{kind=link}
{kind=link}
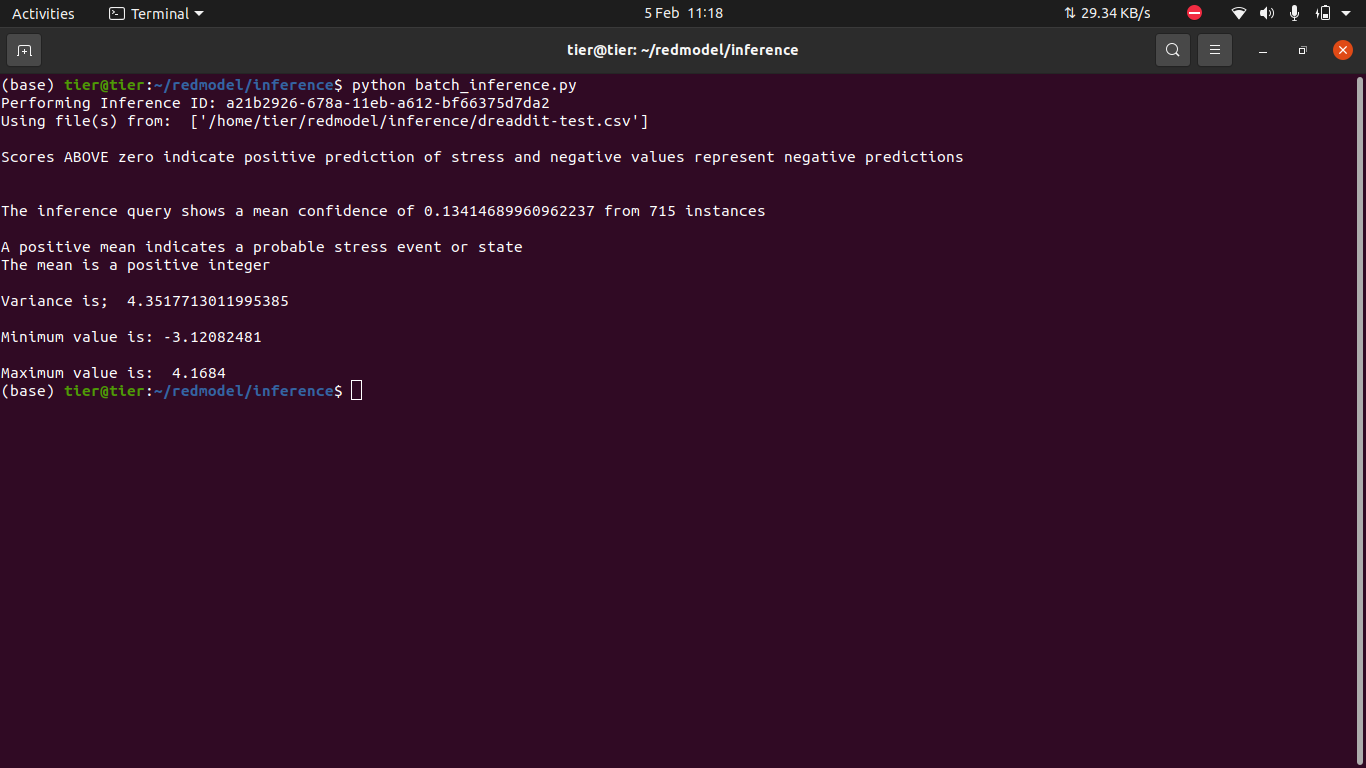
TFX implementation of text sentiment classification using Airflow.
Files containing the definition of DAGs that are used to implement the pipeline
Contains module files that are used in the ML pipeline for tasks such as transformation and training.
analysis notebook is used to preprocess data before saving it in required directory for ML pipelines
remodel_nsl notebook implements the semi supervised workflow as performed in Airflow.
setup_tfx_airflow shell script install the required libraries for reproducing the task.
