Balance Scheduling
The Scheduler selects or filters the stores to be scheduled through Selector/Filter, and generates Operators according to the specific scheduling strategy. All Operators will be handed over to OperatorController for unified speed limit and control. If you are not familiar with these concepts, I suggest you read the article mentioned above first.
In this page, let's take a look at how PD balances the distribution of Regions through scheduling. There are many implementations of Scheduler. Among them, the scheduler responsible for region balance is called region-balance-scheduler. Its main function is to dynamically add and delete nodes as the TiKV cluster dynamically merges or splits regions, which leads to unbalanced region distribution. Algorithm to migrate Region from nodes with more data to nodes with less data, so as to realize the rebalancing of Region storage.
We will introduce the specific structure of balance-region-scheduler in the source code, then sorts out the core process of its scheduling algorithm, and introduces in detail the key execution path of each process or the important mechanism that affects scheduling.
We can view the scheduler running in the cluster through the pd-ctl command
> ./pd-ctl -u http://your-pd-address -d scheduler show
[
"balance-hot-region-scheduler",
"label-scheduler",
"balance-region-scheduler",
"balance-leader-scheduler"
]Here you can see that there are 4 schedulers running, and their functions are different. Here we take balance-region-scheduler as an example to see the specific source code implementation.
The structure of balance-region-scheduler is in the file server/schedulers/balance_region.go.
type balanceRegionScheduler struct {
*BaseScheduler
conf *balanceRegionSchedulerConfig
opController *schedule.OperatorController
filters []filter.Filter
counter *prometheus.CounterVec
}The structure includes the baseScheduler by embedding, so that some of the methods used can be directly "inherited" from the baseScheduler. These methods have little to do with the main process, so we won't introduce them.
The selector is used to select the Store that needs to be scheduled. A Store actually corresponds to a TiKV instance.
The filters is used to filter out the stores that meet the conditions.
The opController is responsible for collecting the Operator generated by the Scheduler and sending the Operator to the TiKV node.
From the previous article, we can know that the core process of the scheduler is implemented in the Schedule() function. Let’s take a look at the core process of scheduling.
For logical clarity, the following code has made some cuts.
func (s *balanceRegionScheduler) Schedule(cluster schedule.Cluster) []*schedule.Operator {
...
// select source store
source := s.selector.SelectSource(cluster, stores)
...
for i := 0; i < balanceRegionRetryLimit; i++ {
// randomly pick a region form the store
region := cluster.RandFollowerRegion(sourceID, core.HealthRegion())
if region == nil {
region = cluster.RandLeaderRegion(sourceID, core.HealthRegion())
}
if region == nil {
continue
}
...
// transferPeer It is a slightly more complicated function. It finds a suitable Store for the Region selected above to create a copy, and generates the final Operator
if op := s.transferPeer(cluster, region, oldPeer, opInfluence); op != nil {
schedulerCounter.WithLabelValues(s.GetName(), "new_operator").Inc()
return []*schedule.Operator{op}
}
...
}
...
}The basic process is actually very simple:
- Choose a store that takes up a lot of space in a Region, called the source store
- Randomly select a Region from the source store to migrate
- Choose a suitable target Store for the Region
- Based on the above information, generate Operator
The main goal of balance-region-scheduler is to maintain datasize balance in TiKVs. If a Region in a Store takes up too much space, we need to migrate the Region on it to a Store with more free space.
The task of selecting Store is completed by BalanceSelector, and the core logic is in the SelectSource function.
stores = filter.SelectSourceStores(stores, s.filters, opts)
opInfluence := s.opController.GetOpInfluence(cluster)
s.OpController.GetFastOpInfluence(cluster, opInfluence)
kind := core.NewScheduleKind(core.RegionKind, core.BySize)
plan := newBalancePlan(kind, cluster, opInfluence)
sort.Slice(stores, func(i, j int) bool {
iOp := plan.GetOpInfluence(stores[i].GetID())
jOp := plan.GetOpInfluence(stores[j].GetID())
return stores[i].RegionScore(opts.GetRegionScoreFormulaVersion(), opts.GetHighSpaceRatio(), opts.GetLowSpaceRatio(), iOp) >
stores[j].RegionScore(opts.GetRegionScoreFormulaVersion(), opts.GetHighSpaceRatio(), opts.GetLowSpaceRatio(), jOp)
})The logic above is to filter the store first, select the stores that can be scheduled, and then sort by score.Next, all schedulable spaces will be searched:
for _, plan.source = range stores {
for i := 0; i < balanceRegionRetryLimit; i++ {
schedulerCounter.WithLabelValues(s.GetName(), "total").Inc()
// Priority pick the region that has a pending peer.
