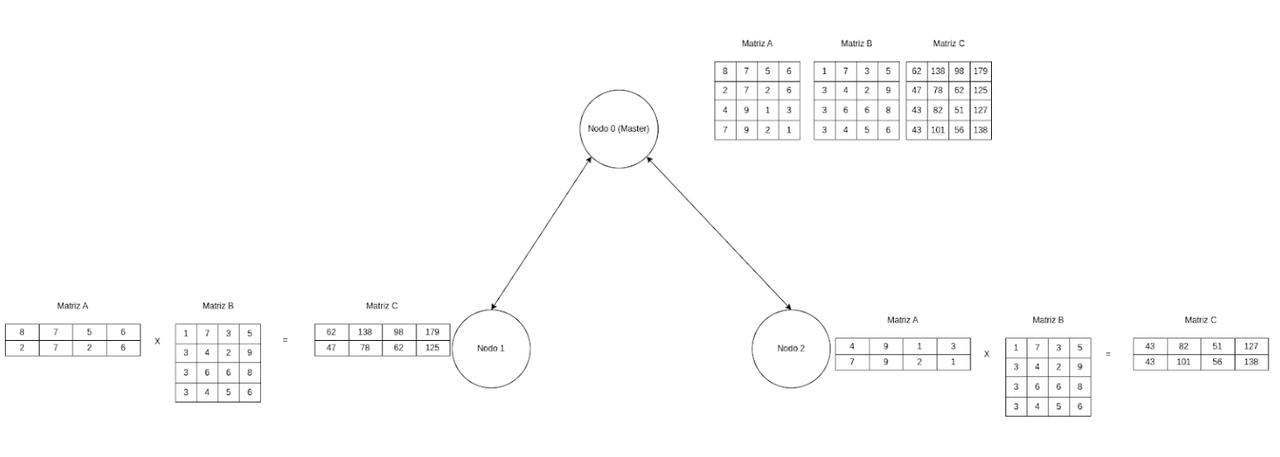
El código desplegado en el cluster de docker básicamente se trata de un programa destinado a la multiplicación de 2 matrices, pero esta vez resuelto por un sistema distribuido.
#include <mpi.h>
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define N 1024 // Define el tamaño de la matrizEstas líneas incluyen las bibliotecas necesarias: mpi.h para la programación paralela con MPI, stdio.h para las funciones de entrada y salida, stdlib.h para la gestión de memoria dinámica, y time.h para la generación de semillas aleatorias. También define el tamaño de la matriz N como 1024.
void matrix_multiply(int *A, int *B, int *C, int stripe_size) {
for (int i = 0; i < stripe_size; i++) {
for (int j = 0; j < N; j++) {
C[i * N + j] = 0;
for (int k = 0; k < N; k++) {
C[i * N + j] += A[i * N + k] * B[k * N + j];
}
}
}
}Esta función realiza la multiplicación de matrices. Toma submatrices A y B, y almacena el resultado en C. stripe_size indica cuántas filas de la matriz A son procesadas por cada proceso.
- Parámetros
- int *A: Puntero a la primera matriz (submatriz)
- int *B: Puntero a la segunda matriz
- int *C: Puntero a la submatriz donde se almacenará el resultado
- int stripe_size: Número de filas de la submatriz A que este proceso está manejando
for (int i = 0; i < stripe_size; i++){}Iterar sobre cada fila de la submatriz A. stripe_size indica cuántas filas de A son procesadas por el proceso actual.
for (int j = 0; j < N; j++){}Iterar sobre cada columna de la matriz B. N es el tamaño de las matrices (en este caso, N = 1024).
C[i * N + j] = 0;Inicializar el elemento C[i * N + j] a 0 antes de comenzar la acumulación. Aquí, C[i * N + j] es el elemento en la fila i y columna j de la matriz resultante C.
for (int k = 0; k < N; k++) {
C[i * N + j] += A[i * N + k] * B[k * N + j];
}Realizar el producto escalar entre la fila i de la submatriz A y la columna j de la matriz B para calcular el elemento C[i * N + j].
- A[i * N + k]: Elemento de la fila i y columna k de la submatriz A.
