pip install function_scheduling_distributed_framework --upgrade

以下这只是简单求和例子,实际情况换成任意函数里面写任意逻辑,框架可没有规定只能用于 求和函数 的自动调度并发。
而是根据实际情况函数的参数个数、函数的内部逻辑功能,全部都由用户自定义,函数里面想写什么就写什么,想干什么就干什么,极端自由。
也就是框架很容易学和使用,把下面的task_fun函数的入参和内部逻辑换成你自己想写的函数功能就可以了,框架只需要学习task_deco这一个函数的参数就行。
import time
from function_scheduling_distributed_framework import task_deco, BrokerEnum
@task_deco("task_queue_name1",qps=5,broker_kind=BrokerEnum.PERSISTQUEUE) # 入参包括20种,运行控制方式非常多,想得到的控制都会有。
def task_fun(x,y):
print(f'{x} + { y} = {x + y}')
time.sleep(3) # 框架会自动并发绕开这个阻塞,无论函数内部随机耗时多久都能自动调节并发达到每秒运行 5 次 这个 task_fun 函数的目的。
if __name__ == "__main__":
for i in range(100):
task_fun.push(i, y=i * 2) # 发布者发布任务
task_fun.consume() # 消费者启动循环调度并发消费任务
"""
对于消费函数,框架内部会生成发布者(生产者)和消费者。
1.推送。 task_fun.push(1,y=2) 会把 {"x":1,"y":2} (消息也自动包含一些其他辅助信息) 发送到中间件的 task_queue_name1 队列中。
2.消费。 task_fun.consume() 开始自动从中间件拉取消息,并发的调度运行函数,task_fun(**{"x":1,"y":2}),每秒运行5次
整个过程只有这两步,清晰明了,其他的控制方式需要看 task_deco 的中文入参解释,全都参数都很有用。
这个是单个脚本实现了发布和消费,一般都是分离成两个文件的,任务发布和任务消费无需在同一个进程的解释器内部,
因为是使用了中间件解耦消息和持久化消息,不要被例子误导成了,以为发布和消费必须放在同一个脚本里面
使用方式只需要这一个例子就行了,其他举得例子只是改了下broker_kind和其他参数而已,
而且装饰器的入参已近解释得非常详细了,框架浓缩到了一个装饰器,并没有用户需要从框架里面要继承什么组合什么的复杂写法。
"""
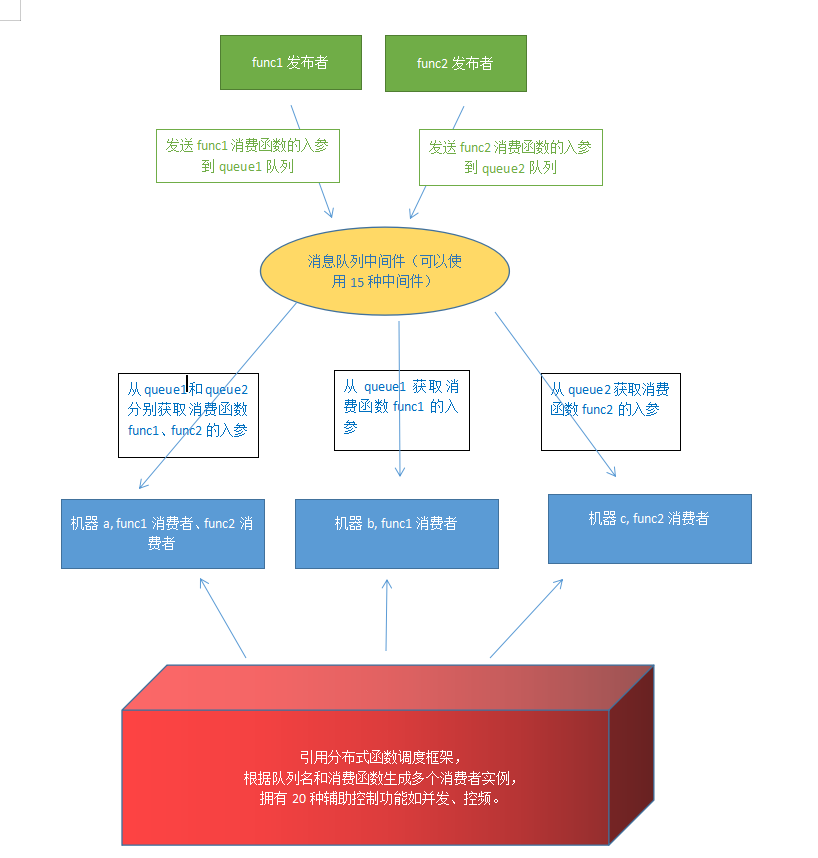
python通用分布式函数调度框架。适用场景范围广泛,
框架非常适合io密集型(框架支持对函数自动使用 thread gevent eventlet asyncio 并发)
框架非常适合cpu密集型(框架能够在线程 协程基础上 叠加 多进程 multi_process 并发 ,不仅能够多进程执行任务还能多机器执行任务)。
不管是函数需要消耗时io还是消耗cpu,用此框架都很合适,因为任务都是在中间件里面,可以自动分布式分发执行。
此框架是函数的辅助控制倍增器。
框架不适合的场景是 函数极其简单,例如函数只是一行简单的 print hello,函数只需要非常小的cpu和耗时,运行一次函数只消耗了几十hz或者几纳秒,
此时那就采用直接调用函数就好了,因为框架施加了很多控制功能,当框架的运行逻辑耗时耗cpu 远大于函数本身 时候,使用框架反而会使函数执行变慢。
(python框架从全局概念上影响程序的代码组织和运行,包和模块是局部的只影响1个代码文件的几行。)
可以一行代码分布式并发调度起一切任何老代码的旧函数和新项目的新函数,并提供数十种函数控制功能。
还是不懂框架能做什么是什么,就必须先去了解下celery rq。如果连celery rq类似这种的用途概念听都没听说,
那就不可能知道框架的概念和功能用途。
功能包括:
分布式:
支持数十种最负盛名的消息中间件.(除了常规mq,还包括用不同形式的如 数据库 磁盘文件 redis等来模拟消息队列)
并发:
支持threading gevent eventlet asyncio 四种并发模式 叠加 多进程。
多进程不是和前面四种模式平行的,是叠加的,例如可以是 多进程 + 协程,多进程 + 多线程。
控频限流:
例如十分精确的指定1秒钟运行30次函数(无论函数需要随机运行多久时间,都能精确控制到指定的消费频率;
分布式控频限流:
例如一个脚本反复启动多次或者多台机器多个容器在运行,如果要严格控制总的qps,能够支持分布式控频限流。
任务持久化:
消息队列中间件天然支持
断点接续运行:
无惧反复重启代码,造成任务丢失。消息队列的持久化 + 消费确认机制 做到不丢失一个消息
定时:
可以按时间间隔、按指定时间执行一次、按指定时间执行多次,使用的是apscheduler包的方式。
指定时间不运行:
例如,有些任务你不想在白天运行,可以只在晚上的时间段运行
消费确认:
这是最为重要的一项功能之一,有了这才能肆无忌惮的任性反复重启代码也不会丢失一个任务。
(常规的手写 redis.lpush + redis.blpop,然后并发的运行取出来的消息,随意关闭重启代码瞬间会丢失大量任务,
那种有限的 断点接续 完全不可靠,根本不敢随意重启代码)
立即重试指定次数:
当函数运行出错,会立即重试指定的次数,达到最大次重试数后就确认消费了
重新入队:
在消费函数内部主动抛出一个特定类型的异常ExceptionForRequeue后,消息重新返回消息队列
超时杀死:
例如在函数运行时间超过10秒时候,将此运行中的函数kill
计算消费次数速度:
实时计算单个进程1分钟的消费次数,在日志中显示;当开启函数状态持久化后可在web页面查看消费次数
预估消费时间:
根据前1分钟的消费次数,按照队列剩余的消息数量来估算剩余的所需时间
函数运行日志记录:
使用自己设计开发的 控制台五彩日志(根据日志严重级别显示成五种颜色;使用了可跳转点击日志模板)
+ 多进程安全切片的文件日志 + 可选的kafka elastic日志
任务过滤:
例如求和的add函数,已经计算了1 + 2,再次发布1 + 2的任务到消息中间件,可以让框架跳过执行此任务。
任务过滤的原理是使用的是函数入参判断是否是已近执行过来进行过滤。
任务过滤有效期缓存:
例如查询深圳明天的天气,可以设置任务过滤缓存30分钟,30分钟内查询过深圳的天气,则不再查询。
30分钟以外无论是否查询过深圳明天的天气,则执行查询。
任务过期丢弃:
例如消息是15秒之前发布的,可以让框架丢弃此消息不执行,防止消息堆积,
在消息可靠性要求不高但实时性要求高的高并发互联网接口中使用
函数状态和结果持久化:
可以分别选择函数状态和函数结果持久化到mongodb,使用的是短时间内的离散mongo任务自动聚合成批量
任务后批量插入,尽可能的减少了插入次数
消费状态实时可视化:
在页面上按时间倒序实时刷新函数消费状态,包括是否成功 出错的异常类型和异常提示
重试运行次数 执行函数的机器名字+进程id+python脚本名字 函数入参 函数结果 函数运行消耗时间等
消费次数和速度生成统计表可视化:
生成echarts统计图,主要是统计最近60秒每秒的消费次数、最近60分钟每分钟的消费次数
最近24小时每小时的消费次数、最近10天每天的消费次数
rpc:
生产端(或叫发布端)获取消费结果。各个发布端对消费结果进行不同步骤的后续处理更灵活,而不是让消费端对消息的处理一干到底。
关于稳定性和性能,一句话概括就是直面百万c端用户(包括app和小程序),
已经连续超过三个季度稳定高效运行无事故,从没有出现过假死、崩溃、内存泄漏等问题。
windows和linux行为100%一致,不会像celery一样,相同代码前提下,很多功能在win上不能运行或出错。
此功能是框架最好用的功能,控频功能远远强于只能控制并发数量的功能。
举个例子,在flask服务端接口中写个 time.sleep,消费函数里面请求这个flask接口,如果服务端反复修改sleep的大小后重新部署web服务,
例如分别把sleep 设置成 0.006 0.04 0.7 1 3 13 26 秒 这些值,如何做到无视服务端的修改而消费代码不重启且精确控制消费函数每秒得到7次响应结果呢,
传统的设置 线程数 进程数 或者asyncio的并发数,完全没有办法做到每秒都得到7次结果,有人说开7个线程就是每秒 7 tps,这是扯淡,
除非服务端flask接口永远都是time.sleep 1秒,如果改成了sleep 其他的值,
例如服务端接口中sleep 0.1秒,你开7个线程,每秒就是请求70次了,这样是严重超频,
例如服务端接口中sleep 10秒,你开7个线程,每秒平均得到的结果不到 1tps,这样是严重没有达到频率,
这在对接第三方供酒店 机票库存供应商的付费api时候,90%的供应商都会根据付费金额不同控制你的每秒调用次数,
请求频率大了返回error过多,没得到正确结果,请求频率小了,浪费自己花费的钱财和需要更长的时间执行完任务。
此框架使用时候,建议不需要指定并发大小,而是指定qps大小,框架会自动自适应调节真正的并发数量来精确达到指定的运行频率。
class BrokerEnum:
RABBITMQ_AMQPSTORM = 0 # 使用 amqpstorm 包操作rabbitmq 作为 分布式消息队列,支持消费确认.推荐这个。
RABBITMQ_RABBITPY = 1 # 使用 rabbitpy 包操作rabbitmq 作为 分布式消息队列,支持消费确认。
REDIS = 2 # 使用 redis 的 list结构,brpop 作为分布式消息队列。随意重启和关闭会丢失大量消息,不支持消费确认。
LOCAL_PYTHON_QUEUE = 3 # 使用python queue.Queue实现的基于当前python进程的消息队列,不支持跨进程 跨脚本 跨机器共享任务,不支持持久化,适合一次性短期简单任务。
RABBITMQ_PIKA = 4 # 使用pika包操作rabbitmq 作为 分布式消息队列。
MONGOMQ = 5 # 使用mongo的表中的行模拟的 作为分布式消息队列,支持消费确认。
PERSISTQUEUE = 6 # 使用基于sqlute3模拟消息队列,支持消费确认和持久化,但不支持跨机器共享任务,可以基于本机单机跨脚本和跨进程共享任务,好处是不需要安装中间件。
NSQ = 7 # 基于nsq作为分布式消息队列,支持消费确认。
KAFKA = 8 # 基于kafka作为分布式消息队列,建议使用BrokerEnum.CONFLUENT_KAFKA。
REDIS_ACK_ABLE = 9 # 基于redis的 list + 临时unack的set队列,采用了 lua脚本操持了取任务和加到pengding为原子性,随意重启和掉线不会丢失任务。
SQLACHEMY = 10 # 基于SQLACHEMY 的连接作为分布式消息队列中间件支持持久化和消费确认。支持mysql oracle sqlserver等5种数据库。
ROCKETMQ = 11 # 基于 rocketmq 作为分布式消息队列,这个中间件必须在linux下运行,win不支持。
REDIS_STREAM = 12 # 基于redis 5.0 版本以后,使用 stream 数据结构作为分布式消息队列,支持消费确认和持久化和分组消费,是redis官方推荐的消息队列形式,比list结构更适合。
ZEROMQ = 13 # 基于zeromq作为分布式消息队列,不需要安装中间件,可以支持跨机器但不支持持久化。
RedisBrpopLpush = 14 # 基于redis的list结构但是采用brpoplpush 双队列形式,和 redis_ack_able的实现差不多,实现上采用了原生命令就不需要lua脚本来实现取出和加入unack了。
"""
操作 kombu 包,这个包也是celery的中间件依赖包,这个包可以操作10种中间件(例如rabbitmq redis),但没包括分布式函数调度框架的kafka nsq zeromq 等。
同时 kombu 包的性能非常差,可以用原生redis的lpush和kombu的publish测试发布,使用brpop 和 kombu 的 drain_events测试消费,对比差距相差了5到10倍。
由于性能差,除非是分布式函数调度框架没实现的中间件才选kombu方式(例如kombu支持亚马逊队列 qpid pyro 队列),否则强烈建议使用此框架的操作中间件方式而不是使用kombu。
"""
KOMBU = 15
"""基于confluent-kafka包,包的性能比kafka-python提升10倍。同时应对反复随意重启部署消费代码的场景,此消费者实现至少消费一次,第8种BrokerEnum.KAFKA是最多消费一次。"""
CONFLUENT_KAFKA = 16
切换任意中间件,代码都不需要做任何变化,不需要关注如何使用中间件的细节。
总体来说首选rabbitmq,这也是不指定broker_kind参数时候的默认的方式。
1、threading 多线程,使用自定义的可缩小、节制开启新线程的自定义线程池,不是直接用官方内置concurrent.futures.ThreadpoolExecutor
此线程池非常智能,配合qps参数,任何场景可以无脑开500线程,真正的做到智能扩张,智能自动缩小。
这线程池是智能线程池,由于非常好用,为这个线程池做了独立的pypi包,可以单独用于没有使用此框架的项目。
2、gevent 需要在运行起点的脚本首行打 gevent 猴子补丁。
3、eventlet 需要在运行起点的脚本首行打 eventlet 猴子补丁。
4、asyncio async异步,主要是针对消费函数已经定义成了 async def fun(x) 这种情况,这种情况不能直接使用多线程,