// Pending region may means the disk is overload, remove the pending region firstly.
plan.region = cluster.RandPendingRegion(plan.SourceStoreID(), s.conf.Ranges, opt.HealthAllowPending(cluster), opt.ReplicatedRegion(cluster), opt.AllowBalanceEmptyRegion(cluster))
if plan.region == nil {
// Then pick the region that has a follower in the source store.
plan.region = cluster.RandFollowerRegion(plan.SourceStoreID(), s.conf.Ranges, opt.HealthRegion(cluster), opt.ReplicatedRegion(cluster), opt.AllowBalanceEmptyRegion(cluster))
}
if plan.region == nil {
// Then pick the region has the leader in the source store.
plan.region = cluster.RandLeaderRegion(plan.SourceStoreID(), s.conf.Ranges, opt.HealthRegion(cluster), opt.ReplicatedRegion(cluster), opt.AllowBalanceEmptyRegion(cluster))
}
if plan.region == nil {
// Finally pick learner.
plan.region = cluster.RandLearnerRegion(plan.SourceStoreID(), s.conf.Ranges, opt.HealthRegion(cluster), opt.ReplicatedRegion(cluster), opt.AllowBalanceEmptyRegion(cluster))
}
if plan.region == nil {
schedulerCounter.WithLabelValues(s.GetName(), "no-region").Inc()
continue
}
log.Debug("select region", zap.String("scheduler", s.GetName()), zap.Uint64("region-id", plan.region.GetID()))
// Skip hot regions.
if cluster.IsRegionHot(plan.region) {
log.Debug("region is hot", zap.String("scheduler", s.GetName()), zap.Uint64("region-id", plan.region.GetID()))
schedulerCounter.WithLabelValues(s.GetName(), "region-hot").Inc()
continue
}
// Check region whether have leader
if plan.region.GetLeader() == nil {
log.Warn("region have no leader", zap.String("scheduler", s.GetName()), zap.Uint64("region-id", plan.region.GetID()))
schedulerCounter.WithLabelValues(s.GetName(), "no-leader").Inc()
continue
}
if op := s.transferPeer(plan); op != nil {
op.Counters = append(op.Counters, schedulerCounter.WithLabelValues(s.GetName(), "new-operator"))
return []*operator.Operator{op}
}
}
}
...If the schedule Operator can be generated, then directly generate the Operator and return. because the search order of the solution space is from the best to the worst, so if the schedule can be generated, it must be the current best. We only do this because in some special circumstances, we can't just pick the highest score store to the lowest for scheduling, such as deploying in 3 data centers, and the number of machines deployed in each data center is not equal.
Here we induced the score calculation in 4.0.
As mentioned above, the score of a store is positively related to the space occupied. The easiest way is to add up all the Region sizes in a Store as a score, so that the Region can always be scheduled to on the store with a low space occupation.
This simple method is indeed effective under ideal circumstances, but there is a problem: low space occupation does not mean high remaining space. For example, I have two hard disks of 1G and 1T, and a 1G hard disk stores 800M of Regio n data. A 1T hard disk stores 1G of data. According to the scheduling algorithm mentioned above, a part of the 1T hard disk region will be scheduled to a 1G hard disk, which is obviously unreasonable. The essence of the problem is that the above algorithm does not consider the issue of hard disk capacity.
The score calculation of PD at the beginning is actually relatively simple (same as above), and then gradually develop the algorithms that appear based on practical experience.
Regarding algorithm problems, it is difficult to understand and boring to simply look at the code. I will explain the algorithm first. The specific implementation code will be very simple after understanding the algorithm. You can see it yourself.
Score calculation formula:
y = x (high space available)
y = x + MaxScore - Capacity - OtherSize (low space available)
y = kx + bIt can be seen that the formula is actually a three-segment curve. the method of calculating the score is different in different situations. Here, y represents the score, x represents the storage space of the Region, MaxScore is a huge constant value, and Capacity is the hard disk capacity of the Store.
When the remaining hard disk space is sufficient, the space occupied by the Region is a fraction. Because there is no need to consider the issue of insufficient remaining space at this time, if the data storage is already balanced at this time, even if the remaining space is different, considering the balance of the access load, no scheduling is the best choice.
When the remaining hard disk space is insufficient, the score is a function of Region occupancy and hard disk capacity (Capacity), and is negatively related to the hard disk capacity. The smaller the capacity, the larger the score. Since MaxScore is a large enough constant, when the hard disk capacity is insufficient, the calculated score will be large enough, so there is a higher priority to migrate to other hard disks.