- B[k * N + j]: Elemento de la fila k y columna j de la matriz B.
La multiplicación A[i * N + k] * B[k * N + j] se suma a C[i * N + j] para acumular el producto escalar.
Ejemplo de Cálculo
A = |1 2 3| |4 5 6| |7 8 9|
B = |9 8 7| |6 5 4| |3 2 1|
Para calcular C[0] (Elemento de la fila 0 y columna 0 de C), tendríamos que hacer C[0] = 19 + 26 + 3*3 = 9 + 12 + 9 = 30. Este proceso se repite para cada elemento de C.
Esto podemos visualizarlo de la siguiente manera:
Supongamos que N = 1024 y tenemos size = 4 procesos. La matriz A de tamaño 1024 x 1024 se divide en 4 submatrices, cada una de tamaño 256 x 1024. Aquí, 256 es el valor de stripe_size (número de filas que cada proceso va a manejar).
A = [ fila_0 ] [ fila_0 ] [...... ] [fila_1023]
Entonces la división de las matrices se realizará de la siguiente manera
Proceso 0: submatriz_A_0 = [ fila_0 ] [ fila_1 ] [...... ] [fila_255 ]
Proceso 1: submatriz_A_1 = [ fila_256 ] [ fila_257 ] [...... ] [fila_511 ]
Proceso 2: submatriz_A_2 = [ fila_512 ] [ fila_513 ] [...... ] [fila_767 ]
Proceso 3: submatriz_A_3 = [ fila_768 ] [ fila_769 ] [...... ] [fila_1023 ]
MPI_Init(&argc, &argv);Inicializa el entorno MPI.
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);rank es el identificador del proceso y size es el número total de procesos.
if (rank == 0) {
A = (int *)malloc(N * N * sizeof(int));
B = (int *)malloc(N * N * sizeof(int));
C = (int *)malloc(N * N * sizeof(int));
// Initialize matrices A and B
for (int i = 0; i < N * N; i++) {
A[i] = rand() % 100;
B[i] = rand() % 100;
}
}Condición if (rank == 0): Esta condición verifica si el proceso actual es el maestro (rank == 0). El proceso maestro es responsable de inicializar las matrices A, B y C.
A = (int *)malloc(N * N * sizeof(int));
B = (int *)malloc(N * N * sizeof(int));
C = (int *)malloc(N * N * sizeof(int));else {
B = (int *)malloc(N * N * sizeof(int)); // Ensure B is allocated in all processes
}Aunque los procesos trabajadores no inicializan A ni C, necesitan una copia de B para realizar la multiplicación de matrices. malloc(N * N * sizeof(int)) asigna memoria para B en cada proceso trabajador.
subA = (int *)malloc(stripe_size * N * sizeof(int));
subC = (int *)malloc(stripe_size * N * sizeof(int));Entonces las submatrices subA y subC
- subA y subC son punteros a enteros que almacenarán las submatrices de A y C respectivamente.
- Cada proceso (incluido el maestro) necesita solo una parte de A y C, de tamaño stripe_size x N.
- stripe_size es el número de filas de A que cada proceso maneja, calculado como N / size.
PI_Scatter Implica un proceso raíz designado que envía datos a todos los procesos en un comunicador. La principal diferencia entre MPI_Bcast y MPI_Scatter es pequeña pero importante. MPI_Bcast envía el mismo dato a todos los procesos mientras MPI_Scatter envía fragmentos de una matriz a diferentes procesos. Consulte la ilustración a continuación para obtener más aclaraciones.
