Change BloomFilter implementation for Sparse Joins #1806
Conversation
* Add groupBy benchmark * Add hand made impl of Tuple2 Coder
- SchemaCoder - BeamSQL support
* Simplify query row transform
scio-core/src/main/scala/com/spotify/scio/coders/instances/AlgebirdCoders.scala
Outdated
Show resolved
Hide resolved
Codecov Report
@@ Coverage Diff @@
## master #1806 +/- ##
==========================================
- Coverage 71.16% 69.42% -1.75%
==========================================
Files 196 197 +1
Lines 6077 6211 +134
Branches 395 443 +48
==========================================
- Hits 4325 4312 -13
- Misses 1752 1899 +147
Continue to review full report at Codecov.
|

There was a problem hiding this comment.
Rough first pass. LGTM mostly. I'd make most BF stuff private for now until we're ready to open it for end users.
For that we should probably verify that the MutableBF:
- passes Beam mutation detection in transforms
- has efficient and deterministic coder (for those store it to disk for future jobs)
scio-core/src/main/scala/com/spotify/scio/util/BloomFilter.scala
Outdated
Show resolved
Hide resolved
scio-core/src/main/scala/com/spotify/scio/coders/instances/AlgebirdCoders.scala
Outdated
Show resolved
Hide resolved
scio-core/src/main/scala/com/spotify/scio/util/BloomFilter.scala
Outdated
Show resolved
Hide resolved
scio-core/src/main/scala/com/spotify/scio/util/BloomFilter.scala
Outdated
Show resolved
Hide resolved
scio-core/src/main/scala/com/spotify/scio/util/BloomFilter.scala
Outdated
Show resolved
Hide resolved
scio-core/src/main/scala/com/spotify/scio/util/BloomFilter.scala
Outdated
Show resolved
Hide resolved
scio-core/src/main/scala/com/spotify/scio/util/BloomFilter.scala
Outdated
Show resolved
Hide resolved
scio-core/src/main/scala/com/spotify/scio/util/BloomFilter.scala
Outdated
Show resolved
Hide resolved
scio-core/src/main/scala/com/spotify/scio/util/BloomFilter.scala
Outdated
Show resolved
Hide resolved
scio-core/src/main/scala/com/spotify/scio/util/BloomFilter.scala
Outdated
Show resolved
Hide resolved
Co-Authored-By: anish749 <[email protected]>
Co-Authored-By: anish749 <[email protected]>
Co-Authored-By: anish749 <[email protected]>
Co-Authored-By: anish749 <[email protected]>
Co-Authored-By: anish749 <[email protected]>
Co-Authored-By: anish749 <[email protected]>
Co-Authored-By: anish749 <[email protected]>
|
Thanks for the review @nevillelyh . For your second point, any pointers about comparing the efficiency of coders? |
| // TODO: investigate this upper bound and density more closely (or derive a better formula). | ||
| // TODO: The following logic is same for immutable Bloom Filters and may be referred here. | ||
| val fpProb = | ||
| if (density > 0.95) |
There was a problem hiding this comment.
🎨 use some {} just because it's a multiline
scio-core/src/main/scala/com/spotify/scio/util/BloomFilter.scala
Outdated
Show resolved
Hide resolved
scio-core/src/main/scala/com/spotify/scio/util/BloomFilter.scala
Outdated
Show resolved
Hide resolved
scio-core/src/main/scala/com/spotify/scio/util/BloomFilter.scala
Outdated
Show resolved
Hide resolved
scio-core/src/main/scala/com/spotify/scio/util/BloomFilter.scala
Outdated
Show resolved
Hide resolved
scio-core/src/main/scala/com/spotify/scio/util/BloomFilter.scala
Outdated
Show resolved
Hide resolved
scio-core/src/main/scala/com/spotify/scio/util/BloomFilter.scala
Outdated
Show resolved
Hide resolved
scio-core/src/main/scala/com/spotify/scio/util/BloomFilter.scala
Outdated
Show resolved
Hide resolved
scio-core/src/main/scala/com/spotify/scio/util/BloomFilter.scala
Outdated
Show resolved
Hide resolved
scio-core/src/main/scala/com/spotify/scio/util/BloomFilter.scala
Outdated
Show resolved
Hide resolved
# Conflicts: # scio-core/src/main/scala/com/spotify/scio/values/PairSCollectionFunctions.scala
Co-Authored-By: anish749 <[email protected]>
Co-Authored-By: anish749 <[email protected]>
|
@regadas thanks for reviewing. I've made the changes. |
|
Here are the updated benchmarks |
I am trying to add the optimisations from #1686 and twitter/algebird#673.
