{kind=link}
{kind=link}
{kind=link}
{kind=link}
This repository contains samples that demonstate parts of a formal language parsing system. There is a parser generator that takes a formal grammar and generates a data file, and there is a sample simulator that takes such a data file and a user-supplied document and emits information about the syntactic structure of the document according to the formal grammar. The system has an unusual design and unusual characteristics:
- Any context-free grammar can be used. Ambiguity, left recursion, right recursion, infinite look-ahead, cycles in production rules, productions that match the empty string, Unicode, the system is not troubled by any of these. Of course, if you need e.g. ambiguities resolved, you have to implement that yourself as post-processing step (parsers report all possible parse trees in compact form). There are however limits on the overall complexity of the grammar.
- No human input is needed. The system only needs a grammar that can typically be copied from data format specifications; programs that parse documents can be grammar-agnostic and generic. The system does not generate programming language source code files where you have to fill in gaps. You also do not have to modify the grammar to accomodate ambiguity resolution or other algorithms.
- Language-independent, data-driven parsing. Grammars are transformed into tabluar data encoded in simple JSON documents amenable to machine processing. The data files can be shared, re-used, analysed, transformed, compiled, combined, and more, in a portable manner.
- Linear parsing time and memory use. For the low level parser, parsing time and memory use are O(n) in the size of input documents and independent of the grammar. For large input documents it is trivial to make a parser that uses O(1) main memory and writes intermediate results to disk. One caveat: for recursive grammars, parser output requires post-processing with possibly non-linear complexity for some applications.
- Credible performance. It's not just linear, the constants are very small aswell. An optimised parser will do nothing but simple arithmetic, table lookups, and memory writes to store results, and should not do much worse than typical regex engines. Note that parsing is branch-free except for bound iterations, and beyond loading the statically prepared parsing data there are no startup or other initialisation costs.
- Security and standards compliance. Parser construction does not depend on human input and is thus not subject to human error. The data tables describe finite state machines that can be exhaustively simulated or analysed verifying that there are no chances for memory corruption or other problems in dependant code for all inputs. When the input grammar comes from a formal standard, there is no chance to miss edge cases ensuring compliance.
- Robustness and versatility. The parsing system is part of a divide-and-conquer strategy to parsing. A basic parser based on it just solves part of the problem and higher level applications can and have to perform additional work. That enables and encourages a coding style amenable to change.
The typical use of the generated data files is from a parser that makes two passes over an input document and then describes all possible parse trees as a series of edge sets of a larger parse graph. The following example illustrates this.
- Grammar-agnostic low-level parser
- Higher-level parser
- Merging regular paths
- Pairing recursions in parallel
- Combination of data files and parallel simulation
- Handling grammars based on tokens
- Handling data structures other than strings
- Limitations
- Sample applications
- License
The following code is a complete and runnable NodeJS application that
reads a generated parsing data file, as they are included in this
repository, and a document, analyses the syntactic structure of the
document, and then generates a GraphViz-compatible .dot file of the
parse graph (for simple grammars or simple inputs, this is equivalent
to a linearised representation of the "parse tree" of the document
with respect to the relevant grammar).
var fs = require('fs');
var zlib = require('zlib');
var util = require('util');
var as_json = process.argv[4] == "-json";
var input = fs.readFileSync(process.argv[3], {
"encoding": "utf-8"
});
zlib.gunzip(fs.readFileSync(process.argv[2]), function(err, buf) {
var g = JSON.parse(buf);
///////////////////////////////////////////////////////////////////
// Typical grammars do not distinguish between all characters in
// their alphabet, or the alphabet of the input to be parsed, like
// all of Unicode. So in order to save space in the transition
// tables, input symbol are mapped into a smaller set of symbols.
///////////////////////////////////////////////////////////////////
var s = [].map.call(input, function(ch) {
return g.input_to_symbol[ ch.charCodeAt(0) ] || 0
});
///////////////////////////////////////////////////////////////////
// The mapped input symbols are then fed to a deterministic finite
// state automaton. The sequence of states is stored for later use.
// The initial state of the automaton is always `1` by convention.
///////////////////////////////////////////////////////////////////
var fstate = 1;
var forwards = [fstate].concat(s.map(function(i) {
return fstate = g.forwards[fstate].transitions[i] || 0;
}));
///////////////////////////////////////////////////////////////////
// An input string does not necessarily match what the parser is
// expecting. When the whole input is read, and the automaton is
// not in an accepting state, then either there is an error in the
// input, or the input is incomplete. The converse does not necess-
// arily hold. For recursive grammars the automaton might be in an
// accepting state even though the input does not match it.
///////////////////////////////////////////////////////////////////
if (g.forwards[fstate].accepts == "0") {
process.stderr.write("failed around " + forwards.indexOf('0'));
return;
}
///////////////////////////////////////////////////////////////////
// The output of the first deterministic finite state transducer is
// then passed through a second one. At the end of the string it
// knows exactly which paths through the graph have led to a match
// and can now trace them back to eliminate matches that failed.
// The output of the second deterministic finite state transducer
// is a concatenation of edges to be added to the parse graph. As
// before, it starts in state `1` by convention.
///////////////////////////////////////////////////////////////////
var bstate = 1;
var edges = forwards.reverse().map(function(i) {
return bstate = g.backwards[bstate].transitions[i] || 0;
}).reverse();
///////////////////////////////////////////////////////////////////
// The `edges` list is just a list of integers, each identifying a
// set of edges. This is useful for post-processing operations, but
// typical applications will need to resolve them to build a graph
// for traversal. As an example, this function will print out the
// whole parse graph as a GraphViz `dot` file that can be rendered.
///////////////////////////////////////////////////////////////////
write_edges_in_graphviz_dot_format(g, edges);
});The code to turn lists of edge set identifiers into a GraphViz file:
function write_edges_in_graphviz_dot_format(g, edges) {
///////////////////////////////////////////////////////////////////
// An edge consists of two vertices and every vertex can have some
// properties. Among them are a type and a label. Important types
// include "start" and "final" vertices. They signify the beginning
// and end of named captures, and pairs of them correspond to non-
// terminal symbols in a grammar. This function combines type and
// label (the name of the non-terminal) into a vertex label.
///////////////////////////////////////////////////////////////////
var print_label = function(offset, v) {
process.stdout.write(util.format('"%s,%s"[label="%s %s"];\n',
offset,
v,
g.vertices[v].type || "",
g.vertices[v].text || v
));
};
process.stdout.write("digraph {\n");
edges.forEach(function(id, ix) {
/////////////////////////////////////////////////////////////////
// There are two kinds of edges associated with edge identifiers.
// "Null" edges represent transitions that do not consume input
// symbols. They are needed to support nesting of non-terminals,
// non-terminals that match the empty string, among other things.
/////////////////////////////////////////////////////////////////
g.null_edges[id].forEach(function(e) {
process.stdout.write(util.format('"%s,%s" -> "%s,%s";\n',
ix, e[0], ix, e[1]));
print_label(ix, e[0]);
print_label(ix, e[1]);
});
/////////////////////////////////////////////////////////////////
// "Char" edges represent transitions that go outside of a set of
// edges (and into the next) because an input symbol has to be
// read to continue on their path. In other words, they are what
// connects the individual edge sets to one another.
/////////////////////////////////////////////////////////////////
g.char_edges[id].forEach(function(e) {
process.stdout.write(util.format('"%s,%s" -> "%s,%s";\n',
ix, e[0], ix + 1, e[1]));
print_label(ix, e[0]);
print_label(ix + 1, e[1]);
});
});
///////////////////////////////////////////////////////////////////
// If there are cycles in the parse graph at the first or the last
// position, it may be necessary to know which of the vertices
// stands for the start symbol of the grammar. They are avaiable:
///////////////////////////////////////////////////////////////////
var start_vertex = g.start_vertex;
var final_vertex = g.final_vertex;
process.stdout.write("}\n");
}In order to run this demo, you can use something like the following.
Note that you need the GraphViz dot utility and NodeJS in addition
to git.
% git ...
% cd ...
% node demo-parselov.js rfc4627.JSON-text.json.gz ex.json > ex.dot
% dot -Tsvg -Grankdir=tb ex.dot > ex.svg
The ex.json file contains just the two characters [] and it might
be useful to take a look at the [RFC 4627 JSON grammar]
(https://tools.ietf.org/html/rfc4627#section-2) to understand the
result. It should look like this:
+-------------------+ +-------------------+
0 | start JSON-text | +->| start end-array | 1
+-------------------+ | +-------------------+
v | v
+-------------------+ | +-------------------+
0 | start array | | | start ws | 1
+-------------------+ | +-------------------+
v | v
+-------------------+ | +-------------------+
0 | start begin-array | | | final ws | 1
+-------------------+ | +-------------------+
v | v
+-------------------+ | +-------------------+
0 | start ws | | | start ws | 2
+-------------------+ | +-------------------+
v | v
+-------------------+ | +-------------------+
0 | final ws | | | final ws | 2
+-------------------+ | +-------------------+
v | v
+-------------------+ | +-------------------+
1 | start ws | | | final end-array | 2
+-------------------+ | +-------------------+
v | v
+-------------------+ | +-------------------+
1 | final ws | | | final array | 2
+-------------------+ | +-------------------+
v | v
+-------------------+ | +-------------------+
1 | final begin-array |--+ | final JSON-text | 2
+-------------------+ +-------------------+
The numbers next to the nodes indicate the offset into the list of
edges which correspond to the offset into the input data except for
terminal edges associated with the accepting state at the end of the
input. The ws nodes in the graph are there because the RFC 4627
grammar allows ws nodes to match the empty string, and since they
are mandatory, they appear in the graph even though there is no
white space in the input document. Applications not interested in the
nodes, or other uninteresting nodes like begin-array, can remove
them from the edge sets making parse graphs considerably smaller.
The parsing process shown in the previous section can be thought of
as a pre-processing step that makes virtually all decisions that can
be made by a finite state automaton for a higher-level parser. Some
decisions still have to be made, for sufficiently complex grammars,
to determine whether the input actually matches the grammar, namely
whether there is a path through the parse graph that balances all
start points with their corresponding end points. Any such path
represents a valid parse tree for the input with respect to the
grammar the static parsing data is based on.
Finding such a path is a simple matter of traversing the graph from
a start_vertex to a final_vertex. The difficulty is in choosing
vertices whenever a given vertex has multiple successors. Picking a
wrong one wastes computing resources, and parsing algorithms differ
in how they avoid wasting resources. The pre-processing step in the
previous section trades high static memory use for convenience and
speed. It generally leaves very few wrong vertices to pick. As an
example, this demo includes the static data for RFC 4627 JSON-text.
In over 90% of the edges therein, all vertices have only a single
successor, and since the grammar is ambiguous, some vertices with
multiple successors actually represent genuine parsing alternatives.
The code below implements a simple generic backtracking traversal through the parse graph and going through the tree, the parsers will generate a simple JSON-based representation of the parse tree. It processes edges from root of the graph to the bottom. Since the list of edges is built the other way around, it could also start at the bottom, in which case this code could run alongside building the list of edges. It is important to understand that a vertex in a set of edges corresponds to just a couple of instructions that are known independently of the input; they can easily be compiled to a series of machine instructions. Also note that this is just a demonstration of what could be done after the pre-processing step using the static data files. It is not considered part of what is discussed at the beginning of this document.
function generate_json_formatted_parse_tree(g, edges) {
var parsers = [{
output: "",
offset: 0,
vertex: g.start_vertex,
stack: []
}];
///////////////////////////////////////////////////////////////////
// To recap, the result of the initial parse is a list of edge sets
// each of which contains two different kinds of sets of edges. The
// vertices encoded therein can have multiple successors. They come
// from ambiguity and recursion in the input grammar. In order to
// exhaustively search for a parse tree within the parse graph, it
// may be necessary to explore all alternative successors of a ver-
// tex. So whenever alternatives are encountered, they are recorded
// in the `parsers` array, and the following algorithm contines un-
// til either a parse tree has been found or until all alternatives
// are exhausted. So the `while` loop takes care of the latter.
