modeld: skip redundant cast, reshape, and flatten #35735
+3
−3
Conversation
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
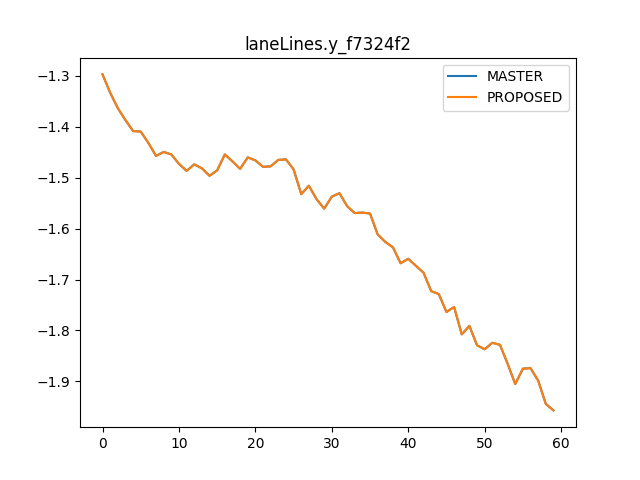
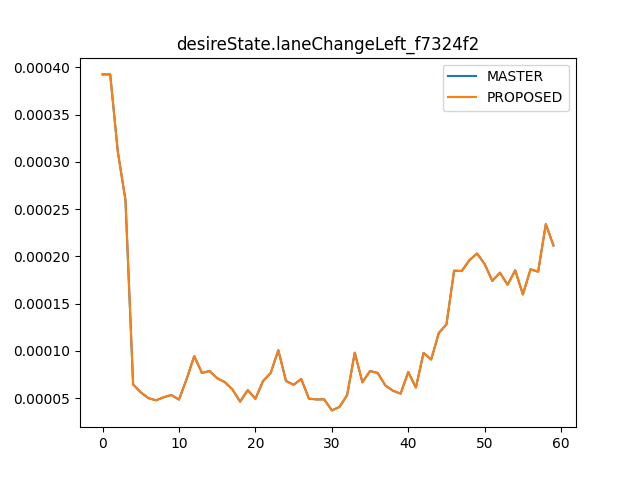
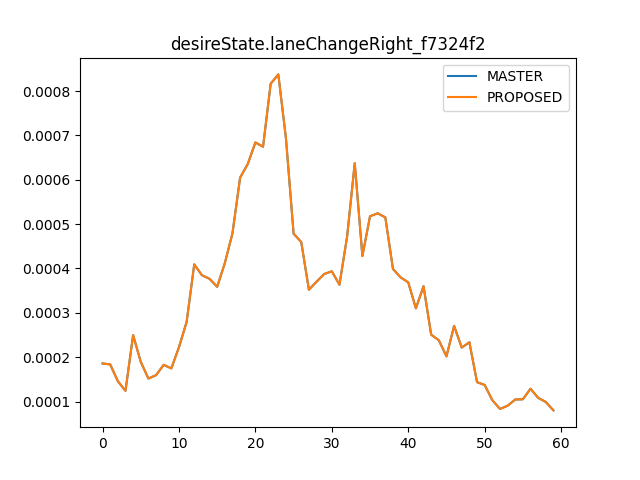
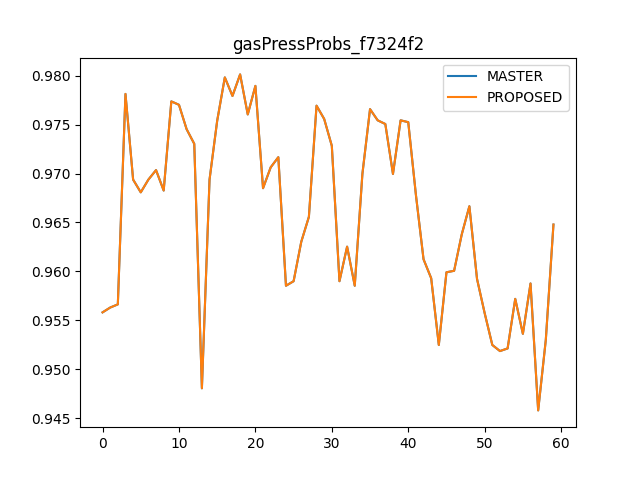
There was a problem hiding this comment.