This involves using a
java.util.BitSetinstead of a customArray[Long]to back the BloomFilter, and not reallocating the BitSet after adding each element. Since adding elements to a BloomFilter are idempotent, and we do not need a reference to the old BloomFilter after it has been created, using a mutable BloomFilter works faster with less things to copy.Here is what I did:
Use
java.util.BitSetbacked bloom filter from twitter/algebird#673.It works but the memory allocation is based on the width of the filter which is derived from the number of keys hint passed in sparse joins.
This means if the hint is misleading (abnormally high) we end up with OOM. Also we have test cases which pass 1Billion elements but doesn't actually add so many elements. This means allocating memory for for the estimated width. The original Algebird BF uses a compressed bitmap and has a sparse bloom filter implementation when less than 10% of the bits are used. This reduces memory usage.
Now, EWAHCompressedBitMaps, used by Algebird, is immutable and is very slow when inserting, because it again copies and reallocates when inserting data. Using this bitmap would again reduce the throughput compared to ClearSpring's BF that I used in #1686. Also this would use Kryo serialization since this bitmap doesn't have a Beam Coder, but that is probably not a problem.
So now we write another compressed mutable bitmap which essentially is a
mutable.Set[Int]. This works better, and has BeamCoders. With this we don't have any OOM issues for sparse filters and is also mutable, hence we are not reallocating.But this is slower than ClearSpring. I didn't quite understand why. But it was 50% slower in terms of throughput compared to
util.BitSet.Then we build a
DelayedBloomFilter(in this version) where we just calculate the hashes(as anArray[Int]), and keep the references in amutable.Buffer[Array[Int]]when inserting values.We wait till this is filled up by the aggregator to a point where this no longer offers any benefit of not allocation the complete memory of
util.BitSetand then we change to theMutableBFInstance[T]. When the first query happens, we materialise themutable.Buffer[Array[Int]]into aSet[Int]and store that, to answer queries. For multiple queries, we don't re materialise this. If a new element is inserted, we discard the previously materialisedSet[Int]and wait till we see the first query. We use aggregators here, which are nice to us and they don't interleave inserts and reads from the filter. This means we can delay the Set allocation till we have a query. Also this BF is not meant to be in caches and only in ephemeral pipelines, which means that we have clearly separated steps for creation and usage of the bloom filter.With the above implementation,
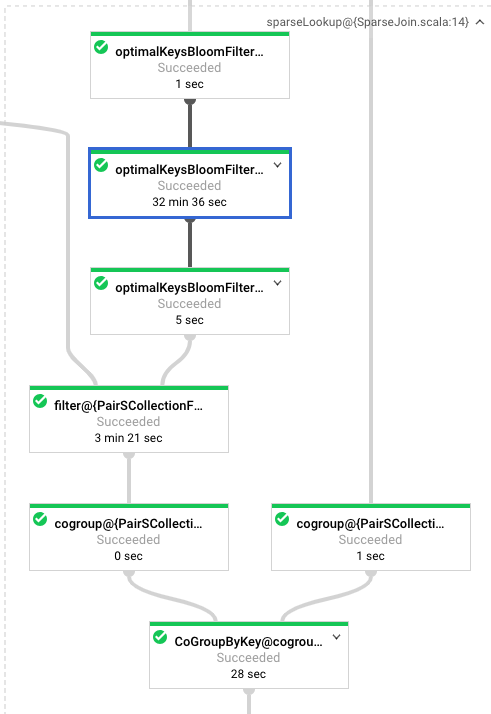
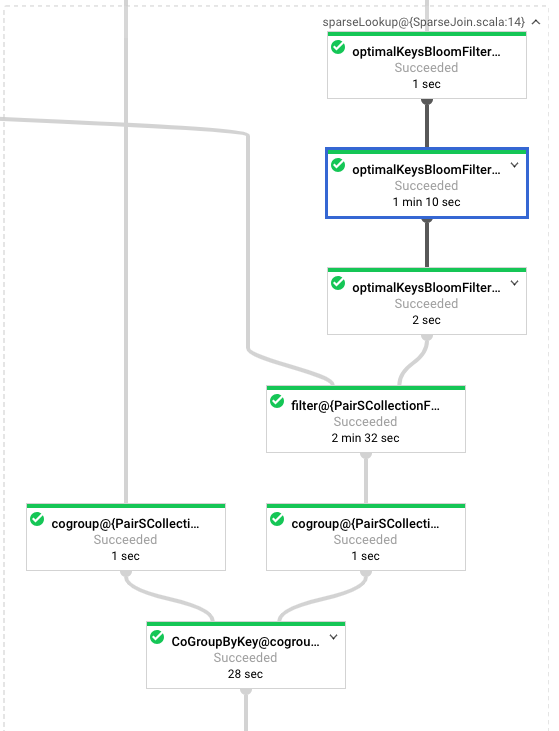
we have the following results for putting 1M elements in the BloomFilter:
Original Implementation (v0.7.4)
Current Branch (v0.7.5-SNAPSHOT)
JMH Benchmark (locally outside this repo)