///////////////////////////////////////////////////////////////////
while (parsers.length) {
var p = parsers[0];
if (g.vertices[p.vertex].type == "start") {
///////////////////////////////////////////////////////////////
// Finding a parse tree within a parse graph requires matching
// all starting points of non-terminal symbols to corresponding
// end points so boundaries of a match are properly balanced.
// When a starting point is found, it is pushed on to a stack.
///////////////////////////////////////////////////////////////
p.stack.push({"vertex": p.vertex, "offset": p.offset});
var indent = p.stack.map(function(){ return ' '; }).join("");
p.output += "\n" + indent;
p.output += '[' + JSON.stringify(g.vertices[p.vertex].text)
.replace(/,/g, '\\u002c') + ', [';
}
if (g.vertices[p.vertex].type == "final") {
///////////////////////////////////////////////////////////////
// When there is an opportunity to close the match that is on
// the top of the stack, i.e., when a `final` vertex is found
// on the path that is currently being explored, the vertex can
// be compared to the stack's top element, and if they match,
// we can move on to a successor vertex. On the other hand, if
// the stack is empty, the code has taken a wrong turn. It may
// be better to catch this condition using a sentinel value on
// the stack; vertex `0` is reserved for such uses.
///////////////////////////////////////////////////////////////
if (p.stack.length == 0) {
parsers.shift();
continue;
}
var top = p.stack.pop();
///////////////////////////////////////////////////////////////
// The `start` vertices know which `final` vertex they match
// with, and if the top of the stack is not it, then the whole
// parser is dropped, and the loop will try an alternative that
// has been recorded earlier, if any.
///////////////////////////////////////////////////////////////
if (p.vertex != g.vertices[top.vertex]["with"]) {
parsers.shift();
continue;
}
p.output += '], ' + top.offset + ', ' + p.offset + '],';
}
/////////////////////////////////////////////////////////////////
// For a successfull match of the whole input, there are three
// conditions to be met: the parser must have reached the end of
// the list of edges, which corresponds to the end of the input;
// there must not be open matches left on the stack, and the ver-
// at the end has to be the final vertex of the whole graph. It
// is possible that there is still a loop around the final vertex
// matching the empty string, but we ignore them here.
/////////////////////////////////////////////////////////////////
if (g.final_vertex == p.vertex) {
if (p.offset + 1 >= edges.length)
if (p.stack.length == 0)
return p.output.replace(/,\]/g, ']').replace(/,$/, '');
}
if (p.offset >= edges.length) {
parsers.shift();
continue;
}
/////////////////////////////////////////////////////////////////
// Without a match and without a parsing failure, the path under
// consideration can be explored further. For that the successors
// of the current vertex have to be retrieved from static data.
/////////////////////////////////////////////////////////////////
var cs = g.char_edges[ edges[p.offset] ].filter(function(e) {
return e && e[0] == p.vertex;
}).map(function(e) {
return { successor: e[1], type: "char" };
});
var ns = g.null_edges[ edges[p.offset] ].filter(function(e) {
return e && e[0] == p.vertex;
}).map(function(e) {
return { successor: e[1], type: "null" };
});
var successors = ns.concat(cs);
/////////////////////////////////////////////////////////////////
// Vertices can have an associated `sort_key` to guide the choice
// among alternative successors. A common disambiguation strategy
// is to pick the "first", "left-most" alternative, in which case
// the `sort_key` corresponds the position of grammar constructs
// in the grammar the parsing data is based on. There are other,
// possibly more complex, strategies that can be used instead.
/////////////////////////////////////////////////////////////////
successors.sort(function(a, b) {
return (g.vertices[a.successor].sort_key || 0) -
(g.vertices[b.successor].sort_key || 0);
});
/////////////////////////////////////////////////////////////////
// It is possible that a vertex has no successors at this point,
// even if there are no errors in the parsing data. In such cases
// this parser has failed to match and alternatives are explored.
/////////////////////////////////////////////////////////////////
if (successors.length < 1) {
parsers.shift();
continue;
}
/////////////////////////////////////////////////////////////////
// Sorting based on the `sort_key` leaves the best successor at
// the first position. The current parser will continue with it.
/////////////////////////////////////////////////////////////////
var chosen = successors.shift();
/////////////////////////////////////////////////////////////////
// All other successors, if there are any, are turned into start
// positions for additional parsers, that may be used instead of
// the current one in case it ultimately fails to match.
/////////////////////////////////////////////////////////////////
successors.forEach(function(s) {
parsers.push({
output: p.output,
offset: s.type == "char" ? p.offset + 1 : p.offset,
vertex: s.successor,
stack: p.stack.slice()
});
});
/////////////////////////////////////////////////////////////////
// Finally, if the successor vertex is taken from `char_edges`,
// meaning an input symbol has been consumed to reach it, the
// parser can move on to the next edge and process the successor.
/////////////////////////////////////////////////////////////////
if (chosen.type == "char") {
p.offset += 1;
}
p.vertex = chosen.successor;
}
}Running this code with the RFC 4627 data file and {"a\ffe":[]} as
input, the result is the following JSON document. You can run this
yourself using the -json switch, something along the lines of:
% git ...
% cd ...
% node demo-parselov.js example.json.gz example.data -json
["JSON-text", [
["object", [
["begin-object", [
["ws", [], 0, 0],
["ws", [], 1, 1]], 0, 1],
["member", [
["string", [
["quotation-mark", [], 1, 2],
["char", [
["unescaped", [], 2, 3]], 2, 3],
["char", [
["escape", [], 3, 4]], 3, 5],
["char", [
["unescaped", [], 5, 6]], 5, 6],
["char", [
["unescaped", [], 6, 7]], 6, 7],
["quotation-mark", [], 7, 8]], 1, 8],
["name-separator", [
["ws", [], 8, 8],
["ws", [], 9, 9]], 8, 9],
["value", [
["array", [
["begin-array", [
["ws", [], 9, 9],
["ws", [], 10, 10]], 9, 10],
["end-array", [
["ws", [], 10, 10],
["ws", [], 11, 11]], 10, 11]], 9, 11]], 9, 11]], 1, 11],
["end-object", [
["ws", [], 11, 11],
["ws", [], 12, 12]], 11, 12]], 0, 12]], 0, 12]Using the RFC 3986 data file and the string example://0.0.0.0:23#x gives:
["URI", [
["scheme", [
["ALPHA", [], 0, 1],
["ALPHA", [], 1, 2],
["ALPHA", [], 2, 3],
["ALPHA", [], 3, 4],
["ALPHA", [], 4, 5],
["ALPHA", [], 5, 6],
["ALPHA", [], 6, 7]], 0, 7],
["hier-part", [
["authority", [
["host", [
["IPv4address", [
["dec-octet", [
["DIGIT", [], 10, 11]], 10, 11],
["dec-octet", [
["DIGIT", [], 12, 13]], 12, 13],
["dec-octet", [
["DIGIT", [], 14, 15]], 14, 15],
["dec-octet", [
["DIGIT", [], 16, 17]], 16, 17]], 10, 17]], 10, 17],
["port", [
["DIGIT", [], 18, 19],
["DIGIT", [], 19, 20]], 18, 20]], 10, 20],
["path-abempty", [], 20, 20]], 8, 20],
["fragment", [
["pchar", [
["unreserved", [
["ALPHA", [], 21, 22]], 21, 22]], 21, 22]], 21, 22]], 0, 22]Using the XML 1.0 4th Edition data file and
<!DOCTYPE x [<!ENTITY z "">]>
<x><y>&z;</y></x>
gives
["document", [
["prolog", [
["doctypedecl", [
["S", [], 9, 10],
["Name", [
["Letter", [
["BaseChar", [], 10, 11]], 10, 11]], 10, 11],
["S", [], 11, 12],
["intSubset", [
["markupdecl", [
["EntityDecl", [
["GEDecl", [
["S", [], 21, 22],
["Name", [
["Letter", [
["BaseChar", [], 22, 23]], 22, 23]], 22, 23],
["S", [], 23, 24],
["EntityDef", [
["EntityValue", [], 24, 26]], 24, 26]], 13, 27]],
13, 27]], 13, 27]], 13, 27]], 0, 29],
["Misc", [
["S", [], 29, 30]], 29, 30],
["Misc", [
["S", [], 30, 31]], 30, 31]], 0, 31],
["element", [
["STag", [
["Name", [
["Letter", [
["BaseChar", [], 32, 33]], 32, 33]], 32, 33]], 31, 34],
["content", [
["element", [
["STag", [
["Name", [
["Letter", [
["BaseChar", [], 35, 36]], 35, 36]], 35, 36]],
34, 37],
["content", [
["Reference", [
["EntityRef", [
["Name", [
["Letter", [
["BaseChar", [], 38, 39]], 38, 39]], 38,
39]], 37, 40]], 37, 40]], 37, 40],
["ETag", [
["Name", [
["Letter", [
["BaseChar", [], 42, 43]], 42, 43]], 42, 43]],
40, 44]], 34, 44]], 34, 44],
["ETag", [
["Name", [
["Letter", [
["BaseChar", [], 46, 47]], 46, 47]], 46, 47]], 44, 48]],
31, 48],
["Misc", [
["S", [], 48, 49]], 48, 49],
["Misc", [
["S", [], 49, 50]], 49, 50]], 0, 50] You can also verify that the parse fails for ill-formed input like
<x><?xml?></x>using the sample files included in the repository like so
% node demo-parselov.js xml4e.document.json.gz bad.xml
The deterministic finite state transducers that together form the
low-level parser compute all possible paths from the start_vertex
of the graph that represents the input grammar to the final_vertex.
The forwards automaton visits only vertices reachable from the start,
and the backwards automaton eliminates all paths that ultimately do
not reach the final vertex. However, entering a recursion 1 time or
23 times is the same to the low-level parser, and the primary job of
the higher-level parser is to eliminate paths that can't be traversed
because nesting constraints are violated, or for that matter, finding
one path on which the nesting constraints are maintained, if the goal
is to derive a parse tree.
In order to do that, the higher-level parser does not actually have to go through all the vertices in the graph that describe the regular non-recursive structure of the input. Instead, it could go through a much smaller graph that describes only recursions plus whatever else is minimally needed to ensure paths in the full graph and the reduced graph correspond to one another.
Recursions have vertices in the graph that represent their entry and
their exit points. The smaller graph can be computed by merging all
vertices that reach the same recursion entry and exit points without
passing through a recursion entry or exit point. The data files that
represent grammars include a projection for each vertex that maps the
vertex to a representative in this smaller graph, the stack_vertex.
Here is what this looks like from the perspective of the element
production in the XML 1.0 4th Edition specification:

Matching an element means finding a path from the start element
at the top to the final element vertex in the box. There are two
instances of element in the graph because the top-level element is
different from descendants of it because one has to go over content
prior to visiting a descendant element.
The stack graph projection for every vertex is available through the
g.vertices[v].stack_vertex property, to stick with the syntax used
in the examples above.
The backtracking higher-level parser shown earlier is not very smart.
For instance, ordinarily the finite state transducers already ensure
that any regular start vertex has a matching final vertex, but if
the parser is forced to backtrack, it will probably jump back to a
position where a regular part of the match is ambiguous. When there
is a choice between multiple recursive symbols, it might choose x,
traverse the graph, and find out that it actually needed a z. Then
it takes y, finds out again that it needs a z, and starts over
again. There are many ways to make it smarter, but it is also possible
to avoid backtracking altogether by processing all alternatives in
parallel.
One approach there would be advance all "parsers" in the parsers
array one step (or up to the next edge) before continuing, but there
can be way too many alternatives for some grammars, and quite often
the parser states would differ only in what is on their individual
stacks. If you recall that multiple "parsers" are created when there
are multiple successors to a vertex, there are also cases where a
vertex has fewer successors than predecessors, i.e., parsers might,
after exploring some differences, converge on the same path.
