Releases: huggingface/transformers
v4.57.0: Qwen3-Next, Vault Gemma, Qwen3 VL, LongCat Flash, Flex OLMO, LFM2 VL, BLT, Qwen3 OMNI MoE, Parakeet, EdgeTAM, OLMO3
New model additions
Qwen3 Next

The Qwen3-Next series represents the Qwen team's next-generation foundation models, optimized for extreme context length and large-scale parameter efficiency.
The series introduces a suite of architectural innovations designed to maximize performance while minimizing computational cost:
- Hybrid Attention: Replaces standard attention with the combination of Gated DeltaNet and Gated Attention, enabling efficient context modeling.
- High-Sparsity MoE: Achieves an extreme low activation ratio as 1:50 in MoE layers — drastically reducing FLOPs per token while preserving model capacity.
- Multi-Token Prediction(MTP): Boosts pretraining model performance, and accelerates inference.
- Other Optimizations: Includes techniques such as zero-centered and weight-decayed layernorm, Gated Attention, and other stabilizing enhancements for robust training.
Built on this architecture, they trained and open-sourced Qwen3-Next-80B-A3B — 80B total parameters, only 3B active — achieving extreme sparsity and efficiency.
Despite its ultra-efficiency, it outperforms Qwen3-32B on downstream tasks — while requiring less than 1/10 of the training cost.
Moreover, it delivers over 10x higher inference throughput than Qwen3-32B when handling contexts longer than 32K tokens.
For more details, please visit their blog Qwen3-Next (blog post).
- Adding Support for Qwen3-Next by @bozheng-hit in #40771
Vault Gemma

VaultGemma is a text-only decoder model derived from Gemma 2, notably it drops the norms after the Attention and MLP blocks, and uses full attention for all layers instead of alternating between full attention and local sliding attention. VaultGemma is available as a pretrained model with 1B parameters that uses a 1024 token sequence length.
VaultGemma was trained from scratch with sequence-level differential privacy (DP). Its training data includes the same mixture as the Gemma 2 models, consisting of a number of documents of varying lengths. Additionally, it is trained using DP stochastic gradient descent (DP-SGD) and provides a (ε ≤ 2.0, δ ≤ 1.1e-10)-sequence-level DP guarantee, where a sequence consists of 1024 consecutive tokens extracted from heterogeneous data sources. Specifically, the privacy unit of the guarantee is for the sequences after sampling and packing of the mixture.
- add: differential privacy research model by @RyanMullins in #40851
Qwen3 VL

Qwen3-VL is a multimodal vision-language model series, encompassing both dense and MoE variants, as well as Instruct and Thinking versions.
Building upon its predecessors, Qwen3-VL delivers significant improvements in visual understanding while maintaining strong pure text capabilities. Key architectural advancements include: enhanced MRope with interleaved layout for better spatial-temporal modeling, DeepStack integration to effectively leverage multi-level features from the Vision Transformer (ViT), and improved video understanding through text-based time alignment—evolving from T-RoPE to text timestamp alignment for more precise temporal grounding.
These innovations collectively enable Qwen3-VL to achieve superior performance in complex multimodal tasks.
Longcat Flash

The LongCatFlash model was proposed in LongCat-Flash Technical Report by the Meituan LongCat Team. LongCat-Flash is a 560B parameter Mixture-of-Experts (MoE) model that activates 18.6B-31.3B parameters dynamically (average ~27B). The model features a shortcut-connected architecture enabling high inference speed (>100 tokens/second) and advanced reasoning capabilities.
The abstract from the paper is the following:
We present LongCat-Flash, a 560 billion parameter Mixture-of-Experts (MoE) language model featuring a dynamic computation mechanism that activates 18.6B-31.3B parameters based on context (average ~27B). The model incorporates a shortcut-connected architecture enabling high inference speed (>100 tokens/second) and demonstrates strong performance across multiple benchmarks including 89.71% accuracy on MMLU and exceptional agentic tool use capabilities.
Tips:
- LongCat-Flash uses a unique shortcut-connected MoE architecture that enables faster inference compared to traditional MoE models
- The model supports up to 128k context length for long-form tasks
- Dynamic parameter activation makes it computationally efficient while maintaining high performance
- Best suited for applications requiring strong reasoning, coding, and tool-calling capabilities
- The MoE architecture includes zero experts (nn.Identity modules) which act as skip connections, allowing tokens to bypass expert computation when appropriate
Flex Olmo