Pull Request Overview
This PR removes redundant tensor-to-NumPy operations (cast, reshape, flatten, and extra .to("CPU")) in model inference to lower CPU usage and slightly speed up execution.
- Replace
.numpy().flatten()with direct buffer extraction via.contiguous().realize().uop.base.buffer.numpy() - Apply the same change for both vision and policy outputs in
modeld.pyand for the monitoring model indmonitoringmodeld.py
Reviewed Changes
Copilot reviewed 2 out of 2 changed files in this pull request and generated 1 comment.
| File | Description |
|---|---|
| selfdrive/modeld/modeld.py | Drop .flatten() and use direct buffer NumPy extraction |
| selfdrive/modeld/dmonitoringmodeld.py | Remove redundant .flatten() in monitoring model output process |
Comments suppressed due to low confidence (3)
selfdrive/modeld/modeld.py:166
- Removing
.flatten()changesvision_outputfrom a 1D array to its original multi-dimensional shape, which may breakslice_outputs. To preserve existing behavior, reapply a flatten step (e.g.,.reshape(-1)or.flatten()) after the NumPy conversion.
self.vision_output = self.vision_run(**self.vision_inputs).contiguous().realize().uop.base.buffer.numpy()
selfdrive/modeld/modeld.py:173
- The
.flatten()call was removed here as well, alteringpolicy_outputshape from a flat vector to multi-dimensional. Consider adding.reshape(-1)or.flatten()to maintain the expected 1D output.
self.policy_output = self.policy_run(**self.policy_inputs).contiguous().realize().uop.base.buffer.numpy()
selfdrive/modeld/dmonitoringmodeld.py:96
- By removing
.flatten(),outputwill retain its original multi-dimensional shape. If downstream logic expects a flat array, reapply a flatten (e.g.,.reshape(-1)or.flatten()) after conversion.
output = self.model_run(**self.tensor_inputs).contiguous().realize().uop.base.buffer.numpy()
Comment on lines
+166
to
+173
| self.vision_output = self.vision_run(**self.vision_inputs).contiguous().realize().uop.base.buffer.numpy() | ||
| vision_outputs_dict = self.parser.parse_vision_outputs(self.slice_outputs(self.vision_output, self.vision_output_slices)) | ||
|
|
||
| self.full_features_buffer[0,:-1] = self.full_features_buffer[0,1:] | ||
| self.full_features_buffer[0,-1] = vision_outputs_dict['hidden_state'][0, :] | ||
| self.numpy_inputs['features_buffer'][:] = self.full_features_buffer[0, self.temporal_idxs] | ||
|
|
||
| self.policy_output = self.policy_run(**self.policy_inputs).numpy().flatten() | ||
| self.policy_output = self.policy_run(**self.policy_inputs).contiguous().realize().uop.base.buffer.numpy() |
There was a problem hiding this comment.
[nitpick] The long chain .contiguous().realize().uop.base.buffer.numpy() is repeated multiple times. Consider extracting this pattern into a helper function (e.g., to_cpu_array(tensor)) to reduce duplication and improve readability.
Copilot uses AI. Check for mistakes.
