The SWhybrid is a heterogeneous framework to use CPU, CUDA-enabled GPUs and Xeon Phi (KNC and KNL both supported) to perform Smith-Waterman database search. We have designed a highly extensible framework to support different architectures flexibly. You can put any coprocessors in the workstations as you want,i.e. GTX1080 along with a Xeon Phi 7110p coprocessor, and they can still work properly at best efficiency.
H. Lan, W. Liu, Y. Liu and B. Schmidt*: SWhybrid: A Hybrid-Parallel Framework for Large-Scale Protein Sequence Database Search, the 31st IEEE International Parallel & Distributed Processing Symposium (IPDPS 2017), Orlando, USA, May, 2017 (To Appear).
SWhybrid features its extensibility by supporting different types of devices.
| Device Type | Instruction sets | Tested Devices |
|---|---|---|
| CPU | SSE, AVX2 | E5-2620, E5-2683v4 |
| Xeon Phi processor (Knights Landing based) | AVX2, AVX512 | Xeon Phi 7210 self-boot |
| Xeon Phi coprocessor (Knights Cornor based) | KNC | Xeon Phi 7110 |
| CUDA | PTX / Video SIMD | GTX780 (cc 3.5), Titan (cc 3.5), K40 (cc 3.5) Titan X (cc 5.2) GTX1080 (cc 6.1) Titan X ultimate(cc 6.1) |
For CUDA-enabled GPUs:
Only devices with computed capability 3.5 and above are supported, it means that old deivces like G80, GT200, Fermi, and GK104 (including GTX6xx and Tesla K10) are not supported.
We provide multiple Makefiles to fit different computing environments as follows:
| Makefile Name | Computing Environment |
|---|---|
| Makefile.cuda | CPU + CUDA |
| Makefile.knc | CPU + KNC |
| Makefile.hybrid | CPU + CUDA + KNC |
| Makefile.knl_avx2 | KNL host with AVX2 |
| Makefile.knl_avx512 | KNL host with AVX512 |
You can set the CPU_ARCH variable as sse or avx2 to select the instruction set used on CPUs.
If you are using AMD CPUs without SSSE3, comment out that HAVE_SSSE3 macro.
If you only want to use a single type of devices, i.e. CPU only, comment out the relevant WITH_CUDA or WITH_KNC macros and the corresponding source files.
You have to run the make command under the root folder of SWhybrid instead of in the src folder. An example is as follows:
swhybrid$ make -f Makefiles/Makefile.cuda
Screen layout:
Makefiles/Makefile.cuda:35: Using avx2 for CPU kernel
Makefiles/Makefile.cuda:36: NVCC gencode option -gencode arch=compute_35,code=sm_35 -gencode arch=compute_52,code=sm_52 -gencode arch=compute_61,code=sm_61
mkdir -p ./obj
g++ -mavx2 -O3 -fopenmp -pthread -DWITH_AVX2 -DWITH_CUDA -I/home/lan/tools/cuda-8.0/include -c src/WorkerPool.cpp -o obj/WorkerPool.cpp.o
g++ -mavx2 -O3 -fopenmp -pthread -DWITH_AVX2 -DWITH_CUDA -I/home/lan/tools/cuda-8.0/include -c src/DataPool.cpp -o obj/DataPool.cpp.o
g++ -mavx2 -O3 -fopenmp -pthread -DWITH_AVX2 -DWITH_CUDA -I/home/lan/tools/cuda-8.0/include -c src/main.cpp -o obj/main.cpp.o
g++ -mavx2 -O3 -fopenmp -pthread -DWITH_AVX2 -DWITH_CUDA -I/home/lan/tools/cuda-8.0/include -c src/RecalcWorker.cpp -o obj/RecalcWorker.cpp.o