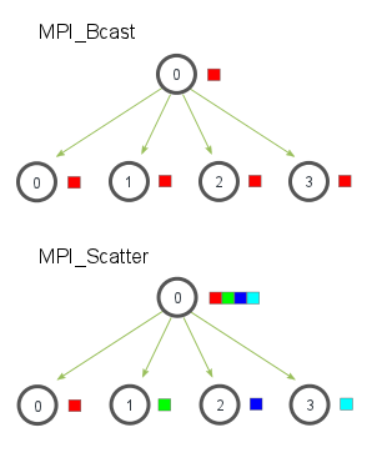
MPI_Scatter(
void* send_data,
int send_count,
MPI_Datatype send_datatype,
void* recv_data,
int recv_count,
MPI_Datatype recv_datatype,
int root,
MPI_Comm communicator)El primer parámetro, send_data es una matriz de datos que reside en el proceso raíz. El segundo y tercer parámetro, send_count y send_datatype, dictan cuántos elementos de un tipo de datos MPI específico se enviarán a cada proceso. Si send_count es uno y send_datatype es MPI_INT, entonces el proceso cero obtiene el primer número entero de la matriz, el proceso uno obtiene el segundo número entero, y así sucesivamente. Si send_count es dos, entonces el proceso cero obtiene el primer y segundo número entero, el proceso uno obtiene el tercero y el cuarto, y así sucesivamente. En la práctica, send_count suele ser igual al número de elementos de la matriz dividido por el número de procesos.
Los parámetros de recepción del prototipo de función son casi idénticos con respecto a los parámetros de envío. El recv_data parámetro es un búfer de datos que puede contener recv_count elementos que tienen un tipo de datos de recv_datatype. Los últimos parámetros, root y communicator, indican el proceso raíz que está dispersando la matriz de datos y el comunicador en el que residen los procesos.
MPI_Scatter(A, stripe_size * N, MPI_INT, subA, stripe_size * N, MPI_INT, 0, MPI_COMM_WORLD);Un broadcast es una de las técnicas de comunicación colectiva estándar. Durante un broadcast, un proceso envía los mismos datos a todos los procesos en un comunicador. Uno de los usos principales de la transmisión es enviar entradas del usuario a un programa paralelo o enviar parámetros de configuración a todos los procesos.
El patrón de comunicación de una transmisión se ve así:
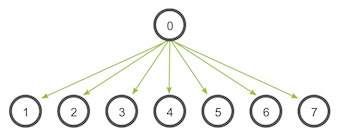
MPI_Bcast(
void* data,
int count,
MPI_Datatype datatype,
int root,
MPI_Comm communicator)Aunque el proceso raíz y el proceso receptor realizan trabajos diferentes, todos llaman a la misma MPI_Bcast función. Cuando el proceso raíz (en nuestro ejemplo, era el proceso cero) llama MPI_Bcast, la vairable data se enviará a todos los demás procesos. Cuando todos los procesos receptores llamen MPI_Bcast, la variable data se completará con los datos del proceso raíz.
MPI_Bcast(B, N * N, MPI_INT, 0, MPI_COMM_WORLD);matrix_multiply(subA, B, subC, stripe_size);Cada proceso ejecuta la función matrix_multiply en su submatriz subA y la matriz completa B para calcular una submatriz de resultado subC.
MPI_Gather es la inversa de MPI_Scatter. En lugar de distribuir elementos de un proceso a muchos procesos, MPI_Gather toma elementos de muchos procesos y los reúne en un solo proceso. Esta rutina es muy útil para muchos algoritmos paralelos, como la clasificación y búsqueda paralelas. A continuación se muestra una ilustración sencilla de este algoritmo.
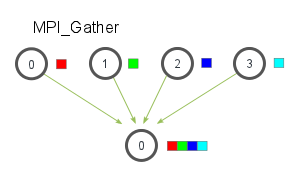
Similar a MPI_Scatter, MPI_Gather toma elementos de cada proceso y los reúne en el proceso raíz. Los elementos están ordenados por el rango del proceso del que fueron recibidos. El prototipo de función para MPI_Gather es idéntico al de MPI_Scatter.
MPI_Gather(
void* send_data,
int send_count,
MPI_Datatype send_datatype,
void* recv_data,
int recv_count,
MPI_Datatype recv_datatype,
int root,
MPI_Comm communicator)En MPI_Gather, solo el proceso raíz necesita tener un búfer de recepción válido. Todos los demás procesos de llamada pueden pasar NULL por recv_data. Además, no olvide que el parámetro recv_count es el recuento de elementos recibidos por proceso , no la suma total de recuentos de todos los procesos. Esto a menudo puede confundir a los programadores MPI principiantes.
MPI_Gather(subC, stripe_size * N, MPI_INT, C, stripe_size * N, MPI_INT, 0, MPI_COMM_WORLD);