Instead of giving each parser its own stack, it is possible to comine
all possible stack configurations into a graph. Each "parser" can then
simply point to a vertex in the graph identifying the most-recently
pushed value. That value then links to the value pushed before
itself, and so on and so forth. Since there may be more than one way
to reach a given vertex, there might be multiple most-recently pushed
values for each vertex. In other words, instead of a push to a stack,
we add a vertex to graph and then point to the added vertex as the
most recently pushed value; instead of a pop from the stack, we move
the pointer to the predecessors in the graph.
#!perl -w
use Modern::Perl;
use Graph::Directed;
use YAML::XS;
use List::MoreUtils qw/uniq/;
use List::UtilsBy qw/partition_by sort_by nsort_by/;
use Graph::SomeUtils ':all';
use IO::Uncompress::Gunzip qw/gunzip/;
local $Storable::canonical = 1;
my ($path, $file) = @ARGV;
gunzip $path => \(my $data);
my $d = YAML::XS::Load($data);
#####################################################################
# The following is just the typical reading of data and simulating
# the finite automata in order to identify a list of edge sets.
#####################################################################
open my $f, '<:utf8', $file;
my $chars = do { local $/; binmode $f; <$f> };
my @vias = map { $d->{input_to_symbol}[ord $_] } split//, $chars;
my $fstate = 1;
my @forwards = ($fstate);
push @forwards, map {
$fstate = $d->{forwards}[$fstate]{transitions}{$_} // 0
} @vias;
my $bstate = 1;
my @edges = reverse map {
$bstate = $d->{backwards}[$bstate]{transitions}{$_} || 0;
} reverse @forwards;
#####################################################################
# This script is going to generate a graph using file offsets paired
# with vertex identifiers, just like when generating the dot output.
# These helper functions combine two integers into a single string.
#####################################################################
sub pair {
my ($offset, $v) = @_;
return pack('N2', $offset, $v);
}
sub unpair {
my ($pair) = @_;
return unpack('N2', $pair);
}
#####################################################################
# The following will generate a graph that links all vertices in the
# graph produced by the deterministic finite state transducers to all
# possible stack configurations when encountering the vertex. Graph
# `$o` holds the view of the stack, `$g` the (unused) parse graph.
#####################################################################
my $g = Graph::Directed->new;
my $start = pair(0, $d->{start_vertex});
my $final = pair($#edges, $d->{final_vertex});
$g->add_vertex($start);
my $o = Graph::Directed->new;
$o->add_vertex($start);
#####################################################################
# The algorithm transfers a view of the stack from vertices to their
# immediate successors. The `@heads` are the vertices that still need
# to be processed for a given edge, because their successors are the
# newly added vertices in the following edge.
#####################################################################
my @heads = ($start);
#####################################################################
# This projection could be used to merge all regular paths in the
# grammar and only retain recursions plus whatever is needed to keep
# the possible paths through the graph for recursive vertices intact.
# Refer to the section "Merging regular paths" in the documentation.
#####################################################################
sub map_edge {
my ($edge) = @_;
return $edge;
return [ map { $d->{vertices}[$_]{stack_vertex} } @$edge ];
}
for (my $ax = 0; $ax < @edges; ++$ax) {
my $edge = $edges[$ax];
###################################################################
# Edge sets describe graph parts that, when concatenated, describe
# a parse graph. The following code does just that, it creates new
# vertices from the edge sets, noting the current offset, and then
# adds them to the overall graph. It is convenient to keep track of
# vertices added in this step, hence `$null` and `$char` graphs.
###################################################################
my $null = Graph::Directed->new;
my $char = Graph::Directed->new;
$null->add_edges(map { [
pair($ax, $_->[0]), pair($ax, $_->[1])
] } map { map_edge($_) } @{$d->{null_edges}[$edge]});
$char->add_edges(map { [
pair($ax, $_->[0]), pair($ax + 1, $_->[1])
] } map { map_edge($_) } @{$d->{char_edges}[$edge]});
###################################################################
# Since we are going transfer views of the stack from vertices to
# their successors, it is convenient to get hold of all successors
# from a single graph, so the edges are combined into `$both`.
###################################################################
my $both = Graph::Directed->new;
$both->add_edges($null->edges);
$both->add_edges($char->edges);
###################################################################
# It can be convenient to build the parse graph alongside running
# this algorithm, `$g`, but the algorithm does not depend on it.
###################################################################
$g->add_edges($both->edges);
my %seen;
my @todo = @heads;
while (@todo) {
my $v = shift @todo;
#################################################################
# Successors have to be processed after their predecessors.
#################################################################
if (not $seen{$v}++) {
push @todo, $v;
push @todo, $null->successors($v);
next;
}
my ($vix, $vid) = unpair($v);
if (($d->{vertices}[$vid]{type} // "") =~ /^(start|if)$/) {
###############################################################
# `start` vertices correspond to `push` operations when using a
# stack. In the graph representation, the most recently pushed
# vertex is, accordingly, a predecessor of the current vertex.
###############################################################
$o->add_edge($v, $_) for $both->successors($v);
} elsif (($d->{vertices}[$vid]{type} // "") =~ /^(final|fi)$/) {
###############################################################
# `final` vertices correspond to `pop` operations when using a
# stack. They have to be matched against all the `predecessors`
# aka the most recently pushed vertices on the stack graph, and
# when they match, a `pop` is simulated by making the previous
# values, the second-most-recently-pushed vertices, available
# to the successors of the current vertex. Since the current
# vertex can be its own (direct or indirect) successor, due to
# right recursion, the successor may have to be processed more
# than one time to clear the emulated stack of matching values.
###############################################################
for my $parent ($o->predecessors($v)) {
my ($pix, $pid) = unpair($parent);
if (not ($d->{vertices}[$pid]{with} // '') eq $vid) {
$o->delete_edge($parent, $v);
next;
}
for my $s ($both->successors($v)) {
for my $pp ($o->predecessors($parent)) {
next if $o->has_edge($pp, $s);
$o->add_edge($pp, $s);
push @todo, $s;
}
}
}
} else {
###############################################################
# Other vertices do not affect the stack and so successors have
# the all the possible stack configurations available to them.
###############################################################
for my $s ($both->successors($v)) {
$o->add_edge($_, $s) for $o->predecessors($v);
}
}
}
###################################################################
# The new `@heads` are the end points of `char` edges. This should
# use only vertices that can actually be reached from the previous
# `@heads`, over a path that does not violate nesting constraints,
# but the low-level parser generally ensures there are no vertices
# added that cannot be reached from the `start_vertex`.
###################################################################
@heads = uniq map { $_->[1] } $char->edges;
}In the code above the @heads array corresponds to all the p.vertex
properties in the backtracking parser shown earlier, and the graph
$o links any p.vertex to what used to be the p.stacks. If the
$o graph has an edge $o->has_edge($start, $final) and the $final
vertex is reachable from $start, then the input matches the grammar.
Note that the process above is entirely generic and does not depend on
any particular behavior of the deterministic finite state transducers;
it would be sufficient if they simply report all possible edges given
a particular input character. In other words, the code above resembles
simulating a non-deterministic pushdown transducer exploring all the
possible transitions in parallel. The finite state transducers in turn
correspond to an exhaustive parallel simulation that ignores the stack.
When fully computed, they ensure that there are only relatively few
edges added in each step and that all vertices are reachable from the
start_vertex and reach the final_vertex. Furthermore, if the
non-recursive regular paths have already been computed by the finite
machines, they can be ignored in this step, as discussed in the
previous section.
The code above processes the list of edge sets produces by the finite
automata from the left to the right. It would also be possible to use
it from the right to the left and execute it alongside the backwards
automaton. And as with the backtracking parser, it should be easy to
see that most of the process above can be pre-computed and be turned
into simple machine instructions.
Also note that using a graph instead of a single stack adds a lot of
power. A finite state machine with two stacks is already sufficient
for turing-completeness. Having an essentially infinite number of
stacks does not add computational power, but if you consider simpler
machines like deterministic pushdown automata, it might be impossible
to express the union of two DPDAs as one DPDA (you can simulate them
in parallel, but what do you do if one automaton wants to push while
the other wants to pop if you have only one stack to work with?),
the approach above would allow them to exist peacefully together, the
@heads, in a manner of speaking, could be the the two states of the
automata, and the "stack graph" would just be two stacks, one for each
of them.
Finally note that parallel simulation also makes it easy to extend the
graph formalism seen so far with features that depend on combining
multiple paths, like boolean combinators. The data files for XML 1.0
for instance have if and matching fi vertices that offer two paths
to traverse. They are combined using an andnot condition. If there
is a path from the start_vertex to the final_vertex over the not
part, then the if condition fails and both paths are invalid. That
represents
PITarget ::= Name - (('X' | 'x') ('M' | 'm') ('L' | 'l'))
and other rules making use of the - operator. If the right hand side
is not recursive, such rules are resolved by the finite transducers,
but if the right hand side is not regular, the higher-level parser has
to explore them aswell. The simple backtracking parser shown earlier
ignores them at the moment.
The code in a previous section does many things at runtime that could
be computed statically, like building the initial @todo list, and
it does so rather expensively like building temporary graph objects.
As a first step, let's say we've pre-computed the initial @todo and
the vertex successors the code above derives from the $null and
$char graphs. In the abstract, we would then have for each set of
edges:
my @todo = ...;
while (@todo) {
my $vid = shift @todo;
for ($vid) {
when(23) { do_start(...); }
when(42) { push @todo, do_final(...); }
when(65) { do_other(...); }
...
}
}where the functions called above would look as follows. Parameters
$ns, and $cs are the successors of $v in the $null graph and
the $char graph respectively, the rest should be obvious from the
previous section.
sub do_start {
my ($o, $vix, $vid, $ns, $cs) = @_;
my $v = pair($vix, $vid);
$o->add_edge($v, pair($vix, $_)) for @$ns;
$o->add_edge($v, pair($vix + 1, $_)) for @$cs;
}
sub do_other {
my ($o, $vix, $vid, $ns, $cs) = @_;
my $v = pair($vix, $vid);
for my $parent ($o->predecessors($v)) {
$o->add_edge($parent, pair($vix, $_)) for @$ns;
$o->add_edge($parent, pair($vix + 1, $_)) for @$cs;
}
}
sub do_final {
my ($o, $vix, $vid, $with, $ns, $cs) = @_;
my $v = pair($vix, $vid);
my @todo;
for my $parent ($o->predecessors($v)) {
my ($pix, $pid) = unpair($parent);
if ($pid ne $with) {
$o->delete_edge($parent, $v);
next;
}
for my $pp ($o->predecessors($parent)) {
for my $sid (@$ns) {
my $s = pair($vix, $sid);
next if $o->has_edge($pp, $s);
$o->add_edge($pp, $s);
push @todo, $sid;
}
for my $sid (@$cs) {
my $s = pair($vix + 1, $sid);
$o->add_edge($pp, $s);
}
}
}
return @todo;
}We have seen earlier how the graph that represents the input grammar
can be simplified so it consists mostly of vertices that represent
recursions. Now, especially if we do that, it is possible to replace
calls to the functions above with just a couple of instructions. For
instance, from the perspective of most vertices, there can only ever
be one most recently pushed vertex in the $o graph, which makes
two of the loops in do_final redundant for them. Furthermore, most
vertices only have one successor, either in $ns or in $cs, so
those loops are often superfluous aswell.
The possible return values of do_final are only interesting if
there is a cycle in the $null graph (such cycles represent left and
right recursion); indeed, if there are no such cycles, we do not need
the while (@todo) loop and can simply process vertices in
topological order. The do_other routine is for unlabeled vertices
that generally represent terminals in the grammar. Since we do not
care about those, instead of copying the predecessors in the "stack
graph" from one unlabeled vertex to another unlabeled vertex, we
could replace one with the other simply by updating the offset
position and vertex id of the previous one, in most cases.