In the above two cases, the two points with sufficient and insufficient remaining space are respectively defined. In order to smoothly calculate the score between the two points, we calculate the linear function of y=kx + b based on the coordinates of the two points.
In order to make it easier for everyone to understand, the following figure gives an intuitive display.

I believe that it will be easier for everyone to go to the specific implementation code.
We publish score calculation V2 in 5.0, the main reason is that the score is discontinuous in different scene,it will be very sensitive when the store's available disk space is critical value.
The score calculation v2 is such as:
$$ y=(1+256* \frac{log(C)-log(A-F+1)}{C-A+F-1})R (A<F) \ y=(1+256\frac{log(C)}{C})R+b\frac{F-A}{F} (A \ge F)\ $$
C: the disk size(gb) A: the disk available size(gb) F: C* low_space_ratio, the default low_space_ratio is 0.8(gb) R: the total region size (mb) b: 1e7
The scoreV2 consider the heterogeneous scene, such as capacity or compression ratio(R/U). And the less available size has, the faster score go up, So the will avoid to one store uses up disk size according to server can not server.
In order to make it easier for everyone to understand, the following figure gives an intuitive display:
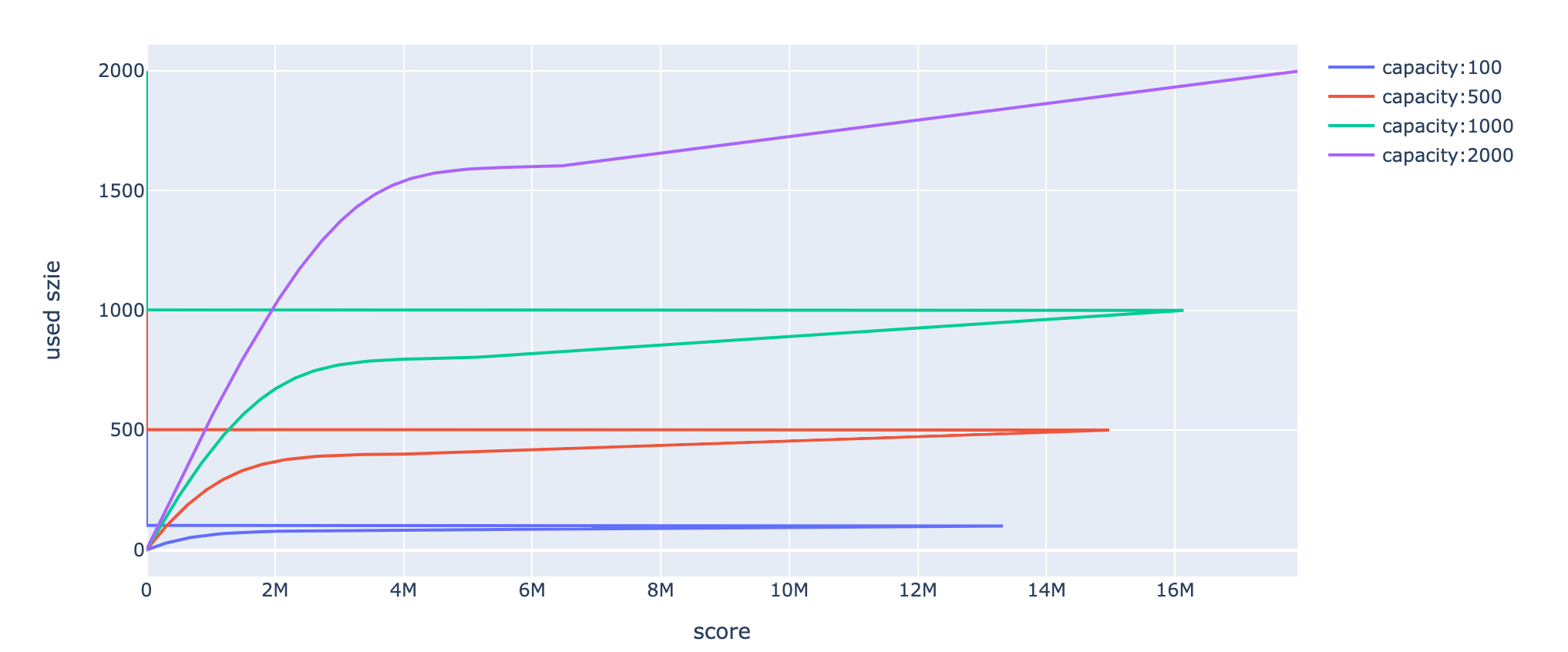
As the figure above shows, score is similar when there are has few available size even though they have different capacity.