因为执行 fun(1) 后得到的并不是所想象的函数最终结果,而是得到的一个协程对象,所以针对已经定义成异步函数了的,需要使用此种并发模式。
框架不鼓励用户定义异步函数,你就用同步的直观方式思维定义函数就行了,其余的并发调度交给框架就行了。
5、开启多进程启动多个consumer,此模式是 多进程 + 上面4种的其中一种并发方式,充分利用多核和充分利用io,用法如下。可以实现 多进程 叠加 协程并发。
# 这种是多进程方式,一次编写能够兼容win和linux的运行。
from function_scheduling_distributed_framework import task_deco, BrokerEnum, ConcurrentModeEnum, run_consumer_with_multi_process
import os
@task_deco('test_multi_process_queue',broker_kind=BrokerEnum.REDIS_ACK_ABLE,
concurrent_mode=ConcurrentModeEnum.THREADING,)
def fff(x):
print(x * 10,os.getpid())
if __name__ == '__main__':
# run_many_consumer_with_multi_process([consumer_init_params_include_consuming_function(fff)],process_num=6)
run_consumer_with_multi_process(fff,6)
源码实现思路基本90%遵守了oop的6个设计原则,很容易扩展中间件。
1、单一职责原则——SRP
2、开闭原则——OCP
3、里式替换原则——LSP
4、依赖倒置原则——DIP
5、接口隔离原则——ISP
6、迪米特原则——LOD
最主要是大量使用了模板模式、工厂模式、策略模式、鸭子类。
可以仿照源码中实现中间件的例子,只需要继承发布者、消费者基类后实现几个抽象方法即可添加新的中间件。
将函数名和队列名绑定,即可开启自动消费。
只需要一行代码就 将任何老物件的旧函数和新项目的新函数实现 分布式 、并发、 控频、断点接续运行、定时、指定时间不运行、
消费确认、重试指定次数、重新入队、超时杀死、计算消费次数速度、预估消费时间、
函数运行日志记录、任务过滤、任务过期丢弃等数十种功能。
和celery一样支持线程、gevent、eventlet 并发运行模式,大大简化比使用celery,很强大简单,已在多个生产项目和模块验证。
确保任何并发模式在linux和windows,一次编写处处运行。不会像celery在windwos上某些功能失效。
没有严格的目录结构,代码可以在各个文件夹层级到处移动,脚本名字可以随便改。不使用令人讨厌的cmd命令行启动。
没有大量使用元编程,使代码性能提高,减少代码拼错概率和降低调用难度。
并且所有重要公有方法和函数设计都不使用*args,**kwargs方式,全部都能使ide智能提示补全参数,一切为了ide智能补全。
pip install function_scheduling_distributed_framework --upgrade -i https://pypi.org/simple
2.1为简单例子,介绍了入参意义,这里是介绍的是手动实例化生成消费者的方式,这个是本质。
下面的2.2 是装饰器生成消费者的使用方式,这个是简洁一丝丝。
"""
运行后悔自动在你的当前项目根目录下生成一个 distributed_frame_config.py 的文件,在里面修改写配置就好了,框架会自动读取这个文件的配置。
"""
import time
from function_scheduling_distributed_framework import get_consumer
# 主要的消费函数,演示做加法,假设需要花10秒钟。
# 为什么消费举例大多数是time.sleep(n秒钟),主要是用框架用来验证并发和控频。
# 消费函数适合是io密集型和cpu密集型。
# 如果消费函数是个简单地两数求和或者简单print一下hello world,那不需要使用这种分布式任务框架
# 消费函数如果能在1us之内结束运行,那就直接使用调用函数的行方式不香吗,对运行时间很短暂的函数引入分布式任务框架是多此一举。
def f2(a, b):
print(f'消费此消息 {a} + {b} 中。。。。。')
time.sleep(10) # 模拟做某事需要阻塞10秒种,必须用并发绕过此阻塞。
print(f'计算 {a} + {b} 得到的结果是 {a + b}')
# 把消费的函数名传给consuming_function,就这么简单。
# 通过设置broker_kind,一键切换中间件为mq或redis等7种中间件或包。
# 额外参数支持超过10种控制功能,celery支持的控制方式,都全部支持。
# 这里演示使用本地持久化队列,本机多个脚本之间可以相互通信共享任务,无需安装任何中间件,降低初次使用门槛。
# 框架使用很简单,全部源码的函数和类都不需要深入了解,只需要看懂get_consumer这一个函数的参数就可以就可以。
"""
使用工厂模式再包一层,通过设置数字来生成基于不同中间件或包的consumer。
:param queue_name: 队列名字。
:param consuming_function: 处理消息的函数。 指定队列名字和指定消费函数这两个参数是必传,必须指定,
这2个是这个消费框架的本质核心参数,其他参数都是可选的。
:param function_timeout : 超时秒数,函数运行超过这个时间,则自动杀死函数。为0是不限制。
:param concurrent_num:并发数量,
:param specify_concurrent_pool:使用指定的线程池(协程池),可以多个消费者共使用一个线程池,不为None时候。threads_num失效
:param concurrent_mode:并发模式,1线程 2gevent 3eventlet 4 asyncio
:param max_retry_times: 最大自动重试次数,当函数发生错误,立即自动重试运行n次,对一些特殊不稳定情况会有效果。
可以在函数中主动抛出重试的异常ExceptionForRetry,框架也会立即自动重试。
主动抛出ExceptionForRequeue异常,则当前消息会重返中间件。
:param log_level:框架的日志级别,默认是debug级别,可以看到详细的执行信息,如果不想看到太多详细的日志,可以设置为logging.INFO常量(20) 或者数字20。
:param is_print_detail_exception:是否打印详细的堆栈错误。为0则打印简略的错误占用控制台屏幕行数少。
:param msg_schedule_time_intercal:消息调度的时间间隔,用于控频的关键。
:param qps:指定1秒内的函数执行次数,qps会覆盖msg_schedule_time_intercal,以后废弃msg_schedule_time_intercal这个参数。
:param msg_expire_senconds:消息过期时间,为0永不过期,为10则代表,10秒之前发布的任务如果现在才轮到消费则丢弃任务。
:param is_using_distributed_frequency_control: 是否使用分布式空频(依赖redis计数),默认只对当前实例化的消费者空频有效。假如实例化了2个qps为10的使用同一队列名的消费者,
并且都启动,则每秒运行次数会达到20。如果使用分布式空频则所有消费者加起来的总运行次数是10。
:param is_send_consumer_hearbeat_to_redis 时候将发布者的心跳发送到redis,有些功能的实现需要统计活跃消费者。因为有的中间件不是真mq。
:param logger_prefix: 日志前缀,可使不同的消费者生成不同的日志
:param create_logger_file : 是否创建文件日志
:param do_task_filtering :是否执行基于函数参数的任务过滤
:param task_filtering_expire_seconds:任务过滤的失效期,为0则永久性过滤任务。例如设置过滤过期时间是1800秒 ,
30分钟前发布过1 + 2 的任务,现在仍然执行,
如果是30分钟以内发布过这个任务,则不执行1 + 2,现在把这个逻辑集成到框架,一般用于接口价格缓存。
:param is_consuming_function_use_multi_params 函数的参数是否是传统的多参数,不为单个body字典表示多个参数。
:param is_do_not_run_by_specify_time_effect :是否使不运行的时间段生效
:param do_not_run_by_specify_time :不运行的时间段
:param schedule_tasks_on_main_thread :直接在主线程调度任务,意味着不能直接在当前主线程同时开启两个消费者。
:param function_result_status_persistance_conf :配置。是否保存函数的入参,运行结果和运行状态到mongodb。
这一步用于后续的参数追溯,任务统计和web展示,需要安装mongo。
:param is_using_rpc_mode 是否使用rpc模式,可以在发布端获取消费端的结果回调,但消耗一定性能,使用async_result.result时候会等待阻塞住当前线程。。
:param broker_kind:中间件种类,。 0 使用pika链接rabbitmqmq,1使用rabbitpy包实现的操作rabbitmnq,2使用redis,
3使用python内置Queue,4使用amqpstorm包实现的操作rabbitmq,5使用mongo,6使用本机磁盘持久化。
7使用nsq,8使用kafka,9也是使用redis但支持消费确认。10为sqlachemy,支持mysql sqlite postgre oracel sqlserver
11使用rocketmq. 12使用redis的 stream 数据结作为中间件,这个也支持消费确认 。13 zeromq
:return AbstractConsumer
'''
有人会抱怨入参超多很复杂,是因为要实现一切控制方式,实现的运行控制手段非常丰富,所以参数就会多。
看这个里面的参数解释非常重要,几乎能想到的控制功能全部都有。比如有人说日志太多,不想看那么详细的提示日志
,早就通过参数提供实现了,自己抱怨参数多又以为没提供这个功能,简直是自相矛盾。
想入参参数少那就看readme的6.5 “新增一个10行代码的函数的最精简乞丐版实现的分布式函数执行框架,演示最本质实现原理。“
这个例子的框架啥控制手段都没有,参数自然就很少。
'''
"""
consumer = get_consumer('queue_test2', consuming_function=f2, broker_kind=6)
# 推送需要消费的任务,可以变消费边推送。发布的内容字典需要和函数所能接收的参数一一对应,
# 并且函数参数需要能被json序列化,不要把自定义的类型作为消费函数的参数。
consumer.publisher_of_same_queue.clear()
[consumer.publisher_of_same_queue.publish(dict(a=i,b=i * 2)) for i in range(100)]
# 开始从中间件循环取出任务,使用指定的函数消费中间件里面的消息。
consumer.start_consuming_message()
核心必要参数:
queue_name: 队列名字。
consuming_function: 处理消息的函数。 指定队列名字和指定消费函数这两个参数是必传,必须指定,
queue_name和consuming_function这2个是这个消费框架的本质核心参数,其他参数都是可选的。
重点参数:
concurrent_num:并发数量。
qps qps是有个很有趣的参数,能精确控制函数每秒运行多少次。
concurrent_num和qps存在着一定的关系。
例如对于下面这个函数
def func(x):
time.sleep(2)
print(x)
1)如果设置 concurrent_num = 1000(或100万) qps = 10
那么一秒钟会执行10次func函数。如果不指定qps的值,则不进行控频,消费框架会平均每秒钟会执行50次函数func。
如果设置concurrent_num = 1000 qps = 5
那么一秒钟会执行5次func函数。所以可以看到,当你不知道要开多少并发合适的时候,可以粗暴开1000个线程,但要设置一个qps。
那为什么次框架,可以让你粗暴的设置1000设置100万线程呢,并不是做了数字截取,判断线程设置大于多少就自动调小了,此消费框架并没有这样去实现。
而是次框架使用的非concurrent.tutures.ThreadpoolExecutor,是使用的自定义的 ThreadPoolExecutorShrinkAble 线程池,
此线程池其中之一的功能就是节制开更多的线程,因为对于上面的休眠2秒的func函数,如果设置concurrent_num = 1000000 qps = 5,
正常来说开10个线程足够实现每秒执行5次了,此框架在调节线程新增线程时候进行了更多的判断,所以原生线程池不可以设置100万大小,
而ThreadPoolExecutorShrinkAble可以设置为100万大小。
此外ThreadPoolExecutorShrinkAble 实现了线程池自动缩小的功能,这也是原生concurrent.tutures.ThreadpoolExecutor没有的功能。
