Portfolio Highlight: End-to-end ML pipeline for predicting term deposit subscriptions using advanced feature engineering and a tuned Artificial Neural Network (ANN).
This project demonstrates how to build a robust, interpretable, and business-relevant machine learning solution for bank marketing. The workflow—from data cleaning to ANN optimization—mirrors real-world data science best practices and is designed for portfolio presentation.
- Project Overview
- Dataset Deep Dive
- Project Structure
- Quick Start
- Installation
- Usage
- Technical Deep Dive
- Results and Analysis
- Rationale for Model Selection
- Conclusion & Future Work
- Contributing
- License
Goal: Predict which bank customers will subscribe to a term deposit using a modern ML pipeline, with a focus on business value and model interpretability.
Key Steps:
- Data cleaning & feature engineering
- Exploratory data analysis (EDA)
- Feature selection
- ANN model development & tuning
- Evaluation & business recommendations
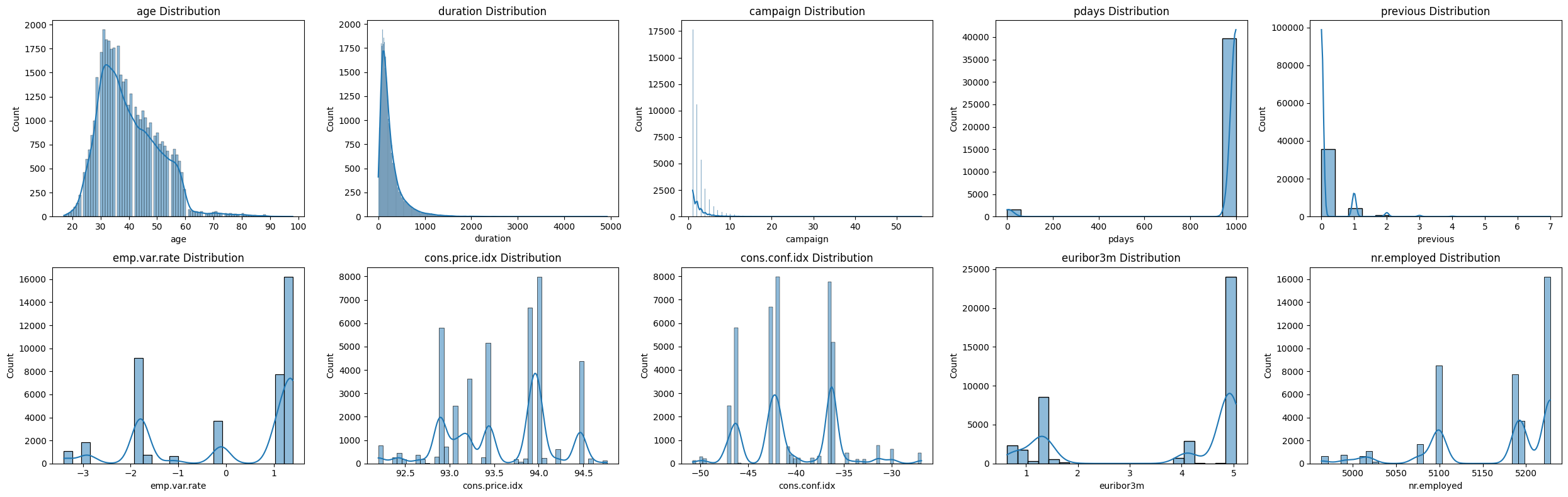
Dataset: 41,188 samples, 21 features (demographics, financials, campaign data). Target: y (term deposit subscription).
Sample Data:
"age";"job";"marital";"education";"default";"housing";"loan";"contact";"month";"day_of_week";"duration";"campaign";"pdays";"previous";"poutcome";"emp.var.rate";"cons.price.idx";"cons.conf.idx";"euribor3m";"nr.employed";"y"
56;"housemaid";"married";"basic.4y";"no";"no";"no";"telephone";"may";"mon";261;1;999;0;"nonexistent";1.1;93.994;-36.4;4.857;5191;"no"
57;"services";"married";"high.school";"unknown";"no";"no";"telephone";"may";"mon";149;1;999;0;"nonexistent";1.1;93.994;-36.4;4.857;5191;"no"
... (see full dataset)
Cleaning Steps:
- Removed duplicates
- Replaced "unknown" in categorical columns with mode
- Encoded categorical features (one-hot, cyclic for months)
.