g++ -mavx2 -O3 -fopenmp -pthread -DWITH_AVX2 -DWITH_CUDA -I/home/lan/tools/cuda-8.0/include -c src/Worker.cpp -o obj/Worker.cpp.o
g++ -mavx2 -O3 -fopenmp -pthread -DWITH_AVX2 -DWITH_CUDA -I/home/lan/tools/cuda-8.0/include -c src/Param.cpp -o obj/Param.cpp.o
g++ -mavx2 -O3 -fopenmp -pthread -DWITH_AVX2 -DWITH_CUDA -I/home/lan/tools/cuda-8.0/include -c src/Bucket.cpp -o obj/Bucket.cpp.o
g++ -mavx2 -O3 -fopenmp -pthread -DWITH_AVX2 -DWITH_CUDA -I/home/lan/tools/cuda-8.0/include -c src/FastaFile.cpp -o obj/FastaFile.cpp.o
g++ -mavx2 -O3 -fopenmp -pthread -DWITH_AVX2 -DWITH_CUDA -I/home/lan/tools/cuda-8.0/include -c src/AVXKernel.cpp -o obj/AVXKernel.cpp.o
g++ -mavx2 -O3 -fopenmp -pthread -DWITH_AVX2 -DWITH_CUDA -I/home/lan/tools/cuda-8.0/include -c src/AVXWorker.cpp -o obj/AVXWorker.cpp.o
nvcc -O3 -Xptxas -v -gencode arch=compute_35,code=sm_35 -gencode arch=compute_52,code=sm_52 -gencode arch=compute_61,code=sm_61 -c src/CUDAWorker.cu -o obj/CUDAWorker.cu.o
ptxas info : 109 bytes gmem
ptxas info : 109 bytes gmem
ptxas info : 109 bytes gmem
nvcc -O3 -Xptxas -v -gencode arch=compute_35,code=sm_35 -gencode arch=compute_52,code=sm_52 -gencode arch=compute_61,code=sm_61 -c src/CUDAKernel.cu -o obj/CUDAKernel.cu.o
ptxas info : 4 bytes gmem
ptxas info : Compiling entry function '_Z7ComputePjS_jjPiP4int4m' for 'sm_35'
ptxas info : Function properties for _Z7ComputePjS_jjPiP4int4m
24576 bytes stack frame, 0 bytes spill stores, 0 bytes spill loads
ptxas info : Used 85 registers, 372 bytes cmem[0], 4 bytes cmem[2], 1 textures
ptxas info : 4 bytes gmem
ptxas info : Compiling entry function '_Z7ComputePjS_jjPiP4int4m' for 'sm_52'
ptxas info : Function properties for _Z7ComputePjS_jjPiP4int4m
24576 bytes stack frame, 0 bytes spill stores, 0 bytes spill loads
ptxas info : Used 85 registers, 372 bytes cmem[0], 12 bytes cmem[2], 1 textures
ptxas info : 4 bytes gmem
ptxas info : Compiling entry function '_Z7ComputePjS_jjPiP4int4m' for 'sm_61'
ptxas info : Function properties for _Z7ComputePjS_jjPiP4int4m
24576 bytes stack frame, 0 bytes spill stores, 0 bytes spill loads
ptxas info : Used 77 registers, 372 bytes cmem[0], 12 bytes cmem[2], 1 textures
nvcc -O3 -Xptxas -v -gencode arch=compute_35,code=sm_35 -gencode arch=compute_52,code=sm_52 -gencode arch=compute_61,code=sm_61 -c src/CUDAWorkerVideoSIMD.cu -o obj/CUDAWorkerVideoSIMD.cu.o
ptxas info : 109 bytes gmem
ptxas info : 109 bytes gmem
ptxas info : 109 bytes gmem
nvcc -O3 -Xptxas -v -gencode arch=compute_35,code=sm_35 -gencode arch=compute_52,code=sm_52 -gencode arch=compute_61,code=sm_61 -c src/CUDAKernelVideoSIMD.cu -o obj/CUDAKernelVideoSIMD.cu.o
ptxas info : 4 bytes gmem, 4 bytes cmem[3]
ptxas info : Compiling entry function '_Z7ComputeP5uint4PjjjPiP4int4' for 'sm_35'
ptxas info : Function properties for _Z7ComputeP5uint4PjjjPiP4int4