自动缩小是什么意思呢,比如一段时间任务非常密集1秒钟来了几百个任务,所以当时开启了很多线程来应付,但一段时间后每分钟只来了个把任务,
此时 ThreadPoolExecutorShrinkAble 能够自动缩小线程池,
ThreadPoolExecutorShrinkAble实现了java ThreadpoolExecutor的KeepAliveTime参数的功能,
原生concurrent.tutures.ThreadpoolExecutor线程池即使以后永久不来新任务,之前开的线程数量一致保持这。
关于 ThreadPoolExecutorShrinkAble 的厉害之处,可以参考 https://github.com/ydf0509/threadpool_executor_shrink_able
最终关于 concurrent_num 大小设置为多少,看自己需求,上面说的100万是举个例子,
实际这个参数还被用作为线程池的任务队列的有界队列的大小,所以一定要设置为1000以下,否则如果设置为100万,
从消息中间件预取出的消息过多,造成python内存大、单个消费者掏空消息队列中间件造成别的新启动的消费者无任务可消费、
对于不支持消费确认类型的中间件的随意重启会丢失大量正在运行的任务 等不利影响。
2)上面的func函数,设置 concurrent_num = 1 qps = 100,那会如何呢?
由于你设置的并发是1,对于一个需要2秒运行完成的函数,显然平均每2秒才能执行1次,就是框架真正的只能达到0.5个qps。
所以 concurrent_num 和 qps,既有关系,也不是绝对的关系。
在对一个随机消耗时间的函数进行并发控制时候,如果函数的运行时间是0.5到20秒任意时间不确定的徘徊,你可以设置 concurrent_num = 100,
如果合作方要求了只能1秒钟能让你使用多少次,例如需要精确控频10次,可以设置qps =10,concurrent_num随便搞个 一两百 两三百就行了,
因为是智能的克制的调节线程池大小的,所以不会真的达到concurrent_num的值。
3)qps是个小数可以小于1,如果要设置10秒执行一次函数,则设置qps=0.1
这主要是介绍了 concurrent_num 和qps的关系和设置值。
# 这次使用修改你导入框架运行一次后的项目根目录下的自动生成的distributed_frame_config.py配置文件的方式来进行redis rabbitmq等的配置。
#装饰器版,使用方式例如:
from function_scheduling_distributed_framework import task_deco,BrokerEnum
@task_deco('queue_test_f01', qps=0.2, broker_kind=BrokerEnum.REDIS_ACK_ABLE) # qps 0.2表示每5秒运行一次函数,broker_kind=2表示使用redis作中间件。
def add(a, b):
print(a + b)
for i in range(10, 20):
add.pub(dict(a=i, b=i * 2)) # 使用add.pub 发布任务
add.push(i, b=i * 2) # 使用add.push 发布任务
add.consume() # 使用add.consume 消费任务from function_scheduling_distributed_framework import get_consumer,BrokerEnum
def add(a, b):
print(a + b)
# 需要手动指定consuming_function入参的值。
consumer = get_consumer('queue_test_f01', consuming_function=add,qps=0.2, broker_kind=BrokerEnum.REDIS_ACK_ABLE)
for i in range(10, 20):
consumer.publisher_of_same_queue.publish(dict(a=i, b=i * 2)) # consumer.publisher_of_same_queue.publish 发布任务
consumer.start_consuming_message() # 使用consumer.start_consuming_message 消费任务装饰器版本的 task_deco 入参 和 get_consumer 入参99%一致,唯一不同的是 装饰器版本加在了函数上自动知道消费函数了,
所以不需要传consuming_function参数。
看这个例子,step1函数中不仅可以给step2发布任务,也可以给step1自身发布任务。
qps规定了step1每2秒执行一次,step2每秒执行3次。
import time
from function_scheduling_distributed_framework import task_deco, BrokerEnum
@task_deco('queue_test_step1', qps=0.5, broker_kind=BrokerEnum.LOCAL_PYTHON_QUEUE)
def step1(x):
print(f'x 的值是 {x}')
if x == 0:
for i in range(1, 300):
step1.pub(dict(x=x + i))
for j in range(10):
step2.push(x * 100 + j) # push是直接发送多个参数,pub是发布一个字典
time.sleep(10)
@task_deco('queue_test_step2', qps=3, broker_kind=BrokerEnum.LOCAL_PYTHON_QUEUE)
def step2(y):
print(f'y 的值是 {y}')
time.sleep(10)
if __name__ == '__main__':
# step1.clear()
step1.push(0) # 给step1的队列推送任务。
step1.consume() # 可以连续启动两个消费者,因为conusme是启动独立线程里面while 1调度的,不会阻塞主线程,所以可以连续运行多个启动消费。
step2.consume()# 定时运行消费演示,定时方式入参用法可以百度 apscheduler 定时包。
import datetime
from function_scheduling_distributed_framework import task_deco, BrokerEnum, fsdf_background_scheduler, timing_publish_deco
@task_deco('queue_test_666', broker_kind=BrokerEnum.LOCAL_PYTHON_QUEUE)
def consume_func(x, y):
print(f'{x} + {y} = {x + y}')
if __name__ == '__main__':
fsdf_background_scheduler.add_job(timing_publish_deco(consume_func), 'interval', id='3_second_job', seconds=3, kwargs={"x": 5, "y": 6}) # 每隔3秒发布一次任务,自然就能每隔3秒消费一次任务了。
fsdf_background_scheduler.add_job(timing_publish_deco(consume_func), 'date', run_date=datetime.datetime(2020, 7, 24, 13, 53, 6), args=(5, 6,)) # 定时,只执行一次
fsdf_background_scheduler.add_timing_publish_job(consume_func, 'cron', day_of_week='*', hour=14, minute=51, second=20, args=(5, 6,)) # 定时,每天的11点32分20秒都执行一次。
# 启动定时
fsdf_background_scheduler.start()
# 启动消费
consume_func.consume()
import time
"""
这种是多进程方式,一次编写能够兼容win和linux的运行。一次性启动16个进程 叠加 多线程 并发。
"""
from function_scheduling_distributed_framework import task_deco, BrokerEnum, ConcurrentModeEnum, run_consumer_with_multi_process
import os
import requests
import threading
@task_deco('test_multi_process_queue',broker_kind=BrokerEnum.REDIS_ACK_ABLE,concurrent_mode=ConcurrentModeEnum.THREADING,qps=100)
def fff(x):
resp = requests.get('http://www.baidu.com/content-search.xml')
print(x,os.getpid(),threading.get_ident(),resp.text[:5])
if __name__ == '__main__':
for i in range(10000):
fff.push(i)
# fff.consume() # 这个是单进程多线程/协程 消费。
# 一次性启动16个进程 叠加 多线程 并发。此demo可以作为超高速爬虫例子,能充分利用io和cpu,在16核机器上请求效率远远暴击 scrapy 数十倍,大家可以亲自对比测试。
run_consumer_with_multi_process(fff,16) from function_scheduling_distributed_framework import task_deco, BrokerEnum
@task_deco('test_rpc_queue', is_using_rpc_mode=True, broker_kind=BrokerEnum.REDIS_ACK_ABLE)
def add(a, b):
return a + b
if __name__ == '__main__':
add.consume()from test_frame.test_rpc.test_consume import add
for i in range(100):
async_result = add.push(i, i * 2)
print(async_result.result)通过不同的时间观察控制台,可以发现无论f2这个函数需要耗时多久(无论是函数耗时需要远小于1秒还是远大于1秒),框架都能精确控制每秒刚好运行2次。
当函数耗时很小的时候,只需要很少的线程就能自动控制函数每秒运行2次。
当函数突然需要耗时很大的时候,智能线程池会自动启动更多的线程来达到每秒运行2次的目的。
当函数耗时从需要耗时很大变成只需要耗时很小的时候,智能线程池会自动缩小线程数量。
总之是围绕qps恒定,会自动变幻线程数量,做到既不多开浪费cpu切换,也不少开造成执行速度慢。
import time
import threading
from function_scheduling_distributed_framework import task_deco, BrokerEnum,ConcurrentModeEnum
t_start = time.time()
@task_deco('queue_test2_qps', qps=2, broker_kind=BrokerEnum.PERSISTQUEUE,concurrent_mode=ConcurrentModeEnum.THREADING,concurrent_num=600 )
def f2(a, b):
"""
这个例子是测试函数耗时是动态变化的,这样就不可能通过提前设置参数预估函数固定耗时和搞鬼了。看看能不能实现qps稳定和线程池自动扩大自动缩小
要说明的是打印的线程数量也包含了框架启动时候几个其他的线程,所以数量不是刚好和所需的线程计算一样的。
"""
result = a + b
sleep_time = 0.01
if time.time() - t_start > 60: # 先测试函数耗时慢慢变大了,框架能不能按需自动增大线程数量
sleep_time = 7
if time.time() - t_start > 120:
sleep_time = 30
if time.time() - t_start > 240: # 最后把函数耗时又减小,看看框架能不能自动缩小线程数量。
sleep_time = 0.8
if time.time() - t_start > 300:
sleep_time = None
print(f'{time.strftime("%H:%M:%S")} ,当前线程数量是 {threading.active_count()}, {a} + {b} 的结果是 {result}, sleep {sleep_time} 秒')
if sleep_time is not None:
time.sleep(sleep_time) # 模拟做某事需要阻塞n秒种,必须用并发绕过此阻塞。
return result
if __name__ == '__main__':
f2.clear()
for i in range(1000):
f2.push(i, i * 2)
f2.consume()####win之1