├── data/ # Raw and processed datasets
├── notebooks/ # Jupyter notebooks for exploration, modeling, and evaluation
├── docs/ # Project documentation, reports, and presentations
├── screenshots/ # Visualizations for portfolio and reporting
├── README.md # Project overview and guide
└── requirements.txt # Python dependencies
- Clone the repository:
git clone https://github.com/imaddde867/Bank-Term-Deposit-Prediction.git cd Bank-Term-Deposit-Prediction - Set up your environment:
python -m venv venv source venv/bin/activate # On Windows: venv\Scripts\activate pip install -r requirements.txt
- Launch the Jupyter Notebook:
Explore the notebook for the full workflow and code.
jupyter notebook notebooks/ML-Final.ipynb
The main workflow is in notebooks/ML-Final.ipynb:
- Data loading, cleaning, and EDA
- Feature engineering and selection
- ANN model building, tuning, and evaluation
See docs/ for reports and rationale.
- Removed duplicates, handled 'unknown' values, encoded categoricals (one-hot, cyclic for months)
- Scaled numerical features (StandardScaler, MinMaxScaler)
- Ordinal encoding for education
- Correlation analysis to drop redundant features
- Random Forest for feature importance (top 19 features retained)
Why ANN? Artificial Neural Networks (ANNs) are powerful for capturing complex, non-linear relationships in high-dimensional data. Here, an ANN outperformed tree-based models in AUC and generalization.
Architecture:
- Input: 19 features
- 3 hidden layers (128, 64, 32 neurons), each with ReLU, BatchNorm, Dropout