0 bytes stack frame, 0 bytes spill stores, 0 bytes spill loads
ptxas info : Used 74 registers, 364 bytes cmem[0], 1 textures
ptxas info : 4 bytes gmem, 4 bytes cmem[3]
ptxas info : Compiling entry function '_Z7ComputeP5uint4PjjjPiP4int4' for 'sm_52'
ptxas info : Function properties for _Z7ComputeP5uint4PjjjPiP4int4
0 bytes stack frame, 0 bytes spill stores, 0 bytes spill loads
ptxas info : Used 72 registers, 364 bytes cmem[0], 1 textures
ptxas info : 4 bytes gmem, 4 bytes cmem[3]
ptxas info : Compiling entry function '_Z7ComputeP5uint4PjjjPiP4int4' for 'sm_61'
ptxas info : Function properties for _Z7ComputeP5uint4PjjjPiP4int4
0 bytes stack frame, 0 bytes spill stores, 0 bytes spill loads
ptxas info : Used 72 registers, 364 bytes cmem[0], 1 textures
g++ -O2 obj/FastaFile.cpp.o obj/Bucket.cpp.o src/DBmaker.cpp -o DBmaker
g++ -fopenmp -pthread ./obj/WorkerPool.cpp.o ./obj/DataPool.cpp.o ./obj/main.cpp.o ./obj/RecalcWorker.cpp.o ./obj/Worker.cpp.o ./obj/Param.cpp.o ./obj/Bucket.cpp.o ./obj/FastaFile.cpp.o ./obj/AVXKernel.cpp.o ./obj/AVXWorker.cpp.o ./obj/CUDAWorker.cu.o ./obj/CUDAKernel.cu.o ./obj/CUDAWorkerVideoSIMD.cu.o ./obj/CUDAKernelVideoSIMD.cu.o -o swhybrid -lgomp -L/home/lan/tools/cuda-8.0/lib64/ -lcudart
strip swhybrid
A successful build will generate a preprocessor DBmaker and the main binary SWhbyrid. Firstly you have to call the DBmaker to genrate an indexed database. Currently we only support FASTA format as input. And then, you can use SWhybrid to search. SWhybrid is designed for heterogeneous architectures and tends to use every single devices available in the system. If you want to run benchmark only on a single platform, please use change the Makefile and rebuild SWhybrid.
./DBmaker [Input path (FASTA required)] [Output_path]
Currently only FASTA format are accepted. The preprocessor will generate OUTPUT.seq, OUTPUT.map and OUTPUT.title, respectively. You can speicify any of them when running SWhybrid.
Parameter list:
./SWhybrid
Input Files:
-q <str> (QUERY_FILE)
-d (DATABASE_FILE)
Scoring Scheme:
-m <str> (Scoring matrix name, default = blosum62, supported)
-g <int> (gap open penalty, default = 10)
-e <int> (gap extend penalty, default = 2)
-v (verbose, show current search progress and system configuration)
We use the env_nr database from NCBI as an example:
Firstly download the latest version of the database
$wget ftp://ftp.ncbi.nlm.nih.gov/blast/db/FASTA/env_nr.gz
And unzip the tarball
$gunzip env_nr.gz
Preprocessor the database using the Bucket algorithm
$./DBmaker env_nr env_nr
Screen layout:
flushing out chunk 0 of size 256MB
flushing out chunk 1 of size 255MB
flushing out chunk 2 of size 255MB
flushing out chunk 3 of size 255MB
flushing out chunk 4 of size 255MB
flushing out chunk 5 of size 24MB
last batch num 72
total sequence num is 6865992 68c448
closing files
file closed
Now you can search the database with the example queries.