####win之2

3.1.3控频功能证明,使用内网连接broker,设置函数的qps为100,来调度需要消耗任意随机时长的函数,能够做到持续精确控频,频率误差小。如果设置每秒精确运行超过5000次以上的固定频率,前提是cpu够强。

(需要设置函数状态持久化为True才支持此项功能,默认不开启函数状态结果持久化, 使用的是自动批量聚合插入mongo的方式,需要安装mongodb)。

实测在进行阻塞式任务时候,性能大幅超过celery。
1)高并发

2)函数结果和运行次数和错误异常查看。使用的测试函数如下。
def add(a, b):
logger.info(f'消费此消息 {a} + {b} 中。。。。。')
time.sleep(random.randint(3, 5)) # 模拟做某事需要阻塞10秒种,必须用并发绕过此阻塞。
if random.randint(4, 6) == 5:
raise RandomError('演示随机出错')
logger.info(f'计算 {a} + {b} 得到的结果是 {a + b}')
return a + b

3)任务消费统计曲线。

在修改为每行最大240个字符后,其余的任何警告级别都保持默认的情况下,
所有文件任意一行在pycahrm的code编辑区域的滚动条做到了0个黄色,和使用alt + shift + i检查,符合极致的pep8规则。

{
"body": "W1szLCA2XSwge30sIHsiY2FsbGJhY2tzIjogbnVsbCwgImVycmJhY2tzIjogbnVsbCwgImNoYWluIjogbnVsbCwgImNob3JkIjogbnVsbH1d",
"content-encoding": "utf-8",
"content-type": "application/json",
"headers": {
"lang": "py",
"task": "test_task\u554a",
"id": "39198371-8e6a-4994-9f6b-0335fe2e9b92",
"shadow": null,
"eta": null,
"expires": null,
"group": null,
"retries": 0,
"timelimit": [
null,
null
],
"root_id": "39198371-8e6a-4994-9f6b-0335fe2e9b92",
"parent_id": null,
"argsrepr": "(3, 6)",
"kwargsrepr": "{}",
"origin": "gen22848@FQ9H7TVDZLJ4RBT"
},
"properties": {
"correlation_id": "39198371-8e6a-4994-9f6b-0335fe2e9b92",
"reply_to": "3ef38b98-1417-3f3d-995b-89e8e15849fa",
"delivery_mode": 2,
"delivery_info": {
"exchange": "",
"routing_key": "test_a"
},
"priority": 0,
"body_encoding": "base64",
"delivery_tag": "59e39055-2086-4be8-a801-993061fee443"
}
}
额外控制参数如重试、超时kill,由代码决定, 不需要存到中间件里面去。例如函数运行超时大小在本地代码修改后,立即生效。
不由中间件里面的配置来决定。 (现在也加入了少量优先级控制参数,队列里面消息任务的配置将覆盖python代码的consumer配置,但还是可以人为构造出来,没有celery那么难人为构造)
{"a":3,"b":6}
这样做好处有:
1)修改代码时候,函数控制功能立即生效。举个例子原来是设置的函数运行时间超时10秒kill,现在想设置20秒超时kill,对于celery已经发布的任务,还是10秒, 此框架的方式立即生效。
2)celery的方式不是跨平台,如果发布方和消费方不在同一个git项目,不能直接调用。例如java人员或ai人员并不能直接调用你项目里面的add.delay(1,2)这样写来发布消息, 非常难以构造出来上面celery任务的那一长串东西,几乎不可能。
测试的消费基准函数为简单地求和函数,两个框架都推送和消费20000次。
都使用gevent并发模型,相同并发数量 相同的linux机器内网连接中间件下反复测试的。
假设框架包装和调度一个函数执行的代码需要消耗的cpu执行时间是t1,消费函数自身需要的cpu执行时间是t2,
如果消费函数本身非常简单,例如消费函数是def f(x): print(x)这种机器简单地,那么t1远大于t2,
此时celery的t1远大于此框架的t1,所以出现了10倍的性能差距。
如果消费函数非常复杂,执行逻辑需要消耗的cpu时间远大于调度和包装一个函数的cpu执行时间,即t2远大于t1,
此时相同的非常复杂的消费函数逻辑,两个框架的执行效率就不会出现有10倍的差距。
如果有人怀疑吹牛,可以试试十分简单地求和函数,不做limit_rate控频,使用redis中间件,测试执行2万次函数消耗的时间,
我指的是单进程,并发模式gevent evetlet你随意测试。我电脑cpu频率低一点,消费2万次时间是69秒,频率高一点的cpu,怎么也得30秒。
此框架单进程情况下执行2万次求和需要时间是7秒。
如果不信的人可以自己测试一下,如果测试后你的celery单进程(或在单核电脑),你使用任意gvent eventlet threading模式能在30秒内完成2万次求和,
我愿意转账2000元你,如果你测试后30秒不能完成2万次求和,你只需要转账1000元给我就可以。鄙视又怀疑又不愿意亲自测试的人。
不是celery不行,而是实现手段上包袱上有区别,如果你直接裸写 redis + lpush + brpop + Threadpoolexecutor,调度上面的函数,
你会发现你也可以暴击celery几十倍也可以秒杀此框架好多倍,复杂调用链路长的代码一般都会消耗更多的cpu,导致运行耗时变长。
celery的kombu性能很差,再加上celery性能也不行,造成celery慢很多,此框架也支持kombu操作中间件,再换成konbu操作redis而不是redispy操作redis时候,
光用这个kombu性能就会降低4倍了。
如果有人说,不要限定成不准使用多进程模式只能使用其他并发模式,说这样那就没意义了,
测试条件要对等,一定要坚持控制变量法,变化的只能是使用上面框架;具体开多少并发,并发模式选择进程还是gevent eventlet threading 中间件类型 中间件地址 这些要全部保持一致。
如果你非要吧celery开4个进程,那么此分布式函数调度框架也学样开4个进程,那么7秒钟就不止是消费2万次了,应该是8万次左右了。
celery_app.config_from_object(Config2)
@celery_app.task(name='求和啊',)
def add(a, b):
print(f'计算 {a} + {b} 得到的结果是 {a + b}')
return a + b
if __name__ == '__main__':
celery_app.worker_main(
argv=['worker', '--pool=gevent', '--concurrency=50', '-n', 'worker1@%h', '--loglevel=debug',
'--queues=queue_add', '--detach',])def add(a, b):
# if random.randint(4, 6) == 5:
# raise RandomError('演示随机出错')
print(f'计算 {a} + {b} 得到的结果是 {a + b}')
return a + b
# 把消费的函数名传给consuming_function,就这么简单。
consumer_add = get_consumer('queue_test569', consuming_function=add, max_retry_times=2,
qps=0, log_level=10, logger_prefix='zz平台消费',
concurrent_mode=2, broker_kind=2, ) # 通过设置broker_kind,一键切换中间件为rabbitmq或redis等数十种中间件或包。
if __name__ == '__main__':
consumer_add.start_consuming_message()答:与rq相比,rq只是基于redis一种中间件键,并且连最基本的并发方式和并发数量都没法指定
,更不用说包括控频 等一系列辅助控制功能,功能比celery差太远了,也和此框架不能比较。
这个框架的最开始实现绝对没有受到celery框架的半点启发。
这是从无数个无限重复复制粘贴扣字的使用redis队列的py文件中提取出来的框架。
原来有无数个这样的脚本。以下为伪代码演示,实际代码大概就是这个意思。
while 1:
msg = redis_client.lpop('queue_namex')
funcx(msg)
原来有很多个这样的一些列脚本,无限次地把操作redis写到业务流了。
排除无限重复复制粘贴不说,这样除了redis分布式以外,缺少了并发、
控频、断点接续运行、定时、指定时间不运行、
消费确认、重试指定次数、重新入队、超时杀死、计算消费次数速度、预估消费时间、
函数运行日志记录、任务过滤、任务过期丢弃等数十种功能。
所以这个没有借鉴celery,只是使用oop转化公式提取了可复用流程的骨架模板,然后慢慢增加各种辅助控制功能和中间件。
这个和celery一样都属于万能分布式函数调度框架,函数控制功能比rq丰富。比celery的优点见以下解答。
答: 为了直接表达框架的意思。
答: 支持python内置Queue对象作为当前解释器下的消息队列。
支持sqlite3作为本机持久化消息队列。
支持pika包实现的使用rabbitmq作为分布式消息队列。
