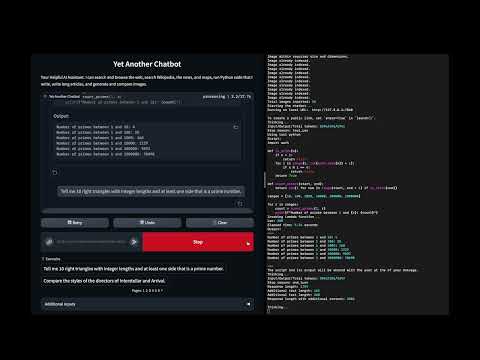
In this demo:
- Running AI generated code to solve problems
- Running for security in an AWS Lambda function with basic permissions
- Deployed via a container image to easily add Python modules
- Python only but easily extensible
In this demo:
- A tool to help write long forms of text such as articles and blog posts)
- Providing sequential access to text split in pages
- To mitigate the "asymmetry" between a model input and output sizes
In this demo:
- Best results use more than one tools together
- Start with a sketchbook to write a long article
- The article contains code snippets
- A review runs and tests all code snippets and updates each page fixing the code (if needed) and adding actual results
- If you encounter issues with OpenSearch, check the connection settings and ensure the service is running
- For AWS Lambda function errors, verify your AWS credentials and permissions
- If image processing fails, ensure you have the necessary libraries installed and check file permissions
Contributions to YAIA are welcome! Please refer to the contributing guidelines for more information on how to submit pull requests, report issues, or request features.
This project is licensed under the MIT License. See the LICENSE file for details.
- Combine multiple tools for complex tasks. For example, use the web search to find information, then use the sketchbook to write a summary, and finally generate a conversation about the topic.
- When working with images, you can generate new images, search for existing ones, or download images from the web to add to your catalog.
- Use the arXiv integration to stay up-to-date with the latest research in your field of interest.
- The conversation generation tool is great for creating engaging content or preparing for presentations.
- Regularly check and update your personal improvements to track your progress and areas for growth.
For more detailed information on specific components or advanced usage, please refer to the inline documentation in the source code.