If all vertices in the graph can only ever see one most recently
pushed value, we do not even need a graph and can use an ordinary
stack instead. If the grammar you are interested in is not recursive
or uses only right recursion, none of this is even needed, you can
just use the backtracking parser presented earlier.
And that is just the point. Compilers ought to figure out how to analyse formal languages efficiently, rather than bothering humans with it.
With the approach shown above it would be nice if we could use a
simpler data structure than a graph, namely a stack. Some languages
are simple enough that a stack is sufficient. When the vertices in
all null_edges and all char_edges are projected to stack_vertex
and loops around unlabeled vertices are removed, and the result is
that all vertices in each edge have at most one successor, or if all
successors are final vertices (we can choose among them using the
last-in value) then there is at most one possible path we can take.
The above is the case for non-recursive languages like the RFC 3986
grammar (URIs), and also recursive grammars like the RFC 5234 (ABNF)
and XML element grammars. When parsing RFC 5234 documents, the
stack would be a path through a graph like this:

The choice in the graph is not visible to the algorithm above since
option starts with [ and group starts with ( and so the two
options do not appear together in the same backwards state. A case
where we get a negative answer for the analysis above is the whole
XML document production. A problem there are element content
models (which can occur in the internal subset of document type
declarations):
children ::= (choice | seq) ('?' | '*' | '+')?
cp ::= (Name | choice | seq) ('?' | '*' | '+')?
choice ::= '(' S? cp ( S? '|' S? cp )+ S? ')'
seq ::= '(' S? cp ( S? ',' S? cp )* S? ')'
Since choice and seq are both recursive, and cannot be told apart
except by whether , or | is used to separate their children, both
options would have to be put on the stack together, which violates
the rule given above (one vertex has multiple successors that are not
all final vertices). A cheap option would be to use a graph for the
rare case of encounters with this obscure part of the XML format, and
switch to using a stack once the actual document content is read.
The JSON grammar in RFC 4627 is more complicated. It makes liberal
use of the ws production to indicate where ignorable white space
characters, such as spaces and newlines between values, can be placed.
This results in an ambiguity as to where recursive productions begin
with respect to an input tring. So an analysis of the graph produced
as part of the algorithm explained at the beginning of the section
shows that at some points there is a choice between reading more
input and starting to match productions like value.
If we actually want to report all possible matches, which includes
encoding all the "continue reading or start a value" choices, it is
not possible to do that with a simple stack. A common sacrifice that
is made is adding a simple disambiguation strategy, for instance, we
could simply ignore the option to "continue reading" and enter the
recursive symbol as soon as possible. That would change the language,
and it has to be done carefully.
Let's put some of this into code:
#!perl -w
use Modern::Perl;
use Graph::Directed;
use YAML::XS;
use List::Util qw/all/;
use List::MoreUtils qw/uniq/;
use List::UtilsBy qw/partition_by sort_by nsort_by/;
use Graph::SomeUtils ':all';
use IO::Uncompress::Gunzip qw/gunzip/;
local $Storable::canonical = 1;
my ($path, $file) = @ARGV;
gunzip $path => \(my $data);
my $d = YAML::XS::Load($data);
sub map_edge {
my ($edge) = @_;
return $edge;
return [ map { $d->{vertices}[$_]{stack_vertex} } @$edge ];
}
for (my $ax = 0; $ax < @{ $d->{null_edges} }; ++$ax) {
my $edge = $ax;
my $null = Graph::Directed->new;
my $char = Graph::Directed->new;
$null->add_edges(map { map_edge($_) } @{$d->{null_edges}[$edge]});
$char->add_edges(map { map_edge($_) } @{$d->{char_edges}[$edge]});
###################################################################
# This removes loops from unlabeled vertices and unlabeled vertices
# between labeled vertices. The sole purpose of unlabeled vertices
# is to ensure that we can always properly go from one set of edges
# to another. Ordinarily they represent terminals in the grammar,
# but here they also represent non-recursive symbols. Loops are due
# to merging `start` and `final` vertices e.g. because non-terminal
# symbols match the empty string. In any case, they do not affect
# how we ultimately pair vertices that repesent recursions.
###################################################################
for my $v ($null->vertices) {
next if length ($d->{vertices}[$v]{type} // '');
$null->delete_edge($v, $v);
next if $char->successors($v);
next unless $null->predecessors($v);
next unless $null->successors($v);
for my $p ($null->predecessors($v)) {
for my $s ($null->successors($v)) {
$null->add_edge($p, $s);
}
}
graph_delete_vertex_fast($null, $v);
}
for my $v ($null->vertices, $char->vertices) {
#################################################################
# If a vertex has multiple successors in `$char`, we would leave
# this set of edges on more than a single vertex, which would
# violate our constraints. Similarily, if there is a choice be-
# tween moving on to the next set of edges (next character) and
# staying here, that would violate our constraints. Hence this:
#################################################################
my @s;
push @s, $null->successors($v);
push @s, $char->successors($v);
next if @s <= 1;
#################################################################
# The following tests do not allow successors in `$char` but do
# allow multiple successors in `$null` provided that all of them
# are either `final` vertices (in which case we can choose among
# them by looking at the last-in value) or `start` vertices.
#################################################################
my $all_final = all {
($d->{vertices}[$_]{type} // '') eq 'final'
} $null->successors($v);
my @out = uniq map { $_->[1] } $char->edges;
#################################################################
# The check `and not $char->successors($v)` ensures that there is
# no choice between going into a recursive symbol, or moving out
# of it, and moving on to the next character.
#################################################################
if ($all_final and not $char->successors($v)) {
next;
}
#################################################################
# If we get here, there is a problem with the grammar that might
# make it impossible to link the `start` and `final` points of
# recursive symbols in a match together using only a stack. This
# will print debugging in formation if there is a violation,
# otherwise this script will not print anything at all.
#################################################################
say join "\t",
scalar(@out),
"succ",
$v,
"null",
(map {
$_, $d->{vertices}[$_]{type}, $d->{vertices}[$_]{text}
} (sort $null->successors($v))),
"char", (sort $char->successors($v));
}
}This script checks for the conditions explained above. For the URI,
ABNF, and XML element samples it prints nothing, for the RFC 4627
JSON sample it will print something like:
1 succ 349 null 76 final array char 349
1 succ 367 null 209 final object char 367
1 succ 378 null 69 final object char 378
1 succ 382 null 8 start value char 382
1 succ 388 null 151 final array char 388
1 succ 394 null 57 start value char 394
2 succ 349 null 76 final array char 349
2 succ 365 null 40 start value char 365
2 succ 367 null 209 final object char 367
2 succ 368 null 378 char 368
2 succ 378 null 69 final object char 378
2 succ 379 null 145 start value char 379
2 succ 381 null 12 start value char 381
2 succ 382 null 349 char 382
2 succ 382 null 8 start value char 382
2 succ 388 null 151 final array char 388
2 succ 389 null 122 start value char 389
2 succ 391 null 367 char 391
2 succ 394 null 388 char 394
2 succ 394 null 57 start value char 394
This is a crude way of telling you that at some point you can go from
stack_vertex 349 to vertex 76 without reading anything (null)
or to vertex 349 after reading an input symbol (char). In other
words, the grammar might be ambiguous, and it is probably not possible
to parse using only a single stack while reporting all possible matches.
This also attempts to tell you where the problem might lie.
Applied to the XML 1.0 extSubset data file, the script generates a
lot of nonsense. That is because the forwards automaton is not
"complete", it does not actually trace all possible paths through the
grammar, and accordingly the backwards automaton and hence the
char_edges and the null_edges are not complete either. In contrast
the backtracking higher-level parser would still, very slowly, do the
right thing when trying to parse. This is explained in more detail in
the section on "Limitations".
The design of the core system makes it easy to simulate multiple
automata in parallel, and since all state is trivially accessible,
new data files that easily be created as combinations of existing
ones. The most common combinations are directly supported as part
of the core data file generation process, such as the union of two
alternatives, and set subtraction. The latter is used e.g. by the
EBNF grammar for XML 1.0 to express rules such as any Name except 'xml' which are often difficult to express with other systems.
Likewise, the intersection of two grammars is easily computed.
An important implication is that the system can be used to compare
grammars. As an example, the sample files include one for URIs as
defined by RFC 3986. The precursor of RFC 3986 is RFC 2396, and it
can be useful to construct a data file for strings that are URIs
under one definition but not the other, e.g. to derive test cases,
or if the two definitions were meant to be the same, to verify that
they are (as in set theory, if A - B is empty and B - A is empty
then A and B are equivalent).
The way to combine data files is exhaustive simulation. As example,
the forwards automaton in any data file starts in state 1. If you
have two data iles, you can make a pair of states (1, 1) and a
character ch, and compute
var s1 = g1.forwards[1].transitions[ g1.input_to_symbol[ch] ];
var s2 = g2.forwards[1].transitions[ g2.input_to_symbol[ch] ];which would give a transition from (1, 1) over ch to (s1, s2).
The pairs are the states in the new automaton. When computing a union,
a state in the new automaton is accepting if either of the states it
represents is accepting. For intersection both states have to be
accepting. For A - B the state in A has to be accepting, but the
state for B must not be. For boolean combinations the structure of
the automaton is always the same, except that some states may end up
being redundant.
For the backwards automaton the process is the same. Merging the
corresponding graph data is done by taking the union of edges. It
is of course necessary to rename vertices to avoid collisions. It
is also useful to first create a common input_to_symbol table and
then simulate over character classes instead of indiviual characters.
There are many other interesting combinations than the simple boolean
ones. For instance, instead of of indiscriminate union it can also be
useful to create an ordered choice if A then A else B. This would
disambiguate between A and B. Typical applications include support
for legacy constructs in grammars or other fallback rules. This can
be implemented just like the union, but when creating the backwards
automaton, the unwanted edges would be left out. Alternatively, an
ordered choice a || b can also be expressed as a | (b - a).
It is also possible to create interleavings (switching from one automaton to another) and other constructs with similar effort.
Here is an example that creates a combination of two data files where the result will match strings that do not match the first data file but do match the second data file.