支持rabbitpy包实现的使用rabbitmq作为分布式消息队列。
支持amqpstorm包实现的使用rabbitmq作为分布式消息队列。
支持redis中间件作为分布式消息队列。(不支持消费确认,例如把消息取出来了,但函数还在运行中没有运行完成,
突然关闭程序或断网断电,会造成部分任务丢失【设置的并发数量越大,丢失数量越惨】,所以推荐mq)
支持mongodb中间件作为分布式消息队列。
答: python内置Queue对象作为当前解释器下的消息队列,
优势:不需要安装任何中间件,消息存储在解释器的变量内存中,调度没有io,传输速度损耗极小,
和直接一个函数直接调用另一个函数差不多快。
劣势:只支持同一个解释器下的任务队列共享,不支持单独启动的两个脚本共享消息任务。
没有持久化,解释器退出消息就消失,代码不能中断。 没有分布式。
persistqueue sqlite3作为本机持久化消息队列,
优势: 不需要安装中间件。可以实现本机消息持久化。支持多个进程或多个不同次启动那个的脚本共享任务。
劣势: 只能单机共享任务。 无法多台机器共享任务。分布式能力有限。
redis 作为消息队列,
优势: 真分布式,多个脚本和多态机器可以共享任务。
劣势: 需要安装redis。 是基于redis的list数组结构实现的,不是真正的ampq消息队列,
不支持消费确认,所以你不能在程序运行中反复随意将脚本启动和停止或者反复断电断网,
这样会丢失相当一部分正在运行的消息任务,断点接续能力弱一些。
mongo 作为消息队列:
优势: 真分布式。是使用mongo col里面的的一行一行的doc表示一个消息队列里面的一个个任务。支持消费确认。
劣势: mongo本身没有消息队列的功能,是使用三方包mongo-queue模拟的消息队列。性能没有专用消息队列好。
rabbitmq 作为消息队列:
优势: 真正的消息队列。支持分布式。支持消费确认,支持随意关闭程序和断网断电。连金融支付系统都用这个,可靠性极高。完美。
劣势: 大多数人没安装这个中间件,需要学习怎么安装rabbitmq,或者docker安装rabbitmq。
kafka 作为消息队列:
优势:性能好吞吐量大,中间件扩展好。kafka的分组消费设计得很好,
还可以随时重置偏移量,不需要重复发布旧消息。
劣势:和传统mq设计很大的不同,使用偏移量来作为断点接续依据,需要消费哪些任务不是原子性的,
偏移量太提前导致部分消息重复消费,太靠后导致丢失部分消息。性能好需要付出可靠性的代价。
高并发数量时候,主题的分区如果设置少,确认消费实现难,框架中采用自动commit的方式。
要求可靠性 一致性高还是用rabbitmq好。
nsq 作为消息队列:
优势:部署安装很简单,比rabittmq和kafka安装简单。性能不错。
劣势:用户很少,比rabbitmq用户少了几百倍,导致资料也很少,需要看nsq包的源码来调用一些冷门功能。
redis 可确认消费方式,作为消息队列,
优势: 真分布式,多个脚本和多态机器可以共享任务。某个消费者突然关闭或者宕机,不会造成内存中正在运行的任务丢失。
劣势: 需要安装redis。
sqlalchemy 作为消息队列,
优势: 真分布式,一次性支持了5种关系型数据库每个队列由一张表来模拟,每个任物是表中的一行;
比直接弹出元素的队列,方便统计消费情况。
劣势: 由于是数据库模拟的消息队列,比原生的mq和redis kafka等直接将任物新增到队尾的方式,性能差很多。
所有中间件总结评分:
总体来说首选rabbitmq,所以这也是不指定broker_kind参数时候的默认的方式。
答: 1) 如5.4所写,新增了python内置 queue队列和 基于本机的持久化消息队列。不需要安装中间件,即可使用。
2) 性能比celery框架提高一丝丝。
3) 公有方法,需要被用户调用的方法或函数一律都没有使用元编程,不需要在消费函数上加app.task这样的装饰器。
例如不 add.delay(1,2)这样发布任务。 不使用字符串来import 一个模块。
过多的元编程过于动态,不仅会降低性能,还会让ide无法补全提示,动态一时爽,重构火葬场不是没原因的。
4) 全部公有方法或函数都能在pycharm智能能提示补全参数名称和参数类型。
一切为了调用时候方便而不是为了实现时候简略,例如get_consumer函数和AbstractConsumer的入参完全重复了,
本来实现的时候可以使用*args **kwargs来省略入参,
但这样会造成ide不能补全提示,此框架一切写法只为给调用者带来使用上的方便。不学celery让用户不知道传什么参数。
如果拼错了参数,pycharm会显红,大大降低了用户调用出错概率。
5)不使用命令行启动,在cmd打那么长的一串命令,容易打错字母。并且让用户不知道如何正确的使用celery命令,不友好。
此框架是直接python xx.py 就启动了。
6)框架不依赖任何固定的目录结构,无结构100%自由,想把使用框架写在哪里就写在哪里,写在10层级的深层文件夹下都可以。
脚本可以四处移动改名。celery想要做到这样,要做额外的处理。
7)使用此框架比celery更简单10倍,如例子所示。使用此框架代码绝对比使用celery少几十行。
8)消息中间件里面存放的消息任务很小,简单任务 比celery的消息小了50倍。 消息中间件存放的只是函数的参数,
辅助参数由consumer自己控制。消息越小,中间件性能压力越小。
9)由于消息中间件里面没有存放其他与python 和项目配置有关的信息,这是真正的跨语言的函数调度框架。
java人员也可以直接使用java的redis类rabbitmq类,发送json参数到中间件,由python消费。
celery里面的那种参数,高达几十项,和项目配置混合了,java人员绝对拼凑不出来这种格式的消息结构。
10)celery有应该中心化的celery app实例,函数注册成任务,添加装饰器时候先要导入app,然后@app.task,
同时celery启动app时候,调度函数就需要知道函数在哪里,所以celery app所在的py文件也是需要导入消费函数的,否则会
celery.exceptions.NotRegistered报错
这样以来就发生了务必蛋疼的互相导入的情况,a要导入b,b要导入a,这问题太令人窘迫了,通常解决这种情况是让其中一个模块后导入,
这样就能解决互相导入的问题了。celery的做法是,使用imports一个列表,列表的每一项是消费函数所在的模块的字符串表示形式,
例如 如果消费函数f1在项目的a文件夹下的b文件夹下的c.py中,消费函数与f2在项目的d文件夹的e.py文件中,
为了解决互相导入问题,celery app中需要配置 imports = ["a.b.c",'d.e'],这种import在pycharm下容易打错字,
例如scrapy和django的中间件注册方式,也是使用的这种类似的字符串表示导入路径,每添加一个函数,只要不在之前的模块中,就要这么写,
不然不写improt的话,那是调度不了消费函数的。此框架原先没有装饰器方式,来加的装饰器方式与celery的用法大不相同,
因为没有一个叫做app类似概念的东西,不需要相互导入,启动也是任意文件夹下的任意脚本都可以,自然不需要写什么imports = ['a.b.c']
11)简单利于团队推广,不需要看复杂的celry 那样的5000页英文文档。
对于不规则文件夹项目的clery使用时如何的麻烦,可以参考 celery_demo项目 https://github.com/ydf0509/celery_demo。
12)此库支持 asyncio 原始函数,不用用户额外处理 asyncio loop相关麻烦的问题。celery不支持async定义的函数,celery不能把@app.task
加到一个async def 的函数上面。
13) 这是最重要的,光使用简单还不够,性能是非常重要的指标。
此框架消息发布性能和消息消费性能远远超过celery数十倍。为此专门开了一个对比项目,发布和消费10万任务,
对分布式函数调度框架和celery进行严格的控制变量法来benchmark,分别测试两个框架的发布和消费性能。
对比项目在此,可以直接拉取并分别运行两个项目的发布和消费一共4个脚本。
https://github.com/ydf0509/distrubuted_framework_vs_celery_benchmark
答:框架默认使用json。并且不提供序列化方式选择,有且只能用json序列化。json消息可读性很强,远超其他序列化方式。
默认使用json来序列化和反序列化消息。所以推送的消息必须是简单的,不要把一个自定义类型的对象作为消费函数的入参,
json键的值必须是简单类型,例如 数字 字符串 数组 字典这种。不可以是不可被json序列化的python自定义类型的对象。
用json序列化已经满足所有场景了,picke序列化更强,但仍然有一些自定义类型的对象的实例属性由于是一个不可被序列化
的东西,picke解决不了,这种东西例如self.r = Redis(),而redis对象又包括threding.Lock类型的属性 ,不可以被pike序列化
就算能序列化的对象也是要用一串很长的东西来。
用pike来序列化复杂嵌套属性类型的对象,不仅会导致中间件要存储很大的东西传输效率会降低,在编码和解码也会消耗更多的cpu。如果框架支持了pike序列化,会让使用者养成不好的粗暴习惯。
想消费函数传redis对象作为入参,这种完全可以使用json来解决,例如指定ip 和端口,在消费函数内部来使用redis。所以用json一定可以满足一切传参场景。
如果json不能满足你的消费任务的序列化,那不是框架的问题,一定是你代码设计的问题。所以没有预留不同种类序列化方式的扩展,
也不打算准备加入其他序列化方式。
答:使用的是定时发布任务,那么就能定时消费任务了。导入fsdf_background_scheduler然后添加定时发布任务。
FsdfBackgroundScheduler继承自 apscheduler 的 BackgroundScheduler,定时方式可以百度 apscheduler
import datetime