FlexOlmo is a new class of language models (LMs) that supports (1) distributed training without data sharing, where different model parameters are independently trained on closed datasets, and (2) data-flexible inference, where these parameters along with their associated data can be flexibly included or excluded from model inferences with no further training. FlexOlmo employs a mixture-of-experts (MoE) architecture where each expert is trained independently on closed datasets and later integrated through a new domain-informed routing without any joint training. FlexOlmo is trained on FlexMix, a corpus we curate comprising publicly available datasets alongside seven domain-specific sets, representing realistic approximations of closed sets.
You can find all the original FlexOlmo checkpoints under the FlexOlmo collection.
- Add FlexOlmo model by @2015aroras in #40921
LFM2 VL

LFM2-VL first series of vision-language foundation models developed by Liquid AI. These multimodal models are designed for low-latency and device-aware deployment. LFM2-VL extends the LFM2 family of open-weight Liquid Foundation Models (LFMs) into the vision-language space, supporting both text and image inputs with variable resolutions.
Architecture
LFM2-VL consists of three main components: a language model backbone, a vision encoder, and a multimodal projector. LFM2-VL builds upon the LFM2 backbone, inheriting from either LFM2-1.2B (for LFM2-VL-1.6B) or LFM2-350M (for LFM2-VL-450M). For the vision tower, LFM2-VL uses SigLIP2 NaFlex encoders to convert input images into token sequences. Two variants are implemented:
- Shape-optimized (400M) for more fine-grained vision capabilities for LFM2-VL-1.6B
- Base (86M) for fast image processing for LFM2-VL-450M
The encoder processes images at their native resolution up to 512×512 pixels, efficiently handling smaller images without upscaling and supporting non-standard aspect ratios without distortion. Larger images are split into non-overlapping square patches of 512×512 each, preserving detail. In LFM2-VL-1.6B, the model also receives a thumbnail (a small, downscaled version of the original image capturing the overall scene) to enhance global context understanding and alignment. Special tokens mark each patch’s position and indicate the thumbnail’s start. The multimodal connector is a 2-layer MLP connector with pixel unshuffle to reduce image token count.
- Add new model LFM2-VL by @zucchini-nlp in #40624
BLT

The BLT model was proposed in Byte Latent Transformer: Patches Scale Better Than Tokens by Artidoro Pagnoni, Ram Pasunuru, Pedro Rodriguez, John Nguyen, Benjamin Muller, Margaret Li1, Chunting Zhou, Lili Yu, Jason Weston, Luke Zettlemoyer, Gargi Ghosh, Mike Lewis, Ari Holtzman†, Srinivasan Iyer.
BLT is a byte-level LLM that achieves tokenization-level performance through entropy-based dynamic patching.
The abstract from the paper is the following:
*We introduce the Byte Latent Transformer (BLT), a new byte-level LLM architecture that, for the first time, matches tokenization-based LLM performance at scale with significant improvements in inference
efficiency and robustness. BLT encodes bytes into dynamically sized patches, which serve as the primary units of computation. Patches are segmented based on the entropy of the next byte, allocating
more compute and model capacity where increased data complexity demands it. We present the first flop controlled sca...
Contributors
Assets 2
Patch release v4.56.2
Vault-Gemma (based on v4.56.1)
A new model is added to transformers: Vault-Gemma
It is added on top of the v4.56.1 release, and can be installed from the following tag: v4.56.1-Vault-Gemma-preview.
In order to install this version, please install with the following command:
pip install git+https://github.com/huggingface/[email protected]
If fixes are needed, they will be applied to this release; this installation may therefore be considered as stable and improving.
As the tag implies, this tag is a preview of the Vault-Gemma model. This tag is a tagged version of the main branch and does not follow semantic versioning. This model will be included in the next minor release: v4.57.0.
Vault-Gemma
VaultGemma is a text-only decoder model derived from Gemma 2, notably it drops the norms after the Attention and MLP blocks, and uses full attention for all layers instead of alternating between full attention and local sliding attention. VaultGemma is available as a pretrained model with 1B parameters that uses a 1024 token sequence length.
VaultGemma was trained from scratch with sequence-level differential privacy (DP). Its training data includes the same mixture as the Gemma 2 models, consisting of a number of documents of varying lengths. Additionally, it is trained using DP stochastic gradient descent (DP-SGD) and provides a (ε ≤ 2.0, δ ≤ 1.1e-10)-sequence-level DP guarantee, where a sequence consists of 1024 consecutive tokens extracted from heterogeneous data sources. Specifically, the privacy unit of the guarantee is for the sequences after sampling and packing of the mixture.
The example below demonstrates how to chat with the model with pipeline:
from transformers import pipeline
pipe = pipeline(
task="text-generation",
model="google/vaultgemma-1b",
dtype="auto",
device_map="auto",
)
text = "Tell me an unknown interesting biology fact about the brain."
outputs = pipe(text, max_new_tokens=32)
response = outputs[0]["generated_text"]
print(response)with the AutoModelForCausalLM class:
# pip install accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = "google/vaultgemma-1b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto", dtype="auto")
text = "Tell me an unknown interesting biology fact about the brain."
input_ids = tokenizer(text, return_tensors="pt").to(model.device)
outputs = model.generate(**input_ids, max_new_tokens=32)
print(tokenizer.decode(outputs[0]))or with transformers chat:
transformers chat google/vaultgemma-1b
Embedding Gemma (based on v4.56.0)
60b68e3A new model is added to transformers: Embedding Gemma
It is added on top of the v4.56.0 release, and can be installed from the following tag: v4.56.0-Embedding-Gemma-preview.
In order to install this version, please install with the following command:
pip install git+https://github.com/huggingface/[email protected]
If fixes are needed, they will be applied to this release; this installation may therefore be considered as stable and improving.
As the tag implies, this tag is a preview of the EmbeddingGemma model. This tag is a tagged version of the main branch and does not follow semantic versioning. This model will be included in the next minor release: v4.57.0.
Embedding-Gemma