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
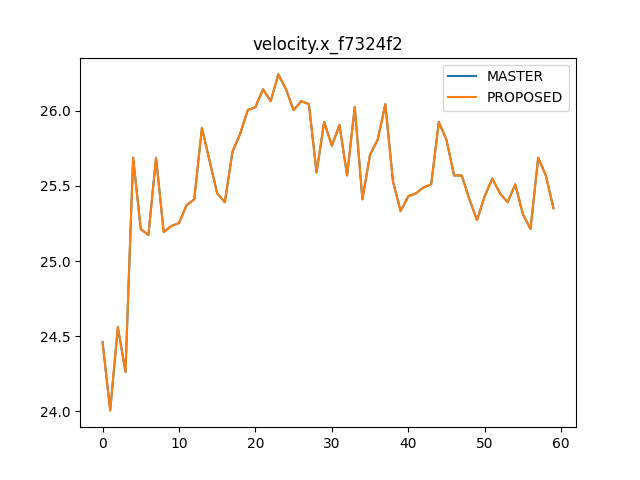
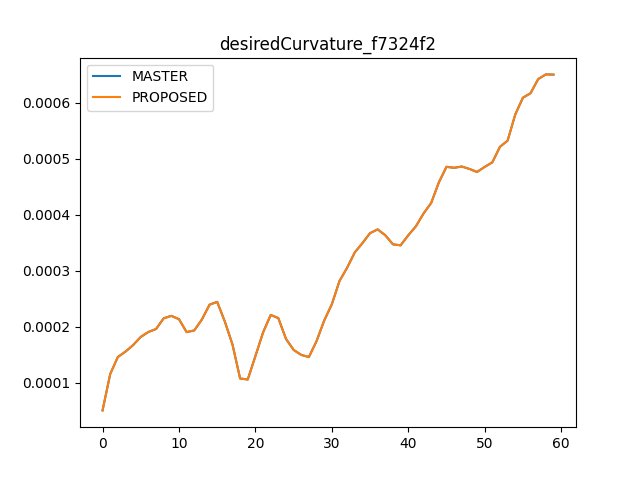
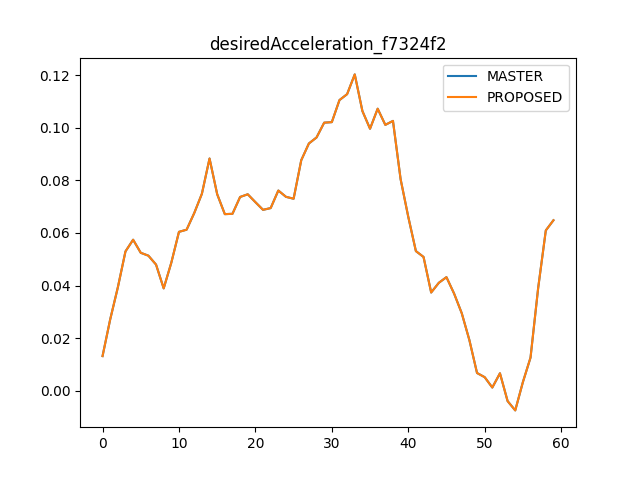
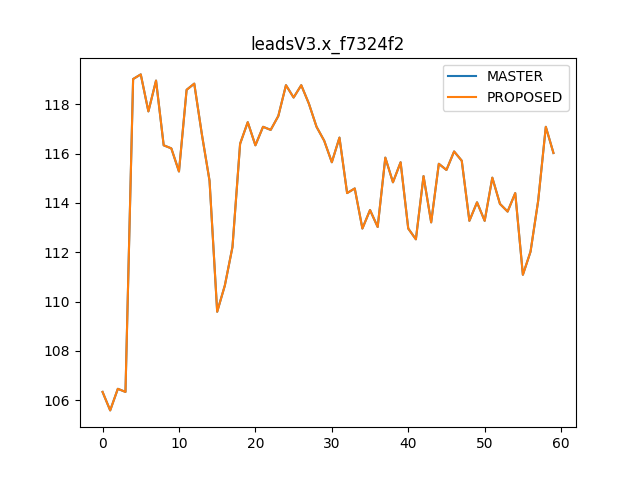
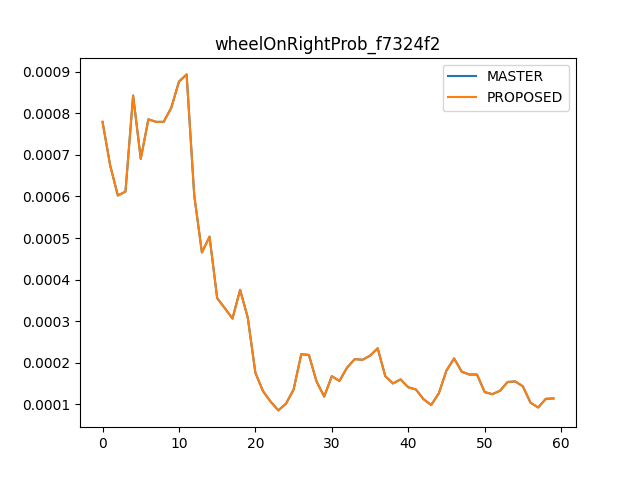
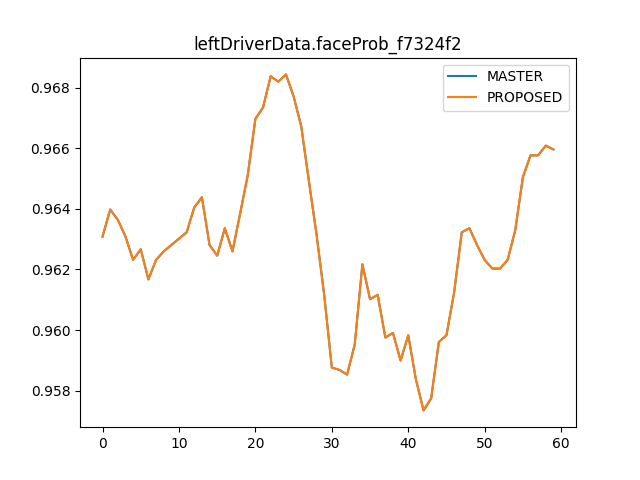
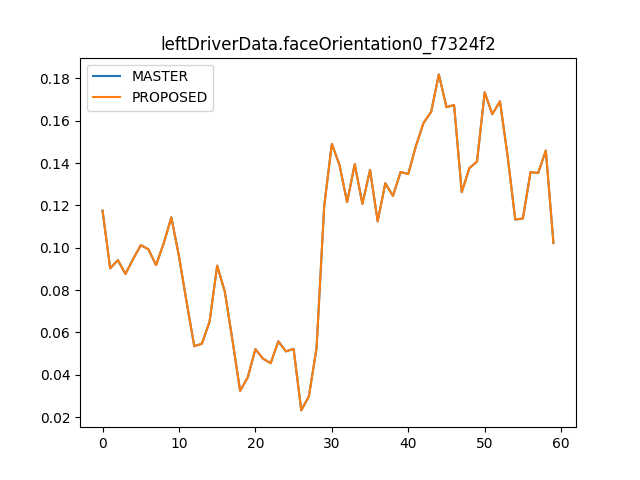
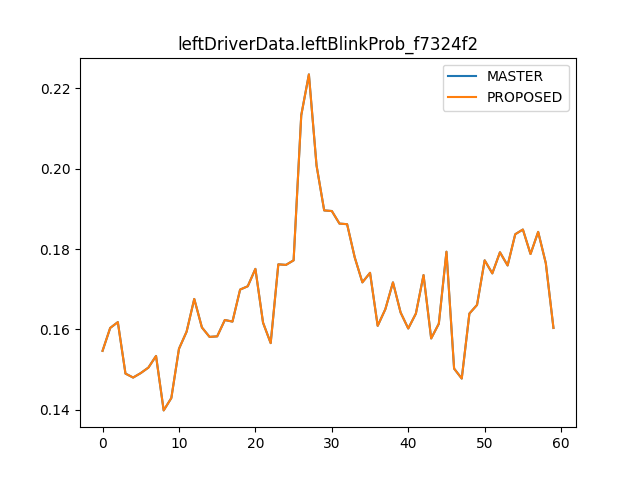
Removing the redundant operations improves
modeld.pyCPU usage from 32% to 24% and makes execution time ~2% fasterFor
dmonitoringmodeld.py, it improves CPU usage from 17% to 12% and makes execution time ~4% faster.In tinygrad,
Tensor.numpy()is essentially defined asin
compile3.py, we already cast to float32and in
modeld.pyanddmonitoringmodeld.py,flatten()is called after.numpy(), making the reshape redundant.There is also an extra .to("CPU") which I think currently causes tinygrad to do a useless copy from CPU to NPY
gotta afford the hey comma cpu usage somehow