from function_scheduling_distributed_framework import task_deco, BrokerEnum, fsdf_background_scheduler, timing_publish_deco
@task_deco('queue_test_666', broker_kind=BrokerEnum.LOCAL_PYTHON_QUEUE)
def consume_func(x, y):
print(f'{x} + {y} = {x + y}')
if __name__ == '__main__':
fsdf_background_scheduler.add_job(timing_publish_deco(consume_func), 'interval', id='3_second_job', seconds=3, kwargs={"x": 5, "y": 6}) # 每隔3秒发布一次任务,自然就能每隔3秒消费一次任务了。
fsdf_background_scheduler.add_job(timing_publish_deco(consume_func), 'date', run_date=datetime.datetime(2020, 7, 24, 13, 53, 6), args=(5, 6,)) # 定时,只执行一次
fsdf_background_scheduler.add_timing_publish_job(consume_func, 'cron', day_of_week='*', hour=14, minute=51, second=20, args=(5, 6,)) # 定时,每天的11点32分20秒都执行一次。
# 启动定时
fsdf_background_scheduler.start()
# 启动消费
consume_func.consume()问的是consuming_function的值能不能是一个类或者一个实例方法。
答:一切对类的调用最后都是体现在对方法的调用。这个问题莫名其妙。
celery rq huery 框架都是针对函数。
调度函数而不是类是因为:
1)类实例化时候构造方法要传参,类的公有方法也要传参,这样就不确定要把中间件里面的参数哪些传给构造方法哪些传给普通方法了。
见5.8
2) 这种分布式一般要求是幂等的,传啥参数有固定的结果,函数是无依赖状态的。类是封装的带有状态,方法依赖了对象的实例属性。
3) 比如例子的add方法是一个是实例方法,看起来好像传个y的值就可以,实际是add要接受两个入参,一个是self,一个是y。如果把self推到消息队列,那就不好玩了。
对象的序列化浪费磁盘空间,浪费网速传输大体积消息,浪费cpu 序列化和反序列化。所以此框架的入参已近说明了,
仅仅支持能够被json序列化的东西,像普通的自定义类型的对象就不能被json序列化了。
celery也是这样的,演示的例子也是用函数(也可以是静态方法),而不是类或者实例方法,这不是刻意要和celery一样,原因已经说了,自己好好体会好好想想原因吧。
框架如何调用你代码里面的类。
假设你的代码是:
class A():
def __init__(x):
self.x = x
def add(self,y):
print( self.x + y)
那么你需要再写一个函数
def your_task(x,y):
return A(x).add(y)
然后把这个your_task函数传给框架就可以了。所以此框架和你在项目里面写类不是冲突的,本人是100%推崇oop编程,非常鲜明的反对极端面向过程编程写代码。
答:基本原理如下
def add(a,b):
print(a + b)
从消息中间件里面取出参数{"a":1,"b":2}
然后使用 add(**{"a":1,"b":2}),就是这样运行函数的。
答:分布式 、并发、 控频、断点接续运行、定时、指定时间不运行、
消费确认、重试指定次数、重新入队、超时杀死、计算消费次数速度、预估消费时间、
函数运行日志记录、任务过滤、任务过期丢弃等数十种功能。
只需要其中的某一种功能就可以使用这。即使不用分布式,也可以使用python内置queue对象。
这就是给函数添加几十项控制的超级装饰器。是快速写代码的生产力保障。
适合一切耗时的函数,不管是cpu密集型 还是io密集型。
不适合的场景主要是:
比如你的函数非常简单,仅仅只需要1微妙 几十纳秒就能完成运行,比如做两数之和,print一下hello,这种就不是分需要使用这种框架了,
如果没有解耦的需求,直接调用这样的简单函数她不香吗,还加个消息队列在中间,那是多此一举。
答:先写自己的函数(类)来实现业务逻辑需求,不需要思考怎么导入框架。
写好函数后把 函数和队列名字绑定传给消费框架就可以了。一行代码就能启动分布式消费。
RedisConsmer('queue_name',consuming_function=your_function).start_consuming_message()
所以即使你不想用这个框架了,你写的your_function函数代码并没有作废。
所以不管是引入这个框架 、废弃使用这个框架、 换成celery框架,你项目的99%行 的业务代码都还是有用的,并没有成为废物。
答: 需要学习真oop和36种设计模式。唯有oop编程思想和设计模式,才能持续设计开发出新的好用的包甚至框架。
如果有不信这句话的,你觉得可以使用纯函数编程,使用0个类来实现这样的框架。
如果完全不理会设计模式,实现threding gevent evenlet 3种并发模式,加上10种中间件类型,实现分布式消费流程,
需要反复复制粘贴扣字30次。代码绝对比你这个多。例如基于nsq消息队列实现任务队列框架,加空格只用了80行。
如果完全反对oop,需要多复制好几千行来实现。
例如没听说设计模式的人,在写完rabbitmq版本后写redis版本,肯定十有八九是在rabbitmq版本写完后,把整个所有文件夹,
全盘复制粘贴,然后在里面扣字母修改,把有关rabbitmq操作的全部扣字眼修改成redis。如果某个逻辑需要修改,
要在两个地方都修改,更别说这是10几种中间件,改一次逻辑需要修改10几次。
我接手维护得老项目很多,这种写法的编程思维的是特别常见的,主要是从来没听说设计模式4个字造成的,
在我没主动学习设计模式之前,我也肯定会是这么写代码的。
只要按照36种设计模式里面的oop4步转化公式思维写代码三个月,光就代码层面而言,写代码的速度、流畅度、可维护性
不会比三年经验的老程序员差,顶多是老程序员的数据库 中间件种类掌握的多一点而已,这个有机会接触只要花时间就能追赶上,
但是编程思维层次,如果没觉悟到,可不是那么容易转变的,包括有些科班大学学过java的也没这种意识,
非科班的只要牢牢抓住把设计模式 oop思维放在第一重要位置,写出来的代码就会比科班好,
不能光学 if else 字典 列表 的基本语法,以前我看python pdf资料时候,资料里面经常会有两章以上讲到类,
我非常头疼,一看到这里的章节,就直接跳过结束学习了,现在我也许只会特意去看这些章节,
然后看资料里面有没有把最本质的特点讲述好,从而让用户知道为什么要使用oop,而不是讲下类的语法,这样导致用户还是不会去使用的。
你来写完包括完成10种中间件和3种并发模式,并且预留消息中间件的扩展。
然后我们来和此框架 比较 实现框架难度上、 实现框架的代码行数上、 用户调用的难度上 这些方面。
如你所见,使用此框架为什么没有配置中间件的 账号 密码 端口号呢。只有运行任何一个导入了框架的脚本文件一次,就会自动生成一个配置文件
然后在配置文件中按需修改需要用到的配置就行。
@task_deco 和celery的 @app.task 装饰器区别很大,导致写代码方便简化容易很多。没有需要先实例化一个 Celery对象一般叫app变量,
然后任何脚本的消费函数都再需要导入这个app,然后@app.task,一点小区别,但造成的两种框架写法难易程度区别很大。
使用此框架,不需要固定的项目文件夹目录,任意多层级深层级文件夹不规则python文件名字下写函数都行,
celery 实际也可以不规则文件夹和文件名字来写任务函数,但是很难掌握,如果这么写的话,那么在任务注册时候会非常难,
一般demo演示文档都不会和你演示这种不规则文件夹和文件名字下写celery消费函数情况,因为如果演示这种情况会非常容易的劝退绝大部分小白。
但是如果不精通celery的任务注册导入机制同时又没严格按照死板固定的目录格式来写celery任务,
一定会出现令人头疼的 Task of kind 'tasks.add' is not registered, please make sure it's imported. 类似这种错误。
主要原因是celery 需要严格Celery类的实例化对象app变量,然后消费函数所在脚本必须import这个app,这还没完,
你必须在settings配置文件写 include imports 等配置,否则cmd 启动celery 后台命令时候,celery并不知情哪些文件脚本导入了 app这个变量,
当celery框架取出到相关的队列任务时候,就会报错找不到应该用哪个脚本下的哪个函数去运行取出的消息了。
你可能会想,为什么celery app 变量的脚本为什么不可以写导入消费函数的import声明呢,比如from dir1.dir2.pyfilename imprt add 了,
这样celery运行时候就能找到函数了是不是?那要动脑子想想,如果celery app主文件用了 from dir1.dir2.pyfilename import add,
同时消费函数 add 所在的脚本 dir1/dir2/pyfilename.py 又从celery app的猪脚本中导入app,然后把@app.task加到add函数上面 ,
那这就是出现了互相导入,a导入b,b导入a的问题了,脚本一启动就报错,正是因为这个互相导入的问题,
celery才需要从配置中写好 include imports autodiscover_tasks,从而实现一方延迟导入以解决互相导入。
此框架的装饰器不存在需要一个类似Celery app实例的东西,不会有这个变量将大大减少编程难度,消费函数写在任意深层级不规则文件下都行。