Today, Google releases EmbeddingGemma, a state-of-the-art multilingual embedding model perfect for on-device use cases. Designed for speed and efficiency, the model features a compact size of 308M parameters and a 2K context window, unlocking new possibilities for mobile RAG pipelines, agents, and more. EmbeddingGemma is trained to support over 100 languages and is the highest-ranking text-only multilingual embedding model under 500M on the Massive Text Embedding Benchmark (MTEB) at the time of writing.
Usage example
EmbeddingGemma can be found on the Huggingface Hub. It is integrated in sentence-transformers which depends on transformers.
See below for sentence-transformers examples using the model:
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("google/embeddinggemma-300m")
# Run inference with queries and documents
query = "Which planet is known as the Red Planet?"
documents = [
"Venus is often called Earth's twin because of its similar size and proximity.",
"Mars, known for its reddish appearance, is often referred to as the Red Planet.",
"Jupiter, the largest planet in our solar system, has a prominent red spot.",
"Saturn, famous for its rings, is sometimes mistaken for the Red Planet."
]
query_embeddings = model.encode_query(query)
document_embeddings = model.encode_document(documents)
print(query_embeddings.shape, document_embeddings.shape)
# (768,) (4, 768)
# Compute similarities to determine a ranking
similarities = model.similarity(query_embeddings, document_embeddings)
print(similarities)
# tensor([[0.3011, 0.6359, 0.4930, 0.4889]])
# Convert similarities to a ranking
ranking = similarities.argsort(descending=True)[0]
print(ranking)
# tensor([1, 2, 3, 0])Patch release v4.56.1
91393fePatch release v4.56.1
This patch most notably fixes an issue with the new dtype argument (replacing torch_dtype) in pipelines!
Bug Fixes & Improvements
- Fix broken Llama4 accuracy in MoE part (#40609)
- fix pipeline dtype (#40638)
- Fix self.dropout_p is not defined for SamAttention/Sam2Attention (#40667)
- Fix backward compatibility with accelerate in Trainer (#40668)
- fix broken offline mode when loading tokenizer from hub (#40669)
- [Glm4.5V] fix vLLM support (#40696)
v4.56: Dino v3, X-Codec, Ovis 2, MetaCLIP 2, Florence 2, SAM 2, Kosmos 2.5, HunYuan, GLMV-4.5
New model additions
Dino v3
DINOv3 is a family of versatile vision foundation models that outperforms the specialized state of the art across a broad range of settings, without fine-tuning. DINOv3 produces high-quality dense features that achieve outstanding performance on various vision tasks, significantly surpassing previous self- and weakly-supervised foundation models.
You can find all the original DINOv3 checkpoints under the DINOv3 collection.