#!perl -w
use Modern::Perl;
use Graph::Directed;
use YAML::XS;
use List::Util qw/min max/;
use List::MoreUtils qw/uniq/;
use List::UtilsBy qw/partition_by sort_by nsort_by/;
use Graph::SomeUtils ':all';
use IO::Uncompress::Gunzip qw/gunzip/;
use IO::Compress::Gzip qw(gzip);
use Data::AutoBimap;
use JSON;
local $Storable::canonical = 1;
my ($path1, $path2) = @ARGV;
gunzip $path1 => \(my $data1);
gunzip $path2 => \(my $data2);
my $d1 = YAML::XS::Load($data1);
my $d2 = YAML::XS::Load($data2);
sub pair {
my ($offset, $v) = @_;
return pack('N2', $offset, $v);
}
sub unpair {
my ($pair) = @_;
return unpack('N2', $pair);
}
#####################################################################
# Create a new alphabet making sure new character sets are disjoint.
#####################################################################
my @input_to_symbol = (pair(0, 0));
my $max = max(scalar(@{ $d1->{input_to_symbol} }),
scalar(@{ $d2->{input_to_symbol} }));
for (my $via = 1; $via < $max; ++$via) {
$input_to_symbol[$via] = pair(
($d1->{input_to_symbol}[$via] // 0),
($d2->{input_to_symbol}[$via] // 0),
);
}
my $sm = Data::AutoBimap->new(start => 0);
$sm->s2n(pair(0, 0));
my @alphabet = map { $sm->s2n($_) } uniq @input_to_symbol;
#####################################################################
# Create a new automaton over pairs of states in the input automata.
#####################################################################
sub combine {
my ($a1, $a2, $im, $sm, $start, $alphabet) = @_;
my %seen;
my @states;
my @todo = $start;
while (@todo) {
my $current = shift @todo;
next if $seen{$current}++;
my ($s1, $s2) = unpair($sm->n2s($current));
for my $via (@$alphabet) {
my ($via1, $via2) = unpair($im->n2s($via));
my $dst =
$sm->s2n(pair(
$a1->[$s1]{transitions}{$via1} // 0,
$a2->[$s2]{transitions}{$via2} // 0,
));
next unless $dst;
$states[$current]{transitions}{$via} = $dst;
push @todo, $dst;
}
#################################################################
# For simple boolean combinations like `and` and `xor` this is
# the only place that encodes the combination. For more complex
# combinations, like `if a then a else b` we would also need to
# remove the edges we are not interested in later in the code.
#################################################################
$states[$current]{accepts} =
(!$a1->[$s1]{accepts})
&
$a2->[$s2]{accepts};
}
return @states;
}
#####################################################################
# Combine the `forwards` automata.
#####################################################################
my $fm = Data::AutoBimap->new(start => 0);
$fm->s2n(pair(0, 0));
my @forwards = combine(
$d1->{forwards},
$d2->{forwards},
$sm,
$fm,
$fm->s2n(pair(1, 1)),
[@alphabet],
);
$forwards[0] = { transitions => {} };
my $xm = Data::AutoBimap->new(start => 0);
$xm->s2n(pair(0, 0));
my @ralpha;
for (my $ix = 0; defined $fm->n2s($ix); ++$ix) {
push @ralpha, $ix;
}
#####################################################################
# Combine the `backwards` automata.
#####################################################################
my $bm = Data::AutoBimap->new(start => 0);
$bm->s2n(pair(0, 0));
my @backwards = combine(
$d1->{backwards},
$d2->{backwards},
$fm,
$bm,
$bm->s2n(pair(1, 1)),
[@ralpha]
);
$backwards[0] = { transitions => {} };
my $vm = Data::AutoBimap->new(start => 0);
$vm->s2n(pair(0, 0));
#####################################################################
# This is most of the new data file.
#####################################################################
my $d3 = {
start_vertex => $vm->s2n(pair($d1->{start_vertex},
$d2->{start_vertex})),
final_vertex => $vm->s2n(pair($d1->{final_vertex},
$d2->{final_vertex})),
forwards => \@forwards,
backwards => \@backwards,
vertices => [{}, {
type => "start",
text => "$path1 combined with $path2",
with => 2,
}, {
type => "final",
text => "$path1 combined with $path2",
with => 1,
}],
input_to_symbol => [ map { $sm->s2n($_) } @input_to_symbol ],
};
#####################################################################
# Copy the vertex data.
#####################################################################
$d3->{vertices}[$vm->s2n(pair(0, $_))] =
$d1->{vertices}[$_] for 1 .. @{ $d1->{vertices} } - 1;
$d3->{vertices}[$vm->s2n(pair($_, 0))] =
$d2->{vertices}[$_] for 1 .. @{ $d2->{vertices} } - 1;
#####################################################################
# Making sure cross-references among vertices are updated.
#####################################################################
for (my $ix = 3; defined $vm->n2s($ix); ++$ix) {
my ($v1, $v2) = unpair($vm->n2s($ix));
my $v = !$v1 ? $v2 : $v1;
my $d = $v1 ? $d2 : $d1;
my $s = $v1 ? sub { $vm->s2n(pair($_[0], 0)) } :
sub { $vm->s2n(pair(0, $_[0])) };
for my $k (qw/with operand1 operand2 stack_vertex/) {
$d3->{vertices}[$ix]{$k} = $s->($d->{vertices}[$v]{$k} || 0);
}
}
#####################################################################
# Copy the edge data.
#####################################################################
for (my $ix = 1; defined $bm->n2s($ix); ++$ix) {
my ($s1, $s2) = unpair($bm->n2s($ix));
for my $k (qw/char_edges null_edges/) {
push @{ $d3->{$k}[$ix] },
map { [map { $vm->s2n(pair(0, $_)) } @$_ ] }
@{ $d1->{$k}[$s1] };
push @{ $d3->{$k}[$ix] },
map { [map { $vm->s2n(pair($_, 0)) } @$_ ] }
@{ $d2->{$k}[$s2] };
}
}
#####################################################################
# Connect the old `start_vertex` and `final_vertex` vertices to the
# new ones. If one of the input data files represents a recursive
# grammar, this should also add appropriate `if` and `fi` vertices
# and their operands to allow the higher-level parser to complete the
# combination. This also ignores edge cases where the `start` or the
# `final` vertex in one of the input automata occurs only as part of
# a `char_edge`. But for demonstration purposes this should be okay.
#####################################################################
for (my $ix = 1; $ix < @{ $d3->{null_edges} }; ++$ix) {
next unless defined $d3->{null_edges}[$ix];
my @edges = @{ $d3->{null_edges}[$ix] };
my @vertices = map { @$_ } @edges;
my %has = map { $_ => 1 } @vertices;
my $s1 = $vm->s2n(pair(0, $d1->{start_vertex}));
my $f1 = $vm->s2n(pair(0, $d1->{final_vertex}));
my $s2 = $vm->s2n(pair($d1->{start_vertex}, 0));
my $f2 = $vm->s2n(pair($d1->{final_vertex}, 0));
push @{ $d3->{null_edges}[$ix] }, [ $d3->{start_vertex}, $s1 ]
if $has{$s1};
push @{ $d3->{null_edges}[$ix] }, [ $d3->{start_vertex}, $s2 ]
if $has{$s2};
push @{ $d3->{null_edges}[$ix] }, [ $f1, $d3->{final_vertex} ]
if $has{$f1};
push @{ $d3->{null_edges}[$ix] }, [ $f2, $d3->{final_vertex} ]
if $has{$f2};
}
$d3->{char_edges}[0] = [];
$d3->{null_edges}[0] = [];
#####################################################################
# Now we can print out the result. It will be rather large since, for
# one thing, the worst case size of the product automata is O(N*M),
# and we made no effort to remove data that has become useless such
# as states that cannot reach an accepting state.
#####################################################################
my $json = JSON->new->canonical->ascii->encode($d3);
gzip \$json => \(my $gzipped);
binmode STDOUT;
print $gzipped;Usage:
% perl not-a-but-b.pl rfc3986.URI.json.gz rfc2396.URI.json.gz > x.gz
% perl random-samples.pl x.gz
Output:
GA.://!:%3A2++%6A./#
VA25536://:%A6#!$:?!
V://%5A:;@-%0A%AAA@%2A6?
G://%A6_+@!+%A5:%16./;?
AA+.VG+3+5A5V://:!%A5?
A://:%60/;2;!/;@;;V
A.V://@@;%1A@
AAAAA63A.5--://G:;%6A1;++
The strings above are strings that are URIs according to RFC 2396 but not according to the later specification RFC 3986. We can also do it the other way around, the following are strings that RFC 3986 accepts but RFC 2396 did not:
V+://@[VAA.::]:/!/?///%A1/1!#@:
GGA.A3A-6:
G-:#-/?
G+G:
G+1:
GG:#@/+_
A-://[V3.:::+]/#
AA05AG:#/;
How to generate these random samples is explained in a later section. It is easy to generate a small set of test cases for all interesting differences between the two specifications covered, as explained in the section on test suite coverage.
Some specifications separate the language definition into multiple
parts, one for small units like number and identifier, called
tokens, and then separately define how to combine tokens into larger
structures. An example is the specification for style sheets, [CSS 2.1]
(http://www.w3.org/TR/2011/REC-CSS2-20110607/syndata.html#syntax).
We can do the same and define two grammars. Using the ABNF format,
it could look like this for CSS 2.1, closely mirroring the structure
of the specification:
CSSTOKEN = IDENT
/ ATKEYWORD
/ STRING
...
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
; Tokens
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
IDENT = ident
ATKEYWORD = "@" ident
STRING = string
...
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
; Macros
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
ident = ["-"] nmstart *nmchar
name = 1*nmchar
nmstart = (ALPHA / "_") / nonascii / escape
...
The underlying idea is that the sequence of characters that make up a style sheet are first turned into a sequence of tokens and the grammar above is for one such token. To distinguish tokens from one another, the CSS 2.1 specification defines that in trying to find a token, we always read as much of the input as possible. The code below is an implementation of that:
#!perl -w
use Modern::Perl;
use Graph::Directed;
use YAML::XS;
use IO::Uncompress::Gunzip qw/gunzip/;
local $Storable::canonical = 1;
my ($path, $file) = @ARGV;
gunzip $path => \(my $data);
my $d = YAML::XS::Load($data);
my %state_to_token;
#####################################################################
# First we are going to map each `forwards` state to a named token,
# if any, going through the set of edges at the accepting position.
#####################################################################
for (my $ix = 0; $ix < @{ $d->{forwards} }; ++$ix) {
my $null = Graph::Directed->new;
my $edge = $d->{backwards}[1]{transitions}{$ix};
next unless defined $edge;
die unless $d->{forwards}[$ix]{complete};
$null->add_edges(@{$d->{null_edges}[$edge]});
my %found = map { $d->{vertices}[$_]{text} => 1 } grep {
($d->{vertices}[$_]{type} // '') eq 'final';
} $null->predecessors($d->{final_vertex});
###################################################################
# `DELIM` tokens match "anything else" and the grammar does not
# fully distinguish them from other named tokens, so we do it here.
###################################################################
if (keys %found > 1) {
delete $found{DELIM};
}
###################################################################
# https://lists.w3.org/Archives/Public/www-style/2015Feb/0043.html
# This manually resolves an ambiguity in the specification.
###################################################################
if ($found{FUNCTION} and $found{'BAD-URI'}) {
delete $found{FUNCTION};
}
###################################################################
# We can only proceed if there is no ambiguity left among tokens.
###################################################################
die if keys %found != 1;
($state_to_token{$ix}) = keys %found;
}
open my $f, '<:utf8', $file;
my $chars = do { local $/; binmode $f; <$f> };
my @vias = map { $d->{input_to_symbol}[ord $_] } split//, $chars;
#####################################################################
# Now we can turn the sequence of input characters into a sequence of
# tokens. Since the specification defines to use the "longest match",
# we simulate the `forwards` automaton until it no longer accepts any
# input. This assumes that all states that do not reach an accepting
# state are merged into state `0` as should normally be the case.
#####################################################################
for (my $ix = 0; $ix < @vias;) {
my $fstate = 1;
my $bx = $ix;
while ($d->{forwards}[$fstate]{transitions}{$vias[$bx]}) {
$fstate = $d->{forwards}[$fstate]{transitions}{$vias[$bx++]};
last if $bx >= @vias;
}
my $token = $state_to_token{$fstate};
say join "\t", $ix, $bx, $token;
$ix = $bx;
}Usage:
% perl csstoken.pl csstoken.json.gz example.css
Input:
/* Example */
body { background: url("example") }Output (start offset, next offset, name of token):
0 13 COMMENT
13 15 S
15 19 IDENT
19 20 S
20 21 LEFT-CURLY
21 22 S
22 32 IDENT
32 33 COLON
33 34 S
34 48 URI
48 49 S
49 50 RIGHT-CURLY
50 52 S
Next we can make a grammar for the remaining parts of the syntax. As the data format still assumes transitions over numbers, we can define a number for each token:
IDENT = %x01
ATKEYWORD = %x02
STRING = %x03
...
stylesheet = *( CDO / CDC / S / statement )
statement = ruleset / at-rule
at-rule = ATKEYWORD *S *any ( block / SEMICOLON *S )
...
One twist of note is that the CSS 2.1 specification defines "COMMENT
tokens do not occur in the grammar (to keep it readable), but any
number of these tokens may appear anywhere outside other tokens." So
when feeding tokens into a parser for the second grammar, we would
have to skip COMMENT tokens (or, alternatively, change the grammar
so that a COMMENT loop appears before and after any reference to a
rule in the grammar, avoiding redundant instances of such loops). It
would also be possible to combine the two grammars into one, but we
would need to make the grammar for the tokens such that they are
disjoint and each token retains the property that it matches "as much
as possible".