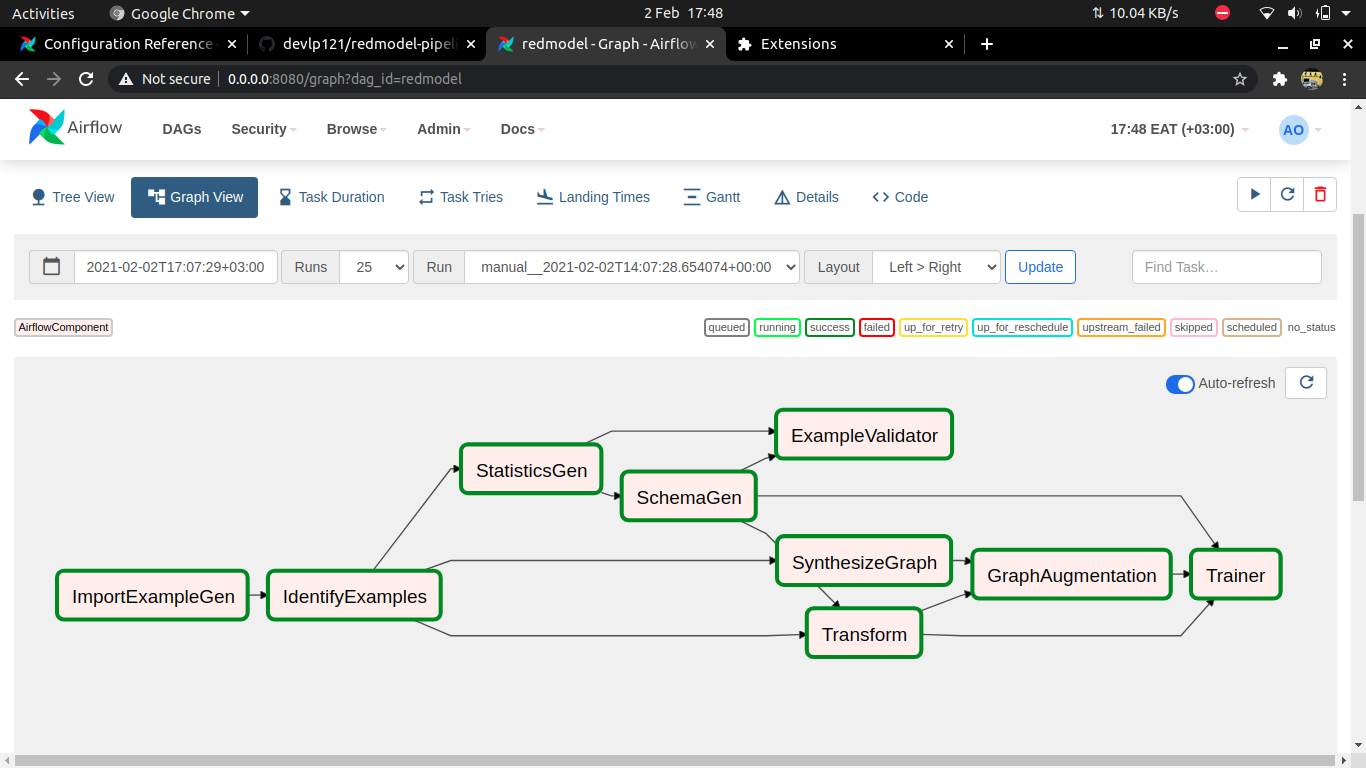
Pipeline components are implemented as DAGs using Airflow
This component ingests CSV data into the machine learning pipeline by converting the data types into compatible datatypes.
Marking each example in the utilized data occurs at this DAG component by assigning each instance with a unique identifier
This component computes statistical information concerning the ingested dataset and the information is used in following stages to evaluate the data for anomalies and also analyze model performance.
This component generates the schema from the provided data and the data is stored in Metadata store for future analysis and evaluation of model performance.
Anomalies are detected at this stage to determine any inconsistencies in the data that might undermine the performance of the generated machine learning model.
Neural Structured Learning is utilized in this component to generate a graph using similarity measurement between labelled and unlabelled data. Embedding for the text is also generated from transfer learning libraries using pretrained layers.
This component performs the general preprocessing tasks that enhance performance and structure the data better.
This component retrieves the probable label assignment from the synthesized graph to create a matching example entity that contains both labels and features that will be used during training.
This method leverages tensorflow to perform training task that completes the model development phase.