- Output: 1 neuron (sigmoid)
Training:
- Early stopping, learning rate scheduling
- 5-fold cross-validation for robust accuracy
- Hyperparameter tuning (batch size, learning rate, dropout, optimizer)
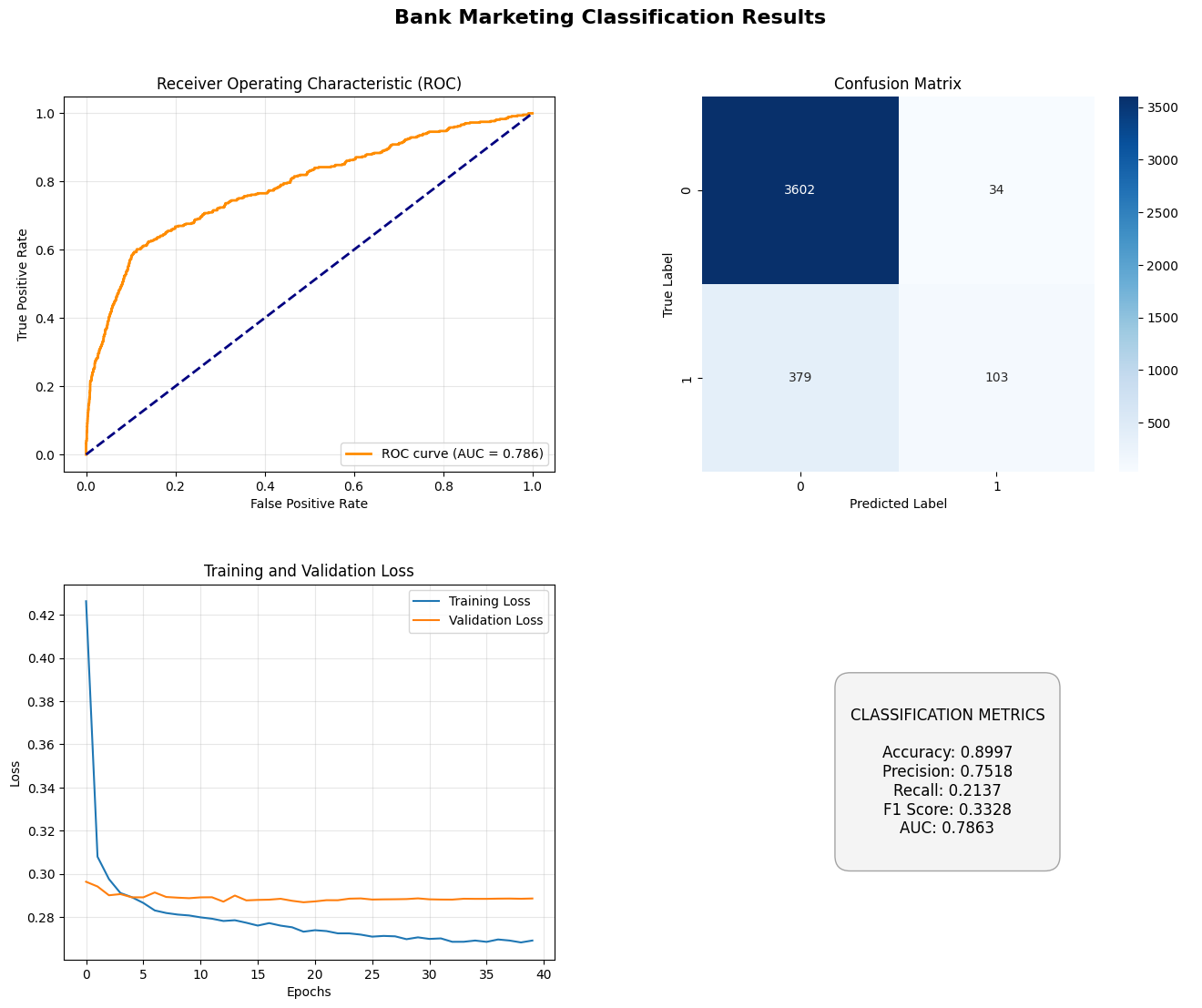
Performance Metrics:
| Metric | Class 0 (No) | Class 1 (Yes) |
|---|---|---|
| Precision | 0.90 | 0.76 |
| Recall | 0.99 | 0.16 |
| F1-score | 0.94 | 0.27 |
| Support | 3636 | 482 |
Overall:
- Accuracy: 0.8961
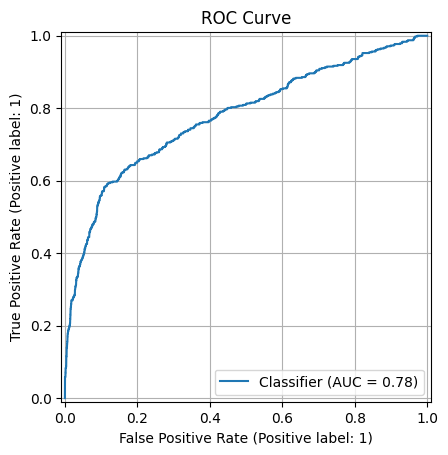
- ROC AUC Score: 0.7777
- 5-fold CV Accuracy: 0.8992 (±0.0022)
Classification Report:
precision recall f1-score support
0 0.90 0.99 0.94 3636
1 0.76 0.16 0.27 482
accuracy 0.90 4118
macro avg 0.83 0.58 0.61 4118
weighted avg 0.88 0.90 0.87 4118
Confusion Matrix:
[[3611 25]
[ 403 79]]
Why ANN?
- Handles complex, non-linear relationships in mixed data
- Outperformed tree-based models in AUC and generalization
- Regularization (Dropout, BatchNorm) and learning rate scheduling ensured stability
- Despite class imbalance, provided actionable leads for marketing
- Probability outputs allow for business-driven threshold tuning
This project showcases a full ML pipeline for a real-world business problem, with a focus on ANN modeling and interpretability. The approach is generalizable to other imbalanced, high-dimensional business tasks.
Next Steps:
- Explore advanced imbalance techniques (SMOTE, class weights)
- Try ensemble models
- Further feature engineering
- Adjust classification threshold for business needs
MIT License. See LICENSE.