The graph formalism on which the system presented in this document is
based essentially linearises hierarchial data structures. Consider, as
a comparison, event-based parsers for languages like XML. They present
a stream of events like start_element and end_element to calling
applications. Likewise, the system here equates parsing with finding a
path through a graph where some vertices are labeled start and other
vertices are labeled final and a valid path is one where there is a
matching final for every start on the path. We can use this idea
to linearise some data structures so they fit into this system.
Trees, like indeed XML documents, are a good example. A simple use case is validation of XML documents. Let's make a simple grammar for a subset of the HTML/XHTML language, considering only the nesting and position of elements, not their attributes or character data content:
start-html = %x01
final-html = %x02
start-head = %x03
final-head = %x04
start-title = %x05
final-title = %x06
start-div = %x07
final-div = %x08
start-p = %x09
final-p = %x0a
start-body = %x0b
final-body = %x0c
html = start-html (head body) final-html
head = start-head (title) final-head
title = start-title "" final-title
body = start-body *(div / p) final-body
div = start-div *(div / p) final-div
p = start-p "" final-p
The first part is similar to how we handled tokens in the previous
section. Essentially, in a manner of speaking, <html> is a token,
and so is </html>, and so is any other start tag or end tag. But
we do not have to derive these tokens from a character string, it
would also be possible to generate a sequence of them from a tree in
memory by way of a depth-first traversal. XML schema languages like
RELAX NG follow a similar principle, although they do offer more
convenient syntactic sugar to express rules.
The basic approach outlined above works well for carefully constructed data format and protocol message formats that are relatively regular, unambiguous, and deterministic, which is the case for a large set of standard formats. The samples include parsing data for URIs, JSON, XML, and ABNF. All the corresponding grammars are ambiguous and only URIs are regular, so these are not strict requirements.
The design of the data files also allows the deterministic finite state transducers used for pre-processing the input to simply record the input without making decisions on their own, in which case the higher level parser would turn into an unaided non-deterministic pushdown transducer. That is a worst-case escape hatch that ensures the integrity of the parsing data files while avoiding the creation of an exponential number of states, so it is always possible to create a correct and reasonably sized data file, but naively written higher level parsers are likely to perform poorly within this system.
There are ways to delay the inevitable however. A simple example are XML document type definition files. The finite state transducers can handle the format fine except for one construct:
ignoreSect ::= '<![' S? 'IGNORE' S? '[' ignoreSectContents* ']]>'
ignoreSectContents ::= Ignore ('<![' ignoreSectContents ']]>' Ignore)*
Ignore ::= Char* - (Char* ('<![' | ']]>') Char*)
In the grammar for XML, Char is the whole alphabet, and the rule
ignoreSectContents matches anything so long as any <![ properly
nests with a closing ]]>. Since the finite transducers cannot
detect the outermost closing ]]>, this simply matches anything; in
order to still make all regular decisions for the higher level parser,
an inordinate amount of states is needed. Of course, for any finite
number of nesting levels, relatively few states are needed, delaying
any fallback to the worst case as much as is convenient by expanding
problematic recursions a couple of times.
An example of this is included in the repository. Using
% node demo-parselov.js xml4e.extSubset.json.gz ex.dtd
Right after reading the first <![IGNORE[ in a location where the
construct is allowed, the first finite state transducer switches to
a worst-case mode of operation and simply records the input. The
second transducer accordingly generates all possible edges for every
position in the input, leaving an inordinate amount of work for the
naively written higher level demo parser introduced earlier. The
dot output is nevertheless correct. For an input like
<!ELEMENT a (b, (c | d)*, e*)>The output would be
["extSubset", [
["extSubsetDecl", [
["markupdecl", [
["elementdecl", [
["S", [], 9, 10],
["Name", [
["Letter", [
["BaseChar", [], 10, 11]], 10, 11]], 10, 11],
["S", [], 11, 12],
["contentspec", [
["children", [
["seq", [
["cp", [
["Name", [
["Letter", [
["BaseChar", [], 13, 14]], 13, 14]], 13, 14]],
13, 14],
["S", [], 15, 16],
["cp", [
["choice", [
["cp", [
["Name", [
["Letter", [
["BaseChar", [], 17, 18]], 17, 18]],
17, 18]], 17, 18],
["S", [], 18, 19],
["S", [], 20, 21],
["cp", [
["Name", [
["Letter", [
["BaseChar", [], 21, 22]], 21, 22]],
21, 22]], 21, 22]], 16, 23]], 16, 24],
["S", [], 25, 26],
["cp", [
["Name", [
["Letter", [
["BaseChar", [], 26, 27]], 26, 27]], 26, 27]],
26, 28]], 12, 29]], 12, 29]], 12, 29]], 0,
30]], 0, 30],
["DeclSep", [
["S", [], 30, 31]], 30, 31]], 0, 31]], 0, 31] It would also be possible to extend the basic formalism along the hiearchy of languages with additional features so such cases can be handled by lower level parsers. For the particular example above, a counter and transitions depending on whether the counter is zero is needed. With a stack and transitions depending on the top symbol, we would have classic deterministic pushdown transducers. Similarily, there could be a finite number of stacks in parallel used in this manner. Beyond that there is probably no point in further extensions.
The Internet Standards body IETF primarily uses the ABNF format to define the syntax of data formats and protocol messages. ABNF lacks features to import symbols from different grammars and does not support namespace mechanisms which can make it difficult to create grammars that properly define all symbols in order to use them with existing ABNF tools. For instance, different specifications might use the same non-terminal name for different things, so grammars cannot simply be concatenated.
A simple mitigation would be to add prefixes to imported rulenames. In order to do that reliably and automatically, an ABNF parser is required. Ideally, for this simple transformation, a tool would do nothing but add prefixes to rulenames, but in practise tools are likely to make additional changes, like normalising or removing formatting, stripping comments, possibly normalise the case of rulenames, change their order, or normalising the format of various non-termials. They might also be unable to process some grammars e.g. due to semantic or higher-level syntactic problems like rules that are referenced but not defined or only defined using the prose rule construct.
With the tools introduced above it is easy to make a tool that just renames rulenames without making any other change and without any requirements beyond the basic well-formedness of the input grammar.
var fs = require('fs');
var util = require('util');
var data = fs.readFileSync(process.argv[2], {
"encoding": "utf-8"
});
var root = JSON.parse(fs.readFileSync(process.argv[3]));
var prefix = process.argv[4];
var todo = [root];
var indices = [];
/////////////////////////////////////////////////////////////////////
// Taking the output of `generate_json_formatted_parse_tree` the JSON
// formatted parse tree is traversed to find the start positions of
// all `rulename`s that appear in a given input ABNF grammar file.
/////////////////////////////////////////////////////////////////////
while (todo.length > 0) {
var current = todo.shift();
todo = current[1].concat(todo);
if (current[0] == "rulename")
indices.push(current[2]);
}
/////////////////////////////////////////////////////////////////////
// The input is then copied, adding the desired prefix as needed.
/////////////////////////////////////////////////////////////////////
var result = "";
if (indices.length) {
var rest = data.substr(indices[indices.length - 1]);
for (var ix = 0; indices.length;) {
var current = indices.shift();
result += data.substr(ix, current - ix);
result += prefix;
ix = current;
}
result += rest;
} else {
result = data;
}
process.stdout.write(result);Usage:
% node demo-parselov.js rfc5234.rulelist.json.gz ex.abnf -json > tmp
% node add-prefix.js ex.abnf tmp "ex-" > prefixed.abnf
Input:
rulelist = 1*( rule / (*c-wsp c-nl) )
...
Output:
ex-rulelist = 1*( ex-rule / (*ex-c-wsp ex-c-nl) )
...
The process is fully reversible by parsing the output and removing
the prefix from all rulenames, assuming an appropriate prefix.
That makes it easy, for instance, to later prove that the modified
grammar is identical to the original, which can be much harder if
other changes are made. Furthermore, the code is not subject to any
limitations that might be imposed by a hand-written ABNF parser. If
some rules are left undefined, or if they are defined using prose
rule constructs that are not generally machine-readable and thus
unsuitable for many applications, or whatever else, so long as the
input actually matches the ABNF meta-grammar, the tool works as
advertised.
There are many situations where similar applications can be useful. For instance, sometimes it may be necessary to inject document type declarations or entity definitions into XML fragments when turning a legacy XML database into a new format because the legacy system omitted them and the employed XML toolkit does not support such a feature natively. Instead of fiddling with such fragments using regular expressions, which may produce incorrect results in some unusual situations (like a document type declaration that has been commented out), an approach as outlined above would ensure correct results.
Another simple example are "minification" applications that remove
redundant parts of documents to reduce their transfer size, like
removing formatting white space from JSON documents. For that use
case, the data file for JSON can be used. The code would look for
ws portions in a JSON document and omit corresponding characters
when producing the output. For the specific case of JSON this may
be uninteresting nowadays because many implementations that can do
this exist, the point is that they are easy to write when proper
parsing is taken care of, as this system does.
A more complex example are variations and extensions of data formats.
To stick with the example of JSON, since JSON originates with the
JavaScript programming language, and as it lacks some features, it
is fairly common to encounter web services that do not emit strictly
compliant JSON, either for legacy reasons or due to delibate choices.
For instance, comments might be included, or rather than using null
they might encode undefined values using the empty string. Say,
[1,2,,4] /* the third value is `undefined` */Typical JSON parsers will be unable to process such data, but it is
easy to remove the comment and inject a null value where it is
missing. Then any JSON parser can be used to process the document. It
is tempting to remove the comment and insert the null value using
regular expression replacement facilities, but doing so manually is
likely to produce incorrect results in some edge cases, like when
something that looks like a comment is included in a quoted string.
Instead, a data file for a more liberal JSON grammar could be made,
and then the desired modifications could be applied as explained
above.
Since the main part of the parsing process is entirely transparent to
higher-level code, it is easy to analyse which parts of the data files
are actually used when running them over a large corpus of documents.
For instance, the W3C provides a large set of XML documents as part of
the XML Test Suite. The following code
takes all .xml files in a given directory, assumes that the files
are UTF-8-encoded, and then runs their contents through the forwards
automaton and records the number of times a given state has been
reached in a histogram. Finally it relates the number of states that
have never been reached to the total number of states which gives a
simple coverage metric:
var fs = require('fs');
var zlib = require('zlib');
var util = require('util');
var seen = {};
var todo = [ process.argv[3] ];
var files = [];
while (todo.length) {
var current = todo.pop();
if (seen[current])
continue;
seen[current] = true;
var stat = fs.statSync(current);
if (stat.isFile())
files.push(current);
if (!stat.isDirectory())
continue;
todo = todo.concat(fs.readdirSync(current).map(function(p) {
return current + "/" + p;
}));
}
var xml_files = files.filter(function(p) {
return p.match(/\.xml$/);
});
zlib.gunzip(fs.readFileSync(process.argv[2]), function(err, buf) {
var g = JSON.parse(buf);
var histogram = [];
g.forwards.forEach(function(e, ix) {
histogram[ix] = 0;
});
for (var ix in xml_files) {
var path = xml_files[ix];
var input = fs.readFileSync(path, {
"encoding": "utf-8"
});
var s = [].map.call(input, function(ch) {
return g.input_to_symbol[ ch.charCodeAt(0) ] || 0
});
var fstate = 1;
var forwards = [fstate].concat(s.map(function(i) {
return fstate = g.forwards[fstate].transitions[i] || 0;
}));
forwards.forEach(function(e) {
histogram[e]++;
});
}
var unused = [];
histogram.forEach(function(e, ix) {
if (e == 0)
unused.push(ix);
});
process.stdout.write("Forward state coverage: "
+ (1 - unused.length / histogram.length));
});Output for the 20130923 version:
% node xmlts.js xml4e.document.json.gz ./xmlconf
Forward state coverage: 0.7478632478632479
This means almost 75% of the states are covered by the .xml files
in the sample. Note that the automaton has different states for cases
like "hexadecimal character reference in attribute value" where the
attribute value is in single quotes and where it is in double quotes.