$./swhybrid -q example_queries/q20-Q9UKN1.fasta -db ./env_nr
Screen layout:
query path example_queries/q20-Q9UKN1.fasta
db path ./env_nr
number of available CPUs: 24
number of available MIC devices: 2
Sequence Database size 1.28GB
top num 10
long query length 5480, pass 8, major length 685, last length 685, average length 685
long query length 5480, pass 8, major length 685, last length 685, average length 685
MIC computing time 31.164000s, AARes 392385024, GCUPs 68.998522
SSE computing time 33.890000s, AARes 596055552, GCUPs 96.381954
MIC computing time 31.425000s, AARes 395311616, GCUPs 68.935805
#Recalc# symbol size 2.26MB
#Recalc# sequence num 993
Recalculator takes 0.27s
total calculation time: 34.737000, GCUPS 216.026073
, total residue 1369360896
----------------top 10 scores---------------
score 497 -- >gi|816799270|gb|KKN75037.1| hypothetical protein LCGC14_0384110, partial [marine sediment metagenome]
score 373 -- >gi|816760533|gb|KKN41062.1| hypothetical protein LCGC14_0727120 [marine sediment metagenome]
score 357 -- >gi|143302314|gb|EDE20598.1| hypothetical protein GOS_1171242, partial [marine metagenome]
score 353 -- >gi|816543413|gb|KKL55155.1| hypothetical protein LCGC14_2258220, partial [marine sediment metagenome]
score 331 -- >gi|143177023|gb|EDD37053.1| hypothetical protein GOS_1315847, partial [marine metagenome]
score 330 -- >gi|135253791|gb|EBG44713.1| hypothetical protein GOS_9431765, partial [marine metagenome]
score 322 -- >gi|143880528|gb|EDH29922.1| hypothetical protein GOS_630718, partial [marine metagenome]
score 314 -- >gi|143324238|gb|EDE33522.1| hypothetical protein GOS_1148440, partial [marine metagenome]
score 308 -- >gi|136135495|gb|EBM14790.1| hypothetical protein GOS_8455521, partial [marine metagenome]
score 307 -- >gi|143406335|gb|EDE78403.1| hypothetical protein GOS_1070628, partial [marine metagenome]
-------------------------------------------
For KNL, we strongly recommend to use the numactl tool to bind all memory allocations on the MCDRAM. SWhybrid will not occupy too much memory so it's safe to allocate everything on MCDRAM.
Typical Search command for KNL:
numactl --membind=1 ./swhybrid_icc -q ./swhybrid/benchmark/query_seqs/q20-Q9UKN1.fasta -db env_nr
Typical screen layout
query path ./swhybrid/benchmark/query_seqs/q11-P07756.fasta
db path env_nr
number of available CPUs: 256
Sequence Database size 1.29GB
Query sequence length 1504
top num 10
AVX computing time 4.799000s, AARes 322701824, GCUPs 101.134308
AVX computing time 5.217000s, AARes 353834496, GCUPs 102.006343
AVX computing time 5.209000s, AARes 350940672, GCUPs 101.327465
AVX computing time 5.297000s, AARes 354414592, GCUPs 100.630458
#Recalc# symbol size 3.34MB
#Recalc# sequence num 11200
Recalculator takes 0.19s
total calculation time: 5.594000, GCUPS 371.271189
, total residue 1380911616
----------------top 10 scores---------------
score 2446 -- >gi|402670512|gb|EJW97357.1| glutamine-dependent carbamyl phosphate synthetase [gut metagenome]
score 2334 -- >gi|142016433|gb|ECU86348.1| hypothetical protein GOS_3006398, partial [marine metagenome]
score 2037 -- >gi|816761971|gb|KKN42249.1| hypothetical protein LCGC14_0715100 [marine sediment metagenome]
score 2034 -- >gi|142018781|gb|ECU88598.1| hypothetical protein GOS_3002200 [marine metagenome]
score 1927 -- >gi|142446843|gb|ECY14197.1| hypothetical protein GOS_2409877 [marine metagenome]
score 1865 -- >gi|142529178|gb|ECY73750.1| hypothetical protein GOS_2306350, partial [marine metagenome]
score 1820 -- >gi|816710604|gb|KKM96493.1| hypothetical protein LCGC14_1177510, partial [marine sediment metagenome]
score 1812 -- >gi|143440129|gb|EDE96789.1| hypothetical protein GOS_1038777 [marine metagenome]
score 1787 -- >gi|142130887|gb|ECV81596.1| hypothetical protein GOS_2830439, partial [marine metagenome]
score 1771 -- >gi|142623539|gb|ECZ40182.1| hypothetical protein GOS_2190190 [marine metagenome]
--------------------------------------------
As each worker on KNL only uses a part of the cores, you will see multiple standalone GCUPS reported. The overall GCUPS performance including the recalculation time is reported in the last figure.
We have conducted performance evaluation on the following heterogeneous test platforms:
| Server | Processor | Memory | Accelerator |
|---|---|---|---|
| S1 | dual E5-2620 | 16GB | 1 Titan X (Maxwell) + 1 Phi-7110 |
| S2 | dual E5-2620 | 16GB | 2 Phi-7110 |
| S3 | dual E5-2620 | 16GB | 2 Tesla K40 |
| S4 | dual E5-2620 | 16GB | 1 Titan X (Maxwell) + 1 GTX1080 |
| S5 | Xeon Phi 7210 | 128GB | - |
Performance on CPUs, including SSE, AVX2 on E5-2620 and E5-2683v4, respectively.