X-Codec
he X-Codec model was proposed in Codec Does Matter: Exploring the Semantic Shortcoming of Codec for Audio Language Model by Zhen Ye, Peiwen Sun, Jiahe Lei, Hongzhan Lin, Xu Tan, Zheqi Dai, Qiuqiang Kong, Jianyi Chen, Jiahao Pan, Qifeng Liu, Yike Guo, Wei Xue
The X-Codec model is a neural audio codec that integrates semantic information from self-supervised models (e.g., HuBERT) alongside traditional acoustic information. This enables :
- Music continuation : Better modeling of musical semantics yields more coherent continuations.
- Text-to-Sound Synthesis : X-Codec captures semantic alignment between text prompts and generated audio.
- Semantic aware audio tokenization: X-Codec is used as an audio tokenizer in the YuE lyrics to song generation model.

- Add X-Codec model by @Manalelaidouni in #38248
Ovis 2
The Ovis2 is an updated version of the Ovis model developed by the AIDC-AI team at Alibaba International Digital Commerce Group.
Ovis2 is the latest advancement in multi-modal large language models (MLLMs), succeeding Ovis1.6. It retains the architectural design of the Ovis series, which focuses on aligning visual and textual embeddings, and introduces major improvements in data curation and training methods.
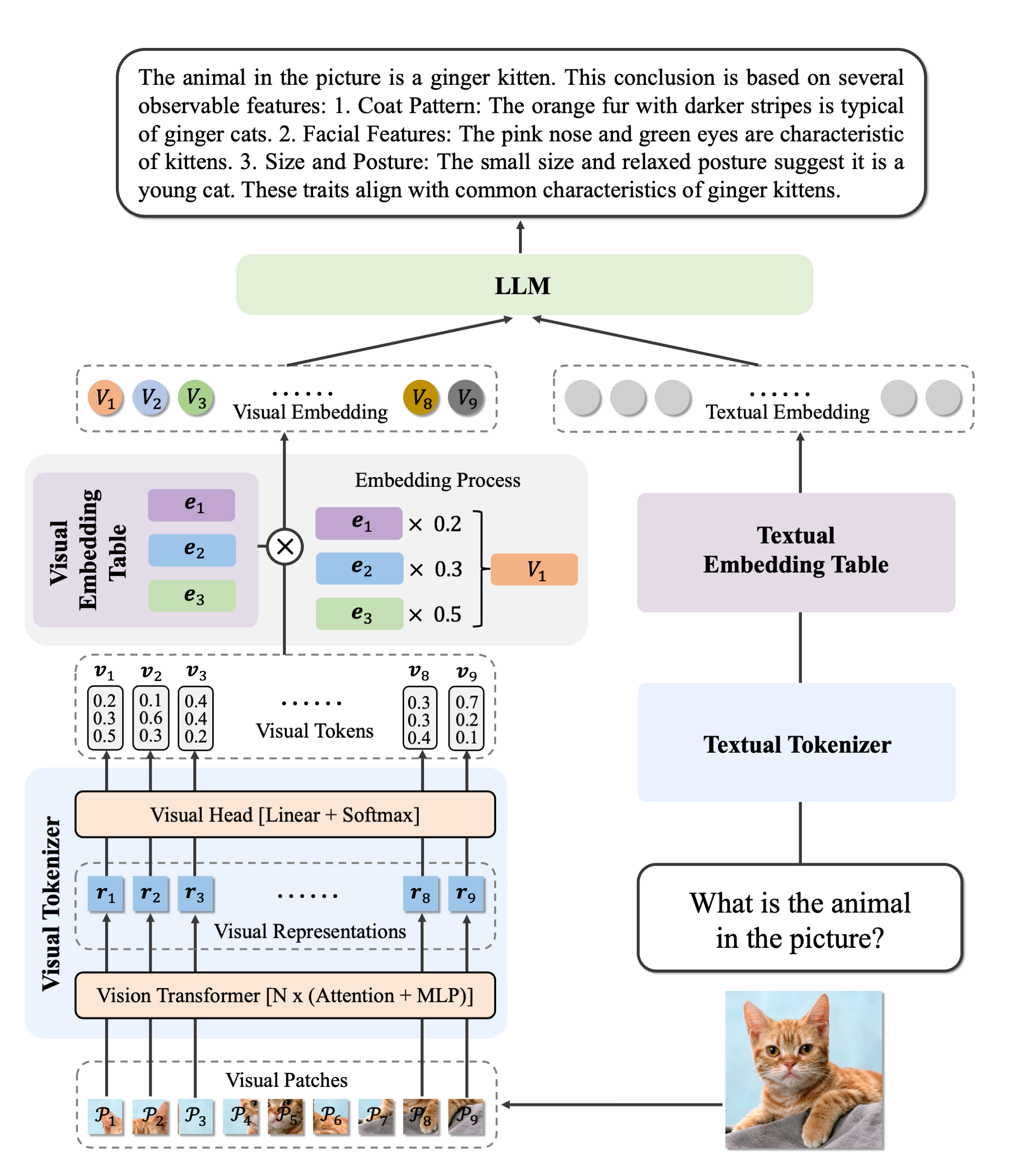
- Add Ovis2 model and processor implementation by @thisisiron in #37088
MetaCLIP 2
MetaCLIP 2 is a replication of the original CLIP model trained on 300+ languages. It achieves state-of-the-art (SOTA) results on multilingual benchmarks (e.g., XM3600, CVQA, Babel‑ImageNet), surpassing previous SOTA such as mSigLIP and SigLIP‑2. The authors show that English and non-English worlds can mutually benefit and elevate each other.