不规则文件夹层级和名称下的celery使用演示
https://github.com/ydf0509/celery_demo

可以看代码,当文件夹层级不规则和文件名称不规则时候,要使用celery绝非简单事情,如果你只看普通的celery入门文档,是绝对解决不了
这种情况下的celery如何正确使用。
在web中推送任务,后台进程消费任务,很多人问怎么在web使用,用法和不与web框架搭配并没有什么不同之处。
因为发布和消费是使用中间件解耦的,一般可以分成web接口启动一次,后台消费启动一次,需要独立部署两次。
演示了flask 使用app应用上下文。
演示例子在
test_frame\use_in_flask_tonardo_fastapi
支持运行过程中,随意关闭和启动python程序。无惧反复关闭python和 突然断电导致任务丢失几百个。
之前开100线程/协程的话,随意重启python和断电会导致极大概率丢失200个任务。
官方Threadpoolexecutor是无界队列。使用这个会导致丢失无数个任务,
因为他会迅速把redis的消息全部取出来,添加到自己的queue队列慢慢消费。
因为这个原因所以需要自定义写BoundedThreadpoolexecutor和CustomThreadpoolexecutor。
改版的CustomThreadpoolexecutor修改成了queue最大长度是max_works,自己内部存储100个,
运行中100个,突然关闭python会丢失200个任务。如果queue设置大小为0,则只会丢失100个运行中的任务。
采用的是消费者去除消息时候,用lua脚本同时pop和添加到unacked的独立zset中,函数运行成功后会从set中删除该任务。
同时有一个一直每隔5秒发送心跳到redis服务中的线程,心跳标识中有消费者的唯一标识,绝对不会重复。
如果突然关闭消费者(例如突然断电或者点击关闭python),那么该消费者的心跳将会停止了。这时其他机器的同队列消费者或者当前机器重新启动代码后,在15秒后会
检到被关闭的消费者是非活跃消费者,那么自动将该消费者的unack里面任务全部重新取出返回到待消费队列中。
RedisConsumerAckAble类比RedisConsumer会有一丝丝性能损耗,但python玩redis大部分情况还是python代码本身有性能瓶颈,
而不是造成redis服务端有性能瓶颈,一般只要用在有意义的业务上,就算python很忙把cpu占光了,也不会造成redis服务端达到极限,
python是性能很差的语言,没玩垮redis,自身就把电脑玩死了,所以大部分情况下不要在意加入确认消费后产生额外的对redis服务端的性能压力。
redis要是能直接作为mq使用,redis早就一统天下了,哪里还不断有几十种mq出来。
所以直接基于redis list的如果要做到可靠就必须改进。
基于redisboard,但对redis的list模拟mq功能,进行页面显示优化突出消息队列消费,
加黄显示正在运行中的队列和每10秒的消费速度。每隔10秒自动刷新统计。
由于实时发布和消费,例如10秒内发布20个,消费50个,页面只能显示大小降低了30个,
这个只有专业的mq才能分别显示出来,redis list只是简单数组。
rabbitmq nsq都有官方自带速率显示。

对比concurrent_log_handler包的 ConcurrentRotatingFileHandler ,
windows下性能提高100倍,linux提高10倍,不信的可以测试对比原三方版。
日志用法不变。默默改变多进程文件切片日志,steramhanlder不变,任然是五彩可点击跳转。

主要在原来基础上实现汉化 彩色 可点击跳转功能。只是放在里面,功能与此框架完全无关。
用法见test_pysnooper.py文件。
可以用来查看执行了哪些代码行 逻辑分支走向,也可以用来度量程序性能,能精确显示运行了多少行python代码。
例如这个可以发现redis.set命令需要执行1000行py代码,
requests.get("https://www.baidu.com")需要执行3万行代码,如果不用工具是万万想不到到底执行了多少行python代码的。

beggar_redis_consumer.py文件的 start_consuming_message函数。
def start_consuming_message(queue_name, consume_function, threads_num):
pool = ThreadPoolExecutor(threads_num)
while True:
try:
redis_task = redis_db_frame.brpop(queue_name, timeout=60)
if redis_task:
task_str = redis_task[1].decode()
print(f'从redis的 {queue_name} 队列中 取出的消息是: {task_str}')
pool.submit(consume_function, **json.loads(task_str))
else:
print(f'redis的 {queue_name} 队列中没有任务')
except redis.RedisError as e:
print(e)
def add(x, y):
time.sleep(5)
print(f'{x} + {y} 的结果是 {x + y}')
# 推送任务
for i in range(100):
redis_db_frame.lpush('test_beggar_redis_consumer_queue', json.dumps(dict(x=i, y=i * 2)))
# 消费任务
start_consuming_message('test_beggar_redis_consumer_queue', consume_function=add, threads_num=10)看完整版代码很长很多,是由于控制功能太多,中间件类型多,并发模式多, 所以加入一个最精简版,精简版的本质实现原理和完整版相同。
每个队列是一张表模拟的。

每个任务是表里面的一行记录。

只要导入了此框架,那么你的项目里面所有print的行为都会直接发生改变。
控制台彩色和可点击跳转很重要,原来是必须使用我框架带的日志才能变成五彩可点击,
或者需要使用框架里面的nb_print函数来打印,才能使打印变成彩色可点击。
现在则直接改变项目所有直接使用print的地方。



有的人在项目中疯狂的例如 print(x),结果项目运行一层一层的调用,很难找到当时是哪里打印的x,几乎不可能找得到的。
除非他是这么写代码 print("x的值是:",x) ,只有这样才有可能通过ide的全局搜索找得到print的地方。
再说代码里面疯狂频繁print本来就不是好的习惯,谁让你那么频繁的print呢。
原来是需要手动调用patch_frame_config函数来设置框架中间件配置,现在新增一种方式。
用户运行一次任意导入了function_scheduling_distributed_framework框架的文件,
框架自动寻找用户的项目根目录,并在用户的项目的根目录下生成一个 distributed_frame_config.py的文件。
生成的distributed_frame_config.py文件 中包含了所有默认配置项,但以 # 做了注释。
用户需要按需修改用到的中间件的值。框架自动读取distributed_frame_config.py文件中变量的值作为框架的配置。
也可以将distributed_frame_config.py文件移到你的python文件运行起点所在的目录,
框架会优先读取python文件运行起点所在的目录中的distributed_frame_config.py 作为配置,
没找到则读取项目根目录下的distributed_frame_config.py作为配置。同时兼容以最后一次手动调用patch_frame_config函数作为追踪配置。