Humans are not likely to manually write test cases for each and every
such variation, which should explain part of the gap in coverage.
The application can effortlessly be extended to report coverage with
respect to other parts of the data, such as which transitions have
been used, and state and transition coverage for the backwards case.
Edge and vertex coverage can also be interesting. Note that the tool
is, except for the .xml filter, entirely generic and does not know
anything about XML.
Generating random documents that match the grammar represented by the
data files is fairly simple in principle. A proper document is simply
a path through the graph (which in turn is just the combination of
all the edges in a data file) that obeys a few constraints imposed by
special vertices in the graph. For grammars that use only standard
combinators like concatenation and union that is at most recursion
nesting constraints. For simple regular grammars it would even suffice
to find a path through the forwards automaton from the first to any
accepting state. The following Perl script takes a data file and then
prints 10 random examples assuming there is a valid string.
#!perl -w
use Modern::Perl;
use Graph::Directed;
use Graph::RandomPath;
use IO::Uncompress::Gunzip qw/gunzip/;
use YAML::XS;
local $Storable::canonical = 1;
my ($path) = @ARGV;
gunzip $path => \(my $data);
my $d = YAML::XS::Load($data);
#####################################################################
# Only the `forwards` transducer knows the character transitions, and
# it is necessary to combine most of the tables in the data file to
# put them back on the edges of the graph. This is somewhat involved,
# and it might be a good idea to redundantly store this in the data.
#####################################################################
my %fwd;
for (my $src = 1; $src < @{ $d->{forwards} }; ++$src) {
for my $via (keys %{ $d->{forwards}[$src]{transitions} }) {
my $dst = $d->{forwards}[$src]{transitions}{$via};
next unless $dst;
$fwd{$src}{$dst}{$via} = 1;
}
}
#####################################################################
# Only the `backwards` automaton knows the vertices a `forward` state
# corresponds to, so it is turned into a more accessible form aswell.
#####################################################################
my %bck;
for (my $edg = 1; $edg < @{ $d->{backwards} }; ++$edg) {
next unless $d->{backwards}[$edg];
for my $dst (keys %{ $d->{backwards}[$edg]{transitions} }) {
my $edg2 = $d->{backwards}[$edg]{transitions}{$dst};
for my $src (keys %{ $d->{backwards}[$edg2]{transitions} }) {
my $edg3 = $d->{backwards}[$edg2]{transitions}{$src};
$bck{$dst}{$src}{$edg3} = 1;
}
}
}
#####################################################################
# Finally it is possible to combine the `forwards` transitions over
# input symbols with the unlabeled `char_edges` to label them.
#####################################################################
my %labels;
for my $src (keys %fwd) {
for my $dst (keys %{ $fwd{$src} }) {
for my $edg (keys %{ $bck{$dst}{$src} }) {
for (my $ix = 0; $ix < @{ $d->{char_edges}[$edg] }; ++$ix) {
my $vsrc = $d->{char_edges}[$edg][$ix][0];
my $vdst = $d->{char_edges}[$edg][$ix][1];
for my $via (keys %{ $fwd{$src}{$dst} }) {
$labels{$vsrc}{$vdst}{$via} = 1;
}
}
}
}
}
#####################################################################
# It is also necessary to turn input symbols (character classes) into
# actual input characters, so here we recover all the ranges.
#####################################################################
my %classes;
$classes{ $d->{input_to_symbol}[0] } = [[0,0]];
for (my $ax = 1; $ax < @{ $d->{input_to_symbol} }; ++$ax) {
my $cs = $d->{input_to_symbol}[$ax];
my $ps = $d->{input_to_symbol}[$ax - 1];
if ($cs == $ps) {
$classes{$cs}[-1][1]++;
} else {
push @{ $classes{$cs} }, [$ax, $ax];
}
}
#####################################################################
# A simple path might not respect proper nesting of recursions, that
# has to be done separately to reject bad paths. It would be possible
# to do that as part of the random path finding routine, of course.
#####################################################################
sub verify_path_stack {
my (@path) = @_;
my @stack;
for (my $ix = 0; $ix < @path; ++$ix) {
my $vd = $d->{vertices}[ $path[$ix] ];
next unless $vd->{type};
if ($vd->{type} eq 'start') {
push @stack, $vd->{with};
}
if ($vd->{type} eq 'final') {
return unless @stack;
my $top = pop @stack;
return unless $top eq $path[$ix];
}
}
return 0 == @stack;
}
#####################################################################
# `verify_path_stack` would actually have to explore more paths than
# the one passed to it to account for boolean combinators that may be
# included in the graph other than simple choices. To work correctly
# at least when regular operands are used, and the data file does not
# include "worst case" states, the path is tested against the DFA.
#####################################################################
sub verify_path_dfa {
my (@vias) = @_;
my $fstate = 1;
my @forwards = ($fstate, map {
$fstate = $d->{forwards}[$fstate]{transitions}{$_} // 0
} @vias);
return $d->{forwards}[$fstate]{accepts};
}
#####################################################################
# Recovering the graph is trivial, it's simply all edges combined.
#####################################################################
my $g = Graph::Directed->new;
$g->add_edges(@$_) for grep { defined } @{ $d->{char_edges} };
$g->add_edges(@$_) for grep { defined } @{ $d->{null_edges} };
#####################################################################
# The `Graph::RandomPath` does what its name implies.
#####################################################################
my $random_path = Graph::RandomPath->create_generator($g,
$d->{start_vertex},
$d->{final_vertex},
max_length => 200,
);
#####################################################################
# Finally we can generate 10 examples and print them out.
#####################################################################
binmode STDOUT, ':utf8';
my $more = 10;
while ($more) {
my @path = $random_path->();
next unless verify_path_stack(@path);
my @via_path;
for (my $ix = 1; $ix < @path; ++$ix) {
my @vias = keys %{ $labels{$path[$ix-1]}{$path[$ix]} // {} };
next unless @vias;
my $random_class = $vias[ int(rand @vias) ];
push @via_path, $random_class;
}
next unless verify_path_dfa(@via_path);
for my $random_class (@via_path) {
# TODO: the next two choices should really be random
my $first_range = $classes{$random_class}->[0];
my $first_ord = $first_range->[0];
my $char = chr $first_ord;
die unless $d->{input_to_symbol}[$first_ord] eq $random_class;
print $char;
}
print "\n";
$more -= 1;
}Usage:
% perl random-samples.pl rfc3986.URI.json.gz
A:/@?#/!?
GV.:#
VV1AA5+:/@%5A//@/%5AV////@:/_%A6@/?#1
G++5:/!A%63@///5#:/
GG0-+5+:/?#0@:
G:V+#//?/?/
A:?!??@/%AA/
A1+A://:-%3A%3A.@[VA.!-+:+!1]:3251
V:/?#
V://[::]//?#
They may not look quite like https://example.org/ but nevertheless
match the URI grammar in RFC 3986. There are many ways to guide this
process and indeed other ways to generate random samples. In many
cases it may actually be best to generate special data files that
constrain the language like imposing a prefix of http: or limiting
the range of permissable characters. A particularily useful case would
be a data file for rfc3986-URI - rfc2396-URI-reference, i.e., any
RFC 3986 URI that was not allowed under the rules of the predecessor
of the specification. Generating counter-examples is pretty much the
same, just generate paths that do not reach the final vertex or fail
one of the other tests.
If you recall the previous sample application that identifies gaps in
test suites, those gaps can easily be filled by random data. For
instance, in order to achieve perfect forwards state coverage, the
random data generator could be instructed to generate a sample for
each of the states that are not covered by the existing samples. For
the example there, the XML test suite, it might also be useful to
have additional constraints like that the sample be well-formed XML.
The million monkeys working behind the scene of the program above
can take care of that aswell, with such a test added, albeit slowly.
A simple form of syntax highlighting is associating each character in a document or protocol message with a colour according to an ideally complete syntactic analysis. An easy but inefficient approach is to take a parse tree found by a higher-level parser, which should contain all interesting information, and colour based on the names of the non-terminals therein (possibly also considering other structural properties of the tree). It would also be possible to use the states of the forwards or the backwards automaton, where the backwards automaton generally knows more about the structure of a document and would thus produce better results. The following code shows a simple implementation using the backwards automaton.
#!perl -w
use Modern::Perl;
use Graph::Directed;
use YAML::XS;
use List::MoreUtils qw/uniq/;
use List::UtilsBy qw/partition_by sort_by nsort_by/;
use IO::Uncompress::Gunzip qw/gunzip/;
use Term::ANSIColor;
use if $^O eq "MSWin32", 'Win32::Console::ANSI';
local $Storable::canonical = 1;
my ($path, $file, @highlight) = @ARGV;
gunzip $path => \(my $data);
my $d = YAML::XS::Load($data);
my $g = Graph::Directed->new;
$g->add_edges(@$_) for grep { defined } @{ $d->{char_edges} };
$g->add_edges(@$_) for grep { defined } @{ $d->{null_edges} };
#####################################################################
# The following creates `(parent, child)` edges in `$p` for all the
# vertices in the graph, where parents are always `start` vertices.
#####################################################################
sub vertices_inside {
my ($g, $v) = @_;
my @todo = $g->successors($v);
my %seen;
while (@todo) {
my $current = shift @todo;
if (($d->{vertices}[$current]{type} // "") =~ /^(final)$/) {
next if $d->{vertices}[$current]{with} eq $v;
next unless $seen{$d->{vertices}[$current]{with}};
}
next if $seen{$current}++;
if (($d->{vertices}[$current]{type} // "") =~ /^(start)$/) {
push @todo, $d->{vertices}[$current]{with};
next;
}
push @todo, $g->successors($current);
}
keys %seen;
}
my $p = Graph::Directed->new;
for my $v ($g->vertices) {
if (($d->{vertices}[$v]{type} // "") eq 'start') {
$p->add_edge($v, $_) for vertices_inside($g, $v);
}
}
#####################################################################
# Then we can associate the symbols the user asked to highlight with
# colours. For simplicity and portability this supports six colours.
#####################################################################
my @colours = qw/yellow cyan magenta green red blue/;
my %highlight_to_colour = map {
$highlight[$_] => $colours[$_]
} 0 .. $#highlight;
my %edge_to_colour;
#####################################################################
# Then each set of edges, where each set corresponds to a state in
# the backwards transducers, is associated with a colour. To do so,
# this just looks at the outgoing `char_edges` and derives a colour
# based on the vertex and its `start` ancestors.
#####################################################################
for (my $ix = 1; $ix < @{ $d->{char_edges} }; ++$ix) {
next unless defined $d->{char_edges}[$ix];
for my $e (@{ $d->{char_edges}[$ix] }) {
my @todo = $e->[0];
my %seen;
while (@todo) {
my $current = shift @todo;
next if $seen{$current}++;
push @todo, $p->predecessors($current);
next unless ($d->{vertices}[$current]{type} // '') eq 'start';
my $col = $highlight_to_colour{
$d->{vertices}[$current]{text} // ''
};
$edge_to_colour{$ix} //= $col;
last if defined $col;
}
}
}
#####################################################################
# The following is just the typical reading of data and simulating
# the finite automata in order to identify a list of edge sets.
#####################################################################
open my $f, '<:utf8', $file;
my $chars = do { local $/; binmode $f; <$f> };
my @chars = split//, $chars;
my @vias = map { $d->{input_to_symbol}[ord $_] } @chars;
my $fstate = 1;
my @forwards = ($fstate);
push @forwards, map {
$fstate = $d->{forwards}[$fstate]{transitions}{$_} // 0
} @vias;
my $bstate = 1;
my @edges = reverse map {
$bstate = $d->{backwards}[$bstate]{transitions}{$_} || 0;
} reverse @forwards;
#####################################################################
# Now the original file can be printed out with the colours added.
#####################################################################
for (my $ix = 0; $ix < @edges - 1; ++$ix) {
my $bwd = $edges[$ix];
print color($edge_to_colour{$bwd}) if $edge_to_colour{$bwd};
print $chars[$ix];
print color('reset') if $edge_to_colour{$bwd};
}Results should look like this:
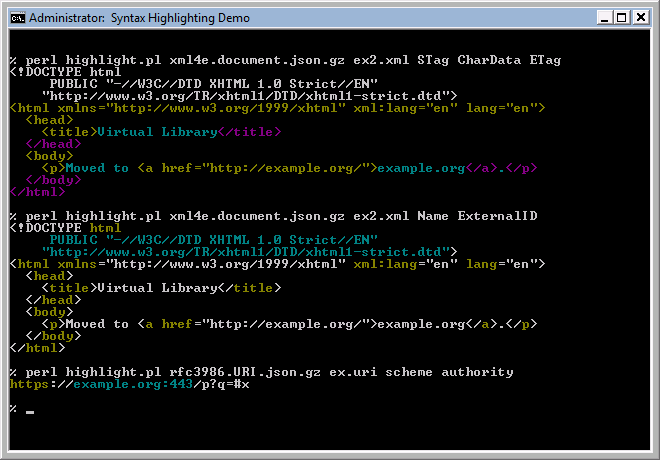
It would also be possible colour base based on forwards states. A
reason to do that would be performance and space savings, at the
expense of more incorrect colouring.