- Add MetaCLIP 2 by @NielsRogge in #39826
Florence 2
Florence-2 is an advanced vision foundation model that uses a prompt-based approach to handle a wide range of vision and vision-language tasks. Florence-2 can interpret simple text prompts to perform tasks like captioning, object detection, and segmentation. It leverages the FLD-5B dataset, containing 5.4 billion annotations across 126 million images, to master multi-task learning. The model's sequence-to-sequence architecture enables it to excel in both zero-shot and fine-tuned settings, proving to be a competitive vision foundation model.

- Add support for Florence-2 by @ducviet00 in #38188
SAM 2
SAM2 (Segment Anything Model 2) was proposed in Segment Anything in Images and Videos by Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Dollár, Christoph Feichtenhofer.
The model can be used to predict segmentation masks of any object of interest given an input image or video, and input points or bounding boxes.

- Add Segment Anything 2 (SAM2) by @SangbumChoi in #32317
Kosmos 2.5
The Kosmos-2.5 model was proposed in KOSMOS-2.5: A Multimodal Literate Model by Microsoft.
The abstract from the paper is the following:
We present Kosmos-2.5, a multimodal literate model for machine reading of text-intensive images. Pre-trained on large-scale text-intensive images, Kosmos-2.5 excels in two distinct yet cooperative transcription tasks: (1) generating spatially-aware text blocks, where each block of text is assigned its spatial coordinates within the image, and (2) producing structured text output that captures styles and structures into the markdown format. This unified multimodal literate capability is achieved through a shared Transformer architecture, task-specific prompts, and flexible text representations. We evaluate Kosmos-2.5 on end-to-end document-level text recognition and image-to-markdown text generation. Furthermore, the model can be readily adapted for any text-intensive image understanding task with different prompts through supervised fine-tuning, making it a general-purpose tool for real-world applications involving text-rich images. This work also paves the way for the future scaling of multimodal large language models.

HunYuan

More information at release 🤗
Seed OSS

More information at release 🤗
- Adding ByteDance Seed Seed-OSS by @Fazziekey in #40272
GLM-4.5V
More information at release 🤗
- GLM-4.5V Model Support by @zRzRzRzRzRzRzR in #39805
Cache
Beyond a large refactor of the caching system in Transformers, making it much more practical and general, models using sliding window attention/chunk attention do not waste memory anymore when caching past states. It was allowed most notable by:
- New DynamicSlidingWindowLayer & associated Cache by @Cyrilvallez in #40039
See the following improvements on memory usage for Mistral (using only sliding layers) and GPT-OSS (1 out of 2 layers is sliding) respectively:


Beyond memory usage, it will also improve generation/forward speed by a large margin for large contexts, as only necessary states are passed to the attention computation, which is very sensitive to the sequence length.
Quantization
MXFP4
Since the GPT-OSS release which introduced the MXPF4 quantization type, several improvements have been made to the support, which should now stabilize.
- Fix MXFP4 quantizer validation to allow CPU inference with dequantize option by @returnL in #39953
- Enable gpt-oss mxfp4 on older hardware (sm75+) by @matthewdouglas in #39940
- Fix typo and improve GPU kernel check error message in MXFP4 quantization by @akintunero in #40349)
- Default to dequantize if cpu in device_map for mxfp4 by @MekkCyber in #39993
- Fix GPT-OSS
swiglu_limitnot passed in for MXFP4 by @danielhanchen in #40197 - [
Mxfp4] Add a way to save with a quantization method by @ArthurZucker in #40176
New standard
Now that we deprecated tensorflow and jax, we felt that torch_dtype was not only misaligned with torch, but was redundant and hard to remember. For this reason, we switched to a much more standard dtype argument!
⚠️ ⚠️ Use dtype instead of torch_dtype everywhere! by @Cyrilvallez in #39782
torch_dtype will still be a valid usage for as long as needed to ensure a smooth transition, but new code should use dtype, and we encourage you to update older code as well!
Breaking changes
The following commits are breaking changes in workflows that were either buggy or not working as expected.
Saner hub-defaults for hybrid cache implementation
On models where the hub checkpoint specifies cache_implementation="hybrid" (static sliding window hybrid cache), UNSETS this value. This will make the model use the dynamic sliding window layers by default.
This default meant that there were widespread super slow 1st generate calls on models with hybrid caches, which should nol onger be the case.
Sine positional embeddings for MaskFormer & LRU cache
Cache the computation of sine positional embeddings for MaskFormer; results in a 6% performance improvement.
- 🚨 Use lru_cache for sine pos embeddings MaskFormer by @yonigozlan in #40007
Explicit cache initialization
Adds explicit cache initialization to prepare for the deprecation of the from_legacy_cache utility.
- 🚨 Always return Cache objects in modelings (to align with generate) by @manueldeprada...
Contributors
Assets 2
Patch v4.55.4
Patch release v4.55.3
Patch release 4.55.3
Focused on stabilizing FlashAttention-2 on Ascend NPU, improving FSDP behavior for generic-task models, fixing MXFP4 integration for GPT-OSS
Bug Fixes & Improvements
- FlashAttention-2 / Ascend NPU – Fix “unavailable” runtime error (#40151) by @FightingZhen
- FlashAttention kwargs – Revert FA kwargs preparation to resolve regression (#40161) by @Cyrilvallez
- FSDP (generic-task models) – Fix sharding/runtime issues (#40191) by @Cyrilvallez
- GPT-OSS / MXFP4 – Ensure swiglu_limit is correctly passed through (#40197) by @danielhanchen
- Mamba – Fix cache handling to prevent stale/incorrect state (#40203) by @manueldeprada
- Misc – Minor follow-up fix addressing #40262 by @ArthurZucker
Contributors
Assets 2
Patch release 4.55.2: for FA2 users!
Patch release 4.55.2!
only affects FA2 generations!
😢 Well sorry everyone, sometimes shit can happen...
4.55.1 was broken because of 🥁 git merge conflict.
I cherry-picked #40002 without having #40029 , thus from ..modeling_flash_attention_utils import prepare_fa_kwargs_from_position_ids is missing, and since this is a slow test, nothing caught it.
Will work to remediate and write the post-mortem when yanking the release.
Patch release 4.55.1
Patch release 4.55.1:
Mostly focused around stabalizing the Mxfp4 for GPTOSS model!
Bug Fixes & Improvements
- Idefics2, Idefics3, SmolVLM – Fix tensor device issue (#39975) by @qgallouedec
- Merge conflicts – Fix merge conflicts from previous changes by @vasqu
- MXFP4 / CPU device_map – Default to dequantize when CPU is in device_map (#39993) by @MekkCyber
- GPT Big Code – Fix attention scaling (#40041) by @vasqu
- Windows compatibility – Resolve Triton version check compatibility (#39986) by @Tsumugii24 @MekkCyber
- Gemma3n model – Add missing None default values for get_placeholder_mask (#39991, #40024) by @Znerual
- Fuyu model – Fix broken image inference (#39915) by @Isotr0py
- PerceptionLM – Fix missing video inputs (#39971) by @shuminghu
- Idefics – Fix device mismatch (#39981) by @zucchini-nlp
- Triton kernels – Remove triton_kernels dependency in favor of included kernels (#39926) by @SunMarc
- GPT-OSS MXFP4 – Enable on older hardware (sm75+) (#39940) by @matthewdouglas @SunMarc
- MXFP4 quantizer – Allow CPU inference with dequantize option (#39953) by @returnL
CI & Build
- CI stability – Post-GPT-OSS fixes for green CI (#39929) by @gante @LysandreJik