Performance on CUDA-enabled GPUs.

Performance on Xeon Phi series (KNC and KNL).
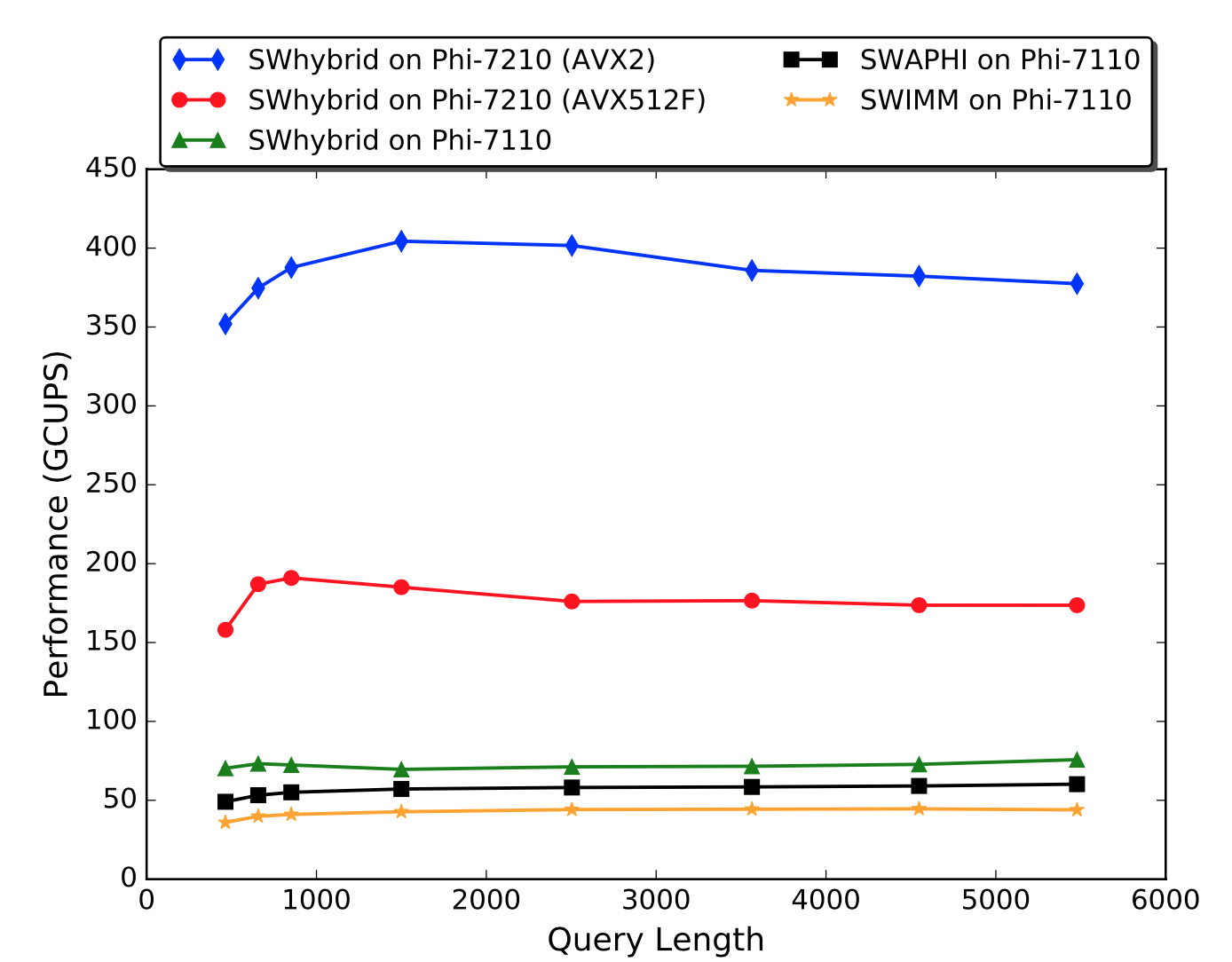
Full system tests.

Titles cannot be displayed properly on Ubuntu 16.04, but works well on Centos.