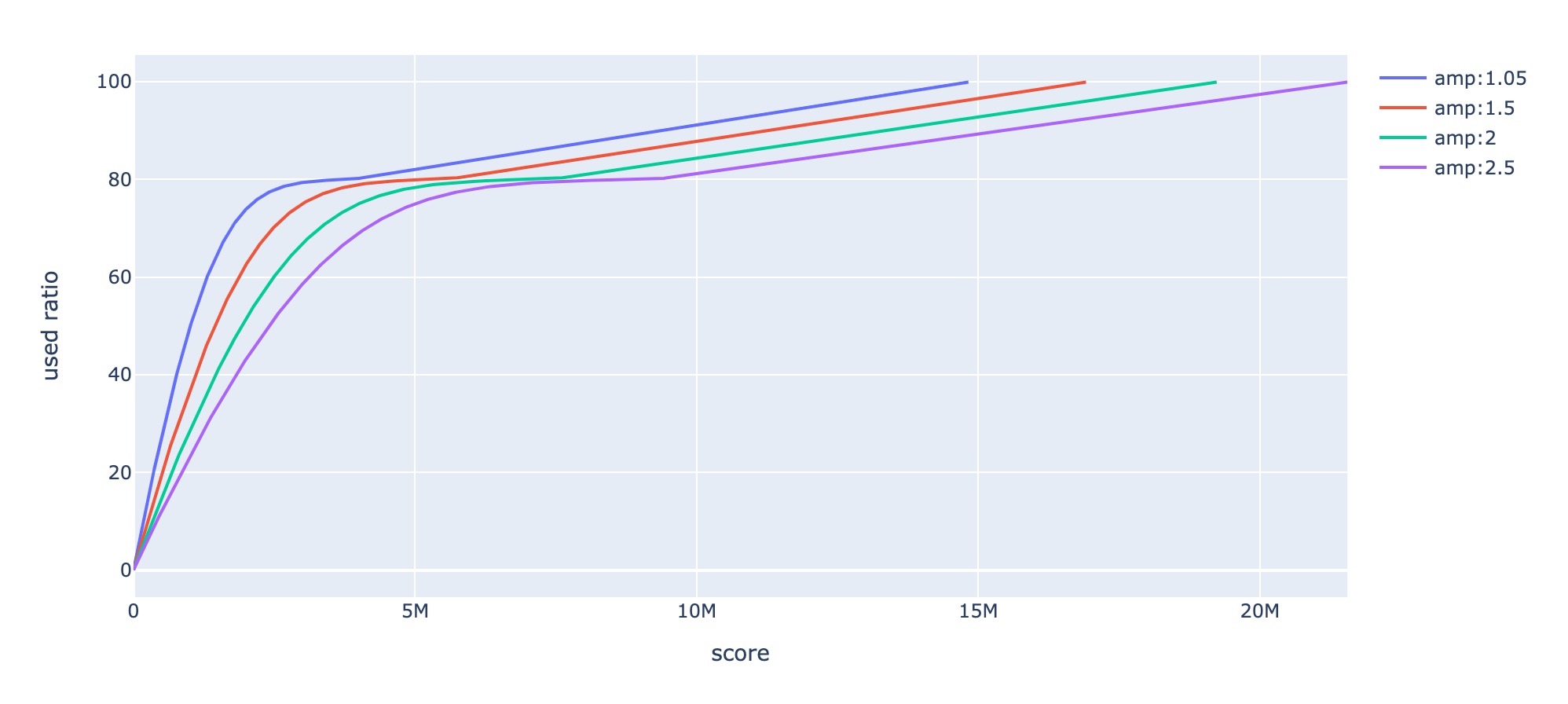
As the figure above shows, score is similar when there are has few available size even though their compression ratio is different
With some of the above information, you can know how to schedule, so the scheduler will generate an Operator, and an Operator includes one or more OperatorSteps. The specific logic is implemented by the CreateMovePeerOperator function called by transferPeer.
If you understand Operator as a scheduling task, OperatorStep can be understood as a step in the task. For example, an Operator that migrates a Region can consist of one AddPeer and one RemovePeer.
Take a look at the specific implementation code:
// CreateMovePeerOperator creates an operator that replaces an old peer with a new peer.
func CreateMovePeerOperator(desc string, cluster opt.Cluster, region *core.RegionInfo, kind OpKind, oldStore uint64, peer *metapb.Peer) (*Operator, error) {
return NewBuilder(desc, cluster, region).
RemovePeer(oldStore).
AddPeer(peer).
Build(kind)
}