A reference Python implementation of the parsing method described in our ACL 2020 paper, Tetra-Tagging: Word-Synchronous Parsing with Linear-Time Inference.
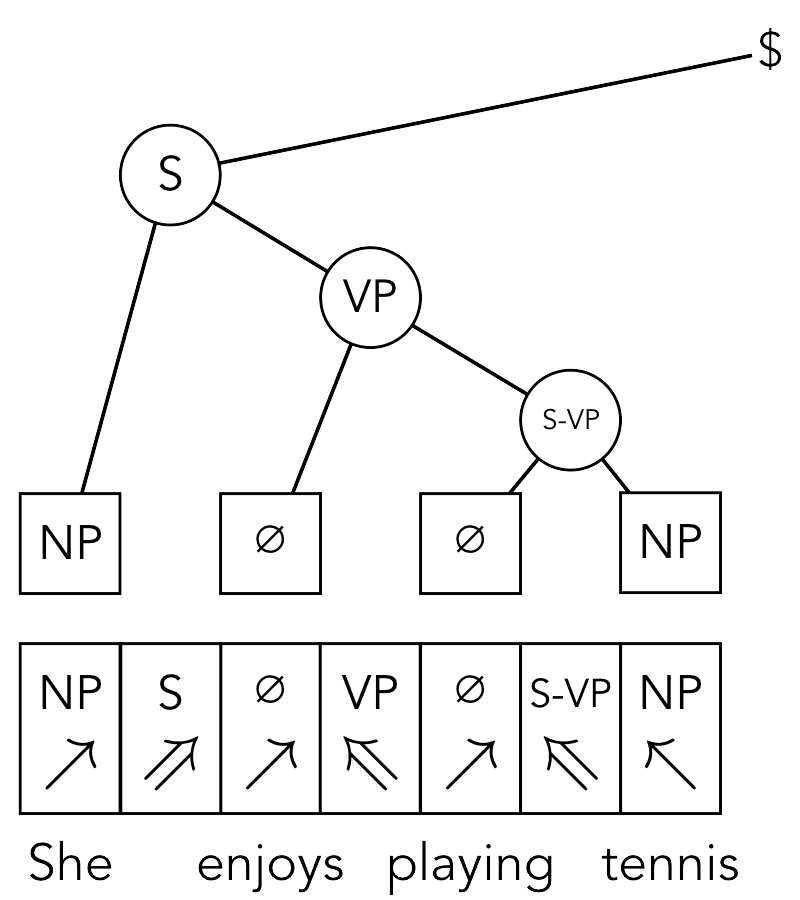
Tetra-tagging is a technique for reducing constituency parsing to sequence labeling. Our implementation consists of a single file, tetra_tag.py, with minimal dependencies: Python 3.6+, NLTK, and numpy. Our hope is that this makes it easy to incorporate tetra-tagging into any training setup, regardless of the framework, hardware, and architectures used.
This notebook gives an example of inference using the model we trained for our paper.
This notebook shows how to use tetra-tagging to train a parser that achieves 93+ F1 in as little as 15 minutes.
Sample usage for the TetraTagSequence class:
>>> import nltk
>>> import tetra_tag
>>> example_tree = nltk.Tree.fromstring("(TOP (S (NP (PRP She)) (VP (VBZ enjoys) (S (VP (VBG playing) (NP (NN tennis))))) (. .)))")
>>> print(example_tree)
(TOP
(S
(NP (PRP She))
(VP (VBZ enjoys) (S (VP (VBG playing) (NP (NN tennis)))))
(. .)))
>>>> tetra_tag.TetraTagSequence.from_tree(example_tree)
['l/NP', 'L/S', 'l', 'L/VP', 'l', 'R/S/VP', 'r/NP', 'R', 'r']
>>> example_tags = tetra_tag.TetraTagSequence(['l/NP', 'L/S', 'l', 'L/VP', 'l', 'R/S/VP', 'r/NP', 'R', 'r'])
>>> print(example_tags)
['l/NP', 'L/S', 'l', 'L/VP', 'l', 'R/S/VP', 'r/NP', 'R', 'r']
>>> leaf_nodes=[nltk.Tree(tag, [word]) for word, tag in example_tree.pos()]
>>> print(example_tags.to_tree(leaf_nodes))
(TOP
(S
(NP (PRP She))
(VP (VBZ enjoys) (S (VP (VBG playing) (NP (NN tennis)))))
(. .)))Sample usage for the TetraTagSystem class:
>>> import nltk
>>> import numpy as np
>>> import tetra_tag
>>> example_tree = nltk.Tree.fromstring("(TOP (S (NP (PRP She)) (VP (VBZ enjoys) (S (VP (VBG playing) (NP (NN tennis))))) (. .)))")
>>> tag_system = tetra_tag.TetraTagSystem(trees=[example_tree])
>>> tag_system.tag_vocab
['L/S', 'L/VP', 'R', 'R/S/VP', 'l', 'l/NP', 'r', 'r/NP']
>>> tag_system.internal_tag_vocab_size, tag_system.leaf_tag_vocab_size
(4, 4)
>>> tag_ids = tag_system.ids_from_tree(example_tree)
>>> tag_ids
[5, 0, 4, 1, 4, 3, 7, 2, 6]
>>> pos = example_tree.pos()
>>> pos
[('She', 'PRP'), ('enjoys', 'VBZ'), ('playing', 'VBG'), ('tennis', 'NN'), ('.', '.')]
>>> print(tag_system.tree_from_ids(tag_ids, pos=pos))
(TOP
(S
(NP (PRP She))
(VP (VBZ enjoys) (S (VP (VBG playing) (NP (NN tennis)))))
(. .)))
>>> random_logits = np.random.random((len(pos), len(tag_system.tag_vocab)))
>>> print(tag_system.tree_from_logits(random_logits, pos=pos))
(TOP
(S
(S (PRP She) (NP (VBZ enjoys)))
(S (VBG playing) (NN tennis))
(NP (. .))))If you use this software for research, please cite our paper as follows:
@inproceedings{kitaev-klein-2020-tetra,
title = "Tetra-Tagging: Word-Synchronous Parsing with Linear-Time Inference",
author = "Kitaev, Nikita and Klein, Dan",
booktitle = "Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics",
month = jul,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.acl-main.557",
pages = "6255--6261"
}