If syntax colouring is all one cares about, further space can be saved by minimising the finite state transducers. Doing so would follow the standard set parititoning algorithm, except that instead of preserving acceptance of the automaton, the colouring would be preserved (so states with different colours belong to different sets in the initial partitioning). Furthermore, states that differ only in the transitions to the non-accepting sink state (a fatal error encountered during parsing) can be merged aswell, which would make the colouring more fault tolerant.
Suppose you have a text editor with some text in a buffer and some
current cursor position, and the user of the editor would like some
help on how to complete what they have typed so far. The forwards
automaton encodes directly which characters can be used for the next
position (and by extension, the characters at any position after it),
so the buffer up to the cursor position can be put through the
forwards automaton and it can be explored a little bit further,
e.g. up to the next white-space character, to, for instance, offer a
list of words that would complete the current input.
Back in 2007 I made a simple webapp demonstrating this approach for
RFC 3986 URIs.
I gather the interface is not very self-explanatory, but the idea is
that you select URI in the list of options and then type http: in
the textarea. The "keyboard" at the top then tells you the characters
you are allowed to append. If you append //[ it will switch into a
mode that recognises IPv6 addresses allowing you to enter only hex
digits, a colon, or v. Enter http://[v1138.(Skywalker)]:42? and
it will correctly tell you that yes, indeed, that is a proper URI,
although you have never encountered such syntax in the wild. Actually
this kind of tool makes it easy to discover interesting edge cases
that could be used for testing, but as explained in a previous section,
we could just generate all "interesting" test cases automatically.
As a better example, suppose the Apache httpd web server came with
grammar for .htaccess files that defines the syntax for the format
in general and also all the standard instructions supported by the
standard modules. A user could then type Add and the editor could,
just as the webapp above does, look up in the forwards automaton
what could be added and offer a selection among AddOutputFilter,
AddType, AddLanguage, and so on. Add syntax colouring and full
validation against the grammar, as explained in previous sections,
and you have a pretty nice .htaccess editor with little effort. And
as the code to "find words from current position to white space" or
whatever else might be useful, can be written generically without any
reference to particular grammars, supporting other formats in such an
editor could be as simple as dropping in another data file, with a
few customisations like which colour to use for which symbol and
things like that.
As you can see in the soure code of the "URI checker" example, it is just a couple of lines of code that are needed when you have the description of a data format in an easily accessible form, such as the data files at the code of the system this documentation is about.
The following code solves a closely related problem: it prints out
all seemingly interesting sequences of US-ASCII letters the forwards
automaton recognises by way of having special transitions for them.
#!perl -w
use Modern::Perl;
use Graph::Directed;
use Storable qw/freeze/;
use YAML::XS;
use List::MoreUtils qw/uniq/;
use IO::Uncompress::Gunzip qw/gunzip/;
local $Storable::canonical = 1;
my ($path, $file) = @ARGV;
gunzip $path => \(my $data);
my $d = YAML::XS::Load($data);
#####################################################################
# To make things simple, we'll scan just for simple [a-z]+ sequences
#####################################################################
my @want = uniq map {
$d->{input_to_symbol}[ord $_]
} (('a' .. 'z'), ('A' .. 'Z'));
my %is_wanted = map { $_ => 1 } @want;
my %is_interesting = ( 0 => 1 );
#####################################################################
# A `forwards` state is interesting if it discriminates among the
# wanted characters, i.e., it doesn't move to the same state for all.
#####################################################################
for (my $ix = 0; $ix < @{ $d->{forwards} }; ++$ix) {
my @dsts = uniq map {
$d->{forwards}[$ix]{transitions}{$_} // 0
} @want;
$is_interesting{$ix}++ if @dsts > 1;
}
#####################################################################
# This partitions the `forwards` states into sets based on how the
# automaton might move over the wanted characters. In essence, this
# minimises the `forwards` automaton to avoid most duplicate strings.
#####################################################################
use Acme::Partitioner;
my $p = Acme::Partitioner->using(0 .. @{ $d->{forwards} } - 1);
my $partitioner = $p
->once_by(sub { $is_interesting{$_} // '' })
->then_by(sub {
my $ix = $_;
my %signature = map { $_,
$p->partition_of($d->{forwards}[$ix]{transitions}{$_} // 0)
} @want;
return Storable::freeze \%signature;
})
;
while ($partitioner->refine) {
warn "p size = " . $p->size() . "\n";
}
#####################################################################
# To merge states, we project all equivalent states onto the first.
#####################################################################
my %map;
for ($p->all_partitions) {
my $new = $_->[0];
$map{$_} = $new for @$_;
}
#####################################################################
# Then we can build a labeled graph of the merged states.
#####################################################################
my $g = Graph::Directed->new;
my %labels;
for my $ix (keys %is_interesting) {
for my $via (keys %{ $d->{forwards}[$ix]{transitions} }) {
next unless $is_wanted{$via};
my $dst = $d->{forwards}[$ix]{transitions}{$via} // 0;
next if $map{$dst} eq '0';
$g->add_edge($map{$ix}, $map{$dst})
unless $map{$ix} eq $map{$dst};
$labels{$map{$ix}}{$map{$dst}}{$via}++;
}
}
#####################################################################
# We also need a reverse map for the input character to symbol map.
#####################################################################
my %classes;
$classes{ $d->{input_to_symbol}[0] } = [[0,0]];
for (my $ax = 1; $ax < @{ $d->{input_to_symbol} }; ++$ax) {
my $cs = $d->{input_to_symbol}[$ax];
my $ps = $d->{input_to_symbol}[$ax - 1];
if ($cs == $ps) {
$classes{$cs}[-1][1]++;
} else {
push @{ $classes{$cs} }, [$ax, $ax];
}
}
#####################################################################
# Starting from the roots, print out all strings.
#####################################################################
my @todo = map { [$_] } $g->predecessorless_vertices;
while (@todo) {
my $p = shift @todo;
if ($g->successors($p->[-1])) {
push @todo, [@$p, $_] for
$g->successors($p->[-1]);
} else {
for (my $ix = 1; $ix < @$p; ++$ix) {
my @vias = keys %{ $labels{$p->[$ix-1]}{$p->[$ix]} };
# Note that this prints out the first member of a class.
# It does not print out the entire class. Maybe it should.
my @firsts = map { $classes{$_}[0][0] } @vias;
if (@firsts > 1) {
printf "[%s]", join '|', map chr, @firsts;
} else {
printf "%s", map chr, @firsts;
}
}
print "\n";
}
}Applying this to the XML 1.0 data file should print out something like:
[I|H|R|Q|F|O|C|D|E|P|L|G|Y|N|A|U|M|S|T|K|B|V]
X[R|Q|H|I|F|E|D|C|O|Y|G|L|P|U|A|N|S|X|T|V|B|K]
NO
XM[I|H|R|Q|F|O|C|D|E|P|L|Y|G|A|N|U|X|M|S|T|K|B|V]
ANY
YES
EMPTY
CDATA
FIXED
NDATA
...
The complicated lines above correspond to the complement of "xml".
That is a special case in the grammar that disambiguates the XML
declaration from processing instructions. Most of the literals are
used only in the prolog of an XML document, but you might recognise
CDATA from <![CDATA[]]> sections. Auto-completion from a specific
point as discussed in this section can be implemented much like this,
constrained to a specific state at the cursor position.
The sytax highlighting script provides us with a cheap way to extract rudimentary information from documents. One interesting example is extracting ABNF grammars from RFC standard documents. To do so we can make a couple of changes to the ABNF grammar from RFC 5234. One change we need is that in RFCs the grammars are typically indented. It is also necessary to provide an alternative to match things that are not ABNF grammars. That gives:
RFC-with-ABNF = *(rulelist / other-line)
other-line = *(%x20 / %x09 / %x0C / %x21-7E) %x0D %x0A
rule = *WSP rulename defined-as elements c-nl
Furthermore, ABNF requires using CRLF as line terminator. It would be possible to change the grammar so it also accepts bare LF instead, but it is easier to simply ensure the RFC text uses CRLFs aswell.

This is of course not guaranteed to work perfectly in all cases. For instance, applying the script and grammar to RFC 5234 itself would highlight example code that is meant to illustrate the ABNF syntax, not something that you would want to extract. Likewise, some RFCs will certainly have text that looks like ABNF but is something else. RFC text also contains page headers and footers, and it is possible that there are ABNF rules in RFCs with a page break in the middle. It would be possible to further modify the grammar to allow these page breaks, but that would make the grammar much more complex. It is easier to eliminate them as pre-processing step. Still, cursory testing suggests this simple approach may work even better than the only other tool designed to do this, which has trouble extracting the ABNF from RFC 4627 (JSON) correctly. It would be very interesting to run both tools against all the RFCs and compare the results.
A data file can be converted into a regular expression following any
standard textbook algorithm. If the forwards automaton is complete,
any DFA to RE algorithm can be directly applied to it. The only thing
to note is that the automaton's transitions are over sets of input
symbols rather than the input symbols (think "ASCII" and "Unicode"
for "input symbol" and "character class" as you might know them from
regular expressions for "sets of input symbols"); the %classes map
in the code to generate random samples can be used to map "character
classes" back to individual input symbols.
If the forwards automaton is not complete, the graph that represents
the grammar can be used instead. That requires knowing the labels of
the edges in the graph. The %labels map in the code to generate the
random samples contain them, and likewise the %classes map can be
used to turn the labels back into individual input symbols. A common
textbook algorithm called "state elimination" can be applied to the
graph (vertices in the graph can be eliminated by connecting their
predecessors directly to their successors by increasingly more complex
regular expressions instead of simple "labels").
Not just because loops in the forwards automaton or the graph itself
can be expanded arbitrarily often, regular expressions can be O(4^n),
or worse, larger than their representation in the data files, and the
standard algorithms, including optimisations to them, typically do not
generate what one might consider reasonably-sized expressions if one is
used to Perl-compatible regular expressions (for instance, they
typically do not use the + quantifier, and they often do not factor
expressions on the right side, i.e., they do not simplify an expression
like (ac|bc) into (a|b)c. So the results might be surprising or
disappointing. I do not think kilobyte-sized regex blobs should be used
as anything but a curiosity, so implementing this is left as an
excercise to the reader.
Eventually.