例如设置默认需不需要彩色,需不需要大背景彩色色块,需不需要自动拦截转化python内置的print.
将qps按范围分段,采用不同的等待或计数方式。使当qps设置很高的时候,控频更精确。
增加了分布式控频,需要依赖redis中间件。
分布式环境中的控频指的是,假如xx.py文件中有一个consumer,设置func函数的qps为10。
如果在线上部署了三个容器服务,如果不使用分布式控频,则func函数的每秒运行总次数会是30。
即使只有1台机器,如果开多进程,Process运行3个进程,或者把xx.py反复运行启动3个,
也会造成func函数每秒运行总次数是30。
分布式控频主要是解决这种问题。默认不使用分布式控频,
当设置 is_using_distributed_frequency_control为True的时候,使用分布式控频。
这次使用修改你的项目根目录下的自动生成的distributed_frame_config.py配置文件的方式来进行redis rabbitmq等的配置。
不用调用patch_frame_config函数的方式进行配置。
装饰器版,使用方式例如:
from function_scheduling_distributed_framework import task_deco
@task_deco('queue_test_f01', qps=0.2, broker_kind=2)
def add(a, b):
print(a + b)
for i in range(10, 20):
add.pub(dict(a=i, b=i * 2)) # 使用add.pub 发布任务
add.push(i, b=i * 2) # 使用add.push 发布任务
add.consume() # 使用add.consume 消费任务对比常规方式,常规方式使用方式如下
from function_scheduling_distributed_framework import get_consumer
def add(a, b):
print(a + b)
# 需要手动指定consuming_function入参的值。
consumer = get_consumer('queue_test_f01', consuming_function=add,qps=0.2, broker_kind=2)
for i in range(10, 20):
consumer.publisher_of_same_queue.publish(dict(a=i, b=i * 2))
consumer.start_consuming_message()装饰器版本的 task_deco 入参 和 get_consumer 入参99%一致,唯一不同的是 装饰器版本加在了函数上自动知道消费函数了,
所以不需要传consuming_function参数。
from function_scheduling_distributed_framework import task_deco, BrokerEnum
@task_deco('queue_test_f03', qps=2, broker_kind=BrokerEnum.ROCKETMQ)
def f(a, b):
print(f'{a} + {b} = {a + b}')
if __name__ == '__main__':
for i in range(100):
f.push(i, i * 2)
f.consume()之前一直都没支持这种并发模式,异步代码不仅消费函数本身与同步代码很多不同,例如函数的定义和调用以及三方库,
不同于gevent和eventlet打个猴子补丁就可以变并发方式并且代码保持100%原样,asyncio的方式代比同步码真的是要大改特改。
而且在框架层面要支持异步也要增加和修改很多,支持异步并不是很容易。这一点连celery5.0目前都还没支持到(据官方文档说5.0要加入支持,但目前的5.0.3还没加入。)
如果消费函数已经写成了async def这种,那么可以设置 concurrent_mode=ConcurrentModeEnum.ASYNC,
框架会在一个新的线程的loop里面自动运行协程,所有协程任务会自动在一个loop里面运行,不是每次临时都生成新的loop只运行一个当前任务方式。
from function_scheduling_distributed_framework import task_deco, BrokerEnum,ConcurrentModeEnum
import asyncio
# 此段代码使用的是语言级Queue队列,不需要安装中间件,可以直接复制运行测试。
@task_deco('test_async_queue2', concurrent_mode=ConcurrentModeEnum.ASYNC,
broker_kind=BrokerEnum.LOCAL_PYTHON_QUEUE, concurrent_num=500,qps=20)
async def async_f(x):
# 测试异步阻塞并发, 此处不能写成time.sleep(1),否则无论设置多高的并发,1秒钟最多只能运行1次函数。
# 同理asyncio 不能和 requests搭配,要和 aiohttp 搭配。
await asyncio.sleep(1)
print(id(asyncio.get_event_loop()))
#通过 id 可以看到每个并发函数使用的都是同一个loop,而不是采用了愚蠢的临时 asyncio.new_event_loop().run_until_complete(async_f(x)) 方式调度。
print(x)
if __name__ == '__main__':
async_f.clear()
for i in range(100):
async_f.push(i, )
async_f.consume()比方说汽车的自动挡和手动挡,学了手动挡一定会开自动挡,只学自动挡很难开手动挡。
asyncio方式的代码比正常普通同步思维的代码写法也要难得多了,能玩asyncio的人一定会用threading gevent,
但只用过threading gevent,不去专门学习asyncio的用法,100%是玩不转的。
gevent就像自动挡汽车,自动换挡相当于自动切换阻塞。
asyncio就像手动挡,全要靠自己写 await / async def /loop / run_until_complete /run_forever/
run_coroutine_threadsafe /wait / wait_for /get_event_loop / new_event_loop / get_running_loop
,写法很麻烦很难。异步多了一个loop就像手动挡汽车多了一个离合器一样,十分之难懂。
手动挡玩的溜性能比自动挡高也更省油。asyncio玩的溜那么他的io并发执行速度和效率也会更好,cpu消耗更少。
如果你写一般的代码,那就用同步方式思维来写吧,让分布式函数调度框架来替你自动并发就可以啦。
如果追求更好的控制和性能,不在乎代码写法上的麻烦,并且asyncio技术掌握的很溜,那就用asyncio的方式吧。
异步鬓发模式里面,整个调用链路必须是一旦异步,必须处处异步,在base_consumer.py的AbstractConsumer中,
方法 _async_run_consuming_function_with_confirm_and_retry里面使用的还是操作中间件的同步库,
主要是因为框架目前支持15种中间件,一个一个的使用异步模式的库操作中间件来实现,比现在代码起码要增加80%,无异于重写一个项目了。
异步和同步真的写法语法相差很大的,不信可以比比aiomysql 和pymysql库,aiohttp和requests,如果非常简单能实现异步,
那aiohttp和aiomysql作者为什么要写几万行代码来重新实现,不在原来基础上改造个七八行来实现?
目前此库对 消息拉取和消息消费完全是属于在两个不同的线程里面,井水不犯河水,所以用同步库拉取消息对asyncio的消费函数没有任何影响,不存在同步库阻塞异步库的问题。
对于消息确认 消息重新入队 任务过滤 mongo插入,都是采用的同步库,但是使用了 run_in_executor,
把这些操作在异步链路中交给线程池来运行了,同事这个线程池不是官方内置线程池,是智能缩小扩大线程池 ThreadPoolExecutorShrinkAble。
run_in_executor 会把一个同步的操作,sumbit提交给线程池,线程池返回的是一个concurrent.futures包的Future对象,
run_in_executor包装转化了这个Future(此Future不是asyncio的,不是一个awaitable对象)成为了一个asyncio包的Future对象,asyncio的Future对象可以被await,
所以这是非常快捷的同步阻塞函数在异步链路中转同步转异步语法的最佳方式。官方也是这么推荐的。
除了框架内部的阻塞函数是run_in_executor快速转化成非阻塞事件循环的,但是主要的用户的消费函数,是使用的真async模式运行在一个loop循环中的,
也即是单线陈鬓发运行用户的异步函数。
其次框架的同步阻塞函数,都是操作中间件类型的库,异步就是 入队 确认消费 查询是否过滤,这些操作一般都会在1毫秒之内完成,不阻塞太长的事件,
即使不使用run_in_executor,直接在异步链路使用这些同步操作,也没太大问题。一旦异步必须处处异步,说的是不能调用耗时太长的同步阻塞函数,
1毫秒的无伤大雅,因为celery 1秒钟最多能调度300个 def f: print(hello) 这样的无cpu 无io的函数,此框架调度运行速度任然超过celery。
还有一种调度起 async def定义 的消费函数方式是继续开多线程并发,然后使用 临时loop = get_event_loop,loop.run_until_complete,这方式愚蠢了,
相当于只是为了运行起这个函数,但全流程丝毫没有丁点异步。
这个是 redis 的 真消息队列,这次是 真mq,
stream 数据结构功能更加丰富接近 rabbitmq kafka这种真mq的消息队列协议,比 list 做消息队列更强。
需要redis的服务端5.0版本以上才能使用这个数据结构。
代码文件在 function_scheduling_distributed_framework/consumers/redis_stream_consumer.py
这个 REDIS_STREAM 中间件和 REDIS_ACK_ABLE 都支持消费确认,不管客户端怎么掉线关闭,都可以确保消息万无一失。
BrokerEnum.REDIS 中间件 不支持消费确认,随意重启或者断电断线会丢失一批任务。
from function_scheduling_distributed_framework import task_deco, BrokerEnum
@task_deco('queue_test_f01', broker_kind=BrokerEnum.REDIS_STREAM,)
def f(a, b):
print(f'{a} + {b} = {a + b}')
if __name__ == '__main__':
for i in range(100):
f.push(i , b=i * 2)
f.consume()代码演示省略,设置broker_kind=BrokerEnum.RedisBrpopLpush就行了。
@task_deco('queue_test_f01', broker_kind=BrokerEnum.RedisBrpopLpush,)
zeromq 和rabbbitmq kafka redis都不同,这个不需要安装一个服务端软件,是纯代码的。
zeromq方式是启动一个端口,所以queue_name传一个大于20000小于65535的数字,不能传字母。
import time
from function_scheduling_distributed_framework import task_deco,BrokerEnum
@task_deco('30778',broker_kind=BrokerEnum.ZEROMQ,qps=2)
def f(x):
time.sleep(1)
print(x)
if __name__ == '__main__':
f.consume()from test_frame.test_broker.test_consume import f
for i in range(100):
f.push(i) 一次性新增操作10种消息队列,.但比较知名的例如rabbitmq redis sqlite3 函数调度框架已经在之前实现了。
使用方式为设置 @task_deco 装饰器的 broker_kind 为 BrokerEnum.KOMBU
在你项目根目录下的 distributed_frame_config.py 文件中设置
KOMBU_URL = 'redis://127.0.0.1:6379/7' 那么就是使用komb 操作redis。
KOMBU_URL = 'amqp://username:[email protected]:5672/',那么就是操纵rabbitmq
KOMBU_URL = 'sqla+sqlite:////dssf_sqlite.sqlite',那么就是在你的代码所在磁盘的根目录创建一个sqlite文件。四个////表示根目,三个///表示当前目录。
其余支持的中间件种类大概有10种,不是很常用,可以百度 google查询kombu或者celery的 broker_url 配置方式。
操作 kombu 包,这个包也是celery的中间件依赖包,这个包可以操作10种中间件(例如rabbitmq redis),
但没包括分布式函数调度框架能支持的kafka nsq zeromq 等。
但是 kombu 包的性能非常差,如何测试对比性能呢?
可以用原生redis的lpush和kombu的publish测试发布
使用brpop 和 kombu 的 drain_events测试消费,对比差距相差了5到10倍。
由于性能差,除非是分布式函数调度框架没实现的中间件才选kombu方式(例如kombu支持亚马逊队列 qpid pyro 队列),
否则强烈建议使用此框架的操作中间件方式而不是使用kombu。
可以把@task_deco装饰器的broker_kind参数 设置为 BrokerEnum.REDIS_ACK_ABLE 和BrokerEnum.KOMBU(配置文件的KOMBU_URL配置为redis),
进行对比,REDIS_ACK_ABLE的消费速度远远超过 BrokerEnum.KOMBU,所以之前专门测试对比celery和此框架的性能,
差距很大,光一个 kombu 就拉了celery大腿很多,再加上celery的除了kombu的执行性能也很低,所以celery比此框架慢很多。
test_frame\test_celery 下面有celery的发布 消费例子,可以测试对比下速度,同样gevent 并发和redis中间件,
celery 执行 print hello 这样的最简单任务,单核单进程每秒执行次数过不了300,celery性能真的是太差了。
import time
from function_scheduling_distributed_framework import task_deco,BrokerEnum
@task_deco('test_kombu2',broker_kind=BrokerEnum.KOMBU,qps=5,)
def f(x):
time.sleep(60)
print(x)
if __name__ == '__main__':
f.consume()from test_frame.test_broker.test_consume import f
for i in range(10000):
f.push(i)KOMBU_URL = 'redis://127.0.0.1:6379/7'
# KOMBU_URL = f'amqp://{RABBITMQ_USER}:{RABBITMQ_PASS}@{RABBITMQ_HOST}:{RABBITMQ_PORT}/{RABBITMQ_VIRTUAL_HOST}'
# KOMBU_URL = 'sqla+sqlite:////celery_sqlite3.sqlite' # 4个//// 代表磁盘根目录下生成一个文件。推荐绝对路径。3个///是相对路径。